
 Technologie-Peripheriegeräte
KI
Das Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun
Technologie-Peripheriegeräte
KI
Das Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun
Das Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun

Im Jahr 2023 scheint es im Chatbot-Bereich nur noch zwei Lager zu geben: „OpenAI's ChatGPT“ und „Andere“.
ChatGPT ist leistungsstark, aber es ist für OpenAI fast unmöglich, es als Open Source zu veröffentlichen. Das „andere“ Lager schnitt schlecht ab, aber viele Leute arbeiten an Open Source, wie zum Beispiel LLaMA, das vor einiger Zeit von Meta als Open Source bereitgestellt wurde.
LLaMA ist der allgemeine Name für eine Reihe von Modellen mit Parametergrößen im Bereich von 7 Milliarden bis 65 Milliarden. Darunter ist das LLaMA-Modell mit 13 Milliarden Parametern am weitesten verbreitet Benchmarks" Es kann GPT-3 mit 175 Milliarden Parametern übertreffen. Das Modell wurde jedoch keiner Anweisungsoptimierung (Anweisungsoptimierung) unterzogen, sodass der Generierungseffekt schlecht ist.
Um die Leistung des Modells zu verbessern, halfen Forscher aus Stanford bei der Feinabstimmung der Anweisungen und trainierten ein neues 7-Milliarden-Parameter-Modell namens Alpaca Model (basierend auf LLaMA 7B). Konkret baten sie das text-davinci-003-Modell von OpenAI, 52.000 Beispiele für die Befehlsfolge als Trainingsdaten für Alpaca selbst zu generieren. Experimentelle Ergebnisse zeigen, dass viele Verhaltensweisen von Alpakas denen von text-davinci-003 ähneln. Mit anderen Worten: Die Leistung des leichten Modells Alpaca mit nur 7B-Parametern ist vergleichbar mit der von sehr großen Sprachmodellen wie GPT-3.5.

Für normale Forscher ist dies eine praktische und kostengünstige Möglichkeit zur Feinabstimmung, aber es erfordert viel Berechnungen Die Menge ist immer noch groß (der Autor sagte, sie hätten sie für 3 Stunden auf acht 80-GB-A100 optimiert). Darüber hinaus sind die Seed-Aufgaben von Alpaca alle auf Englisch und die gesammelten Daten sind auch auf Englisch, sodass das trainierte Modell nicht für Chinesisch optimiert ist.
Um die Kosten für die Feinabstimmung weiter zu senken, nutzte ein anderer Forscher aus Stanford, Eric J. Wang, die LoRA-Technologie (Low-Rank-Adaption) zur Reproduktion Alpaka-Ergebnis. Konkret trainierte Eric J. Wang mit einer RTX 4090-Grafikkarte ein Alpaca-äquivalentes Modell in nur 5 Stunden und reduzierte so den Rechenleistungsbedarf solcher Modelle auf Verbraucherniveau. Darüber hinaus kann das Modell auf einem Raspberry Pi ausgeführt werden (zu Forschungszwecken).
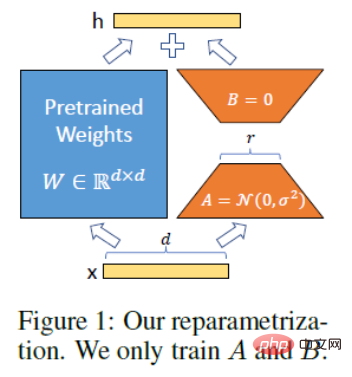
Das technische Prinzip von LoRA. Die Idee von LoRA besteht darin, einen Bypass neben dem ursprünglichen PLM hinzuzufügen und eine Dimensionsreduktion und anschließende Dimensionsoperation durchzuführen, um den sogenannten intrinsischen Rang zu simulieren. Während des Trainings werden die Parameter des PLM festgelegt und nur die Dimensionsreduktionsmatrix A und die Dimensionsverbesserungsmatrix B trainiert. Die Eingabe- und Ausgabedimensionen des Modells bleiben unverändert und die Parameter von BA und PLM werden bei der Ausgabe überlagert. Initialisieren Sie A mit einer zufälligen Gaußschen Verteilung und initialisieren Sie B mit einer 0-Matrix, um sicherzustellen, dass die Bypass-Matrix zu Beginn des Trainings immer noch eine 0-Matrix ist (zitiert nach: https://finisky.github.io/lora/). Der größte Vorteil von LoRA besteht darin, dass es schneller ist und weniger Speicher benötigt, sodass es auf Consumer-Hardware ausgeführt werden kann.

