

Beispielanalyse der Prinzipien der MySQL-Indexerstellung

1. Geeignet zum Erstellen von Indizes
1. Feldwerte unterliegen Eindeutigkeitsbeschränkungen
Gemäß den Alibaba-Spezifikationen müssen Felder mit eindeutigen Merkmalen im Geschäft, auch kombinierte Felder, in einen eindeutigen Index integriert werden.

Zum Beispiel ist die Schülernummer in der Schülertabelle ein eindeutiges Feld. Durch die Erstellung eines eindeutigen Indexes für dieses Feld können die Informationen eines bestimmten Schülers schnell abgefragt werden Namen, wodurch die Abfragegeschwindigkeit verringert wird.
2. Felder, die häufig als Where-Abfragebedingungen verwendet werden
Wenn ein Feld häufig in der Where-Bedingung der Select-Anweisung verwendet wird, ist es notwendig, einen Index für dieses Feld zu erstellen, insbesondere wenn die Datenmenge groß ist Es reicht aus, einen gewöhnlichen Index zu erstellen. Dies kann die Abfrageeffizienz erheblich verbessern.
Zum Beispiel enthält die Testtabelle student_info 1 Million Daten. Wenn kein Index für das Feld student_id erstellt wird, lauten die Abfrageergebnisse wie folgt:
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费211ms
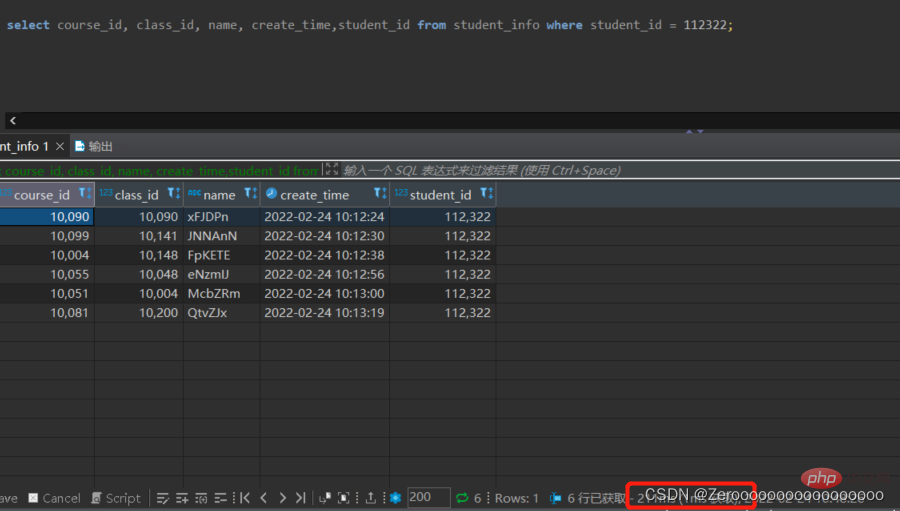
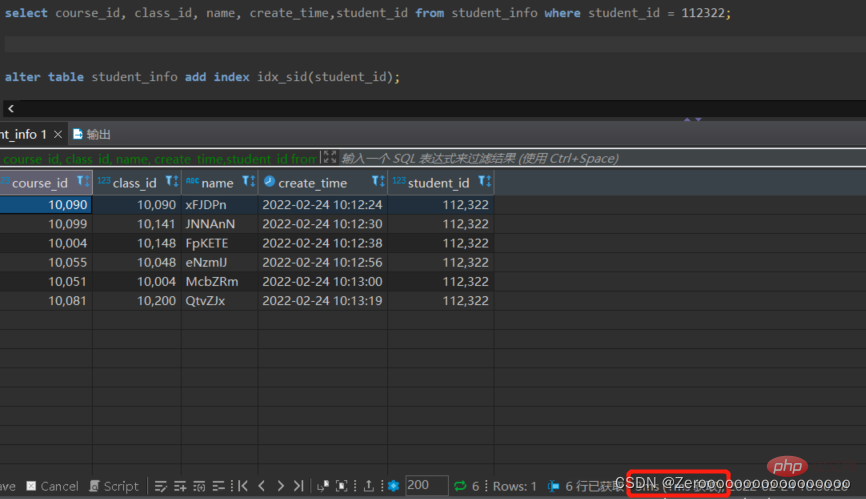
After Beim Erstellen eines Indexes für student_id lauten die Abfrageergebnisse wie folgt:
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费3ms
3. Oft ermöglichen die Spalten „Gruppieren nach“ und „Ordnen nach“ das Speichern oder Abrufen von Daten in einer bestimmten Reihenfolge, z. B. bei Verwendung von „Gruppieren nach“. Um die Daten zu gruppieren oder „Sortieren nach“ zum Sortieren der Daten zu verwenden, müssen Sie die Gruppierungs- oder Sortierfelder indizieren. Wenn mehrere Spalten sortiert werden müssen, kann auf diesen Spalten ein kombinierter Index erstellt werden.
