Kürzlich habe ich an mehreren hochintensiven akademischen Aktivitäten teilgenommen, darunter geschlossene Seminare des CCF Computer Vision Committee und die VALSE Offline-Konferenz. Nachdem ich mit anderen Wissenschaftlern gesprochen hatte, kamen mir viele Ideen, und ich hoffe, dass ich sie für mich und meine Kollegen als Referenz aussortieren kann. Natürlich wird es aufgrund der persönlichen Ebene und des Forschungsumfangs auf jeden Fall viele Ungenauigkeiten oder sogar Fehler im Artikel geben. Natürlich ist es unmöglich, alle wichtigen Forschungsrichtungen abzudecken. Ich freue mich darauf, mit interessierten Wissenschaftlern zu kommunizieren, um diese Perspektiven zu konkretisieren und zukünftige Richtungen besser zu erkunden.
In diesem Artikel werde ich mich auf die Analyse der Schwierigkeiten und möglichen Forschungsrichtungen im Bereich Computer Vision konzentrieren, insbesondere in Richtung der visuellen Wahrnehmung (d. h. Erkennung). Anstatt die Details bestimmter Algorithmen zu verbessern, möchte ich lieber die Einschränkungen und Engpässe aktueller Algorithmen untersuchen (insbesondere das Pre-Training + Fine-Tuning-Paradigma auf Basis von Deep Learning) und daraus vorläufige Entwicklungsschlussfolgerungen ziehen, einschließlich der Frage, welche Probleme wichtig sind , welche Themen unwichtig sind, welche Richtungen förderungswürdig sind, welche Richtungen weniger kosteneffektiv sind usw.
Bevor ich anfange, zeichne ich zunächst die folgende Mindmap. Um einen geeigneten Einstiegspunkt zu finden, beginne ich mit dem Unterschied zwischen Computer Vision und natürlicher Sprachverarbeitung (den beiden beliebtesten Forschungsrichtungen in der künstlichen Intelligenz) und stelle drei grundlegende Eigenschaften von Bildsignalen vor: Informationssparsamkeit, Interdomänenvielfalt , unendlicher Granularität, und entsprechen mehreren wichtigen Forschungsrichtungen. Auf diese Weise können wir den Status jeder Forschungsrichtung besser verstehen: welche Probleme sie gelöst hat und welche wichtigen Probleme nicht gelöst wurden, und dann zukünftige Entwicklungstrends gezielt analysieren.
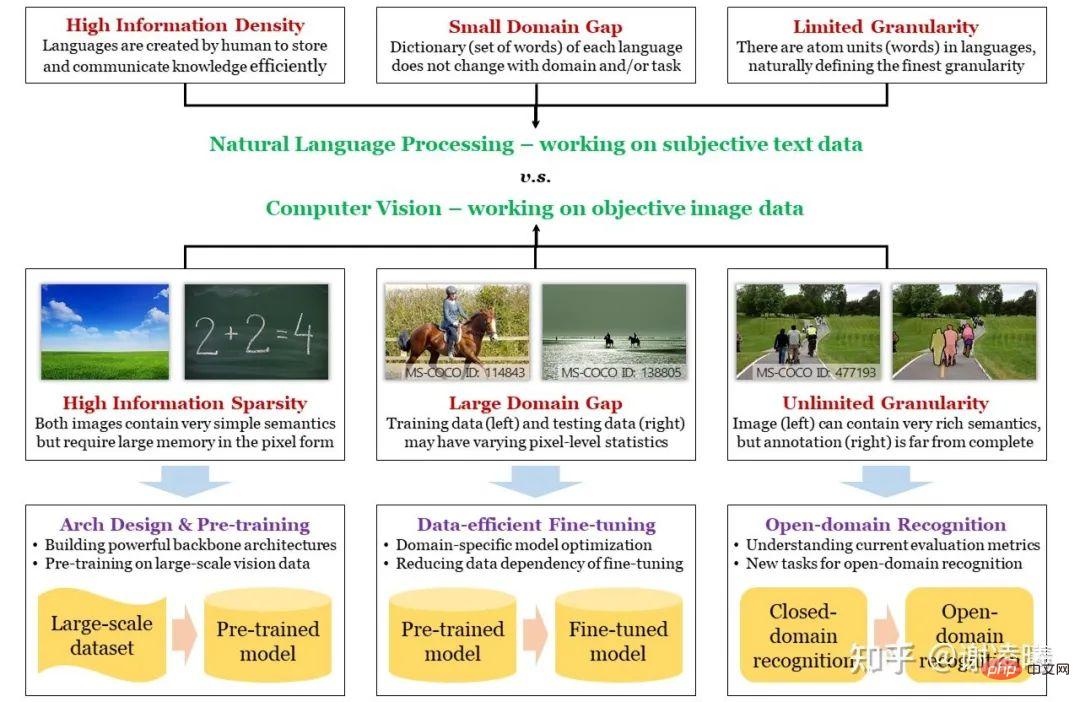
Bild: Der Unterschied zwischen CV und NLP, die drei großen Herausforderungen von CV und wie man mit ihnen umgeht
Die drei Grundschwierigkeiten von CV und die entsprechenden Forschungsrichtungen
NLP stand immer vor dem Lebenslauf. Unabhängig davon, ob tiefe neuronale Netze manuelle Methoden übertreffen oder vorab trainierte große Modelle einen Trend zur Vereinheitlichung zeigen, geschahen diese Dinge zuerst im NLP-Bereich und wurden bald auf den CV-Bereich verlagert. Der wesentliche Grund dafür ist, dass NLP einen höheren Ausgangspunkt hat: Die Grundeinheit der natürlichen Sprache sind Wörter, während die Grundeinheit von Bildern Pixel sind; erstere verfügen über natürliche semantische Informationen, während letztere möglicherweise nicht in der Lage sind, Semantik auszudrücken. Grundsätzlich ist die natürliche Sprache ein vom Menschen geschaffener Träger zum Speichern von Wissen und zum Kommunizieren von Informationen. Sie muss daher die Eigenschaften einer hohen Effizienz und einer hohen Informationsdichte aufweisen, während es sich bei Bildern um optische Signale handelt, die vom Menschen durch verschiedene Sensoren erfasst werden und objektiv wiedergegeben werden können reale Situation, weist aber dementsprechend keine starke Semantik auf und die Informationsdichte kann sehr gering sein. Aus einer anderen Perspektive ist der Bildraum viel größer als der Textraum und auch die Struktur des Raumes ist viel komplexer. Das heißt, wenn Sie eine große Anzahl von Proben im Raum abtasten und diese Daten verwenden möchten, um die Verteilung des gesamten Raums zu charakterisieren, sind die abgetasteten Bilddaten um viele Größenordnungen größer als die abgetasteten Textdaten. Dies ist übrigens auch der wesentliche Grund, warum Pre-Training-Modelle in natürlicher Sprache besser sind als visuelle Pre-Training-Modelle – wir werden dies später erwähnen.