Alpaka-LoRA-Projekt gepostet von Eric J. Wang.
Projektadresse: https://github.com/tloen/alpaca-lora
#🎜 🎜#Dies ist zweifellos eine große Überraschung für Forscher, die ihre eigenen ChatGPT-ähnlichen Modelle trainieren möchten (einschließlich der chinesischen Version von ChatGPT), aber nicht über erstklassige Rechenressourcen verfügen. Daher entstanden nach dem Aufkommen des Alpaca-LoRA-Projekts weiterhin Tutorials und Trainingsergebnisse rund um das Projekt, und in diesem Artikel werden einige davon vorgestellt.
So verwenden Sie Alpaca-LoRA zur Feinabstimmung von LLaMAIm Alpaca-LoRA-Projekt erwähnte der Autor dies, um die Feinabstimmung vorzunehmen -Kostengünstig und effizient stimmen, sie verwendeten PEFT von Hugging Face. PEFT ist eine Bibliothek (LoRA ist eine der unterstützten Technologien), die es Ihnen ermöglicht, verschiedene Transformer-basierte Sprachmodelle zu verwenden und diese mithilfe von LoRA zu optimieren. Der Vorteil besteht darin, dass Sie Ihr Modell kostengünstig und effizient auf bescheidener Hardware mit kleineren (vielleicht zusammensetzbaren) Ausgaben optimieren können.
In einem aktuellen Blog stellten mehrere Forscher vor, wie Alpaca-LoRA zur Feinabstimmung von LLaMA verwendet werden kann.
Bevor Sie Alpaca-LoRA nutzen können, müssen Sie einige Voraussetzungen erfüllen. Das erste ist die Wahl der GPU. Dank LoRA können Sie nun die Feinabstimmung auf Low-Spec-GPUs wie NVIDIA T4 oder 4090 Consumer-GPUs durchführen. Darüber hinaus müssen Sie LLaMA-Gewichte beantragen, da deren Gewichte nicht öffentlich sind.
Da nun die Voraussetzungen erfüllt sind, geht es im nächsten Schritt um die Nutzung von Alpaca-LoRA. Zuerst müssen Sie das Alpaca-LoRA-Repository klonen. Der Code lautet wie folgt:
git clone https://github.com/daanelson/alpaca-lora cd alpaca-lora
Zweitens erhalten Sie die LLaMA-Gewichte. Speichern Sie die heruntergeladenen Gewichtswerte in einem Ordner mit dem Namen unconverted-weights. Die Ordnerhierarchie ist wie folgt:
unconverted-weights ├── 7B │ ├── checklist.chk │ ├── consolidated.00.pth │ └── params.json ├── tokenizer.model └── tokenizer_checklist.chk
Nachdem die Gewichte gespeichert wurden, verwenden Sie den folgenden Befehl, um die PyTorch-Prüfpunktgewichte in transformatorkompatible Formate zu konvertieren :
cog run python -m transformers.models.llama.convert_llama_weights_to_hf --input_dir unconverted-weights --model_size 7B --output_dir weights
Die endgültige Verzeichnisstruktur sollte wie folgt aussehen:
weights ├── llama-7b └── tokenizermdki
Nachdem Sie die beiden oben genannten Schritte ausgeführt haben, fahren Sie mit dem dritten Schritt fort und installieren Sie Cog:
sudo curl -o /usr/local/bin/cog -L "https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)" sudo chmod +x /usr/local/bin/cog
Der vierte Schritt besteht in der Feinabstimmung Modell: Standardmäßig ist die im Finetune-Skript konfigurierte GPU weniger leistungsstark. Wenn Sie jedoch über eine leistungsstärkere GPU verfügen, können Sie MICRO_BATCH_SIZE in finetune.py auf 32 oder 64 erhöhen. Wenn Sie außerdem Anweisungen zum Optimieren eines Datensatzes haben, können Sie den DATA_PATH in finetune.py so bearbeiten, dass er auf Ihren eigenen Datensatz verweist. Es ist zu beachten, dass dieser Vorgang sicherstellen sollte, dass das Datenformat mit alpaca_data_cleaned.json übereinstimmt. Führen Sie als Nächstes das Feinabstimmungsskript aus:
cog run python finetune.py
Der Feinabstimmungsprozess dauerte 3,5 Stunden auf einer 40-GB-A100-GPU und mehr Zeit auf weniger leistungsstarken GPUs.