Gruppieren Sie beispielsweise die von Studenten ausgewählten Kurse nach student_id, zeigen Sie verschiedene student_id und die Anzahl der Kurse an und zeigen Sie 100 Elemente an. Wenn Sie keinen Index für student_id erstellen, lauten die Abfrageergebnisse wie folgt:
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
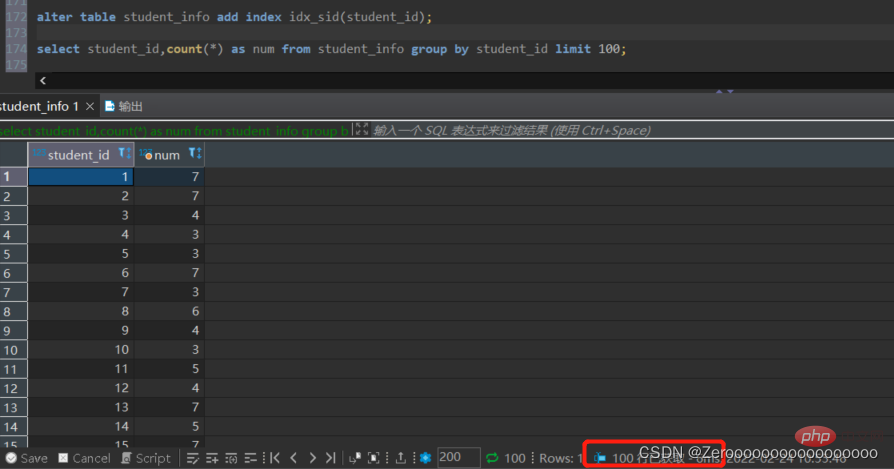
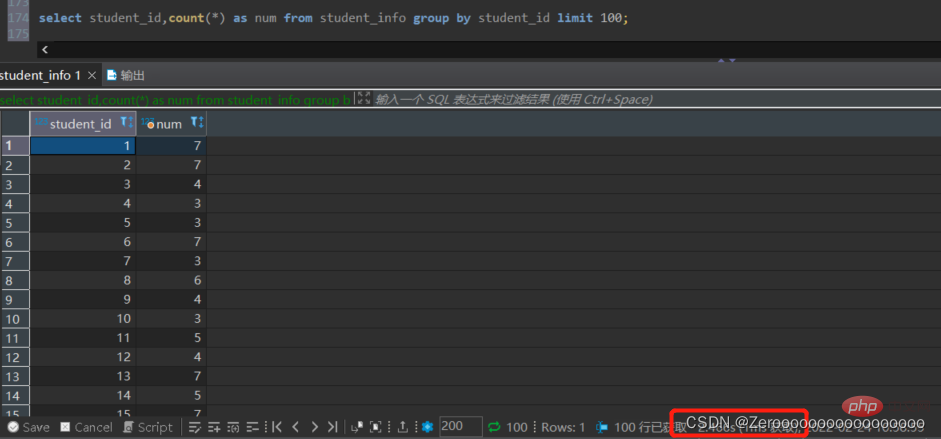 Nach dem Erstellen eines Index für student_id lauten die Abfrageergebnisse wie folgt:
Nach dem Erstellen eines Index für student_id lauten die Abfrageergebnisse wie folgt:
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
4. Die Where-Bedingungsspalte von Aktualisieren und Löschen
Fragen Sie die Daten gemäß einer bestimmten Bedingung ab und führen Sie dann den Aktualisierungs- oder Löschvorgang aus. Wenn ein Index für das Wo-Feld erstellt wird, kann die Antwort verbessert werden, um die Effizienz zu verbessern . Der Grund dafür ist, dass dieser Datensatz zuerst basierend auf der Bedingungsspalte „Where“ abgerufen und dann aktualisiert oder gelöscht werden muss. Wenn es sich bei den aktualisierten Feldern beim Aktualisieren um Nicht-Indexfelder handelt, ist die Effizienzsteigerung deutlicher. Dies liegt daran, dass für die Aktualisierung von Indexfeldern keine Wartung erforderlich ist.
