
 Technologie-Peripheriegeräte
KI
Der TabTransformer-Konverter verbessert die Leistung von mehrschichtigen Perzeptronen und führt eine eingehende Analyse durch
Technologie-Peripheriegeräte
KI
Der TabTransformer-Konverter verbessert die Leistung von mehrschichtigen Perzeptronen und führt eine eingehende Analyse durch
Der TabTransformer-Konverter verbessert die Leistung von mehrschichtigen Perzeptronen und führt eine eingehende Analyse durch

Heute sind Transformer zu Schlüsselmodulen in den fortschrittlichsten Architekturen für die Verarbeitung natürlicher Sprache (NLP) und Computer Vision (CV) geworden. Der Bereich der Tabellendaten wird jedoch immer noch von GBDT-Algorithmen (Gradient Boosted Decision Tree) dominiert. Es gab also Versuche, diese Lücke zu schließen. Unter ihnen ist das erste konverterbasierte tabellarische Datenmodellierungspapier das von Huang et al. im Jahr 2020 veröffentlichte Papier „TabTransformer: Tabular Data Modeling Using Context Embedding“.
Dieser Artikel soll eine grundlegende Darstellung des Inhalts des Papiers bieten. Außerdem wird er auf die Implementierungsdetails des TabTransformer-Modells eingehen und Ihnen zeigen, wie Sie es verwenden speziell für unsere eigenen Daten.
1. Überblick über das Papier
Die Hauptidee des oben genannten Papiers besteht darin, dass ein Konverter verwendet wird, um eine reguläre kategorische Einbettung in eine kontextuelle Einbettung, dann wird die Leistung herkömmlicher mehrschichtiger Perzeptrone (MLP) deutlich verbessert. Als nächstes wollen wir diese Beschreibung genauer verstehen.