Basierend auf der obigen Analyse haben wir die erste grundlegende Schwierigkeit von CV durch den Unterschied zwischen CV und NLP eingeführt, nämlich semantische Sparsamkeit. Die anderen beiden Schwierigkeiten, Unterschiede zwischen Domänen und unendliche Granularität, hängen in gewisser Weise mit den oben genannten wesentlichen Unterschieden zusammen. Gerade weil die Semantik beim Sampling von Bildern nicht berücksichtigt wird, korrelieren die Sampling-Ergebnisse (d. h. Bildpixel) beim Sampling verschiedener Domänen (d. h. unterschiedlicher Verteilungen wie Tag und Nacht, sonnige und regnerische Tage usw.) stark mit Domänenmerkmale, was zu Domänenunterschieden zwischen führt. Da die grundlegende semantische Einheit eines Bildes schwer zu definieren ist (während Text leicht zu definieren ist) und die durch das Bild ausgedrückten Informationen reich und vielfältig sind, kann der Mensch gleichzeitig nahezu unendlich feine semantische Informationen aus dem Bild gewinnen. weit über jedes aktuelle CV-Feld hinaus. Die durch diesen Bewertungsindex definierte Fähigkeit ist unendliche Granularität. Bezüglich der unendlichen Granularität habe ich einmal einen Artikel geschrieben, der sich speziell mit diesem Thema befasst. https://zhuanlan.zhihu.com/p/376145664
Ausgehend von den oben genannten drei Grundschwierigkeiten fassen wir die Forschungsrichtungen der Branche in den letzten Jahren wie folgt zusammen:
-
Semantische Sparsität: Die Lösung besteht darin, effiziente Rechenmodelle (neuronale Netze) und visuelles Vortraining zu erstellen. Die Hauptlogik besteht hier darin, dass Sie, wenn Sie die Informationsdichte der Daten erhöhen möchten, die ungleichmäßige Verteilung der Daten annehmen und modellieren müssen (Informationstheorie) (d. h. die vorherige Verteilung der Daten lernen müssen). Derzeit gibt es zwei Arten der effizientesten Modellierungsmethoden. Eine besteht darin, das Design neuronaler Netzwerkarchitekturen zu verwenden, um datenunabhängige Prior-Verteilungen zu erfassen (z. B. entspricht das Faltungsmodul der lokalen Prior-Verteilung von Bilddaten und das Transformatormodul). Die erste Möglichkeit besteht darin, die datenbezogene vorherige Verteilung durch Vorabtraining auf großen Datenmengen zu erfassen. Diese beiden Forschungsrichtungen sind auch die grundlegendsten und am meisten betroffenen im Bereich der visuellen Erkennung.
-
Interdomänenvariabilität: Die Lösung ist ein dateneffizienter Feinabstimmungsalgorithmus. Gemäß der obigen Analyse ist der im Berechnungsmodell gespeicherte Prior umso stärker, je größer das Netzwerk und je größer der Datensatz vor dem Training ist. Wenn jedoch ein großer Unterschied in der Datenverteilung zwischen der Vortrainingsdomäne und der Zieldomäne besteht, bringt dieser starke Prior Nachteile mit sich, da uns die Informationstheorie sagt: Die Informationsdichte bestimmter Teile (Vortrainingsdomäne) wird erhöht Reduzieren Sie auf jeden Fall die Informationsdichte anderer Teile (Teile, die nicht im Vortrainingsbereich enthalten sind, d. h. Teile, die während des Vortrainingsprozesses als unwichtig angesehen werden). In der Realität ist es wahrscheinlich, dass ein Teil oder die gesamte Zieldomäne in den unbeteiligten Teil fällt, was zu einer schlechten direkten Übertragung des vorab trainierten Modells führt (d. h. Überanpassung). Zu diesem Zeitpunkt ist eine Anpassung an die neue Datenverteilung durch Feinabstimmung in der Zieldomäne erforderlich. Wenn man bedenkt, dass das Datenvolumen der Zieldomäne oft viel kleiner ist als das der Pre-Training-Domäne, ist die Dateneffizienz eine wesentliche Annahme. Darüber hinaus müssen Modelle aus praktischer Sicht in der Lage sein, sich an sich ändernde Bereiche anzupassen, sodass lebenslanges Lernen ein Muss ist.
-
Unendliche Granularität: Die Lösung ist ein offener Domänenerkennungsalgorithmus. Unendliche Granularität umfasst Open-Domain-Funktionen und ist ein höheres Ziel. Die Forschung in diese Richtung ist noch vorläufig, insbesondere da es in der Branche keine allgemein anerkannten Datensätze zur Erkennung offener Domänen und Bewertungsindikatoren gibt. Eine der wichtigsten Fragen hierbei ist die Einführung von Open-Domain-Funktionen in die visuelle Erkennung. Die gute Nachricht ist, dass mit dem Aufkommen modalübergreifender Pre-Training-Methoden (insbesondere CLIP im Jahr 2021) die natürliche Sprache meiner Meinung nach in Zukunft immer mehr zum Traktor der offenen Domänenerkennung wird 2-3 Jahre. Allerdings bin ich mit den verschiedenen Zero-Shot-Erkennungsaufgaben, die im Zuge der Open-Domain-Erkennung entstanden sind, nicht einverstanden. Ich denke, Zero-Shot selbst ist eine falsche Behauptung. Es gibt keine Zero-Shot-Identifizierungsmethode auf der Welt und es besteht auch keine Notwendigkeit dafür. Bestehende Zero-Shot-Aufgaben verwenden alle unterschiedliche Methoden, um Informationen an den Algorithmus weiterzugeben, und die Weitergabemethoden variieren stark, was einen fairen Vergleich zwischen verschiedenen Methoden erschwert. In dieser Richtung schlage ich eine Methode namens visuelle Erkennung auf Abruf vor, um die unendliche Granularität der visuellen Erkennung weiter offenzulegen und zu erforschen.
