
 Technologie-Peripheriegeräte
KI
Deep Learning hat eine neue Gefahr! Die University of Sydney schlägt eine neue modalübergreifende Aufgabe vor, bei der Text als Leitfaden für den Bildausschnitt verwendet wird
Technologie-Peripheriegeräte
KI
Deep Learning hat eine neue Gefahr! Die University of Sydney schlägt eine neue modalübergreifende Aufgabe vor, bei der Text als Leitfaden für den Bildausschnitt verwendet wird
Deep Learning hat eine neue Gefahr! Die University of Sydney schlägt eine neue modalübergreifende Aufgabe vor, bei der Text als Leitfaden für den Bildausschnitt verwendet wird

Bildausschnitt bezieht sich auf das Extrahieren des genauen Vordergrunds im Bild. Aktuelle automatische Methoden neigen dazu, alle hervorstechenden Objekte in einem Bild wahllos zu extrahieren. In diesem Artikel schlägt der Autor eine neue Aufgabe namens Reference Image Matting (RIM) vor, die sich auf die Extraktion detaillierter Alpha-Mattierungen eines bestimmten Objekts bezieht, die einer bestimmten Beschreibung in natürlicher Sprache am besten entsprechen können. Allerdings sind gängige visuelle Erdungsmethoden auf die Segmentierungsebene beschränkt, wahrscheinlich aufgrund des Mangels an qualitativ hochwertigen RIM-Datensätzen. Um diese Lücke zu schließen, erstellten die Autoren RefMatte, den ersten groß angelegten anspruchsvollen Datensatz, indem sie eine umfassende Bildsynthese- und Ausdrucksgenerierungs-Engine entwickelten, um synthetische Bilder basierend auf den aktuellen öffentlichen Mattierungsaussichten von hoher Qualität mit Flexibilitätslogik und neu gekennzeichneten diversifizierten Eigenschaften zu generieren .
RefMatte besteht aus 230 Objektkategorien, 47.500 Bildern, 118.749 Ausdrucksbereichseinheiten und 474.996 Ausdrücken und kann in Zukunft problemlos weiter erweitert werden. Darüber hinaus erstellten die Autoren mithilfe künstlich generierter Phrasenanmerkungen einen realen Testsatz bestehend aus 100 natürlichen Bildern, um die Generalisierungsfähigkeit des RIM-Modells weiter zu bewerten. Zuerst wurden RIM-Aufgaben in zwei Kontexten definiert, auf Eingabeaufforderungen basierend und ausdrucksbasiert, und dann wurden mehrere typische Bildmattierungsmethoden und spezifische Modelldesigns getestet. Diese Ergebnisse liefern empirische Einblicke in die Grenzen bestehender Methoden sowie mögliche Lösungen. Es wird davon ausgegangen, dass die neue Aufgabe RIM und der neue Datensatz RefMatte neue Forschungsrichtungen in diesem Bereich eröffnen und die zukünftige Forschung vorantreiben werden.

Papiertitel: Referring Image Matting
Papieradresse: https://arxiv.org/abs/2206.0514 9
Codeadresse: https://github.com/JizhiziLi/RI M
1
Bildmattierung bezieht sich auf das Extrahieren einer weichen Ahpha-Mattierung des Vordergrunds in natürlichen Bildern, was für verschiedene nachgelagerte Anwendungen wie Videokonferenzen, Werbeproduktion und E-Commerce-Promotion von Vorteil ist. Typische Mattierungsmethoden können in zwei Gruppen unterteilt werden: 1) auf Hilfseingaben basierende Methoden wie Trimap und 2) automatische Mattierungsmethoden, die den Vordergrund ohne manuellen Eingriff extrahieren. Ersteres eignet sich jedoch nicht für automatische Anwendungsszenarien und letzteres ist im Allgemeinen auf bestimmte Objektkategorien wie Menschen, Tiere oder alle wichtigen Objekte beschränkt. Wie eine steuerbare Bildmattierung beliebiger Objekte durchgeführt werden kann, d. h. die Alpha-Mattierung eines bestimmten Objekts zu extrahieren, die am besten zu einer gegebenen Beschreibung in natürlicher Sprache passt, ist immer noch ein zu erforschendes Problem.
