
 Technologie-Peripheriegeräte
KI
Der Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!
Technologie-Peripheriegeräte
KI
Der Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!
Der Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!

Der Appetit der KI ist zu groß und die Daten des menschlichen Korpus reichen nicht mehr aus.
Eine neue Arbeit des Epoch-Teams zeigt, dass KI in weniger als 5 Jahren den gesamten hochwertigen Korpus verbrauchen wird.

Sie müssen wissen, dass dies ein vorhergesagtes Ergebnis ist, das die Wachstumsrate menschlicher Sprachdaten berücksichtigt. Mit anderen Worten, selbst wenn alle neuen Papiere und Codes, die in den letzten Jahren von Menschen geschrieben wurden, der KI zugeführt werden, es wird nicht reichen.
Wenn diese Entwicklung anhält, werden große Sprachmodelle, die auf qualitativ hochwertige Daten angewiesen sind, um ihr Niveau zu verbessern, bald mit einem Engpass konfrontiert sein.
Einige Internetnutzer können bereits nicht still sitzen:
Das ist so lächerlich. Menschen können sich effektiv trainieren, ohne alles im Internet zu lesen.
Wir brauchen bessere Modelle, nicht mehr Daten.
Einige Internetnutzer machten sich darüber lustig, dass es besser sei, die KI fressen zu lassen, was sie ausspuckt:
Sie können den von der KI selbst generierten Text als minderwertige Daten an die KI weiterleiten.

Werfen wir einen Blick darauf, wie viele Daten von Menschen hinterlassen werden?
Wie wäre es mit der „Bestandsaufnahme“ von Text- und Bilddaten?
Das Papier sagt hauptsächlich Text- und Bilddaten voraus.
Zuerst sind die Textdaten.
Die Qualität der Daten reicht normalerweise von gut bis schlecht. Die Autoren haben die verfügbaren Textdaten basierend auf den Datentypen, die von vorhandenen großen Modellen und anderen Daten verwendet werden, in Teile mit geringer Qualität und in Teile mit hoher Qualität unterteilt.
Hochwertiger Korpus bezieht sich auf die Trainingsdatensätze, die von großen Sprachmodellen wie Pile, PaLM und MassiveText verwendet werden, einschließlich Wikipedia, Nachrichten, Codes auf GitHub, veröffentlichten Büchern usw.
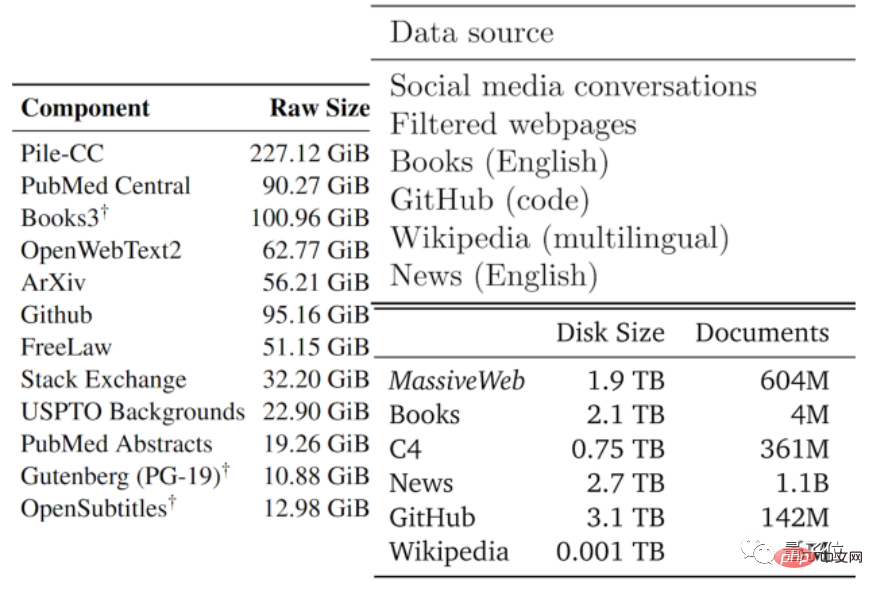
Korpus von geringer Qualität stammt aus Tweets in sozialen Medien wie Reddit und inoffizieller Fanfiction (Fanfic).
