
 Technologie-Peripheriegeräte
KI
Gemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |
Technologie-Peripheriegeräte
KI
Gemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |
Gemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |

Aufgabenuniversalität ist eines der Kernziele der grundlegenden Modellforschung und auch die einzige Möglichkeit für die Deep-Learning-Forschung, zu fortgeschrittener Intelligenz zu führen. Dank der universellen Schlüsselmodellierungsfähigkeiten des Aufmerksamkeitsmechanismus hat Transformer in den letzten Jahren in vielen Bereichen gute Leistungen erbracht und nach und nach einen Trend zur universellen Architektur gezeigt. Mit zunehmender Länge der Sequenz weist die Berechnung des Standardaufmerksamkeitsmechanismus jedoch eine quadratische Komplexität auf, was seine Anwendung bei der Modellierung langer Sequenzen und großen Modellen erheblich behindert.
Zu diesem Zweck hat ein Team der School of Software der Tsinghua-Universität dieses Schlüsselproblem eingehend untersucht und einen aufgabenuniversellen linearen Komplexitäts-Backbone-Netzwerk-Flowformer vorgeschlagen, der seine Komplexität auf den Standard-Transformer reduziert und gleichzeitig seine Vielseitigkeit beibehält. Das Papier wurde vom ICML 2022 angenommen.

Autorenliste: Wu Haixu, Wu Jialong,
Code: https://github.com/thuml/FlowformerIm Vergleich zum Standardtransformer weist das in diesem Artikel vorgeschlagene Flowformer-Modell die folgenden Eigenschaften auf:
Lineare Komplexität
und kann Behandeln Sie Eingaben mit Tausenden von Sequenzlängen.
- führt keine neuen Induktionspräferenzen ein und behält die universelle Modellierungsfähigkeit des ursprünglichen Aufmerksamkeitsmechanismus bei Sprache, Zeitreihen, Reinforcement Learning
- erzielt hervorragende Ergebnisse bei fünf Hauptaufgaben. 1. Problemanalyse
- Die Standardeingabe des Aufmerksamkeitsmechanismus enthält drei Teile: Abfragen (), Schlüssel () und Werte (). Die Berechnungsmethode lautet wie folgt: Wo ist die Aufmerksamkeitsgewichtsmatrix und das Finale? Das Berechnungsergebnis wird aus der gewichteten Fusion erhalten, und die Rechenkomplexität des obigen Prozesses beträgt. Es wird darauf hingewiesen, dass es viele Studien zum Problem der kontinuierlichen Multiplikation multinomialer Matrizen in klassischen Algorithmen gibt. Insbesondere für den Aufmerksamkeitsmechanismus können wir das assoziative Gesetz der Matrixmultiplikation verwenden, um eine Optimierung zu erreichen. Beispielsweise kann die ursprüngliche quadratische Komplexität auf linear reduziert werden. Die Funktion im Aufmerksamkeitsmechanismus macht es jedoch unmöglich, das Assoziativgesetz direkt anzuwenden. Daher ist das Entfernen von Funktionen im Aufmerksamkeitsmechanismus der Schlüssel zum Erreichen linearer Komplexität. Viele neuere Arbeiten haben jedoch gezeigt, dass Funktionen eine Schlüsselrolle bei der Vermeidung trivialer Aufmerksamkeitslernen spielen. Zusammenfassend freuen wir uns auf eine Modelldesignlösung, die die folgenden Ziele erreicht: (1) Funktionen entfernen; (2) triviale Aufmerksamkeit vermeiden; (3) die Vielseitigkeit des Modells beibehalten; 2. Motivation
- Um Ziel (1) zu erreichen, wurde in früheren Arbeiten häufig die Kernelmethode verwendet, um die Funktion zu ersetzen, d wird triviale Aufmerksamkeit erregen. Zu diesem Zweck mussten in früheren Arbeiten für Ziel (2) einige induktive Präferenzen eingeführt werden, die die Vielseitigkeit des Modells einschränkten und daher Ziel (3) nicht erfüllten, wie beispielsweise die Lokalitätsannahme in cosFormer. Wettbewerbsmechanismus in Softmax
Um die oben genannten Ziele zu erreichen, gehen wir von den grundlegenden Eigenschaften der Analyse aus. Wir weisen darauf hin, dass ursprünglich vorgeschlagen wurde, die maximale Operation „Winner-take-all“ in eine differenzierbare Form zu erweitern. Daher
Dank seines inhärenten „Konkurrenz“-Mechanismus kann es die Aufmerksamkeitsgewichte zwischen Token unterscheiden und so gewöhnliche Aufmerksamkeitsprobleme vermeiden.Basierend auf den obigen Überlegungen versuchen wir, den Wettbewerbsmechanismus in das Design des Aufmerksamkeitsmechanismus einzuführen, um triviale Aufmerksamkeitsprobleme zu vermeiden, die durch die Zerlegung der Kernelmethode verursacht werden.