Sprachgesteuerte Aufgaben wie verweisende Ausdruckssegmentierung (RES), verweisende Bildsegmentierung (RIS), visuelle Fragebeantwortung (VQA) und verweisendes Ausdrucksverständnis (REC) wurden ausführlich erforscht. In diesen Bereichen wurden auf der Grundlage zahlreicher Datensätze wie ReferIt, Google RefExp, RefCOCO, VGPhraseCut und Cops-Ref große Fortschritte erzielt. Beispielsweise zielen RES-Methoden darauf ab, beliebige Objekte zu segmentieren, die durch Beschreibungen in natürlicher Sprache angegeben werden. Allerdings sind die erhaltenen Masken aufgrund von Bildern mit niedriger Auflösung und groben Maskenanmerkungen im Datensatz auf Segmentierungsebenen ohne feine Details beschränkt. Daher ist es unwahrscheinlich, dass sie in Szenen verwendet werden, die eine detaillierte Alpha-Mattierung von Vordergrundobjekten erfordern.

Um diese Lücke zu schließen, schlägt der Autor in diesem Artikel eine neue Aufgabe namens „Referring Image Matting (RIM)“ vor. RIM bezieht sich auf die Extraktion spezifischer Vordergrundobjekte in einem Bild, die am besten zu einer bestimmten Beschreibung in natürlicher Sprache passen, zusammen mit detaillierter, hochwertiger Alpha-Mattierung. Anders als die Aufgaben, die durch die beiden oben genannten Mattierungsmethoden gelöst werden, zielt RIM auf eine kontrollierbare Bildmattierung beliebiger Objekte im Bild ab, die durch die sprachliche Beschreibung angegeben werden. Es hat praktische Bedeutung im Bereich industrieller Anwendungen und eröffnet neue Forschungsrichtungen für die Wissenschaft.
Um die RIM-Forschung voranzutreiben, hat der Autor den ersten Datensatz namens RefMatte erstellt, der aus 230 Objektkategorien, 47.500 Bildern und 118.749 Ausdrucksbereichseinheiten sowie der entsprechenden hochwertigen Alpha-Matte und 474.996 Ausdruckszusammensetzung besteht.
Um diesen Datensatz zu erstellen, hat der Autor zunächst viele beliebte öffentliche Mattierungsdatensätze wie AM-2k, P3M-10k, AIM-500 und SIM erneut überprüft und jedes Objekt sorgfältig untersucht, indem er es manuell beschriftet hat. Die Autoren verwenden außerdem mehrere vorab trainierte Deep-Learning-Modelle, um verschiedene Attribute für jede Entität zu generieren, wie z. B. menschliches Geschlecht, Alter und Kleidungstyp. Anschließend entwerfen die Autoren eine umfassende Kompositions- und Ausdrucksgenerierungs-Engine, um zusammengesetzte Bilder mit angemessenen absoluten und relativen Positionen zu erzeugen und dabei andere Vordergrundobjekte zu berücksichtigen. Abschließend schlägt der Autor mehrere Ausdruckslogikformen vor, die umfangreiche visuelle Attribute nutzen, um verschiedene Sprachbeschreibungen zu generieren. Darüber hinaus schlagen die Autoren einen realen Testsatz RefMatte-RW100 vor, der 100 Bilder mit verschiedenen Objekten und von Menschen kommentierten Ausdrücken enthält, um die Generalisierungsfähigkeit der RIM-Methode zu bewerten. Das Bild oben zeigt einige Beispiele.