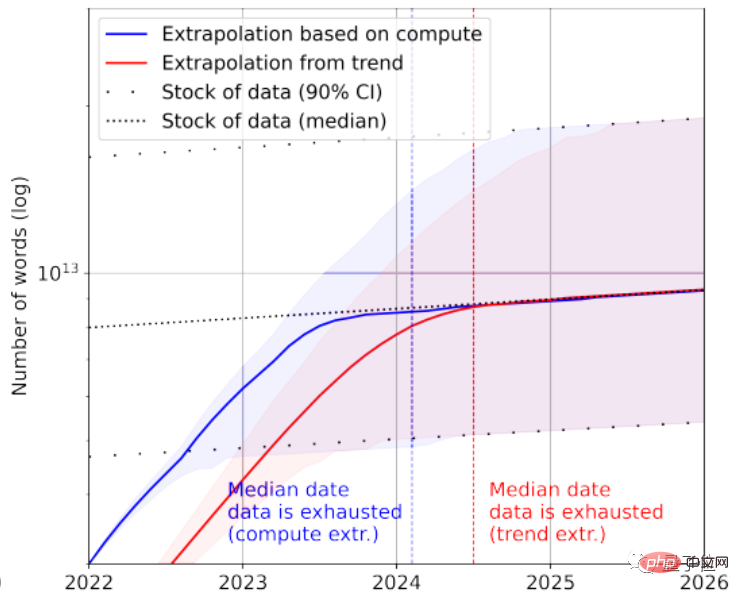
Statistik zufolge gibt es im hochwertigen Sprachdatenbestand nur noch etwa 4,6×10^12~1,7×10^13 Wörter, was weniger als eine Größenordnung größer ist als der derzeit größte Textdatensatz.
In Kombination mit der Wachstumsrate prognostiziert das Papier, dass hochwertige Textdaten zwischen 2023 und 2027 durch KI erschöpft sein werden und der geschätzte Knoten bei etwa 2026 liegt.
Es scheint ein bisschen schnell zu sein...
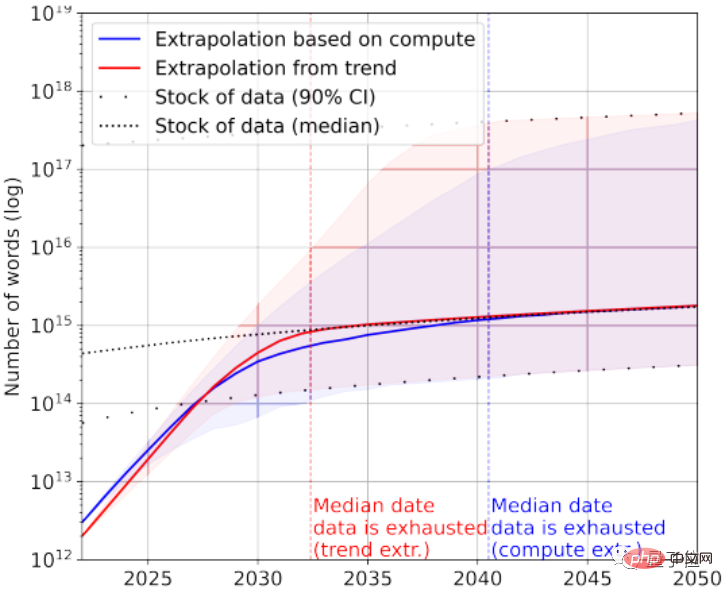
Natürlich können zur Rettung auch Textdaten von geringer Qualität hinzugefügt werden. Laut Statistik sind derzeit noch 7×10^13~7×10^16 Wörter im Gesamtbestand an Textdaten übrig, was 1,5–4,5 Größenordnungen größer ist als der größte Datensatz.
Wenn die Anforderungen an die Datenqualität nicht hoch sind, wird die KI zwischen 2030 und 2050 alle Textdaten verbrauchen.
Wenn man sich die Bilddaten noch einmal ansieht, unterscheidet das Papier hier nicht zwischen Bildqualität.