Hier bedarf es einer zusätzlichen Erklärung. Aufgrund der Unterschiede in der Größe des Datenraums und der strukturellen Komplexität kann das CV-Feld das Problem der Unterschiede zwischen Domänen zumindest bisher nicht direkt durch vorab trainierte Modelle lösen, das NLP-Feld ist jedoch nahe an diesem Punkt. Daher haben wir gesehen, dass NLP-Wissenschaftler aufforderungsbasierte Methoden verwenden, um Dutzende oder Hunderte von nachgelagerten Aufgaben zu vereinheitlichen, aber das Gleiche ist im Bereich Lebenslauf nicht passiert. Darüber hinaus besteht der Kern des im NLP vorgeschlagenen Skalierungsgesetzes darin, ein größeres Modell zu verwenden, um den Datensatz vor dem Training zu überanpassen. Mit anderen Worten, für NLP stellt Überanpassung kein Problem mehr dar, da der Datensatz vor dem Training mit kleinen Eingabeaufforderungen ausreicht, um die Verteilung des gesamten semantischen Raums darzustellen. Dies wurde jedoch im CV-Bereich nicht erreicht, sodass auch die Domänenmigration in Betracht gezogen werden muss und der Kern der Domänenmigration darin besteht, eine Überanpassung zu vermeiden. Mit anderen Worten: In den nächsten zwei bis drei Jahren wird der Forschungsschwerpunkt von CV und NLP sehr unterschiedlich sein. Daher ist es sehr gefährlich, die Denkweise einer Richtung in die andere Richtung zu kopieren. Das Folgende ist eine kurze Analyse der einzelnen Forschungsrichtungen . In den folgenden 10 Jahren (bis heute) hat das Design neuronaler Netzwerkarchitekturen einen Prozess vom manuellen Design zum automatischen Design und zurück zum manuellen Design (Einführung komplexerer Rechenmodule) durchlaufen:
- 2012-2017, manueller Aufbau tieferer neuronaler Faltungsnetze und Erforschung allgemeiner Optimierungstechniken. Schlüsselwörter: ReLU, Dropout, 3x3-Faltung, BN, Verbindung überspringen usw. In diesem Stadium ist die Faltungsoperation die grundlegendste Einheit, die der Lokalität vor Bildmerkmalen entspricht.
- 2017-2020, baut automatisch komplexere neuronale Netze auf. Unter ihnen erfreute sich Network Architecture Search (NAS) eine Zeit lang großer Beliebtheit und etablierte sich schließlich als grundlegendes Werkzeug. In jedem gegebenen Suchraum kann das automatische Design etwas bessere Ergebnisse erzielen und sich schnell an unterschiedliche Rechenkosten anpassen.
- Seit 2020 wurde das aus NLP stammende Transformatormodul in CV eingeführt und nutzt den Aufmerksamkeitsmechanismus, um die Fernmodellierungsfunktionen neuronaler Netze zu ergänzen. Mit Hilfe von Architekturen, die Transformatoren beinhalten, werden heute für die meisten Sehaufgaben optimale Ergebnisse erzielt.
Für die Zukunft dieser Richtung urteile ich wie folgt:
- Wenn sich die visuelle Erkennungsaufgabe nicht wesentlich ändert, wird sich weder das automatische Design noch das Hinzufügen komplexerer Rechenmodule ändern in der Lage sein, den Lebenslauf auf ein neues Niveau zu heben. Mögliche Änderungen bei visuellen Erkennungsaufgaben lassen sich grob in zwei Teile unterteilen: Eingabe und Ausgabe. Mögliche Änderungen im Eingabeteil, z. B. bei der Ereigniskamera, können den Status quo der regulären Verarbeitung statischer oder sequentieller visueller Signale ändern und zu bestimmten neuronalen Netzwerkstrukturen führen, die eine Art Rahmen (Richtung) darstellen 3 wird besprochen) hat das Potenzial, die visuelle Erkennung von unabhängigen Aufgaben zu einer einheitlichen Aufgabe zu verlagern und so eine Netzwerkarchitektur zu schaffen, die besser für visuelle Eingabeaufforderungen geeignet ist.
- Wenn Sie sich zwischen Faltung und Transformator entscheiden müssen, hat der Transformator ein größeres Potenzial, vor allem weil er verschiedene Datenmodalitäten vereinheitlichen kann, insbesondere Text und Bild, die beiden häufigsten und wichtigsten Modalitäten.
- Interpretierbarkeit ist eine sehr wichtige Forschungsrichtung, aber ich persönlich bin pessimistisch, was die Interpretierbarkeit tiefer neuronaler Netze angeht. Der Erfolg von NLP basiert nicht auf Interpretierbarkeit, sondern auf der Überanpassung großer Korpora. Das ist möglicherweise kein gutes Zeichen für echte KI.