Der letzte Schritt besteht darin, das Modell mit Cog auszuführen:
$ cog predict -i prompt="Tell me something about alpacas." Alpacas are domesticated animals from South America. They are closely related to llamas and guanacos and have a long, dense, woolly fleece that is used to make textiles. They are herd animals and live in small groups in the Andes mountains. They have a wide variety of sounds, including whistles, snorts, and barks. They are intelligent and social animals and can be trained to perform certain tasks.
Der Autor des Tutorials sagte, dass Sie nach Abschluss der oben genannten Schritte weiterhin verschiedene Gameplays ausprobieren können, einschließlich, aber nicht beschränkt auf:
- Bringen Sie Ihren eigenen Datensatz mit, optimieren Sie Ihre eigene LoRA, z. B. optimieren Sie LLaMA so, dass es wie eine Anime-Figur spricht. Siehe: https://replicate.com/blog/fine-tune-llama-to-speak-like-homer-simpson
- Stellen Sie das Modell auf der Cloud-Plattform bereit;
- In Kombination mit anderen LoRA, z Stabile Diffusion LoRA, wenden Sie all dies auf das Bildfeld an.
- Verwenden Sie den Alpaca-Datensatz (oder andere Datensätze), um größere LLaMA-Modelle zu optimieren und zu sehen, wie sie funktionieren. Dies sollte mit PEFT und LoRA möglich sein, erfordert allerdings eine größere GPU.
Alpaca-LoRA-Ableitungsprojekt
Obwohl die Leistung von Alpaca mit GPT 3.5 vergleichbar ist, sind seine Seed-Aufgaben alle auf Englisch und die gesammelten Daten sind auch auf Englisch, sodass das trainierte Modell nicht für Chinesisch geeignet ist. Um die Wirksamkeit des Dialogmodells auf Chinesisch zu verbessern, werfen wir einen Blick auf einige der besseren Projekte.
Das erste ist das Open-Source-Chinesisch-Sprachmodell Luotuo (Luotuo) von drei einzelnen Entwicklern der Central China Normal University und anderen Institutionen. Dieses Projekt basiert auf LLaMA, Stanford Alpaca, Alpaca LoRA, Japanese-Alpaca-LoRA usw ., mit einer einzigen Karte. Kann den Trainingseinsatz abschließen. Interessanterweise nannten sie das Modellkamel, weil sowohl LLaMA (Lama) als auch Alpaka (Alpaka) zur Ordnung Artiodactyla – Familie Camelidae – gehören. Unter diesem Gesichtspunkt wird dieser Name auch erwartet.
Dieses Modell basiert auf Metas Open-Source-LLaMA mit Bezug auf die beiden Projekte Alpaca und Alpaca-LoRA und wurde auf Chinesisch trainiert.