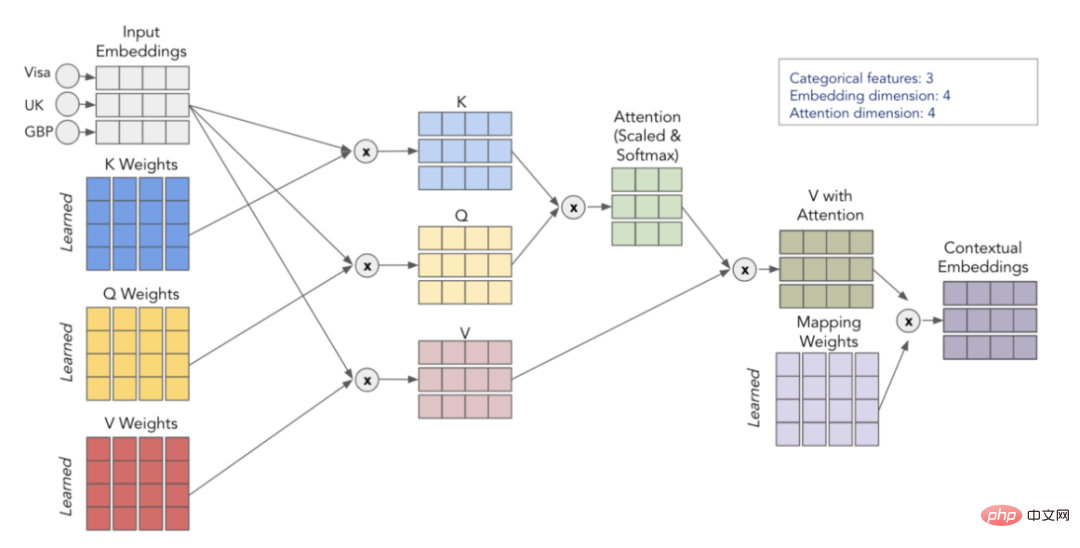
1. Kategoriale Einbettungen
In Deep-Learning-Modellen werden kategoriale Funktionen verwendet Trainieren Sie die Einbettung. Dies bedeutet, dass jeder Kategoriewert eine eindeutige dichte Vektordarstellung hat und an die nächste Ebene übergeben werden kann. Aus dem Bild unten können Sie beispielsweise ersehen, dass jedes kategoriale Merkmal durch ein vierdimensionales Array dargestellt wird. Diese Einbettungen werden dann mit numerischen Merkmalen verkettet und als Eingabe für das MLP verwendet. 2. Kontextuelle Einbettungen
Der Autor des Artikels ist der Ansicht, dass kategoriale Einbettungen keine kontextbezogene Bedeutung haben, das heißt, sie führen keine Interaktions- und Beziehungsinformationen zwischen der Kodierung kategorialer Variablen durch. Um den eingebetteten Inhalt konkreter zu machen, wurde vorgeschlagen, zu diesem Zweck derzeit im NLP-Bereich verwendete Transformatoren zu verwenden. 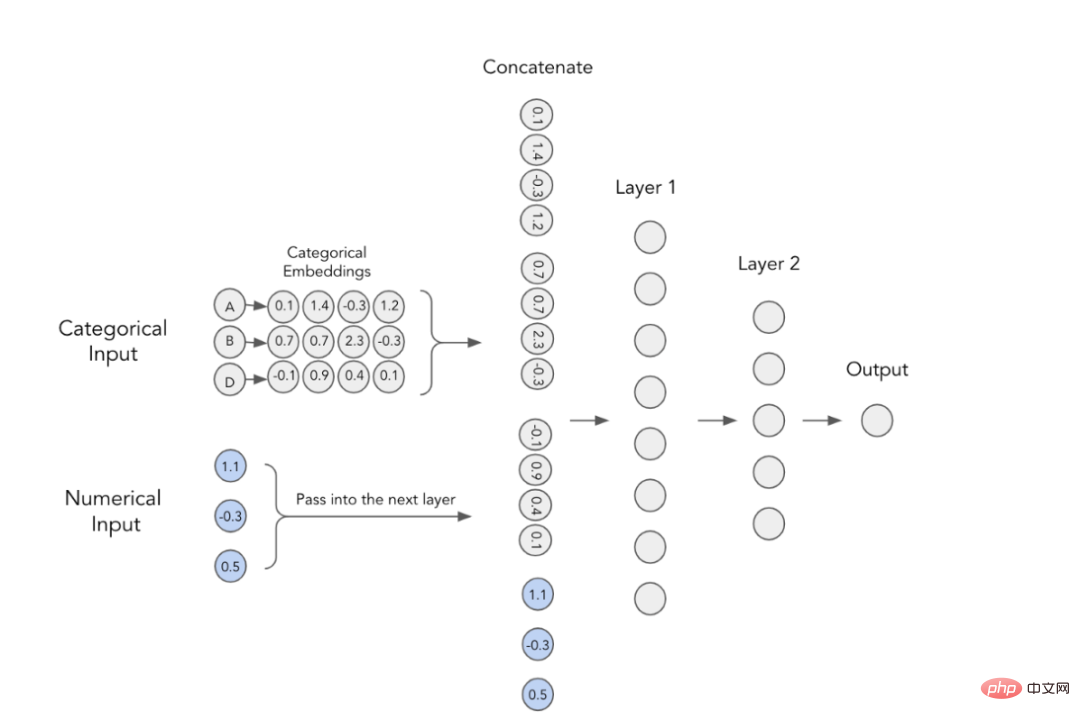
Kontextuelle Einbettung im TabTransformer-Konverter
#🎜🎜 # Zu Um die obige Idee visuell zu veranschaulichen, können wir auch das folgende kontexteinbettende Bild betrachten, das wir nach dem Training erhalten haben. Darunter sind zwei Klassifizierungsmerkmale hervorgehoben: Verwandtschaft (schwarz) und Familienstand (blau). Diese Merkmale sind korreliert; daher sollten die Werte für „Verheiratet“, „Ehemann“ und „Ehefrau“ im Vektorraum nahe beieinander liegen, auch wenn sie aus unterschiedlichen Variablen stammen. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Beispiel des geschulten Tabtransformer -Konverters Einbetten von Ergebnissen#🎜🎜 ## 🎜🎜 ## 🎜🎜##🎜🎜 #Anhand der Ergebnisse der trainierten Kontexteinbettung in der obigen Abbildung können wir sehen, dass der Familienstand von „Verheiratet“ näher an der Beziehungsebene von „Ehemann“ und „Frau“ liegt, während der kategorische Wert für „nicht verheiratet“ von stammt ein separater Datencluster auf der rechten Seite. Diese Art von Kontext macht solche Einbettungen nützlicher, ein Effekt, der mit einfachen Formen von Kategorieneinbettungstechniken nicht möglich ist. 3.TabTransformer-Architektur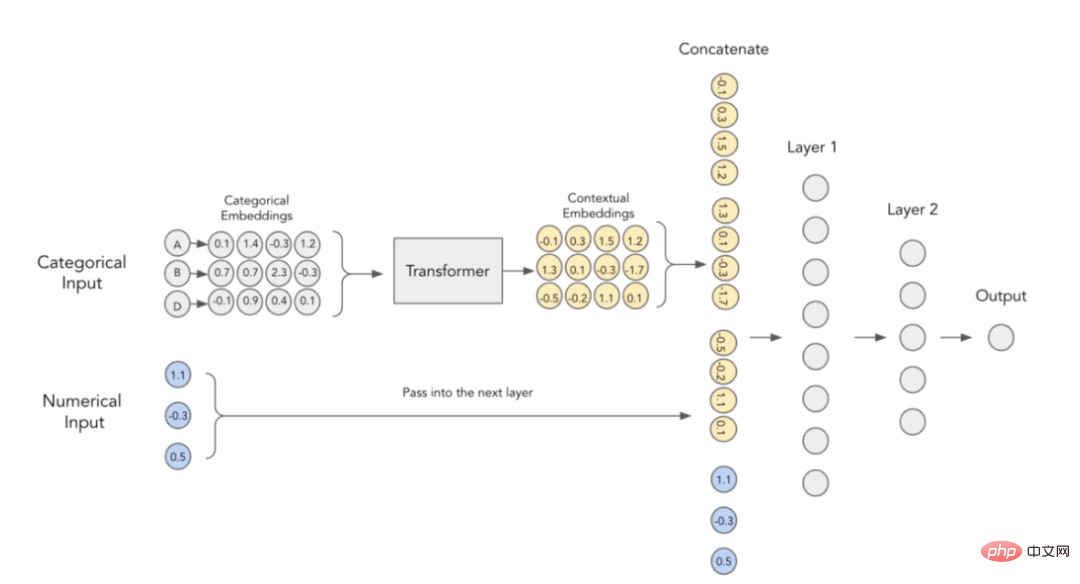
Um den oben genannten Zweck zu erreichen, schlug der Autor des Papiers vor die folgende Architektur: #🎜 🎜#
TabTransformer-Konverter-Architekturdiagramm
(Auszug aus Huang et al . 2020 Paper) 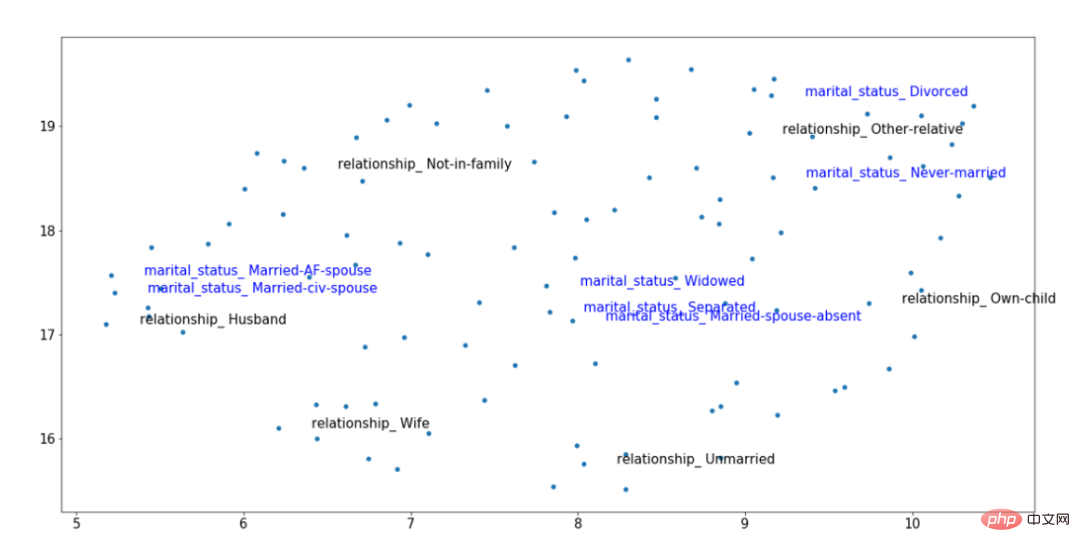
Numerische Merkmale normalisieren und weiterleiten
Kategorische Merkmale einbetten
Die Einbettungen werden von N Transformatorblöcken verarbeitet, um kontextbezogene Einbettungen zu erhalten
Kategorie die Kontext Einbettungen werden mit numerischen Merkmalen verkettet , Die Autoren des Papiers sagen, dass das Hinzufügen einer Konverterschicht die Rechenleistung erheblich verbessern kann. Natürlich geschieht die ganze „Magie“ innerhalb dieser Konverterblöcke. Schauen wir uns also die Implementierung genauer an.