Um eine faire und umfassende Bewertung der State-of-the-Art-Methoden in verwandten Aufgaben durchzuführen, vergleichen die Autoren sie auf RefMatte in zwei verschiedenen Einstellungen in Form von Sprachbeschreibungen, nämlich einer hinweisbasierten Einstellung und ein ausdrucksbasiertes Setup. Da repräsentative Methoden speziell für Segmentierungsaufgaben konzipiert sind, besteht noch eine Lücke bei der direkten Anwendung auf RIM-Aufgaben.
Um dieses Problem zu lösen, schlug der Autor zwei Strategien zur Anpassung an RIM vor, nämlich 1) sorgfältig einen leichtgewichtigen Cutout-Header namens CLIPmat auf CLIPSeg zu entwerfen, um hochauflösende Grafiken in Alpha zu generieren Mattierungsergebnisse unter Beibehaltung der durchgängig trainierbaren Pipeline. 2) Mehrere separate grobe bildbasierte Mattierungsmethoden werden als Nachverfeinerer bereitgestellt, um die Segmentierungs-/Mattierungsergebnisse weiter zu verbessern. Umfangreiche experimentelle Ergebnisse 1) zeigen den Wert des vorgeschlagenen RefMatte-Datensatzes für die RIM-Aufgabenforschung, 2) identifizieren die wichtige Rolle der Form der Sprachbeschreibung 3) validieren die Wirksamkeit der vorgeschlagenen Anpassungsstrategie;
Die Hauptbeiträge dieser Studie sind dreifach. 1) Definieren Sie eine neue Aufgabe namens RIM, die darauf abzielt, Alpha-Matten bestimmter Vordergrundobjekte zu identifizieren und zu extrahieren, die am besten zu einer bestimmten Beschreibung in natürlicher Sprache passen. 2) Erstellen Sie den ersten großen Datensatz RefMatte, bestehend aus 47.500 Bildern und 118.749 Ausdrücken Regionsentitäten mit hochwertiger Alpha-Mattierung und reichhaltigem Ausdruck. 3) Repräsentative hochmoderne Methoden wurden in zwei verschiedenen Umgebungen mit zwei auf RIM zugeschnittenen Strategien für RefMatte getestet und konnten einige nützliche Erkenntnisse gewinnen.
2. Methode

In diesem Abschnitt wird die Konstruktion von RefMatte (Abschnitt 3.1 und Abschnitt 3.2) vorgestellt. Pipeline sowie Aufgabeneinstellungen (Abschnitt 3.3) und Statistiken des Datensatzes (Abschnitt 3.5). Das Bild oben zeigt einige Beispiele von RefMatte. Darüber hinaus erstellen die Autoren einen Testsatz aus der realen Welt, der aus 100 natürlichen Bildern besteht, die mit manuell beschrifteten ausführlichen Sprachbeschreibungen versehen sind (Abschnitt 3.4).
2.1 Vorbereitung von Matting-Entitäten
Um genügend hochwertige Matting-Entitäten vorzubereiten, die beim Aufbau des RefMatte-Datensatzes helfen, hat der Autor die derzeit verfügbaren Matting-Datensätze erneut überprüft, um Interessenten zu filtern Anforderungen erfüllen. Alle Kandidatenentitäten werden dann manuell mit ihren Kategorien gekennzeichnet und ihre Attribute werden mithilfe mehrerer vorab trainierter Deep-Learning-Modelle mit Anmerkungen versehen.