Der größte Bilddatensatz umfasst derzeit 3×10^9 Bilder.
Laut Statistik beträgt die aktuelle Gesamtzahl der Bilder etwa 8,11×10^12~2,3×10^13, was 3~4 Größenordnungen größer ist als der größte Bilddatensatz.
Das Papier prognostiziert, dass der KI zwischen 2030 und 2070 diese Bilder ausgehen werden.
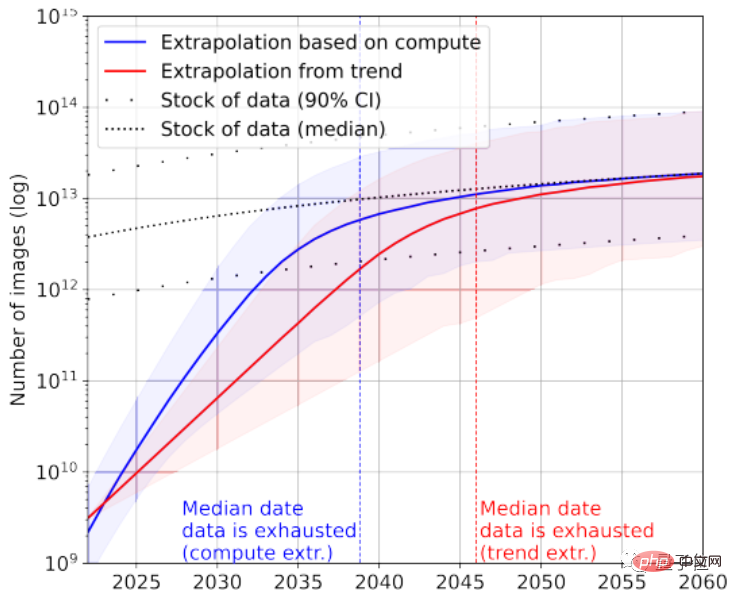
Offensichtlich sind große Sprachmodelle mit einer schwerwiegenderen Situation des „Datenmangels“ konfrontiert als Bildmodelle.
Wie kam man also zu dieser Schlussfolgerung?
Berechnen Sie die durchschnittliche tägliche Anzahl der von Internetnutzern geposteten Beiträge.
Der Artikel analysiert die Effizienz der Textbilddatengenerierung und das Wachstum des Trainingsdatensatzes aus zwei Perspektiven.
Es ist erwähnenswert, dass es sich bei den Statistiken im Papier nicht ausschließlich um gekennzeichnete Daten handelt. Da unbeaufsichtigtes Lernen relativ beliebt ist, sind auch unbeschriftete Daten enthalten.
Nehmen Sie als Beispiel Textdaten. Die meisten Daten werden von sozialen Plattformen, Blogs und Foren generiert.
Um die Geschwindigkeit der Textdatengenerierung abzuschätzen, müssen drei Faktoren berücksichtigt werden, nämlich die Gesamtbevölkerung, die Internetdurchdringungsrate und die durchschnittliche Datenmenge, die von Internetnutzern generiert wird.
Dies ist beispielsweise der geschätzte zukünftige Bevölkerungs- und Internetnutzerwachstumstrend basierend auf historischen Bevölkerungsdaten und der Anzahl der Internetnutzer:
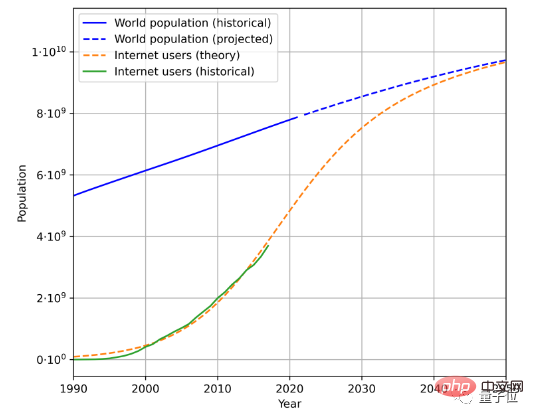
In Kombination mit der durchschnittlichen Datenmenge, die von Benutzern generiert wird, kann die Datengenerierungsrate ermittelt werden berechnet werden. (Aufgrund komplexer geografischer und zeitlicher Änderungen vereinfacht das Papier die Berechnungsmethode für die durchschnittliche Datenmenge, die von Benutzern generiert wird.)