4.Converter (Transformer) Architekturdiagramm 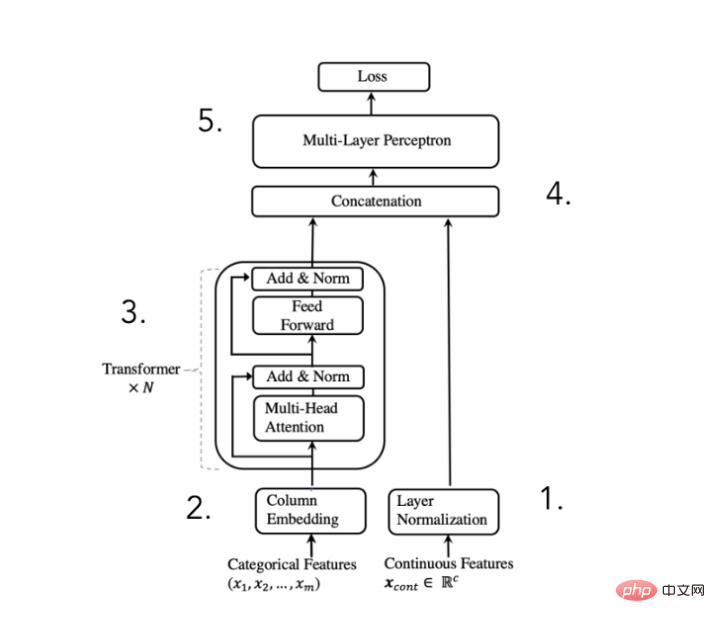
# 🎜🎜#
Vielleicht haben Sie die Transformatorarchitektur schon einmal gesehen, aber für eine schnelle Einführung denken Sie daran, dass der Konverter aus einem Encoder und einem Decoder besteht (siehe Bild oben). Für TabTransformer kümmern wir uns nur um den Encoder-Teil, der die Eingabeeinbettungen kontextualisiert (der Decoder-Teil wandelt diese Einbettungen in das endgültige Ausgabeergebnis um). Aber wie genau wird das gemacht? Die Antwort lautet: Mehrkopf-Aufmerksamkeitsmechanismus.
5. Mehrkopf-Aufmerksamkeitsmechanismus
Um eine Beschreibung aus meinem Lieblingsartikel über Aufmerksamkeitsmechanismen zu zitieren, lautet sie so:
„Das Schlüsselkonzept hinter der Selbstaufmerksamkeit besteht darin, dass dieser Mechanismus es einem neuronalen Netzwerk ermöglicht, zu lernen, wie es auf einzelne Teile einer Eingabesequenz reagiert. Informationsplanung mit dem besten Routing-Schema zwischen ihnen. „
Mit anderen Worten: Die Selbstaufmerksamkeit hilft dem Modell herauszufinden, welche Teile der Eingabe wichtiger sind, wenn es ein bestimmtes Wort/eine bestimmte Kategorie darstellt. Zu diesem Zweck empfehle ich dringend, den oben genannten Artikel zu lesen, um ein intuitiveres Verständnis dafür zu erlangen, warum Selbstfokussierung so effektiv ist. „Mehrkopf-Aufmerksamkeitsmechanismus“ Abfrage), Schlüssel (Key) und Wert (Value). Zuerst multiplizieren wir die Matrizen Q und K, um die Aufmerksamkeitsmatrix zu erhalten. Diese Matrix wird skaliert und durch die Softmax-Schicht geleitet. Anschließend multiplizieren wir dies mit der V-Matrix, um den Endwert zu erhalten. Betrachten Sie für ein intuitiveres Verständnis das folgende Schema, das zeigt, wie wir die Transformation von der Eingabeeinbettung zur Kontexteinbettung mithilfe der Matrizen Q, K und V implementieren.