Vorverarbeitung und Filterung
Aufgrund der Art der Bildmattierungsaufgabe sollten alle Kandidatenentitäten hochauflösend und scharf sein und feine Details in Alpha-Ausschnitten. Darüber hinaus sollten Daten über offene Lizenzen und ohne Datenschutzbedenken öffentlich zugänglich sein, um zukünftige Forschung zu erleichtern. Für diese Anforderungen verwendeten die Autoren alle Vordergrundbilder von AM-2k, P3M-10k und AIM-500. Insbesondere für P3M-10k filtern die Autoren Bilder mit mehr als zwei Sticky-Vordergrundinstanzen heraus, um sicherzustellen, dass jede Entität nur einer Vordergrundinstanz zugeordnet ist. Für andere verfügbare Datensätze wie SIM, DIM und HATT filtern die Autoren die Vordergrundbilder mit identifizierbaren Gesichtern unter den menschlichen Instanzen heraus. Die Autoren filtern auch Vordergrundbilder heraus, die eine niedrige Auflösung haben oder eine Alpha-Mattierung von geringer Qualität aufweisen. Die endgültige Gesamtzahl der Unternehmen betrug 13.187. Als Hintergrundbilder für die nachfolgenden Syntheseschritte wählten die Autoren alle Bilder in BG-20k aus. Kommentieren Sie die Kategorienamen von Entitäten. Daher stellen sie keinen spezifischen (Kategorie-)Namen für jede Entität bereit. Für RIM-Aufgaben ist jedoch der Entitätsname zur Beschreibung erforderlich. Die Autoren haben jede Entität mit einem Kategorienamen auf Einstiegsebene gekennzeichnet, der den am häufigsten verwendeten Namen für eine bestimmte Entität darstellt. Hierbei kommt eine halbautomatische Strategie zum Einsatz. Konkret verwenden die Autoren einen Mask RCNN-Detektor mit einem ResNet-50-FPN-Backbone, um den Klassennamen jeder Vordergrundinstanz automatisch zu erkennen und zu kennzeichnen und sie dann manuell zu überprüfen und zu korrigieren. RefMatte hat insgesamt 230 Kategorien. Darüber hinaus nutzen die Autoren WordNet, um Synonyme für jeden Kategorienamen zu generieren und so die Vielfalt zu erhöhen. Die Autoren haben die Synonyme manuell überprüft und einige davon durch sinnvollere Synonyme ersetzt.
Annotieren Sie die Attribute von Entitäten
Um sicherzustellen, dass alle Entitäten über reichhaltige visuelle Attribute verfügen, um die Bildung reichhaltiger Ausdrücke zu unterstützen, ist der Autor alles Entitäten Verschiedene Attribute wie Farbe, Geschlecht, Alter und Kleidungstyp der menschlichen Entität werden mit Anmerkungen versehen. Die Autoren verwenden auch eine halbautomatische Strategie, um solche Eigenschaften zu generieren. Um Farben zu erzeugen, gruppieren die Autoren alle Pixelwerte des Vordergrundbilds, finden die häufigsten Werte und ordnen sie bestimmten Farben in Webcolors zu. Für Geschlecht und Alter verwenden die Autoren vorab trainierte Modelle. Benutzen Sie Ihren gesunden Menschenverstand, um Altersgruppen basierend auf dem vorhergesagten Alter zu definieren. Für Kleidungstypen verwendet der Autor ein vorab trainiertes Modell. Darüber hinaus fügen die Autoren, inspiriert von der Vordergrundklassifizierung, allen Entitäten hervorstechende oder unbedeutende sowie transparente oder undurchsichtige Attribute hinzu, da diese Attribute auch bei Bildmattierungsaufgaben wichtig sind. Letztendlich verfügt jede Entität über mindestens drei Attribute und menschliche Entitäten über mindestens sechs Attribute.
2.2 Bildkomposition und Ausdrucksgenerierung
Basierend auf den im vorherigen Abschnitt gesammelten Ausschnittentitäten schlug der Autor eine Bildsynthese-Engine und eine Ausdrucksgenerierungs-Engine vor, um den RefMatte-Datensatz zu erstellen. Wie man verschiedene Entitäten anordnet, um vernünftige synthetische Bilder zu bilden, und gleichzeitig semantisch klare, grammatikalisch korrekte, reichhaltige und ausgefallene Ausdrücke generiert, um die Entitäten in diesen synthetischen Bildern zu beschreiben, ist der Schlüssel zum Aufbau von RefMatte und auch eine Herausforderung. Zu diesem Zweck definieren die Autoren sechs Positionsbeziehungen für die Anordnung verschiedener Entitäten in synthetischen Bildern und verwenden unterschiedliche logische Formen, um entsprechende Ausdrücke zu erzeugen.