Richtung 1b: Visuelles Vortraining
Als aktuelle Richtung im Lebenslaufbereich setzen Vortrainingsmethoden große Hoffnungen. Im Zeitalter des Deep Learning kann das visuelle Vortraining in drei Kategorien unterteilt werden: überwacht, unbeaufsichtigt und modalübergreifend. Die allgemeine Beschreibung lautet wie folgt:
- Die Entwicklung des überwachten Vortrainings ist relativ klar. Da Klassifizierungsdaten auf Bildebene am einfachsten zu erhalten sind, gab es lange vor dem Ausbruch des Deep Learning den ImageNet-Datensatz, der den Grundstein für Deep Learning in der Zukunft legen sollte, und er wird auch heute noch verwendet. Der gesamte ImageNet-Datensatz übersteigt 15 Millionen und wurde von anderen nicht klassifizierten Datensätzen nicht übertroffen. Daher handelt es sich immer noch um die am häufigsten verwendeten Daten im überwachten Vortraining. Ein weiterer Grund besteht darin, dass Klassifizierungsdaten auf Bildebene weniger Verzerrungen mit sich bringen, was für die Downstream-Migration vorteilhafter ist. Eine weitere Reduzierung der Verzerrungen erfolgt durch unbeaufsichtigtes Vortraining.
- Das unbeaufsichtigte Vortraining hat einen mühsamen Entwicklungsprozess durchlaufen. Ab 2014 erschien die erste Generation unbeaufsichtigter, auf Geometrie basierender Pre-Training-Methoden, wie z. B. die Beurteilung anhand von Patch-Positionsbeziehungen, Bildrotation usw., und auch generative Methoden entwickeln sich ständig weiter (generative Methoden lassen sich auf frühere Zeiten zurückführen). , was hier nicht beschrieben wird). Derzeit ist die unbeaufsichtigte Vortrainingsmethode immer noch deutlich schwächer als die überwachte Vortrainingsmethode. Nach technischen Verbesserungen zeigte die kontrastive Lernmethode im Jahr 2019 erstmals das Potenzial, die überwachte Vorschulungsmethode bei nachgelagerten Aufgaben zu übertreffen. Unüberwachtes Lernen ist wirklich zum Mittelpunkt der Lebenslaufwelt geworden. Ab 2021 hat der Aufstieg visueller Transformatoren zu einer besonderen Art generativer Aufgabe, MIM, geführt, die sich nach und nach zur vorherrschenden Methode entwickelt hat.
- Neben dem rein betreuten und unbeaufsichtigten Vortraining gibt es auch eine Art Methode dazwischen, nämlich das modalübergreifende Vortraining. Es verwendet schwach gepaarte Bilder und Texte als Trainingsmaterialien. Einerseits vermeidet es die durch Bildüberwachungssignale verursachte Verzerrung und andererseits kann es schwache Semantiken besser lernen als unbeaufsichtigte Methoden. Darüber hinaus ist die Integration von visueller und natürlicher Sprache mithilfe des Transformators natürlicher und sinnvoller.
Basierend auf der obigen Bewertung treffe ich folgendes Urteil:
- Aus praktischer Anwendungssicht sollten verschiedene Vortrainingsaufgaben kombiniert werden. Das heißt, es sollte ein gemischter Datensatz erfasst werden, der eine kleine Menge beschrifteter Daten (noch stärker beschriftete Daten wie Erkennung und Segmentierung), eine mittlere Menge Bild-Text-Paardaten und eine große Menge Bilddaten ohne Daten enthält beliebige Beschriftungen und in solchen gemischten Daten Entwerfen Sie zentral Vortrainingsmethoden.
- Im Lebenslaufbereich ist die unbeaufsichtigte Vorschulung die Forschungsrichtung, die die Natur der Vision am besten widerspiegelt. Obwohl das modalübergreifende Vortraining große Auswirkungen auf die gesamte Richtung hatte, halte ich das unbeaufsichtigte Vortraining immer noch für sehr wichtig und muss beibehalten werden. Es sollte darauf hingewiesen werden, dass die Idee des visuellen Vortrainings weitgehend vom Vortraining in natürlicher Sprache beeinflusst wird, die Natur der beiden jedoch unterschiedlich ist und daher nicht verallgemeinert werden kann. Insbesondere handelt es sich bei der natürlichen Sprache selbst um von Menschen erstellte Daten, in denen jedes Wort und jedes Zeichen von Menschen geschrieben wird und natürlich eine semantische Bedeutung hat. Daher können NLP-Vortrainingsaufgaben im engeren Sinne nicht als real angesehen werden Das unbeaufsichtigte Vortraining ist allenfalls schwach betreutes Vortraining. Aber das Sehen ist anders. Bei Bildsignalen handelt es sich um Rohdaten, die objektiv vorliegen und nicht von Menschen verarbeitet wurden. Die unbeaufsichtigte Vorschulungsaufgabe muss schwieriger sein. Kurz gesagt: Auch wenn modalübergreifendes Vortraining den visuellen Algorithmus in der Technik voranbringen und bessere Erkennungsergebnisse erzielen kann, muss das wesentliche Problem des Sehens immer noch durch das Sehen selbst gelöst werden.
- Derzeit besteht die Essenz des rein visuellen, unbeaufsichtigten Vortrainings darin, aus der Verschlechterung zu lernen. Unter Verschlechterung versteht man hier das Entfernen einiger vorhandener Informationen aus dem Bildsignal, sodass der Algorithmus diese Informationen wiederherstellen muss: Geometrische Methoden entfernen geometrische Verteilungsinformationen (z. B. die relative Position von Patches); Kontrastmethoden entfernen die Gesamtinformationen des Bildes (durch Extrahieren verschiedener Ansichten). ); die Generierungsmethode wie MIM entfernt die lokalen Informationen des Bildes. Diese auf Degradation basierende Methode weist einen unüberwindbaren Engpass auf, nämlich den Konflikt zwischen Degradationsintensität und semantischer Konsistenz. Da es kein überwachtes Signal gibt, hängt das Lernen der visuellen Darstellung vollständig von der Verschlechterung ab. Wenn die Verschlechterung stark genug ist, gibt es keine Garantie dafür, dass die Bilder vor und nach der Verschlechterung semantisch konsistent sind, was zu einer schlechten Konditionierung führt Ziele vor dem Training. Wenn beispielsweise zwei Ansichten, die beim vergleichenden Lernen aus einem Bild extrahiert wurden, keine Beziehung zueinander haben, ist es nicht sinnvoll, ihre Merkmale näher zusammenzubringen. Wenn die MIM-Aufgabe wichtige Informationen (z. B. Gesichter) im Bild entfernt, ist es nicht sinnvoll, diese Informationen zu rekonstruieren . Vernünftig. Die erzwungene Ausführung dieser Aufgaben führt zu einer gewissen Voreingenommenheit und schwächt die Generalisierungsfähigkeit des Modells. In Zukunft sollte es eine Lernaufgabe geben, die keine Verschlechterung erfordert, und ich persönlich glaube, dass Lernen durch Komprimierung ein machbarer Weg ist.
