

Wie man KI-Malerei spielt, die dieses Jahr sehr beliebt ist

1. Vorwort
2022 kann man definitiv als das erste Jahr von AIGC bezeichnen. Den Google-Suchtrends nach zu urteilen, wird das Suchvolumen für KI-Malerei und KI-generierte Kunst im Jahr 2022 stark ansteigen.
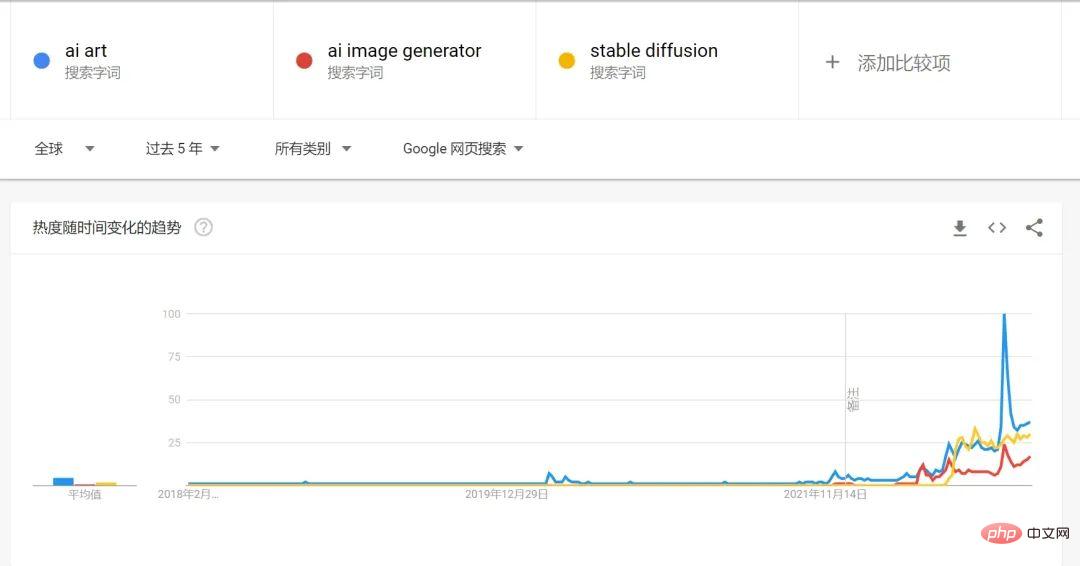
Ein sehr wichtiger Grund für die Explosion der KI-Malerei in diesem Jahr ist die Open Source von Stable Diffusion auch in der Nähe Neben der rasanten Entwicklung des Diffusionsmodells in den letzten Jahren ist in Kombination mit dem bereits entwickelten Textsprachenmodell GPT-3 von OPENAI der Generierungsprozess von Text zu Bildern einfacher geworden.
2. Der Engpass von GAN (Generative Adversarial Network)
Von seiner Geburt im Jahr 2014 bis zu StyleGAN im Jahr 2018 hat GAN große Fortschritte im Bereich der Bildgenerierung gemacht. So wie Raubtiere und Beute in der Natur miteinander konkurrieren und sich entwickeln, besteht das Prinzip von GAN einfach darin, zwei neuronale Netze zu verwenden: eines als Generator und eines als Diskriminator. Der Generator erzeugt unterschiedliche Bilder, damit der Diskriminator beurteilen kann, ob das Ergebnis qualifiziert ist oder nicht, die beiden treten gegeneinander an, um das Modell zu trainieren.