Wettbewerbsmechanismus im NetzwerkflussWir achten auf das klassische Netzwerkflussmodell (Flow Network) in der Graphentheorie. „Erhaltung“(Erhaltung) ist ein wichtiges Phänomen, das heißt, der Zufluss jedes Knotens ist gleich zum Abfluss. Inspiriert von „Bei festen Ressourcen wird es zwangsläufig zu Konkurrenz kommen“ versuchen wir in diesem Artikel, den Informationsfluss im klassischen Aufmerksamkeitsmechanismus aus der Perspektive des Netzwerkflusses erneut zu analysieren und Wettbewerb in den Aufmerksamkeitsmechanismus einzuführen durch ErhaltungseigenschaftenDesign, um alltägliche Aufmerksamkeitsprobleme zu vermeiden.
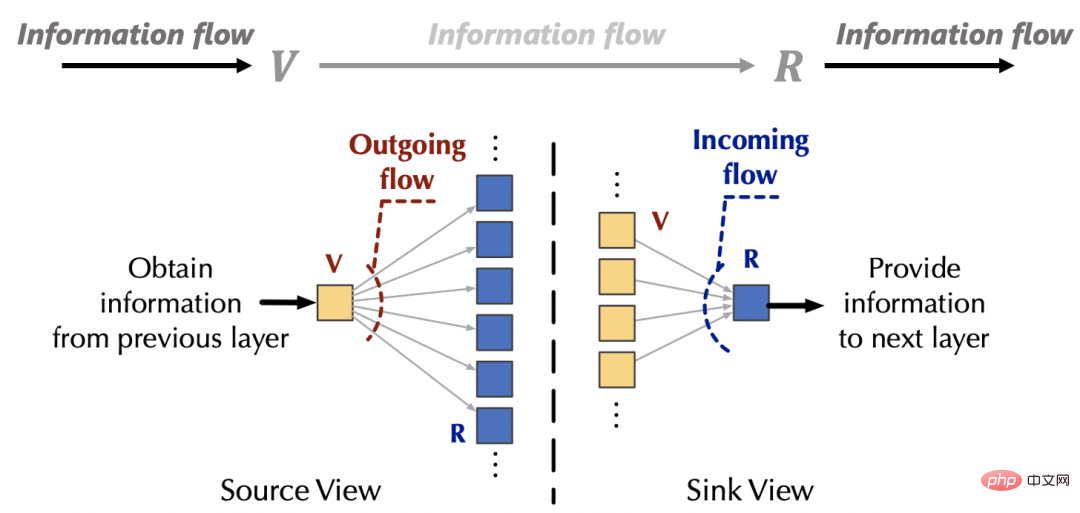
3. Flowformer (Flusskapazität, entsprechend dem Aufmerksamkeitsgewicht) konvergiert zu
Sink (Senke, entsprechend). Außerhalb des Aufmerksamkeitsmechanismus stammen die Informationen der Quelle (v) von der oberen Schicht des Netzwerks, und die Informationen der Senke (R) werden auch der darunter liegenden Feed-Forward-Schicht bereitgestellt. Basierend auf den obigen Beobachtungen können wir „feste Ressourcen“ realisieren, indem wir die Interaktion zwischen dem Aufmerksamkeitsmechanismus und dem externen Netzwerk aus zwei Perspektiven steuern: Zufluss und Abfluss verursacht Konkurrenz innerhalb von Quellen bzw. Senken, um triviale Aufmerksamkeit zu vermeiden. Ohne Beschränkung der Allgemeinheit setzen wir die Menge an Interaktionsinformationen zwischen dem Aufmerksamkeitsmechanismus und dem externen Netzwerk auf den Standardwert 1 ist nicht schwer zu bekommen, vor der Konservierung beträgt die Menge an einfließenden Informationen für die Senke: . Um die Informationsmenge, die in jede Senke fließt, auf Einheit 1 festzulegen, führen wir als Normalisierung in die Berechnung des Informationsflusses (Aufmerksamkeitsgewicht) ein. Nach der Normalisierung beträgt die Menge der Zuflussinformationen der Senke: . Um die aus jeder Quelle fließende