Wenn das Namensfeld in der Tabelle „student_info“ beispielsweise sdfasdfas123123 lautet, wird die student_id in 110119 geändert. Ohne Indizierung des Namensfelds ist die Ausführungssituation wie folgt:
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
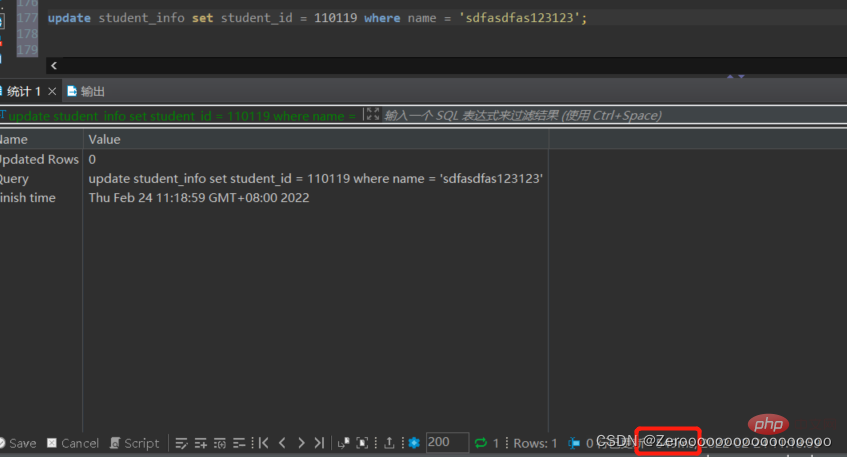 Nach dem Hinzufügen des Index die Ausführungssituation lautet wie folgt:
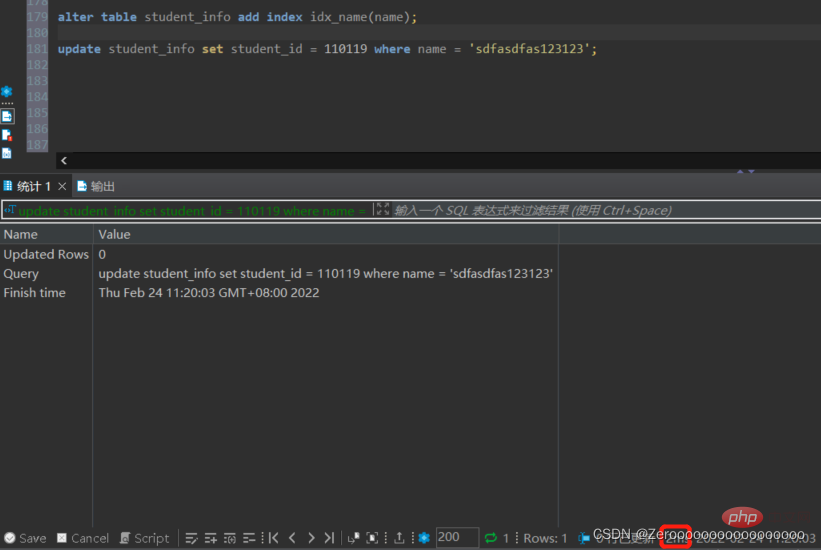
Nach dem Hinzufügen des Index die Ausführungssituation lautet wie folgt:
 5. Distinct-Felder müssen Indizes erstellen
5. Distinct-Felder müssen Indizes erstellen
Manchmal ist es erforderlich, ein bestimmtes Feld zu deduplizieren und einen Index für dieses Feld zu erstellen.
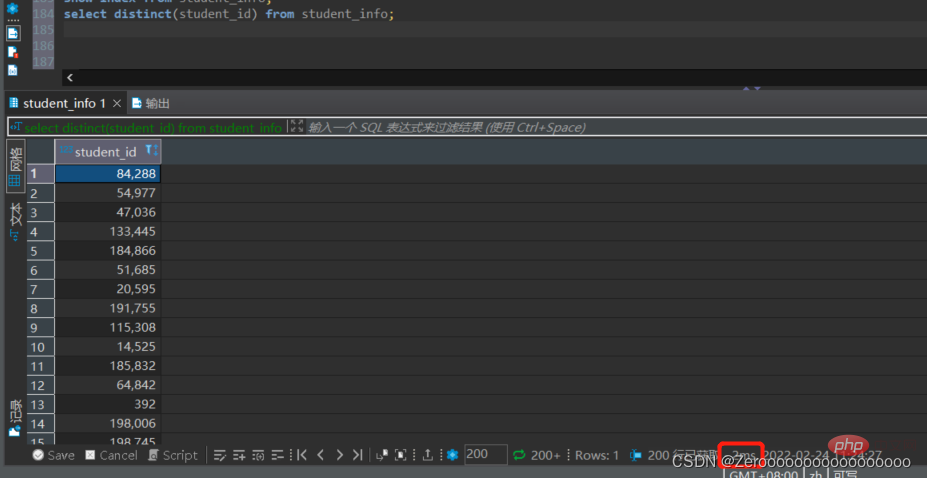
Fragen Sie beispielsweise die verschiedenen student_ids im Kursplan ab. Wenn für student_id kein Index erstellt wird, ist die Ausführungssituation wie folgt:
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
 Nach dem Erstellen des Index ist die Ausführungssituation wie folgt:
Nach dem Erstellen des Index ist die Ausführungssituation wie folgt:
select distinct(student_id) from student_id;#花费2ms
6. Während des Multi-Table-Join-Verbindungsvorgangs sind beim Erstellen eines Index Dinge zu beachten
Zunächst sollte die Datenmenge in der Verbindungstabelle 3 nicht überschreiten, da jede zusätzliche Tabelle dem Hinzufügen einer verschachtelten Schleife entspricht Die Größenordnung nimmt sehr schnell zu, was die Abfrageeffizienz erheblich beeinträchtigt. Zweitens erstellen Sie einen Index für die Where-Bedingung, da Where der Filter für Datenbedingungen ist. Wenn die Datenmenge sehr groß ist, ist es sehr beängstigend, wenn es keine Where-Bedingung zum Filtern gibt. Erstellen Sie schließlich einen Index für die verbundenen Daten Felder und ändern Sie die Felder erneut. Die Typen in mehreren Tabellen müssen konsistent sein.