Nach dieser Methode wird berechnet, dass die Wachstumsrate der Sprachdaten etwa 7 % beträgt, aber dieses Wachstum Die Rate wird mit der Zeit allmählich sinken.
Es wird erwartet, dass die Wachstumsrate unserer Sprachdaten bis zum Jahr 2100 auf 1 % sinken wird.
Eine ähnliche Methode wird zur Analyse von Bilddaten verwendet. Die Wachstumsrate der Bilddaten wird sich jedoch bis 2100 ebenfalls auf etwa 1 % verlangsamen.
Das Papier geht davon aus, dass, wenn die Datenwachstumsrate nicht signifikant ansteigt oder neue Datenquellen entstehen, sei es ein großes Bild- oder Textmodell, das mit hochwertigen Daten trainiert wird, dies zu einem bestimmten Zeitpunkt zu einem Engpass führen kann.
Einige Internetnutzer scherzten darüber, und in Zukunft könnte so etwas wie eine Science-Fiction-Geschichte passieren:
Um KI zu trainieren, haben Menschen groß angelegte Projekte zur Textgenerierung gestartet, und alle arbeiten hart daran, Dinge für KI zu schreiben.
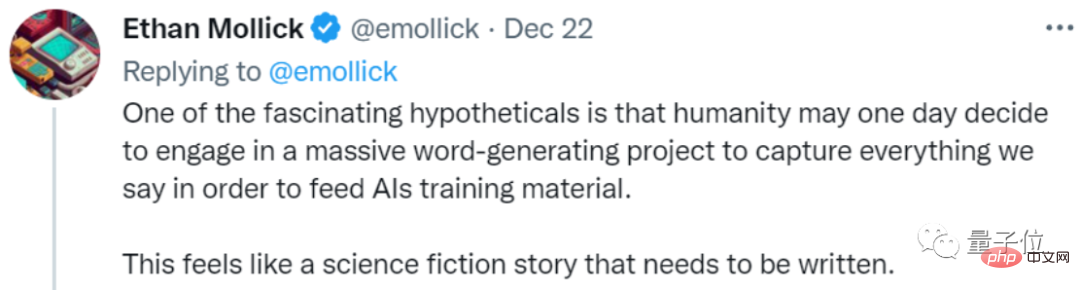
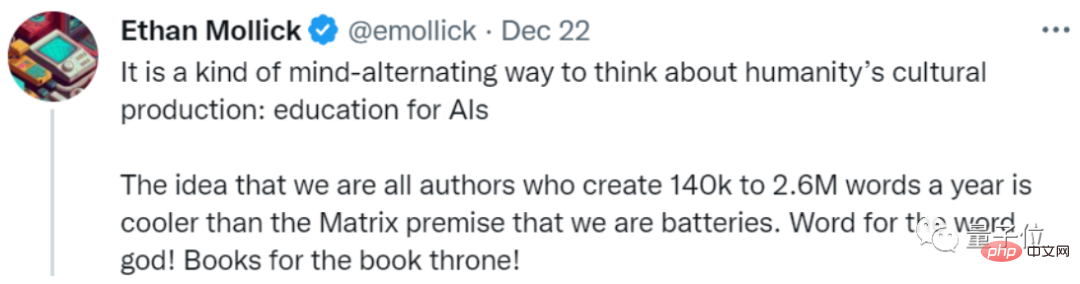
Er nennt es eine Art „Erziehung für KI“:
Wir senden jedes Jahr 140.000 bis 2,6 Millionen Wörter an Textdaten an die KI. Klingt das cooler, als Menschen als Batterien zu verwenden?
Was meint ihr?