Projektadresse: https://github.com/LC1332/Chinese-alpaca-lora
Derzeit hat das Projekt zwei Modelle veröffentlicht: luotuo-lora-7b-0.1 und luotuo-lora- 7b -0.3, es gibt ein anderes Modell im Plan:
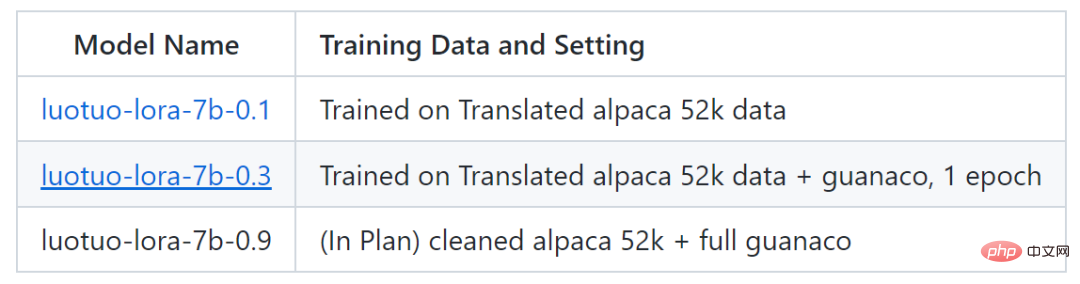
Das Folgende ist die Effektanzeige:


Aber luotuo-lora-7b-0.1 (0.1), luotuo- lora-7b -0,3 (0,3) Es gibt immer noch eine Lücke. Als der Benutzer nach der Adresse der Central China Normal University fragte, antwortete 0,1 falsch:

Neben einfachen Gesprächen gibt es auch Menschen, die Modelloptimierungen in versicherungsrelevanten Bereichen durchgeführt haben. Laut diesem Twitter-Nutzer hat er mit Hilfe des Alpaca-LoRA-Projekts einige chinesische Versicherungsfrage- und Antwortdaten eingegeben und die Endergebnisse waren gut.