Bildkompositions-Engine
Um die hohe Auflösung von Entitäten beizubehalten und sie gleichzeitig in einer angemessenen Positionsbeziehung anzuordnen, setzt der Autor Bilder für zusammen Jeder nimmt zwei oder drei Entitäten. Der Autor definiert sechs Positionsbeziehungen: links, rechts, oben, unten, vorne und hinten. Für jede Beziehung wurden zunächst Vordergrundbilder generiert und per Alpha-Blending mit dem Hintergrundbild des BG-20k zusammengesetzt. Insbesondere für die Links-, Rechts-, Oben- und Unten-Beziehungen stellen die Autoren sicher, dass es in den Vordergrundinstanzen keine Verdeckungen gibt, um deren Details beizubehalten. Bei Vorher-Nachher-Beziehungen wird die Okklusion zwischen Vordergrundinstanzen durch Anpassen ihrer relativen Positionen simuliert. Die Autoren bereiten einen Beutel mit Kandidatenwörtern vor, um jede Beziehung darzustellen.
Expression Generation Engine
Um reichhaltige Ausdrücke für Entitäten in synthetischen Bildern bereitzustellen, definiert der Autor verschiedene logische Formen aus der Perspektive von Each Die Entität definiert drei Ausdrücke, von denen 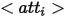 das Attribut darstellt,
das Attribut darstellt, 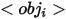 den Kategorienamen darstellt und
den Kategorienamen darstellt und 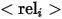 die Beziehung zwischen der Referenzentität und zugehörigen Entitäten darstellt. Beispiele für die drei Ausdrücke sind wie oben gezeigt ( dargestellt in a), (b) und (c).
die Beziehung zwischen der Referenzentität und zugehörigen Entitäten darstellt. Beispiele für die drei Ausdrücke sind wie oben gezeigt ( dargestellt in a), (b) und (c).
2.3 Datensatzaufteilung und Aufgabeneinstellungen
Datensatzaufteilung
Der Datensatz verfügt über insgesamt 13.187 Kartenelemente Davon werden 11.799 für den Aufbau des Trainingssatzes und 1.388 für den Testsatz verwendet. Allerdings sind die Kategorien der Trainings- und Testsätze nicht ausgewogen, da die meisten Entitäten zur Kategorie Mensch oder Tier gehören. Konkret gibt es unter den 11.799 Entitäten im Trainingssatz 9.186 Menschen, 1.800 Tiere und 813 Objekte. In der Testmenge von 1.388 Entitäten gibt es 977 Menschen, 200 Tiere und 211 Objekte. Um die Kategorien auszugleichen, replizierten die Autoren Entitäten, um ein Verhältnis von Mensch:Tier:Objekt von 5:1:1 zu erreichen. Daher enthält der Trainingssatz 10.550 Menschen, 2.110 Tiere und 2.110 Objekte und der Testsatz 1.055 Menschen, 211 Tiere und 211 Objekte.
Um Bilder für RefMatte zu generieren, wählen die Autoren einen Satz von 5 Menschen, 1 Tier und 1 Objekt aus einer Trainings- oder Testaufteilung aus und geben sie in eine Bildsynthese-Engine ein. Für jede Gruppe in der Trainings- oder Testaufteilung generierten die Autoren 20 Bilder zur Bildung des Trainingssatzes und 10 Bilder zur Bildung des Testsatzes. Das Verhältnis der Beziehung links/rechts:oben/unten:vorne/hinten ist auf 7:2:1 eingestellt. Die Anzahl der Elemente in jedem Bild ist auf 2 oder 3 festgelegt. Aus Kontextgründen wählen die Autoren immer zwei Entitäten aus, um für jede Entität eine hohe Auflösung beizubehalten. Nach diesem Vorgang liegen 42.200 Trainingsbilder und 2.110 Testbilder vor. Um die Vielfalt der Entitätskombinationen weiter zu erhöhen, wählen wir zufällig Entitäten und Beziehungen aus allen Kandidaten aus, um weitere 2800 Trainingsbilder und 390 Testbilder zu erstellen. Schließlich enthält der Trainingssatz 45.000 synthetische Bilder und der Testsatz 2.500 Bilder.