Richtung 2: Modellfeinabstimmung und lebenslanges Lernen
#🎜 🎜#
Als Grundproblem hat sich bei der Modellfeinabstimmung eine Vielzahl unterschiedlicher Einstellungen entwickelt. Wenn Sie verschiedene Einstellungen vereinheitlichen möchten, können Sie sich drei Datensätze vorstellen, nämlich den Vortrainingsdatensatz Dpre (unsichtbar), den Zieltrainingssatz Dtrain und den Zieltestsatz Dtest (unsichtbar und unvorhersehbar). Abhängig von den Annahmen über die Beziehung zwischen den dreien können die populäreren Einstellungen wie folgt zusammengefasst werden:
- Transfer-Lernen: Angenommen, die Datenverteilung von Dpre oder Dtrain und Dtest ist sehr unterschiedlich;
- Schwach überwachtes Lernen: Angenommen, Dtrain liefert nur unvollständige Annotationsinformationen; Lernen: Gehen Sie davon aus, dass nur ein Teil der Daten in Dtrain beschriftet ist.
- Lernen mit Rauschen: Gehen Sie davon aus, dass einige der Daten in Dtrain möglicherweise falsch beschriftet sind
- Kontinuierliches Lernen: Gehen Sie davon aus, dass weiterhin neue Dtrains angezeigt werden, sodass der von Dpre gelernte Inhalt während des Lernprozesses möglicherweise vergessen wird
- ...
- Im Allgemeinen ist es schwierig, einen einheitlichen Rahmen zu finden, um die Entwicklung und das Genre von Methoden zur Modellfeinabstimmung zu analysieren. Aus technischer und praktischer Sicht liegt der Schlüssel zur Modellfeinabstimmung in der vorherigen Beurteilung der Größe der Unterschiede zwischen Domänen. Wenn Sie der Meinung sind, dass der Unterschied zwischen Dpre und Dtrain sehr groß sein könnte, müssen Sie den Anteil der vom vorab trainierten Netzwerk auf das Zielnetzwerk übertragenen Gewichte reduzieren oder einen speziellen Kopf hinzufügen, um diesen Unterschied auszugleichen Der Unterschied zwischen Dtrain und Dtest kann sehr groß sein. Es ist notwendig, während des Feinabstimmungsprozesses eine stärkere Regularisierung hinzuzufügen, um eine Überanpassung zu verhindern, oder während des Testprozesses einige Online-Statistiken einzuführen, um die Unterschiede so weit wie möglich auszugleichen. Zu den verschiedenen oben genannten Settings gibt es umfangreiche Forschungsarbeiten, die sehr zielgerichtet sind und hier nicht im Detail besprochen werden.
- In Bezug auf diese Richtung gibt es meiner Meinung nach zwei wichtige Themen:
Vereinigung vom isolierten Umfeld zum lebenslangen Lernen. Von der Wissenschaft bis zur Industrie müssen wir das Denken eines „einmaligen Bereitstellungsmodells“ aufgeben und den Bereitstellungsinhalt als eine modellzentrierte Werkzeugkette verstehen, die mit mehreren Funktionen wie Datenverwaltung, Modellwartung und Modellbereitstellung ausgestattet ist. Aus Branchensicht muss ein Modell oder eine Reihe von Systemen während des gesamten Projektlebenszyklus vollständig betreut werden. Es muss berücksichtigt werden, dass die Benutzerbedürfnisse veränderlich und unvorhersehbar sind. Heute kann die Kamera gewechselt werden, morgen müssen möglicherweise neue Zieltypen erkannt werden und so weiter. Wir streben nicht danach, dass KI alle Probleme autonom löst, aber KI-Algorithmen sollten über einen standardisierten Betriebsprozess verfügen, damit Menschen, die KI nicht verstehen, diesem Prozess folgen, die gewünschten Bedürfnisse hinzufügen und die Probleme lösen können, auf die sie normalerweise stoßen Wie kann KI es wirklich der breiten Masse zugänglich machen und praktische Probleme lösen? Für die Wissenschaft ist es notwendig, so schnell wie möglich ein Umfeld für lebenslanges Lernen zu definieren, das mit realen Szenarien übereinstimmt, entsprechende Benchmarks zu etablieren und die Forschung in diese Richtung zu fördern.
Konflikte zwischen Big Data und kleinen Stichproben lösen, wenn es offensichtliche Unterschiede zwischen Domänen gibt. Dies ist ein weiterer Unterschied zwischen CV und NLP: NLP muss grundsätzlich nicht die domänenübergreifenden Unterschiede zwischen Vortrainings- und Downstream-Aufgaben berücksichtigen, da die grammatikalische Struktur genau die gleiche ist wie bei gebräuchlichen Wörtern, während CV davon ausgehen muss, dass die Upstream- und Downstream-Aufgaben unterschiedlich sind Datenverteilungen unterscheiden sich erheblich, sodass die zugrunde liegenden Merkmale nicht aus den Downstream-Daten extrahiert werden können, wenn das Upstream-Modell nicht fein abgestimmt ist (sie werden direkt von Einheiten wie ReLU herausgefiltert). Daher ist die Verwendung kleiner Daten zur Feinabstimmung eines großen Modells im NLP-Bereich kein großes Problem (der aktuelle Mainstream besteht darin, nur Eingabeaufforderungen zu optimieren), im CV-Bereich jedoch ein großes Problem. Hier mag die Gestaltung visuell freundlicher Eingabeaufforderungen ein guter Ansatz sein, die aktuelle Forschung ist jedoch noch nicht beim Kernthema angelangt.