Insbesondere verwendete der Autor mehr als 3.000 chinesische Frage- und Antwortversicherungskorpus, um die chinesische Version von Alpaca LoRa zu trainieren. Der Implementierungsprozess verwendete die LoRa-Methode und verfeinerte das Alpaca 7B-Modell, was 240 Minuten dauerte ein Endverlust von 0,87.

Bildquelle: https://twitter.com/nash_su/status/1639273900222586882
Das Folgende ist der Trainingsprozess und die Ergebnisse:
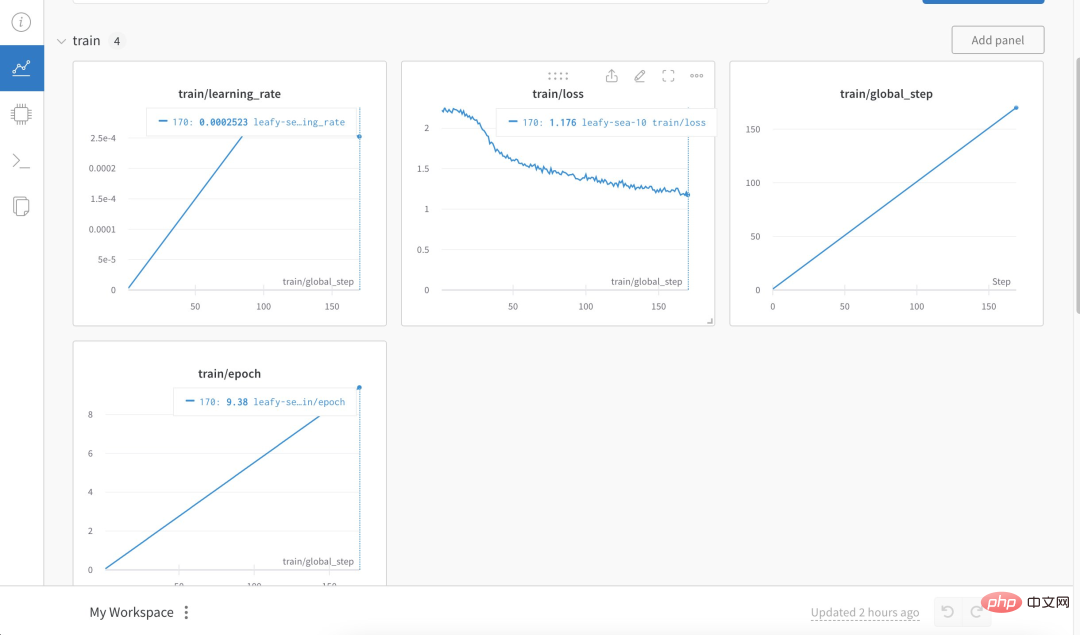
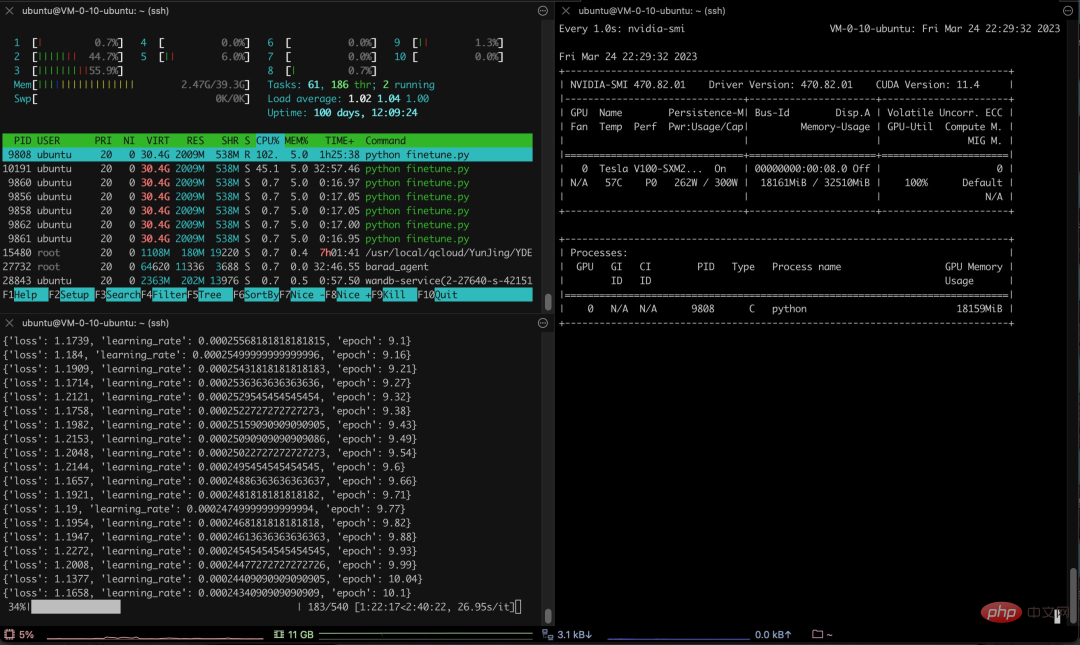
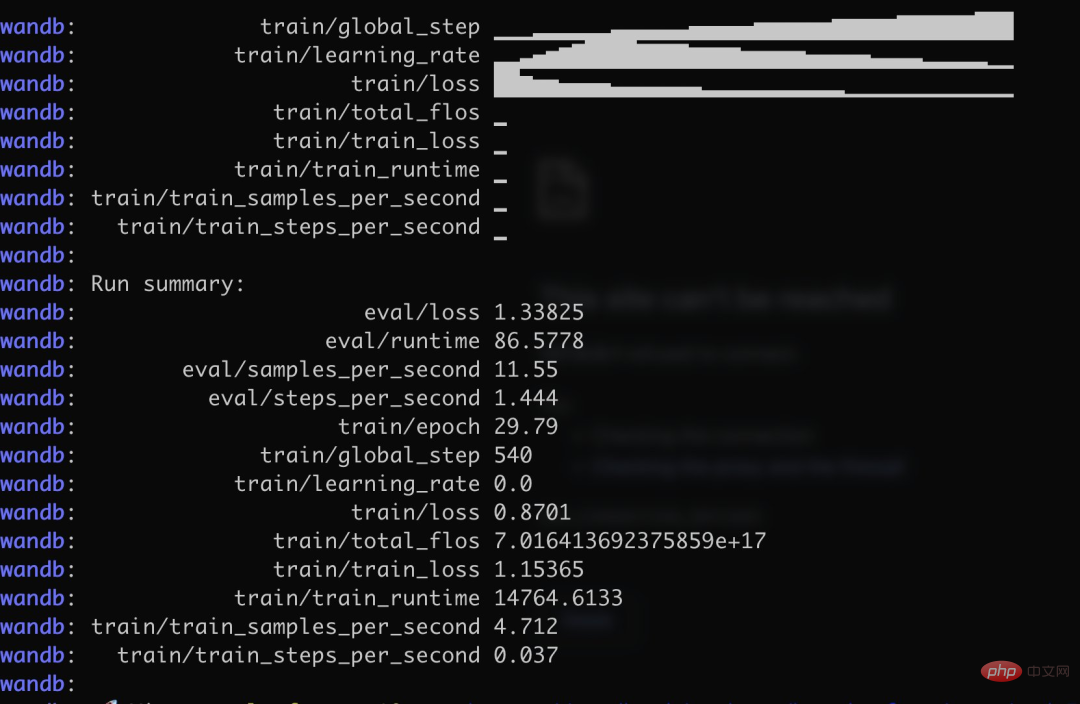
Test Die Ergebnisse zeigen, dass: 1. Inhalte, die sich auf das Trainingskorpus beziehen, grob und vernünftig beantwortet werden können, aber nur, wenn sie kein Unsinn sind. 2. Nicht-korpusbezogene Inhalte werden zwingend auf die Daten in einem bestimmten Korpus antworten. Logisches Denken und mathematische Berechnungen verfügen nicht über diese Fähigkeit.