Aufgabeneinstellung
Um den RIM-Ansatz bei verschiedenen Formen der Sprachbeschreibung zu bewerten, haben die Autoren in RefMatte zwei Einstellungen festgelegt: #🎜 🎜#
Eingabeaufforderungsbasierte Einstellung: Die Textbeschreibung in dieser Einstellung ist der Eingabekategoriename der Entität. Die Eingabeaufforderungen im Bild oben sind beispielsweise Blume, Mensch, Alpaka; 🎜#Ausdrucksbasierte Einstellung: Die Textbeschreibung in dieser Einstellung ist der im vorherigen Abschnitt generierte Ausdruck, ausgedrückt aus Basisausdrücken und absoluten Positionen. Wählen Sie aus Ausdrücken und relativen Positionsausdrücken. Einige Beispiele sind auch im Bild oben zu sehen.
2.4 Testset aus der realen Welt
 Da RefMatte auf synthetischen Bildern basiert, sind sie mit denen aus der realen Welt identisch Zwischen den Bildern können Domänenlücken bestehen. Um die Generalisierungsfähigkeit des darauf trainierten RIM-Modells auf reale Bilder zu untersuchen, hat der Autor außerdem einen realen Testsatz namens RefMatte-RW100 erstellt, der aus 100 realen hochauflösenden Bildern besteht sind 2 bis 3 Einheiten in . Anschließend kommentieren die Autoren ihre Ausdrücke nach den gleichen drei Einstellungen in Abschnitt 3.2. Darüber hinaus hat der Autor der Anmerkung einen freien Ausdruck hinzugefügt. Für hochwertige Alpha-Ausschnitt-Tags generiert der Autor diese mithilfe von Bildbearbeitungsprogrammen wie Adobe Photoshop und GIMP. Einige Beispiele für RefMatte-RW100 sind oben dargestellt.
Da RefMatte auf synthetischen Bildern basiert, sind sie mit denen aus der realen Welt identisch Zwischen den Bildern können Domänenlücken bestehen. Um die Generalisierungsfähigkeit des darauf trainierten RIM-Modells auf reale Bilder zu untersuchen, hat der Autor außerdem einen realen Testsatz namens RefMatte-RW100 erstellt, der aus 100 realen hochauflösenden Bildern besteht sind 2 bis 3 Einheiten in . Anschließend kommentieren die Autoren ihre Ausdrücke nach den gleichen drei Einstellungen in Abschnitt 3.2. Darüber hinaus hat der Autor der Anmerkung einen freien Ausdruck hinzugefügt. Für hochwertige Alpha-Ausschnitt-Tags generiert der Autor diese mithilfe von Bildbearbeitungsprogrammen wie Adobe Photoshop und GIMP. Einige Beispiele für RefMatte-RW100 sind oben dargestellt.