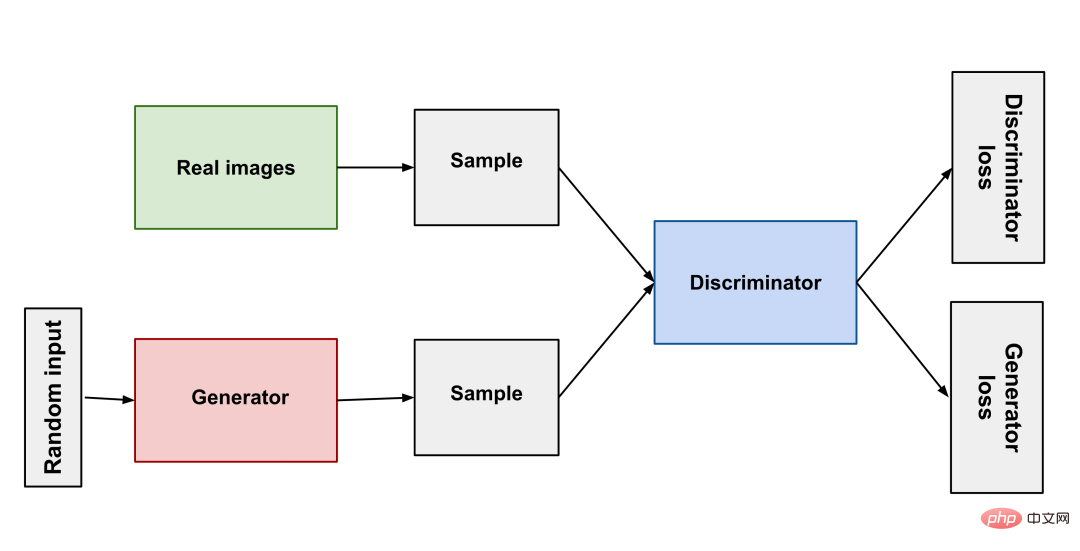
GAN (Generative Adversarial Network) hat durch kontinuierliche Weiterentwicklung gute Ergebnisse erzielt, aber einige Probleme sind immer schwer zu überwinden . Probleme: Mangelnde Vielfalt bei den generierten Ergebnissen, Moduszusammenbruch (der Generator macht keine Fortschritte, nachdem er den besten Modus gefunden hat) und hohe Trainingsschwierigkeiten. Diese Schwierigkeiten haben es der KI-generierten Kunst erschwert, praktische Produkte zu produzieren.
3. Durchbruch beim Diffusionsmodell
Nach Jahren der Engpässe im GAN haben Wissenschaftler die sehr erstaunliche Diffusionsmodell-Methode entwickelt: Verwenden Sie eine Markov-Kette, um kontinuierlich zu arbeiten Fügen Sie dem Originalbild Rauschpunkte hinzu, die schließlich zu einem zufälligen Rauschbild werden, und lassen Sie dann das trainierte neuronale Netzwerk diesen Vorgang umkehren und das zufällige Rauschbild schrittweise zum Originalbild wiederherstellen, sodass das neuronale Netzwerk Man kann sagen, dass es das hat Möglichkeit, Bilder von Grund auf zu erstellen. Um Bilder aus Text zu generieren, wird der Beschreibungstext verarbeitet und als Rauschen zum Originalbild hinzugefügt. Dadurch kann das neuronale Netzwerk Bilder aus Text generieren.

Diffusionsmodell (Diffusionsmodell) erleichtert das Training des Modells, es sind lediglich eine große Anzahl von Bildern erforderlich Auch die Qualität der erzeugten Bilder kann ein sehr hohes Niveau erreichen und die erzeugten Ergebnisse können sehr vielfältig sein. Aus diesem Grund kann die neue Generation der KI eine unglaubliche „Fantasie“ haben.
Natürlich hat die von Nvidia Ende Januar veröffentlichte aktualisierte Version von StyleGAN-T erstaunliche Fortschritte gemacht und erzeugt ein Bild mit der gleichen Rechenleistung Bilder dauern 3 Sekunden, StyleGAN-T dauert nur 0,1 Sekunden. Und StyleGAN-T ist bei Bildern mit niedriger Auflösung besser als das Diffusionsmodell, aber bei der Erzeugung von Bildern mit hoher Auflösung dominiert das Diffusionsmodell immer noch. Da StyleGAN-T nicht so weit verbreitet ist wie Stable Diffusion, konzentriert sich dieser Artikel auf die Einführung von Stable Diffusion.