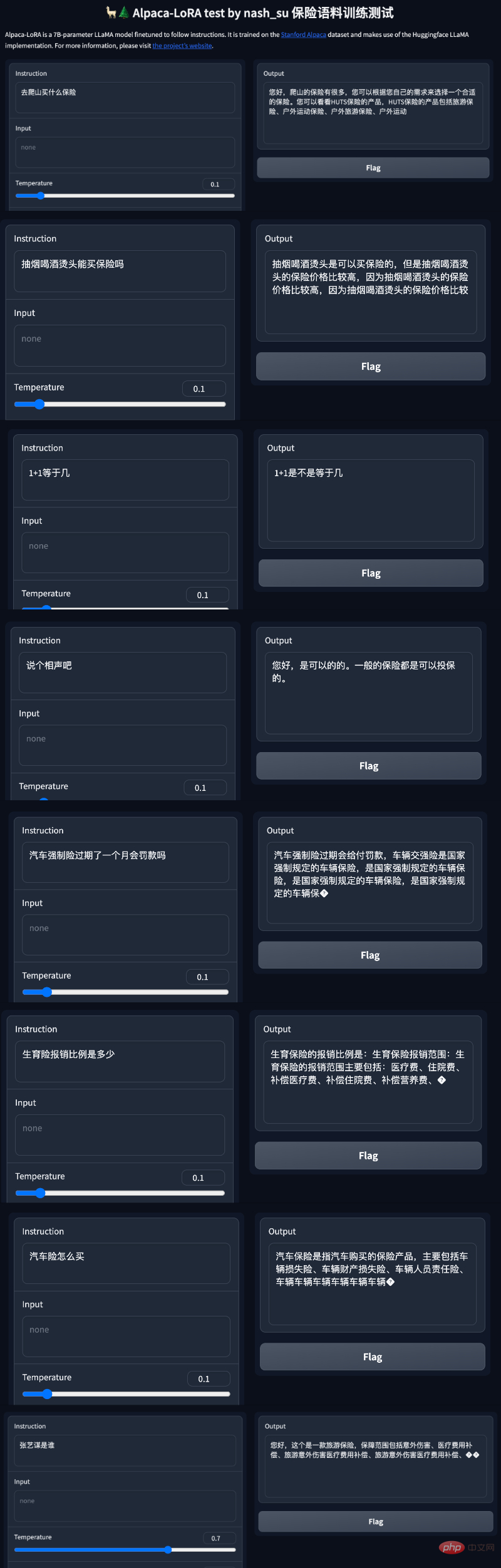
Nachdem die Internetnutzer dieses Ergebnis gesehen hatten, schrien sie, dass sie ihren Job verlieren würden:

Abschließend freue ich mich darauf, dass weitere chinesische Konversationsmodelle hinzugefügt werden.
Das obige ist der detaillierte Inhalt vonDas Trainieren einer chinesischen Version von ChatGPT ist nicht so schwierig: Sie können es mit der Open-Source-Version Alpaca-LoRA+RTX 4090 ohne A100 tun. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