2.5 Statistiken des RefMatte-Datensatzes und des RefMatte-RW100-Testsatzes
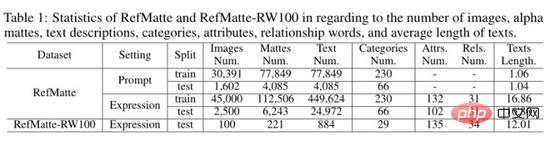
Der Autor hat die Statistiken des RefMatte-Datensatzes und des RefMatte-RW100-Testsatzes wie in der obigen Tabelle gezeigt berechnet. Bei der auf Eingabeaufforderungen basierenden Einstellung entfernen die Autoren Bilder mit mehreren Entitäten, die zur gleichen Kategorie gehören, da es sich bei den Textbeschreibungen um Kategorienamen auf Einstiegsebene handelt, um mehrdeutige Schlussfolgerungen zu vermeiden. Daher gibt es in dieser Einstellung 30.391 Bilder im Trainingssatz und 1.602 Bilder im Testsatz. Die Anzahl, Textbeschreibung, Kategorien, Attribute und Beziehungen der Alpha-Ausschnitte sind jeweils in der Tabelle oben aufgeführt. In der auf Eingabeaufforderungen basierenden Einstellung beträgt die durchschnittliche Textlänge etwa 1, da es normalerweise nur ein Wort pro Kategorie gibt, während sie in der ausdrucksbasierten Einstellung viel größer ist, d. h. etwa 16,8 in RefMatte und etwa 16,8 in RefMatte-RW100 12.

Der Autor hat im Bild oben auch eine Wortwolke aus Eingabeaufforderungen, Attributen und Beziehungen in RefMatte erstellt. Wie man sehen kann, enthält der Datensatz einen großen Anteil an Menschen und Tieren, da diese bei Bildmattierungsaufgaben sehr häufig vorkommen. Die häufigsten Attribute in RefMatte sind maskulin, grau, transparent und hervorstechend, während relationale Wörter ausgewogener sind.
3. Experiment
Aufgrund der Aufgabenunterschiede zwischen RIM und RIS/RES sind die Ergebnisse der direkten Anwendung der RIS/RES-Methode auf RIM nicht optimistisch. Um dieses Problem zu lösen, schlägt der Autor zwei Strategien vor, um sie für RIM anzupassen:
1) Mattierungsköpfe hinzufügen: Entwerfen Sie leichte Mattierungsköpfe auf vorhandenen Modellen, um hochwertige Alpha-Mattings zu generieren und gleichzeitig die Portabilität beizubehalten. Durchgängig trainierbare Pipeline . Konkret hat der Autor einen leichtgewichtigen Mattierungsdecoder namens CLIPMat entwickelt.
2) Verwendung von Matting Refiner: Der Autor verwendet eine separate Mattierungsmethode basierend auf groben Bildern als Post-Refiner, um die Segmentierungs-/Mattierungsergebnisse weiter zu verbessern der oben genannten Methoden. Insbesondere trainieren die Autoren GFM und P3M, indem sie Bilder und grobe Bilder als Ausschnittverfeinerer eingeben.
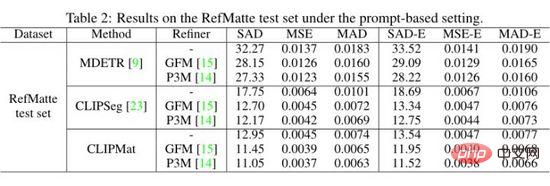
Die Autoren bewerten MDETR, CLIPSeg und CLIPMat anhand einer hinweisbasierten Einstellung auf dem RefMatte-Testsatz und zeigen die quantitativen Ergebnisse in der obigen Tabelle. Es ist ersichtlich, dass CLIPMat im Vergleich zu MDETR und CLIPSeg die beste Leistung erbringt, unabhängig davon, ob der Cutout-Refiner verwendet wird oder nicht. Überprüfen Sie die Wirksamkeit des Hinzufügens eines Cutout-Headers zum Anpassen von CLIPSeg für RIM-Aufgaben. Darüber hinaus kann die Verwendung eines der beiden Cutout-Refiner die Leistung der drei Methoden weiter verbessern.