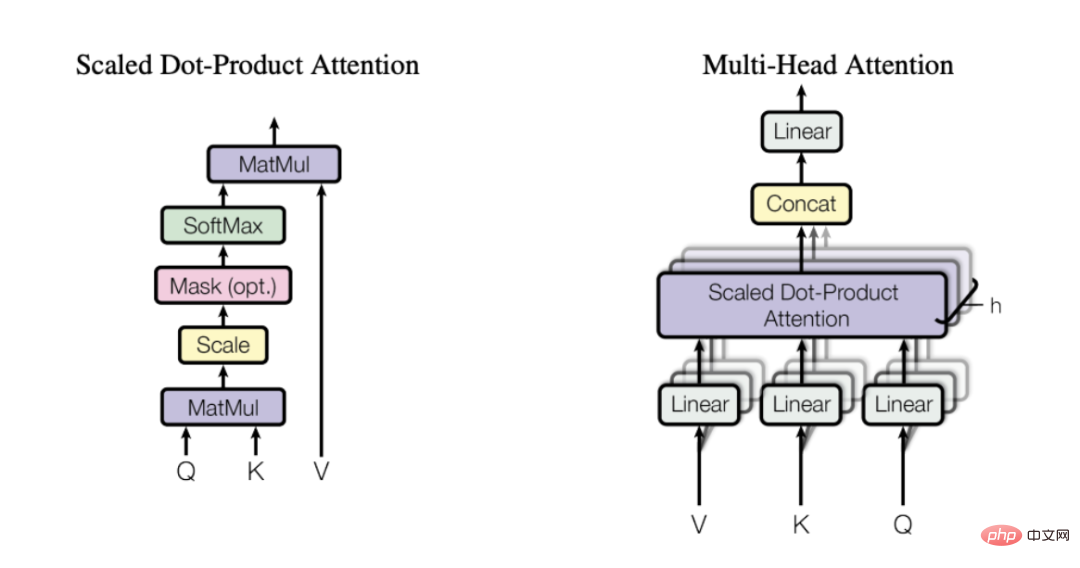
Visualisierung des Selbstaufmerksamkeitsprozesses
Indem wir diesen Vorgang h-mal wiederholen (unter Verwendung verschiedener Q-, K-, V-Matrizen), können wir mehrere Kontexteinbettungen erhalten, die unseren endgültigen Mehrkopf bilden Aufmerksamkeit .
6. Kurzer Rückblick
Einfache kategoriale Einbettungen enthalten keine Kontextinformationen
Indem wir die kategorialen Einbettungen durch den Transformer-Encoder übergeben, können wir die Kontextualisierung einbetten
Der Transformatorteil ist in der Lage, Einbettungen zu kontextualisieren, da er einen Multi-Head-Aufmerksamkeitsmechanismus verwendet.
Der Multi-Head-Aufmerksamkeitsmechanismus verwendet die Matrizen Q, K und V, um nützliche Interaktions- und Korrelationsinformationen beim Codieren von Variablen zu finden.
In TabTransformer kontextualisiert Einbettungen werden mit numerischen Eingaben verkettet und durch eine einfache MLP-Ausgabe vorhergesagt
- Obwohl die Idee hinter TabTransformer einfach ist, kann es einige Zeit dauern, bis Sie den Aufmerksamkeitsmechanismus beherrschen. Daher empfehle ich Ihnen dringend, die obige Erklärung noch einmal zu lesen. Wenn Sie sich etwas verloren fühlen, lesen Sie alle vorgeschlagenen Links in diesem Artikel durch. Ich garantiere Ihnen, dass es Ihnen nicht schwer fallen wird, die Funktionsweise des Aufmerksamkeitsmechanismus zu verstehen, wenn Sie dies einmal getan haben. 7. Anzeige der experimentellen Ergebnisse Tabellenmodelle Darüber hinaus liegt es nahe am Leistungsniveau von GBDT, was sehr ermutigend ist. Das Modell ist außerdem relativ robust gegenüber fehlenden und verrauschten Daten und übertrifft andere Modelle in halbüberwachten Umgebungen. Allerdings sind diese Datensätze eindeutig nicht erschöpfend und es besteht noch erheblicher Raum für Verbesserungen, wie eine Reihe künftiger, verwandter Veröffentlichungen bestätigt.