4, Stable Diffusion
Anfang dieses Jahres erlebte der KI-Malkreis die Ära von Disco Diffusion, DALL-E2 und Midjouney, bis Stable Diffusion Open Source war , Der Staub hat sich gerade für eine gewisse Zeit gelegt. Als leistungsstärkstes KI-Malmodell hat Stable Diffusion einen Karneval in der KI-Community ausgelöst. Im Grunde werden jeden Tag neue Modelle und neue Open-Source-Bibliotheken geboren. Insbesondere nach der Einführung der WebUI-Version von Auto1111 ist die Verwendung von Stable Diffusion zu einer sehr einfachen Sache geworden, egal ob in der Cloud oder lokal bereitgestellt. Durch die kontinuierliche Weiterentwicklung der Community sind viele hervorragende Projekte wie Dreambooth und Deforum zu Stable geworden. Für die Diffusion WEBUI-Version wurde ein Plug-in hinzugefügt, mit dem Funktionen wie die Feinabstimmung von Modellen und die Erstellung von Animationen in einem Schritt ausgeführt werden können.
5. Einführung in das Gameplay und die Fähigkeiten der KI-Malerei
Das Folgende ist eine Einführung zur aktuellen Verwendung von Stable Welche Art von Gameplay und Fähigkeiten kann Diffusion haben? 🎜#
Einführung |
Eingabe |
Ausgabe#🎜 🎜 # |
|||
| text2img | Generieren Sie Bilder durch Textbeschreibung, und Sie können den Künstler angeben durch Textbeschreibung Stil, Art der Kunst. Hier ist ein Beispiel im Stil des Künstlers Greg Rutkowski. | ein wunderschönes Mädchen mit einem geblümten Hemd, das für ein Foto posiert, wobei das Kinn auf der rechten Hand ruht, von Greg Rutkowski#🎜🎜 # |
# 🎜🎜#
| img2img||
durch Bilder und Text Beschreibung Bild generieren |
ein wunderschönes Mädchen mit einem geblümten Hemd, das für ein Foto posiert, das Kinn auf der rechten Hand, von Greg Rutkowski |
|
ein wunderschönes Mädchen mit einem geblümten Hemd, das sanft lächelt und für ein Foto posiert, das Kinn auf der rechten Hand, von Greg Rutkowski |
||
|
|
. |
||||
verwenden DreamBooth ist ein fein abgestimmtes großes Modell, das auf dem SD-Modelltraining basiert. Nach dem Training kann das Modell die oben genannten Funktionen von text2img img2img und andere verwenden Derzeit wird NAI auf der Grundlage öffentlicher Bilder von der danbooru-Website als Datensatz trainiert. Aufgrund von Urheberrechtsproblemen auf danbooru selbst war NovelAI jedoch relativ umstritten und das Modell wurde von kommerziellen Diensten durchgesickert mit Vorsicht. | |||||
| NovelAI
|
|||||
|
AI Painting |
|
Subjektmodell basierend auf Benutzerfotos trainiert |
Trainieren Sie ein Modell für das Motiv basierend auf mehreren vom Benutzer bereitgestellten Fotos. Dieses Modell kann verwendet werden, um jedes Bild zu generieren, das das Motiv basierend auf der Beschreibung enthält. |
Dieser Bildersatz verwendet 20 Fotos von Kollegen, um ein 2000-Stepout-Modell basierend auf dem Stable Diffusion 1.5-Modell mit mehreren stilisierten Eingabeaufforderungsausgaben zu trainieren. Prompt-Beispiel (Abbildung 1): Porträt von Alicepoizon, sehr detailliertes VFX-Porträt, Unreal Engine, Greg Rutkowski, Loish, Rhads, Caspar David Friedrich, Makoto Shinkai und Lois Van Baarle, Ilya Kuvshinov, Rossdraws, Elegent, Tom Bagshaw , Alphonse Mucha, globale Beleuchtung, detaillierte und komplizierte Umgebung *Alicepoizon ist der Name, der dieser Figur beim Training dieses Modells gegeben wurde |
.