Papieradresse: https://arxiv.org/abs/2211.04325
Referenzlink: https://twitter.com/emollick/status/1605756428941246466
Das obige ist der detaillierte Inhalt vonDer Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1387
1387
 52
52

 Teilen Sie eine einfache Möglichkeit zum Paketieren von PyCharm-Projekten
Dec 30, 2023 am 09:34 AM
Teilen Sie eine einfache Möglichkeit zum Paketieren von PyCharm-Projekten
Dec 30, 2023 am 09:34 AM
Teilen Sie die einfache und leicht verständliche PyCharm-Projektpaketierungsmethode. Mit der Popularität von Python verwenden immer mehr Entwickler PyCharm als Hauptwerkzeug für die Python-Entwicklung. PyCharm ist eine leistungsstarke integrierte Entwicklungsumgebung, die viele praktische Funktionen bietet, die uns helfen, die Entwicklungseffizienz zu verbessern. Eine der wichtigen Funktionen ist die Projektverpackung. In diesem Artikel wird auf einfache und leicht verständliche Weise vorgestellt, wie Projekte in PyCharm verpackt werden, und es werden spezifische Codebeispiele bereitgestellt. Warum Paketprojekte? Entwickelt in Python
 Kann KI Fermats letzten Satz überwinden? Der Mathematiker gab fünf Jahre seiner Karriere auf, um 100 Beweisseiten in Code umzuwandeln
Apr 09, 2024 pm 03:20 PM
Kann KI Fermats letzten Satz überwinden? Der Mathematiker gab fünf Jahre seiner Karriere auf, um 100 Beweisseiten in Code umzuwandeln
Apr 09, 2024 pm 03:20 PM
Fermats letzter Satz steht kurz davor, von der KI erobert zu werden? Und das Bedeutsamste an der ganzen Sache ist, dass der letzte Satz von Fermat, den die KI gerade lösen wird, genau dazu dient, zu beweisen, dass KI nutzlos ist. Früher gehörte die Mathematik zum Bereich der reinen menschlichen Intelligenz; heute wird dieses Gebiet von fortschrittlichen Algorithmen entschlüsselt und mit Füßen getreten. Bild Der letzte Satz von Fermat ist ein „berüchtigtes“ Rätsel, das Mathematikern seit Jahrhunderten Rätsel aufgibt. Es wurde 1993 bewiesen, und jetzt haben Mathematiker einen großen Plan: den Beweis mithilfe von Computern nachzubilden. Sie hoffen, dass etwaige logische Fehler in dieser Version des Beweises durch einen Computer überprüft werden können. Projektadresse: https://github.com/riccardobrasca/flt
 Quantilregression für probabilistische Zeitreihenprognosen
May 07, 2024 pm 05:04 PM
Quantilregression für probabilistische Zeitreihenprognosen
May 07, 2024 pm 05:04 PM
Ändern Sie nicht die Bedeutung des ursprünglichen Inhalts, optimieren Sie den Inhalt nicht, schreiben Sie den Inhalt neu und fahren Sie nicht fort. „Die Quantilregression erfüllt diesen Bedarf, indem sie Vorhersageintervalle mit quantifizierten Chancen bereitstellt. Dabei handelt es sich um eine statistische Technik zur Modellierung der Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen, insbesondere wenn die bedingte Verteilung der Antwortvariablen von Interesse ist. Im Gegensatz zur herkömmlichen Regression Methoden: Die Quantilregression konzentriert sich auf die Schätzung der bedingten Größe der Antwortvariablen und nicht auf den bedingten Mittelwert Quantile der erklärten Variablen Y. Das bestehende Regressionsmodell ist eigentlich eine Methode zur Untersuchung der Beziehung zwischen der erklärten Variablen und der erklärenden Variablen. Sie konzentrieren sich auf die Beziehung zwischen erklärenden Variablen und erklärten Variablen
 Ein genauerer Blick auf PyCharm: eine schnelle Möglichkeit, Projekte zu löschen
Feb 26, 2024 pm 04:21 PM
Ein genauerer Blick auf PyCharm: eine schnelle Möglichkeit, Projekte zu löschen