- 2. Erstellen unseres eigenen Beispielprogramms
- Lassen Sie uns nun endlich festlegen, wie wir das Modell auf unsere eigenen Daten anwenden. Die folgenden Beispieldaten stammen aus dem berühmten Tabular Playground Kaggle-Wettbewerb. Um die Verwendung des TabTransformer-Konverters zu erleichtern, habe ich ein tabtransformertf-Paket erstellt. Es kann mit dem pip-Befehl wie folgt installiert werden:
pip install tabtransformertf
from tabtransformertf.utils.preprocessing import df_to_dataset, build_categorical_prep # 设置数据类型 train_data[CATEGORICAL_FEATURES] = train_data[CATEGORICAL_FEATURES].astype(str) val_data[CATEGORICAL_FEATURES] = val_data[CATEGORICAL_FEATURES].astype(str) train_data[NUMERIC_FEATURES] = train_data[NUMERIC_FEATURES].astype(float) val_data[NUMERIC_FEATURES] = val_data[NUMERIC_FEATURES].astype(float) # 转换成TF数据集 train_dataset = df_to_dataset(train_data[FEATURES + [LABEL]], LABEL, batch_size=1024) val_dataset = df_to_dataset(val_data[FEATURES + [LABEL]], LABEL, shuffle=False, batch_size=1024)
from tabtransformertf.utils.preprocessing import build_categorical_prep
category_prep_layers = build_categorical_prep(train_data, CATEGORICAL_FEATURES)
# 输出结果是一个字典结构,其中键部分是特征名称,值部分是StringLookup层
# category_prep_layers ->
# {'product_code': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05d28ee4e0>,
#'attribute_0': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4fb908>,
#'attribute_1': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4da5f8>}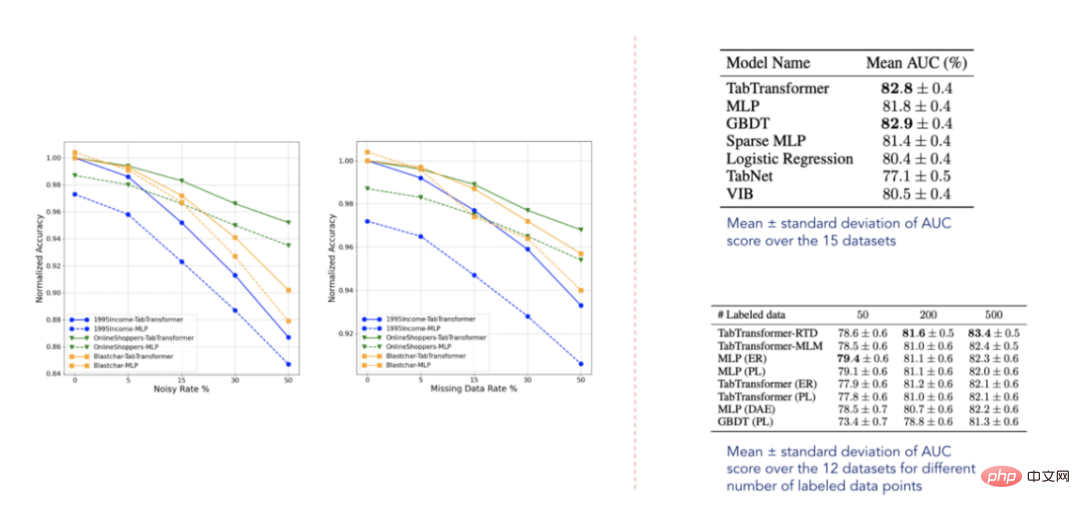
Das ist Vorverarbeitung! Jetzt können wir mit dem Aufbau des Modells beginnen.