 Wenn Sie beispielsweise nur einen Index für student_id erstellen, lauten die Abfrageergebnisse wie folgt:
Wenn Sie beispielsweise nur einen Index für student_id erstellen, lauten die Abfrageergebnisse wie folgt:
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花费0.1ms
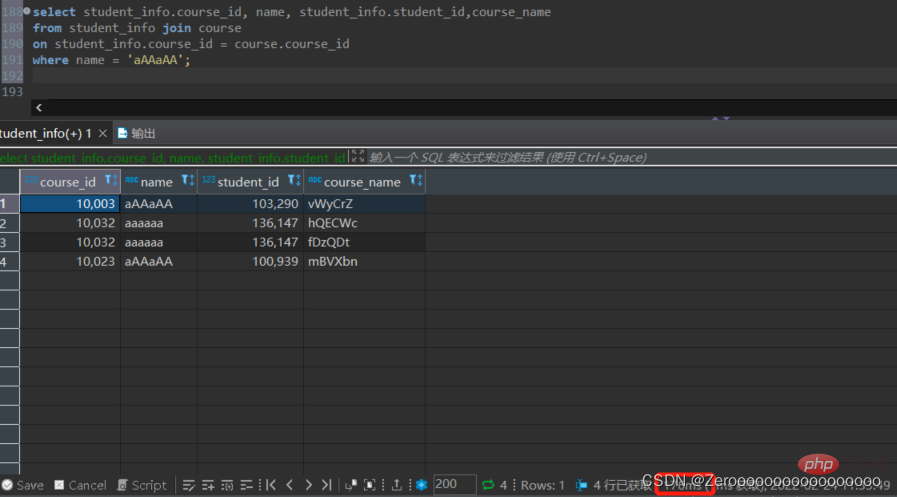 Nach dem Erstellen eines Index für das Namensfeld lauten die Abfrageergebnisse wie folgt:
Nach dem Erstellen eines Index für das Namensfeld lauten die Abfrageergebnisse wie folgt:
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费176ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
上述对于主键来说很合适,因为在聚簇索引中既存储了数据,也存储了索引,可以很好的减少磁盘I/O;而对于二级索引来说,还需要一次回表操作才能查到完整的数据,也就能加了一次磁盘I/O。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9. Definieren Sie keine redundanten oder doppelten Indizes
Das obige ist der detaillierte Inhalt vonBeispielanalyse der Prinzipien der MySQL-Indexerstellung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL: Die einfache Datenverwaltung für Anfänger
Apr 09, 2025 am 12:07 AM
MySQL ist für Anfänger geeignet, da es einfach zu installieren, leistungsfähig und einfach zu verwalten ist. 1. Einfache Installation und Konfiguration, geeignet für eine Vielzahl von Betriebssystemen. 2. Unterstützung grundlegender Vorgänge wie Erstellen von Datenbanken und Tabellen, Einfügen, Abfragen, Aktualisieren und Löschen von Daten. 3. Bereitstellung fortgeschrittener Funktionen wie Join Operations und Unterabfragen. 4. Die Leistung kann durch Indexierung, Abfrageoptimierung und Tabellenpartitionierung verbessert werden. 5. Backup-, Wiederherstellungs- und Sicherheitsmaßnahmen unterstützen, um die Datensicherheit und -konsistenz zu gewährleisten.
 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
So führen Sie SQL in Navicat aus
Apr 08, 2025 pm 11:42 PM
Schritte zur Durchführung von SQL in Navicat: Verbindung zur Datenbank herstellen. Erstellen Sie ein SQL -Editorfenster. Schreiben Sie SQL -Abfragen oder Skripte. Klicken Sie auf die Schaltfläche Ausführen, um eine Abfrage oder ein Skript auszuführen. Zeigen Sie die Ergebnisse an (wenn die Abfrage ausgeführt wird).
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