- Richtung 3: Aufgabe zur unendlich feinkörnigen visuellen Erkennung
- Es gibt nicht viele relevante Forschungsarbeiten zur unendlich feinkörnigen visuellen Erkennung (und ähnlichen Konzepten). Daher werde ich dieses Problem auf meine eigene Weise beschreiben. Im diesjährigen VALSE-Bericht habe ich die bestehenden Methoden und unseren Vorschlag ausführlich erläutert. Eine ausführlichere Erklärung finden Sie in meinem speziellen Artikel oder dem Bericht, den ich über VALSE erstellt habe:
https://zhuanlan.zhihu.com/p/546510418https://zhuanlan. zhihu. com/p/555377882
Zuerst möchte ich die Bedeutung der unendlich feinkörnigen visuellen Erkennung erklären. Einfach ausgedrückt enthalten Bilder sehr umfangreiche semantische Informationen, verfügen jedoch nicht über klare semantische Grundeinheiten. Solange Menschen dazu bereit sind, können sie immer feinkörnigere semantische Informationen aus einem Bild identifizieren (wie in der Abbildung unten gezeigt). Es ist jedoch schwierig, diese Informationen durch begrenzte und standardisierte Annotationen weiterzugeben (selbst wenn ausreichende Annotationskosten aufgewendet werden). Bilden Sie einen semantisch vollständigen Datensatz für das Algorithmenlernen.

Selbst fein gekennzeichneten Datensätzen wie ADE20K fehlt viel semantischer Inhalt, den Menschen kann erkennen
Wir glauben, dass eine unendlich feinkörnige visuelle Erkennung schwieriger und wichtiger ist als das Ziel der visuellen Erkennung im offenen Bereich. Wir untersuchen bestehende Erkennungsmethoden, unterteilen sie in zwei Kategorien, nämlich klassifizierungsbasierte Methoden und sprachgesteuerte Methoden, und diskutieren die Gründe, warum sie keine unendliche Feinkörnigkeit erreichen können.
- Klassifizierungsbasierte Methoden: Dies umfasst Klassifizierung, Erkennung, Segmentierung und andere Methoden im traditionellen Sinne Eigenschaften Es dient dazu, jeder grundlegenden semantischen Einheit (Bild, Box, Maske, Schlüsselpunkt usw.) im Bild eine Kategoriebezeichnung zuzuweisen. Der fatale Fehler dieser Methode besteht darin, dass mit zunehmender Granularität der Erkennung zwangsläufig die Erkennungssicherheit abnimmt, dh Granularität und Sicherheit stehen im Konflikt. In ImageNet gibt es beispielsweise zwei Hauptkategorien: „Möbel“ und „Elektrogeräte“; offensichtlich gehört „Stuhl“ zu „Möbel“ und „Fernseher“ zu „Haushaltsgeräte“, aber gehört „Massagesessel“ zu „ „Möbel“ oder „Haushaltsgeräte“ ist schwer zu beurteilen – dies ist die Abnahme der Sicherheit, die durch die Erhöhung der semantischen Granularität verursacht wird. Wenn auf dem Foto eine „Person“ mit sehr geringer Auflösung vorhanden ist und der „Kopf“ oder sogar „Augen“ dieser „Person“ zwangsweise beschriftet wird, können die Urteile verschiedener Kommentatoren unterschiedlich sein. Auch wenn es sich um ein oder zwei Pixel handelt, wirkt sich die Abweichung auch stark auf Indikatoren wie IoU aus – dies ist die Abnahme der Sicherheit, die durch die Zunahme der räumlichen Granularität verursacht wird.
- Sprachgesteuerte Methoden: Dazu gehören die von CLIP gesteuerte visuelle Prompt-Klassenmethode sowie das länger bestehende Problem der visuellen Erdung usw. Seine Grundfunktion besteht darin, Sprache zu verwenden, um auf semantische Informationen in Bildern zu verweisen und diese zu identifizieren. Die Einführung der Sprache hat tatsächlich die Flexibilität der Erkennung erhöht und natürliche Eigenschaften offener Domänen mit sich gebracht. Allerdings verfügt die Sprache selbst nur über begrenzte Verweisfähigkeiten (stellen Sie sich vor, Sie beziehen sich auf eine bestimmte Person in einer Szene mit Hunderten von Menschen) und kann die Anforderungen einer unendlich feinkörnigen visuellen Erkennung nicht erfüllen. Letztlich sollte die Sprache im Bereich der visuellen Erkennung eine Rolle bei der Unterstützung des Sehens spielen, und die vorhandenen visuellen Eingabeaufforderungsmethoden wirken etwas überwältigend.
Die obige Umfrage zeigt uns, dass die aktuellen visuellen Erkennungsmethoden nicht unendlich feinkörnige Ziele erreichen können und auf dem Weg sind Auch auf dem Weg zur unendlichen Feinkörnigkeit wird man auf unüberwindbare Schwierigkeiten stoßen. Deshalb wollen wir analysieren, wie Menschen diese Schwierigkeiten lösen. Erstens müssen Menschen in den meisten Fällen keine expliziten Klassifizierungsaufgaben durchführen: Um auf das obige Beispiel zurückzukommen: Eine Person geht in ein Einkaufszentrum, um etwas zu kaufen, unabhängig davon, ob das Einkaufszentrum den „Massagesessel“ in die „Möbel“ stellt. Durch einfache Orientierung kann der Mensch schnell den Bereich finden, in dem sich der „Massagesessel“ befindet. Zweitens sind Menschen nicht auf die Verwendung von Sprache beschränkt, um auf Objekte in Bildern zu verweisen. Sie können flexiblere Methoden verwenden (z. B. mit den Händen auf Objekte zeigen), um die Referenz zu vervollständigen und eine detailliertere Analyse durchzuführen.
In Kombination mit diesen Analysen müssen die folgenden drei Bedingungen erfüllt sein, um das Ziel der unendlichen Feinkörnigkeit zu erreichen.
- Offenheit: Offene Domänenerkennung ist ein Unterziel der unendlichen feinkörnigen Erkennung. Derzeit ist die Einführung von Sprache eine der besten Lösungen, um Offenheit zu erreichen.