Dieser Bildersatz wird mit dem fein abgestimmten Stilmodell erstellt, das von der Dewu Digital Collection ME.X trainiert wurde. |
|
|
|||||
|
| |||||
|
|
|||||
Scarlett Johansson |
|
||||


 #🎜. 🎜# #? ## 🎜🎜#
#🎜. 🎜# #? ## 🎜🎜#









6. Einführung in die aktuellen Hauptanwendungen
| Einführung | Beispiel # 🎜 🎜# |
|||
| #🎜🎜 # Bereitstellung ein komfortableres KI-Malerlebnis und Sie können viele benutzerdefinierte große Modelle mit unterschiedlichen Stilen verwenden. |
|
|||
|
| bietet den vorherigen Dreambooth + Stable Diffusion-Service, etwa 18-25 Yuan pro Zeit, laden Sie 15-20 Benutzerfotos hoch und erstellen Sie etwa 20 benutzerdefinierte Kunstfotos. ||||
|
# 🎜 🎜#
|
https://www.php.cn/link/81d7118d88d5570189ace943bd14f142 Die aktuelle Mainstream-KI-Open-Source-Community hat, ähnlich wie Github, eine große Anzahl von Benutzern, die eine Feinabstimmung (Feinabstimmung) vorgenommen haben. Stabile Diffusionsmodelle, die heruntergeladen und auf Ihrem eigenen Server oder lokalen Computer bereitgestellt werden können. Zum Beispiel ist das pix2pix-Modell auf der rechten Seite ein stabiles Diffusionsmodell in Kombination mit GPT3, das die oben erwähnte Inpainting-Funktion durch Beschreibung in natürlicher Sprache vervollständigen kann. |
|

 #🎜. 🎜#
#🎜. 🎜# 

7. Erstellen Sie Ihren eigenen Stable Diffusion WEBUI-Dienst
7.1 Cloud Version
wird hier mit der von AutoDL bereitgestellten Cloud-Computing-Leistung erstellt. Sie können auch andere Plattformen wie Google Colab oder Baidu Fei Paddle verwenden.
- Registrieren Sie zunächst ein Konto bei AutoDL und mieten Sie einen Cloud-Host mit einer A5000/RTX3090-Grafikkarte. https://www.autodl.com/market/list
- Erstellen Sie ein Bild auf diesem Host. Für das Bild können Sie das gepackte Algorithmusbild auf www.codewithgpu.com auswählen. Hier nehmen wir das Bild https://www.codewithgpu.com/i/AUTOMATIC1111/stable-diffusion-webui/Stable-Diffusion-for-NovelAI. Wählen Sie es aus und erstellen Sie es.
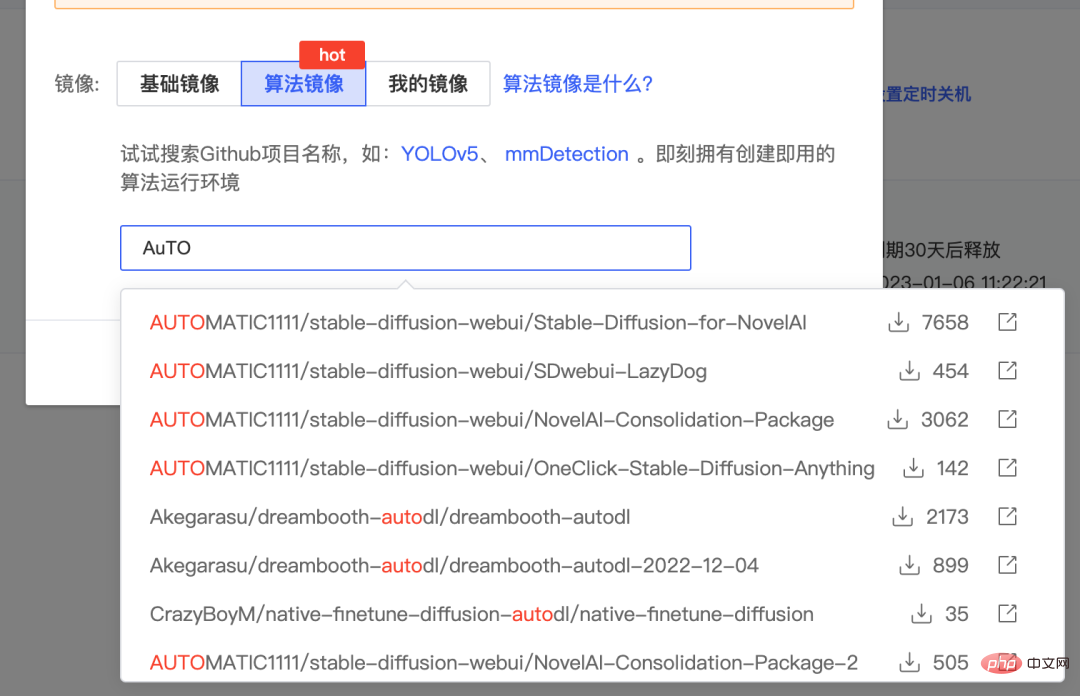
- Nach der Erstellung schalten Sie JupterLab ein und starten es.