2. Erstellen Sie das TabTransformer-Modell
Die Initialisierung des Modells ist einfach. Darunter müssen mehrere Parameter angegeben werden, die wichtigsten Parameter sind jedoch: Embedding_dim, Depth und Heads. Alle Parameter werden nach der Hyperparameter-Optimierung ausgewählt.
from tabtransformertf.models.tabtransformer import TabTransformer tabtransformer = TabTransformer( numerical_features = NUMERIC_FEATURES,# 带有数字特征名称的列表 categorical_features = CATEGORICAL_FEATURES, # 带有分类特征名称的列表 categorical_lookup=category_prep_layers, # 带StringLookup层的Dict numerical_discretisers=None,# None代表我们只是简单地传递数字特征 embedding_dim=32,# 嵌入维数 out_dim=1,# Dimensionality of output (binary task) out_activatinotallow='sigmoid',# 输出层激活 depth=4,# 转换器块层的个数 heads=8,# 转换器块中注意力头的个数 attn_dropout=0.1,# 在转换器块中的丢弃率 ff_dropout=0.1,# 在最后MLP中的丢弃率 mlp_hidden_factors=[2, 4],# 我们为每一层划分最终嵌入的因子 use_column_embedding=True,#如果我们想使用列嵌入,设置此项为真 ) # 模型运行中摘要输出: # 总参数个数: 1,778,884 # 可训练的参数个数: 1,774,064 # 不可训练的参数个数: 4,820
Nachdem das Modell initialisiert wurde, können wir es wie jedes andere Keras-Modell installieren. Auch die Trainingsparameter sind einstellbar, sodass Lerngeschwindigkeit und frühes Stoppen nach Belieben angepasst werden können.
LEARNING_RATE = 0.0001 WEIGHT_DECAY = 0.0001 NUM_EPOCHS = 1000 optimizer = tfa.optimizers.AdamW( learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY ) tabtransformer.compile( optimizer = optimizer, loss = tf.keras.losses.BinaryCrossentropy(), metrics= [tf.keras.metrics.AUC(name="PR AUC", curve='PR')], ) out_file = './tabTransformerBasic' checkpoint = ModelCheckpoint( out_file, mnotallow="val_loss", verbose=1, save_best_notallow=True, mode="min" ) early = EarlyStopping(mnotallow="val_loss", mode="min", patience=10, restore_best_weights=True) callback_list = [checkpoint, early] history = tabtransformer.fit( train_dataset, epochs=NUM_EPOCHS, validation_data=val_dataset, callbacks=callback_list )
3. Bewertung
Der kritischste Indikator im Wettbewerb ist ROC AUC. Geben wir es also zusammen mit der PR-AUC-Metrik aus, um die Leistung des Modells zu bewerten.
val_preds = tabtransformer.predict(val_dataset)
print(f"PR AUC: {average_precision_score(val_data['isFraud'], val_preds.ravel())}")
print(f"ROC AUC: {roc_auc_score(val_data['isFraud'], val_preds.ravel())}")
# PR AUC: 0.26
# ROC AUC: 0.58您也可以自己给测试集评分,然后将结果值提交给Kaggle官方。我现在选择的这个解决方案使我跻身前35%,这并不坏,但也不太好。那么,为什么TabTransfromer在上述方案中表现不佳呢?可能有以下几个原因:
- 数据集太小,而深度学习模型以需要大量数据著称
- TabTransformer很容易在表格式数据示例领域出现过拟合
- 没有足够的分类特征使模型有用
三、结论
本文探讨了TabTransformer背后的主要思想,并展示了如何使用Tabtransformertf包来具体应用此转换器。
归纳起来看,TabTransformer的确是一种有趣的体系结构,它在当时的表现明显优于大多数深度表格模型。它的主要优点是将分类嵌入语境化,从而增强其表达能力。它使用在分类特征上的多头注意力机制来实现这一点,而这是在表格数据领域使用转换器的第一个应用实例。
TabTransformer体系结构的一个明显缺点是,数字特征被简单地传递到最终的MLP层。因此,它们没有语境化,它们的价值也没有在分类嵌入中得到解释。在下一篇文章中,我将探讨如何修复此缺陷并进一步提高性能。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文链接:https://towardsdatascience.com/transformers-for-tabular-data-tabtransformer-deep-dive-5fb2438da820?source=collection_home---------4----------------------------
Das obige ist der detaillierte Inhalt vonDer TabTransformer-Konverter verbessert die Leistung von mehrschichtigen Perzeptronen und führt eine eingehende Analyse durch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