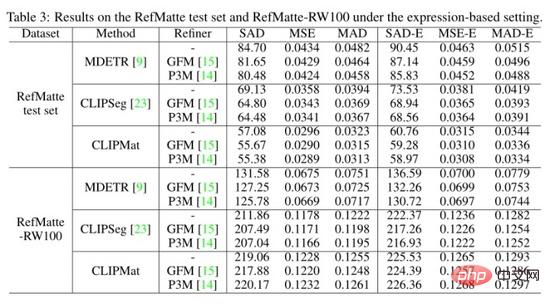
Die Autoren bewerteten auch die drei Methoden des RefMatte-Testsatzes und die ausdrucksbasierte Einstellung von RefMatte-RW100 und zeigen die quantitativen Ergebnisse in der obigen Tabelle. CLIPMat zeigt erneut eine gute Fähigkeit, mehr Details im RefMatte-Testsatz beizubehalten. Beim Test auf RefMatte-RW100 bleiben einstufige Methoden wie CLIPSeg und CLIPMat hinter der zweistufigen Methode MDETR zurück, möglicherweise aufgrund der besseren Fähigkeit der MDETR-Detektoren, die modalübergreifende Semantik zu verstehen.
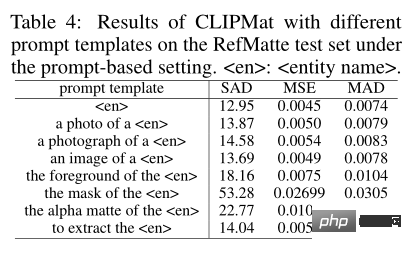
Um die Auswirkungen von Eingabeaufforderungsformularen zu untersuchen, bewerteten die Autoren die Leistung verschiedener Eingabeaufforderungsvorlagen. Zusätzlich zu den herkömmlichen Vorlagen hat der Autor auch weitere Vorlagen hinzugefügt, die speziell für Bildmattierungsaufgaben entwickelt wurden, wie z. B. die Vordergrund-/Masken-/Alpha-Matte von
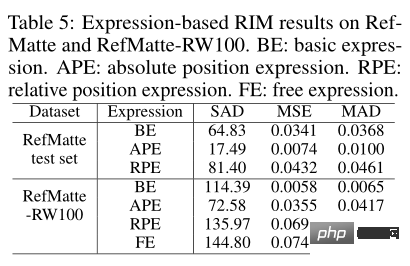
Da in diesem Artikel verschiedene Arten von Ausdrücken in der Aufgabe vorgestellt werden, können Sie die Auswirkungen jedes Typs auf die Ausschnittleistung sehen. Wie in der Tabelle oben gezeigt, wurde das Modell CLIPMat mit der besten Leistung auf dem RefMatte-Testset und das Modell MDETR auf RefMatte-RW100 getestet.
4. Zusammenfassung
In diesem Artikel schlagen wir eine neue Aufgabe namens Reference Image Matting (RIM) vor und erstellen einen großen Datensatz RefMatte. Die Autoren passen bestehende repräsentative Methoden auf relevante Aufgaben von RIM an und messen ihre Leistung durch umfangreiche Experimente auf RefMatte. Die experimentellen Ergebnisse dieser Arbeit liefern nützliche Einblicke in das Modelldesign, die Auswirkungen von Textbeschreibungen und die Domänenlücke zwischen synthetischen und realen Bildern. Die RIM-Forschung kann vielen praktischen Anwendungen wie der interaktiven Bildbearbeitung und der Mensch-Computer-Interaktion zugute kommen. RefMatte kann die Forschung in diesem Bereich erleichtern. Die Lücke zwischen der synthetischen und der realen Domäne kann jedoch zu einer eingeschränkten Verallgemeinerung auf Bilder aus der realen Welt führen.
Das obige ist der detaillierte Inhalt vonDeep Learning hat eine neue Gefahr! Die University of Sydney schlägt eine neue modalübergreifende Aufgabe vor, bei der Text als Leitfaden für den Bildausschnitt verwendet wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