Feb 26, 2024 pm 04:21 PM
Titel: Erfahren Sie mehr über PyCharm: Eine effiziente Möglichkeit, Projekte zu löschen. In den letzten Jahren wurde Python als leistungsstarke und flexible Programmiersprache von immer mehr Entwicklern bevorzugt. Bei der Entwicklung von Python-Projekten ist es entscheidend, eine effiziente integrierte Entwicklungsumgebung zu wählen. Als leistungsstarke integrierte Entwicklungsumgebung stellt PyCharm Python-Entwicklern viele praktische Funktionen und Tools zur Verfügung, darunter das schnelle und effiziente Löschen von Projektverzeichnissen. Im Folgenden konzentrieren wir uns auf die Verwendung von delete in PyCharm
 Praktische Tipps für PyCharm: Konvertieren Sie ein Projekt in eine ausführbare EXE-Datei
Feb 23, 2024 am 09:33 AM
Praktische Tipps für PyCharm: Konvertieren Sie ein Projekt in eine ausführbare EXE-Datei
Feb 23, 2024 am 09:33 AM
PyCharm ist eine leistungsstarke integrierte Python-Entwicklungsumgebung, die eine Fülle von Entwicklungstools und Umgebungskonfigurationen bietet und es Entwicklern ermöglicht, Code effizienter zu schreiben und zu debuggen. Bei der Verwendung von PyCharm für die Python-Projektentwicklung müssen wir manchmal das Projekt in eine ausführbare EXE-Datei packen, um es auf einem Computer auszuführen, auf dem keine Python-Umgebung installiert ist. In diesem Artikel wird erläutert, wie Sie mit PyCharm ein Projekt in eine ausführbare EXE-Datei konvertieren, und es werden spezifische Codebeispiele aufgeführt. Kopf
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
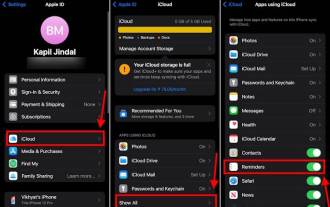 So erstellen Sie eine Einkaufsliste in der iOS 17-Erinnerungs-App auf dem iPhone
Sep 21, 2023 pm 06:41 PM
So erstellen Sie eine Einkaufsliste in der iOS 17-Erinnerungs-App auf dem iPhone
Sep 21, 2023 pm 06:41 PM
So erstellen Sie eine Einkaufsliste auf dem iPhone in iOS17. Das Erstellen einer Einkaufsliste in der Erinnerungen-App ist sehr einfach. Sie fügen einfach eine Liste hinzu und füllen sie mit Ihren Artikeln. Die App sortiert Ihre Artikel automatisch in Kategorien und Sie können sogar mit Ihrem Partner oder Ihrer Wohnungspartnerin zusammenarbeiten, um eine Liste der Dinge zu erstellen, die Sie im Geschäft kaufen müssen. Hier sind die vollständigen Schritte dazu: Schritt 1: iCloud-Erinnerungen aktivieren So seltsam es auch klingen mag, Apple sagt, dass Sie Erinnerungen von iCloud aktivieren müssen, um eine Einkaufsliste unter iOS17 zu erstellen. Hier sind die Schritte dafür: Gehen Sie zur App „Einstellungen“ auf Ihrem iPhone und tippen Sie auf [Ihr Name]. Wählen Sie als Nächstes i aus
 Wie verwende ich die MySQL-Datenbank für Prognosen und prädiktive Analysen?
Jul 12, 2023 pm 08:43 PM
Wie verwende ich die MySQL-Datenbank für Prognosen und prädiktive Analysen?
Jul 12, 2023 pm 08:43 PM
Wie verwende ich die MySQL-Datenbank für Prognosen und prädiktive Analysen? Überblick: Prognosen und prädiktive Analysen spielen eine wichtige Rolle in der Datenanalyse. MySQL, ein weit verbreitetes relationales Datenbankverwaltungssystem, kann auch für Vorhersage- und prädiktive Analyseaufgaben verwendet werden. In diesem Artikel wird die Verwendung von MySQL für Vorhersagen und Vorhersageanalysen vorgestellt und relevante Codebeispiele bereitgestellt. Datenaufbereitung: Zunächst müssen wir relevante Daten aufbereiten. Angenommen, wir möchten Verkaufsprognosen erstellen, benötigen wir eine Tabelle mit Verkaufsdaten. In MySQL können wir verwenden