Informationsmenge auf Einheit 1 festzulegen, führen wir die Berechnung des Informationsflusses (Aufmerksamkeitsgewicht) als Normalisierung ein. Nach der Normalisierung beträgt die Menge der Abflussinformationen aus der j-ten Quelle: (3) Gesamtdesign In diesem Artikel wurden umfangreiche Experimente mit Standarddatensätzen durchgeführt: Deckt Eingabesituationen verschiedener Sequenzlängen (20-4000) ab.
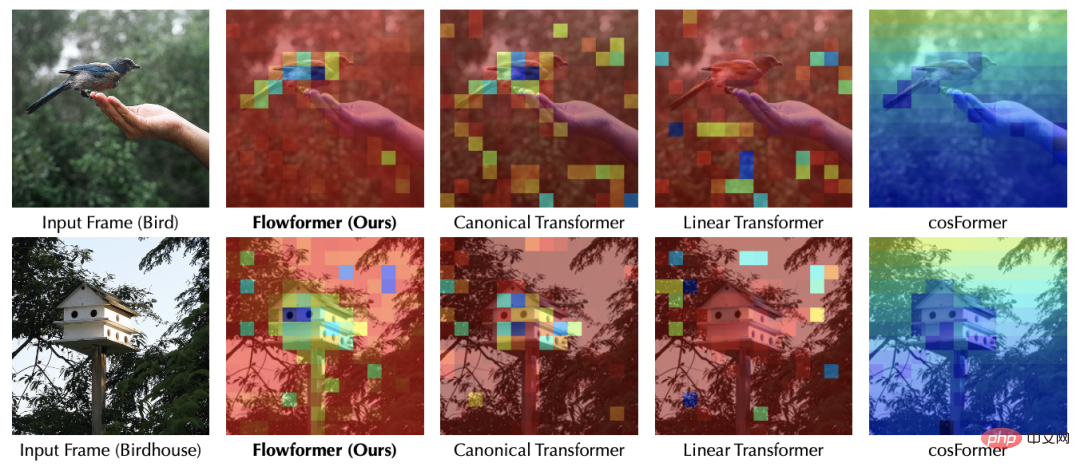
Vergleicht verschiedene Basismethoden wie klassische Modelle in verschiedenen Bereichen, Mainstream-Deep-Modelle, Transformer und seine Varianten. Um das Funktionsprinzip von Flowformer weiter zu erklären, haben wir ein visuelles Experiment zur Aufmerksamkeit in der ImageNet-Klassifizierungsaufgabe (entsprechend Flow-Attention) durchgeführt, aus dem wir Folgendes finden können: Die obige Visualisierung zeigt, dass die Einführung von Wettbewerb in die Gestaltung des Aufmerksamkeitsmechanismus durch Flow-Attention triviale Aufmerksamkeit effektiv vermeiden kann. Weitere Visualisierungsexperimente finden Sie im Artikel. Der in diesem Artikel vorgeschlagene Flowformer führt das Erhaltungsprinzip im Netzwerkfluss in das Design ein und führt auf natürliche Weise den Wettbewerbsmechanismus in die Aufmerksamkeitsberechnung ein, wodurch das triviale Aufmerksamkeitsproblem effektiv vermieden und lineare Komplexität erreicht wird Gleichzeitig bleibt die Vielseitigkeit des Standard-Transformers erhalten. Flowformer hat bei fünf Hauptaufgaben hervorragende Ergebnisse erzielt: lange Sequenzen, Vision, natürliche Sprache, Zeitreihen und verstärkendes Lernen. Darüber hinaus inspiriert das Designkonzept „keine besondere Induktionspräferenz“ im Flowformer auch zur Erforschung allgemeiner Infrastruktur. In zukünftigen Arbeiten werden wir das Potenzial von Flowformer für groß angelegte Vorschulungen weiter untersuchen. 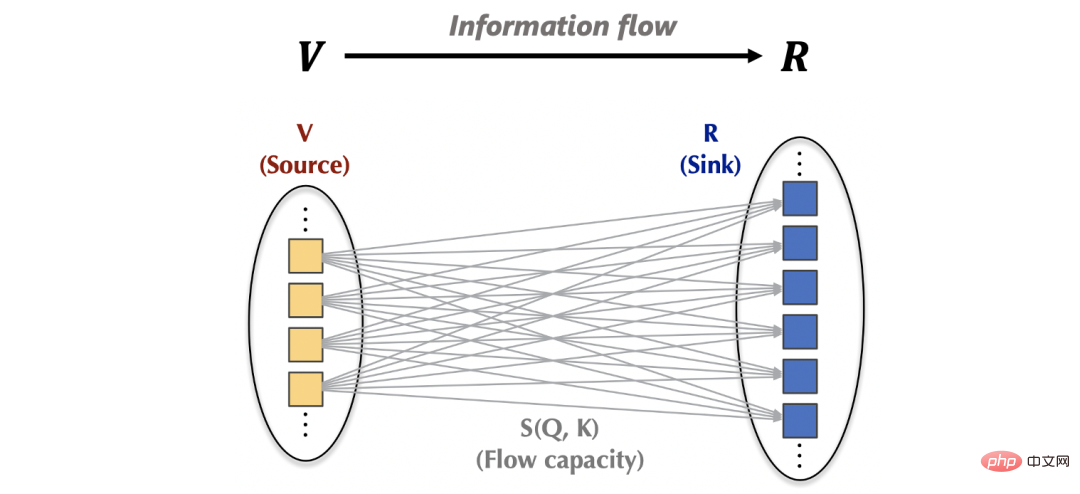
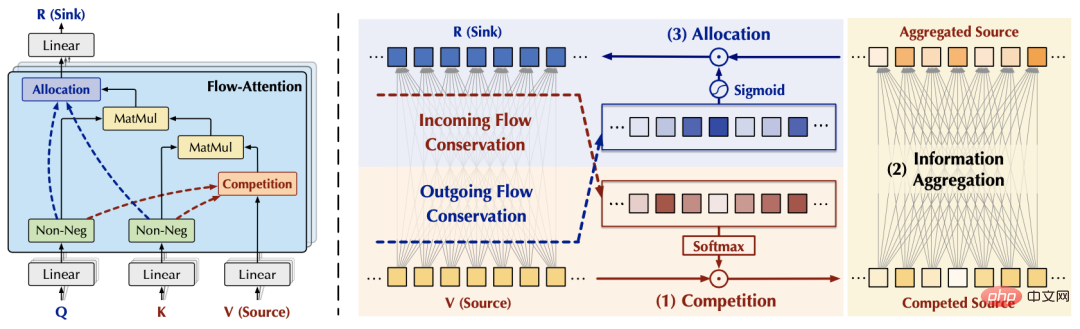