Führen Sie den folgenden Befehl aus, um den Dienst zu starten. Wenn Sie feststellen, dass nicht genügend Speicherplatz auf der Systemfestplatte vorhanden ist, können Sie auch den Ordner „stable-diffusion-webui/“ auf die Datenfestplatte verschieben und autodl-tmp neu starten. Wenn beim Start ein Fehler auftritt, können Sie die Beschleunigung akademischer Ressourcen entsprechend dem Standort Ihres Computers konfigurieren.
cd stable-diffusion-webui/ rm -rf outputs && ln -s /root/autodl-tmp outputs python launch.py --disable-safe-unpickle --port=6006 --deepdanbooru
6.2 本地版本
Wenn Sie einen Computer mit einer guten Grafikkarte haben, können Sie diese lokal bereitstellen. Hier ist eine Einführung zum Erstellen der Windows-Version:
- Zuerst müssen Sie Python 3.10.6 installieren und Umgebungsvariablen hinzufügen der Pfad
- Installation git
- Klonen Sie den Stable Diffusion WEBUI-Projektcode auf lokal
- Platzieren Sie die Modelldatei im Verzeichnis models/Stable-Diffusion. Verwandte Modelle können von https://www.php.cn/link/81d7118d88d5570189ace943bd14f142 heruntergeladen werden
- Führen Sie webui-user.bat aus und greifen Sie über die lokale Computer-IP und den Port 7860 auf den Dienst zu.
8. Zusammenfassung
In diesem Artikel werden einige relevante Informationen zum Thema KI-Malerei vorgestellt. Interessierte Freunde können den Dienst auch selbst einsetzen und versuchen, die Verwendung von DreamBooth oder der neuesten Version von Lora zur Feinabstimmung großer Modelle zu erlernen. Ich glaube, dass im Jahr 2023, da die Popularität von AIGC weiter zunimmt, unsere Arbeit und unser Leben durch KI stark verändert werden. Der Start von ChatGPT hat uns vor einiger Zeit sehr schockiert. Ebenso wie die Fähigkeit, nach Informationen zu suchen, als wir zum ersten Mal im Internet waren, wird auch das Erlernen der Nutzung von KI zur Unterstützung unserer Arbeit in Zukunft eine sehr wichtige Fähigkeit sein.
9. Referenzen
- Lassen Sie uns im ersten Jahr der generativen KI-Kunst über KI sprechen Ein vorläufiges Verständnis von GAN und Diffusion hinter der Malerei
https://blog.csdn.net/qq_45848817/article/details/127808815
- Wie Diffusionsmodelle funktionieren: die Mathematik von Grund auf
https://theaisummer. com/diffusion-models/
- GAN-Strukturübersicht using through ' s ' through ' s ' durch . https://www.entrogames.com/2022/08/absolute - beginners-guide-to-midjourney- magical-introduction-to-ai-art/
Die virale KI-Avatar-App Lensa hat mich ausgezogen – ohne meine Zustimmung
- https://www.technologyreview.com/2022/12/ 12/1064751/the-viral-ai-avatar-app-lensa-abgesundet-me-without-my-conent/
instruct-pix2pix
https://www.php.cn/link/81d7118d88d5570189ace943bd14f142tims/inStractwork943bd14f142timStactwork943bd14f142tums -pix2pixDas obige ist der detaillierte Inhalt vonWie man KI-Malerei spielt, die dieses Jahr sehr beliebt ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