- Besonderheit: Bei der Einführung in die Sprache sollte man sich nicht an die Sprache binden, sondern ein visuell ansprechendes Referenzschema (also Erkennungsaufgabe) entwerfen.
- Variable Granularität: Es ist nicht immer erforderlich, die feinste Granularität zu erkennen, aber die Granularität der Erkennung kann je nach Bedarf flexibel geändert werden.
Unter der Anleitung dieser drei Bedingungen haben wir eine visuelle Erkennungsaufgabe auf Abruf entworfen. Im Gegensatz zur einheitlichen visuellen Erkennung im herkömmlichen Sinne verwendet die visuelle On-Demand-Erkennung eine Anfrage als Einheit für Annotation, Lernen und Bewertung. Derzeit unterstützt das System zwei Arten von Anforderungen, die eine Segmentierung von Instanz zu Semantik und eine Segmentierung von Semantik zu Instanz realisieren. Daher kann durch die Kombination beider eine Bildsegmentierung mit beliebiger Feinheit erreicht werden. Ein weiterer Vorteil der visuellen On-Demand-Erkennung besteht darin, dass das Anhalten nach Abschluss einer beliebigen Anzahl von Anforderungen keinen Einfluss auf die Genauigkeit der Annotation hat (selbst wenn eine große Menge an Informationen nicht annotiert ist), was sich positiv auf die Skalierbarkeit offener Domänen (z. B. Hinzufügen) auswirkt neue semantische Kategorien) haben große Vorteile. Spezifische Details finden Sie im Artikel zur visuellen On-Demand-Erkennung (siehe Link oben).
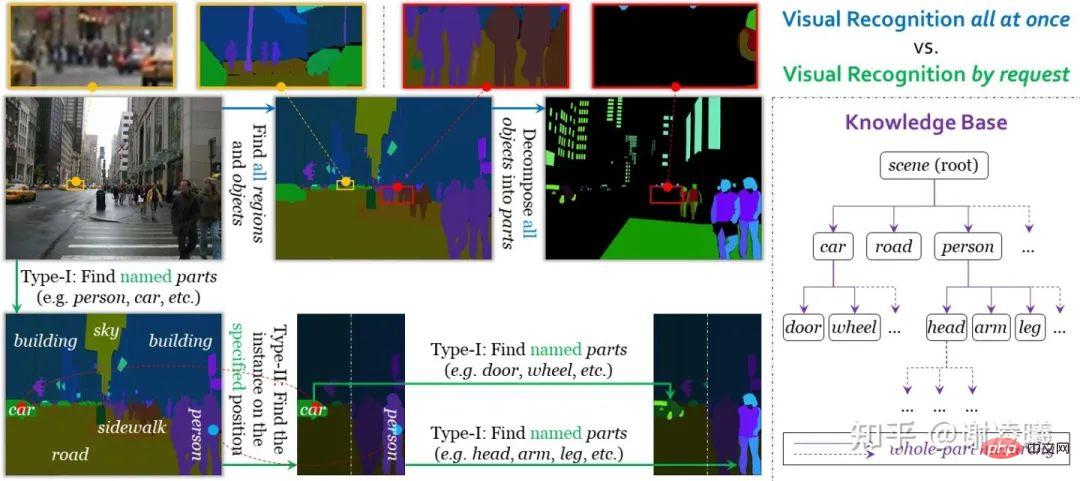
Vergleich zwischen einheitlicher visueller Identität und visueller On-Demand-Identität
Nach Abschluss dieses Artikels denke ich immer noch über die Auswirkungen der visuellen On-Demand-Identität auf andere Richtungen nach. Hier werden zwei Perspektiven bereitgestellt:
- Anfrage in der visuellen On-Demand-Erkennung ist im Wesentlichen eine visuell freundliche Eingabeaufforderung. Es kann nicht nur den Zweck der Abfrage des visuellen Modells erreichen, sondern auch die Mehrdeutigkeit der Referenz vermeiden, die durch reine Sprachaufforderungen verursacht wird. Da immer mehr Arten von Anfragen eingeführt werden, wird erwartet, dass dieses System ausgereifter wird.
- Die visuelle Erkennung auf Abruf bietet die Möglichkeit, verschiedene visuelle Aufgaben formal zu vereinheitlichen. Beispielsweise werden Aufgaben wie Klassifizierung, Erkennung und Segmentierung in diesem Framework vereinheitlicht. Dies kann Inspiration für das visuelle Vortraining sein. Derzeit ist die Grenze zwischen visuellem Vortraining und nachgelagerter Feinabstimmung noch unklar. Es ist noch unklar, ob das vorab trainierte Modell für verschiedene Aufgaben geeignet sein oder sich auf die Verbesserung bestimmter Aufgaben konzentrieren soll. Wenn es jedoch zu einer formal einheitlichen Anerkennungsaufgabe kommt, ist diese Debatte möglicherweise nicht mehr relevant. Übrigens ist auch die formale Vereinheitlichung nachgelagerter Aufgaben ein großer Vorteil des NLP-Bereichs.
Außerhalb der oben genannten Richtungen
Ich teile die Probleme im Lebenslaufbereich in drei Hauptkategorien ein: Erkennung, Generierung und Interaktion, und Erkennung ist nur das einfachste Problem unter ihnen. Bezüglich dieser drei Teilbereiche lautet eine kurze Analyse wie folgt:
- Im Bereich der Anerkennung sind herkömmliche Anerkennungsindikatoren offensichtlich veraltet, daher benötigen die Menschen aktualisierte Bewertungsindikatoren. Derzeit ist die Einführung natürlicher Sprache in die visuelle Erkennung ein offensichtlicher und unumkehrbarer Trend, der jedoch bei weitem nicht ausreicht. Die Branche benötigt mehr Innovationen auf Aufgabenebene.