3.2 Fluss-Aufmerksamkeit
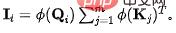
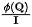 (2) Erhaltung des Ausflusses aus der Quelle (V): Ähnlich wie beim oben genannten Prozess beträgt vor der Erhaltung für die Quelle die Menge der ausfließenden Informationen:
(2) Erhaltung des Ausflusses aus der Quelle (V): Ähnlich wie beim oben genannten Prozess beträgt vor der Erhaltung für die Quelle die Menge der ausfließenden Informationen: 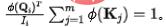
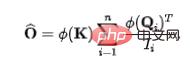
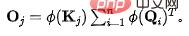 Basierend auf den obigen Ergebnissen entwerfen wir den folgenden Flow-Attention-Mechanismus, der insbesondere drei Teile umfasst: Wettbewerb, Aggregation und Zuteilung: Der Wettbewerb konkurriert Wenn der Mechanismus vorhanden ist Wichtige Informationen werden hervorgehoben. Die Aggregation basiert auf dem Matrix-Assoziationsgesetz, um eine lineare Komplexität zu erreichen. Durch die Einführung eines Wettbewerbsmechanismus wird die Menge der an die nächste Ebene weitergegebenen Informationen gesteuert. Alle Operationen im obigen Prozess weisen eine lineare Komplexität auf. Gleichzeitig basiert das Design von Flow-Attention nur auf dem Erhaltungsprinzip im Netzwerkfluss und integriert den Informationsfluss wieder. Daher werden keine neuen induktiven Präferenzen eingeführt, wodurch die Vielseitigkeit des Modells gewährleistet wird. Flowformer wird erhalten, indem die quadratische Komplexität Attention im Standardtransformator durch Flow-Attention ersetzt wird.
Basierend auf den obigen Ergebnissen entwerfen wir den folgenden Flow-Attention-Mechanismus, der insbesondere drei Teile umfasst: Wettbewerb, Aggregation und Zuteilung: Der Wettbewerb konkurriert Wenn der Mechanismus vorhanden ist Wichtige Informationen werden hervorgehoben. Die Aggregation basiert auf dem Matrix-Assoziationsgesetz, um eine lineare Komplexität