- Generierung ist eine fortgeschrittenere Fähigkeit als Erkennung. Menschen können eine Vielzahl gängiger Objekte leicht erkennen, aber nur wenige können realistische Objekte zeichnen. Aus der Sprache des statistischen Lernens liegt dies daran, dass das generative Modell die gemeinsame Verteilung p (x, y) modellieren muss, während das Diskriminanzmodell nur die bedingte Verteilung p (y | x) modellieren muss: Ersteres kann Letzteres ableiten kann nicht aus Letzterem abgeleitet werden, aber Ersteres kann nicht aus Letzterem abgeleitet werden. Gemessen an der Entwicklung der Branche muss die Qualität der Bilderzeugung zwar weiter verbessert werden, die Stabilität und Kontrollierbarkeit der generierten Inhalte (ohne offensichtlich unrealistische Inhalte zu erzeugen) muss jedoch noch verbessert werden. Gleichzeitig unterstützt der generierte Inhalt den Erkennungsalgorithmus immer noch relativ schwach, und es ist für Menschen schwierig, virtuelle Daten und synthetische Daten vollständig zu nutzen, um Ergebnisse zu erzielen, die mit dem Training mit realen Daten vergleichbar sind. Für diese beiden Probleme sind wir der Ansicht, dass wir bessere und wesentlichere Bewertungsindikatoren entwerfen müssen, um bestehende Indikatoren zu ersetzen (Ersetzen von FID, IS usw. für Generierungsaufgaben, während die Generierungs- und Identifizierungsaufgaben kombiniert werden müssen, um a zu definieren). einheitlicher Bewertungsindex).
- 1978 stellte sich der Computer-Vision-Pionier David Marr vor, dass die Hauptfunktion des Sehens darin besteht, ein dreidimensionales Modell der Umgebung zu erstellen und während der Interaktion damit interagieren Wissen lernen. Im Vergleich zu Erkennung und Generierung ähnelt die Interaktion eher menschlichen Lernmethoden, es gibt jedoch derzeit relativ wenige Studien in der Branche. Die Hauptschwierigkeit bei der Interaktionsforschung liegt in der Konstruktion einer realen Interaktionsumgebung. Genauer gesagt beruht die aktuelle Konstruktionsmethode visueller Datensätze auf einer spärlichen Abtastung der Umgebung, während die Interaktion eine kontinuierliche Abtastung erfordert. Offensichtlich ist Interaktion das A und O, um das grundlegende Problem des Sehens zu lösen. Obwohl es in der Branche viele verwandte Studien gibt (z. B. zur verkörperten Intelligenz), haben sich bisher keine universellen, aufgabengesteuerten Lernziele herauskristallisiert. Wir wiederholen noch einmal die Idee des Computer-Vision-Pioniers David Marr: Die Hauptfunktion des Sehens besteht darin, ein dreidimensionales Modell der Umgebung zu erstellen und Wissen durch Interaktion zu erlernen. Computer Vision, einschließlich anderer KI-Richtungen, sollte sich in diese Richtung entwickeln, um wirklich praktisch zu werden.
Kurz gesagt, in verschiedenen Teilbereichen, die sich ausschließlich auf die starken Anpassungsfähigkeiten des statistischen Lernens (insbesondere tief) verlassen Lernen) Alle Versuche haben ihr Limit erreicht. Zukünftige Entwicklungen müssen auf einem grundlegenderen Verständnis des Lebenslaufs basieren, und die Festlegung sinnvollerer Bewertungsindikatoren für verschiedene Aufgaben ist der erste Schritt, den wir unternehmen müssen.
Fazit
Nach mehreren intensiven akademischen Austauschen kann ich die Verwirrung in der Branche deutlich spüren Zumindest für die visuelle Wahrnehmung (Erkennung) gibt es immer weniger interessante und wertvolle Forschungsfragen und die Schwelle wird immer höher. Wenn dies so weitergeht, ist es möglich, dass die CV-Forschung in naher Zukunft den Weg des NLP einschlägt und sich schrittweise in zwei Kategorien aufteilt: Der eine Typ verbraucht riesige Mengen an Rechenressourcen für das Vortraining und der andere aktualisiert SOTA ständig vergeblich Der Typ entwirft ständig neue, aber bedeutungslose Umgebungen, um Innovationen voranzutreiben. Das ist offensichtlich keine gute Sache für den Lebenslaufbereich. Um so etwas zu vermeiden, muss die Industrie neben der ständigen Erforschung der Natur der Vision und der Schaffung wertvollerer Bewertungsindikatoren auch die Toleranz erhöhen, insbesondere die Toleranz gegenüber Nicht-Mainstream-Richtungen. Beschweren Sie sich nicht über die Homogenität der Forschung und sich gleichzeitig über die Homogenität der Forschung beschweren. Einreichungen, die SOTA nicht erreichen, sind eine Nervensäge. Der aktuelle Engpass ist eine Herausforderung für alle. Wenn die Entwicklung der KI stagniert, kann niemand davor zurückschrecken. Danke, dass du bis zum Ende zugeschaut hast. Freundliche Diskussion willkommen.
Erklärung des AutorsAlle Inhalte geben nur die eigene Meinung des Autors wieder und können widerrufen werden muss eine Erklärung beiliegen. Danke!
Das obige ist der detaillierte Inhalt vonHuaweis junges Genie Xie Lingxi: Persönliche Ansichten zur Entwicklung des Bereichs der visuellen Erkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


 Welche Dateitypen gibt es?
Welche Dateitypen gibt es?
 Was tun, wenn das Installationssystem die Festplatte nicht findet?
Was tun, wenn das Installationssystem die Festplatte nicht findet?
 Was man im Programmierkurs lernen kann
Was man im Programmierkurs lernen kann
 Welche Antivirensoftware gibt es?
Welche Antivirensoftware gibt es?
 Welcher Ordner ist AppData, der gelöscht werden kann?
Welcher Ordner ist AppData, der gelöscht werden kann?
 keine solche Dateilösung
keine solche Dateilösung
 Konfiguration der Java-Umgebungsvariablen
Konfiguration der Java-Umgebungsvariablen
 Allgemeine Verwendung von Array.slice
Allgemeine Verwendung von Array.slice








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