zu erreichen. Durch die Einführung eines Wettbewerbsmechanismus wird die Menge der an die nächste Ebene weitergegebenen Informationen gesteuert. Alle Operationen im obigen Prozess weisen eine lineare Komplexität auf. Gleichzeitig basiert das Design von Flow-Attention nur auf dem Erhaltungsprinzip im Netzwerkfluss und integriert den Informationsfluss wieder. Daher werden keine neuen induktiven Präferenzen eingeführt, wodurch die Vielseitigkeit des Modells gewährleistet wird. Flowformer wird erhalten, indem die quadratische Komplexität Attention im Standardtransformator durch Flow-Attention ersetzt wird. 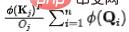 4. Experimente
4. Experimente
5. Analyse
6. Zusammenfassung
Das obige ist der detaillierte Inhalt vonGemeinsame Aufgaben! Tsinghua schlägt den Flowformer für das Backbone-Netzwerk vor, um eine lineare Komplexität zu erreichen |. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Was passiert, wenn das Netzwerk keine Verbindung zum WLAN herstellen kann?
Apr 03, 2024 pm 12:11 PM
Was passiert, wenn das Netzwerk keine Verbindung zum WLAN herstellen kann?
Apr 03, 2024 pm 12:11 PM
1. Überprüfen Sie das WLAN-Passwort: Stellen Sie sicher, dass das von Ihnen eingegebene WLAN-Passwort korrekt ist und achten Sie auf die Groß-/Kleinschreibung. 2. Überprüfen Sie, ob das WLAN ordnungsgemäß funktioniert: Überprüfen Sie, ob der WLAN-Router normal funktioniert. Sie können andere Geräte an denselben Router anschließen, um festzustellen, ob das Problem beim Gerät liegt. 3. Starten Sie das Gerät und den Router neu: Manchmal liegt eine Fehlfunktion oder ein Netzwerkproblem mit dem Gerät oder Router vor, und ein Neustart des Geräts und des Routers kann das Problem lösen. 4. Überprüfen Sie die Geräteeinstellungen: Stellen Sie sicher, dass die WLAN-Funktion des Geräts eingeschaltet und die WLAN-Funktion nicht deaktiviert ist.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
