In MySQL wird bei der Suche nach Daten Suchen Sie zuerst den entsprechenden Wert im Index und dann die entsprechende Datenzeile basierend auf dem passenden Indexdatensatz. Wenn Sie die folgende Abfrageanweisung ausführen möchten:
SELECT * FROM USER WHERE uid = 5;
Nach dem Login kopieren
Wenn ein Index auf der UID basiert , MySQL verwendet den Index. Suchen Sie zuerst die Zeile mit der UID 5, was bedeutet, dass MySQL zuerst nach Wert im Index sucht und dann alle Datenzeilen zurückgibt, die diesen Wert enthalten.
1.2 Häufig verwendete Datenstrukturen für MySQL-Indizes
MySQL-Indizes werden auf der Ebene der Speicher-Engine implementiert, nicht auf dem Server. Daher gibt es keinen einheitlichen Indexierungsstandard: Indizes in verschiedenen Speicher-Engines funktionieren unterschiedlich.
1.2.1 B-Tree
Die meisten MySQL-Engines unterstützen diese Art von Index-B-Tree, auch wenn mehrere Speicher-Engines denselben Indextyp unterstützen, kann die zugrunde liegende Implementierung auftreten unterscheiden sich auch. InnoDB verwendet beispielsweise B+Tree.
Speicher-Engines implementieren B-Tree auf unterschiedliche Weise, mit unterschiedlichen Leistungen und Vorteilen. MyISAM verwendet beispielsweise die Präfixkomprimierungstechnologie, um Indizes zu verkleinern, während InnoDB die Daten gemäß dem ursprünglichen Datenformat speichert. MyISAM-Indizes beziehen sich auf die indizierten Zeilen anhand des physischen Speicherorts der Daten, während InnoDB die indizierten Zeilen entsprechend der Komponente anwendet .
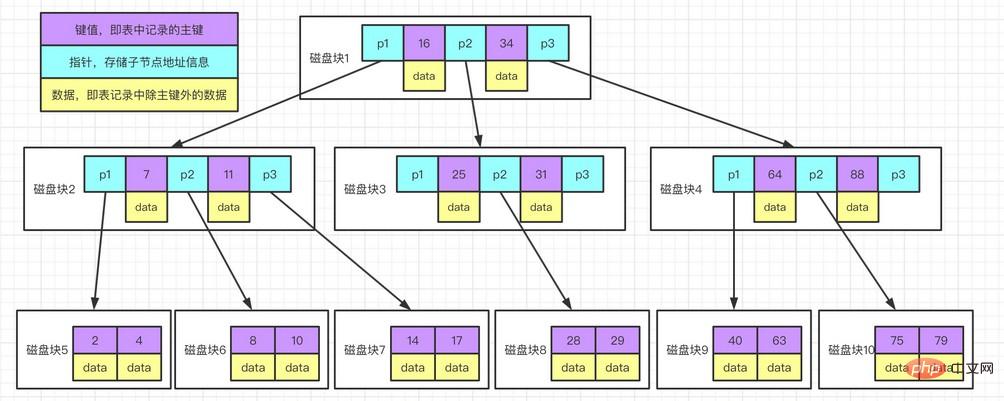
Alle Werte im B-Baum werden nacheinander gespeichert und der Abstand von jeder Blattseite zur Wurzel ist gleich. Die folgende Abbildung zeigt grob die Funktionsweise des InnoDB-Index. Die von MyISAM verwendete Struktur ist unterschiedlich. Die grundlegende Implementierung ist jedoch ähnlich.
Instanzdiagrammbeschreibung:
Jeder Knoten belegt einen Festplattenblock, und auf einem Knoten gibt es zwei aufsteigende Sortierschlüssel. Wort und drei Zeiger auf den Wurzelknoten des Teilbaums. Die Zeiger speichern die Adresse des Plattenblocks, in dem sich der untergeordnete Knoten befindet. Die drei durch die beiden Schlüsselwörter geteilten Bereichsfelder entsprechen den Bereichsfeldern der Daten des Teilbaums, auf den die drei Zeiger zeigen. Am Beispiel des Wurzelknotens lauten die Schlüsselwörter 16 und 34, der Datenbereich des Teilbaums, auf den der P1-Zeiger zeigt, ist kleiner als 16, der Datenbereich des Teilbaums, auf den der P2-Zeiger zeigt, beträgt 16 bis 34 und die Daten Der Bereich des Teilbaums, auf den der P3-Zeiger zeigt, ist größer als 34. Schlüsselwortsuchprozess:
Suchen Sie Festplattenblock 1 basierend auf dem Wurzelknoten und lesen Sie ihn in den Speicher. [Festplatten-E/A-Vorgang zum ersten Mal]
Vergleiche Schlüsselwort 28 Suchen Sie im Intervall (16,34) den Zeiger P2 von Festplattenblock 1.
Suchen Sie Plattenblock 3 anhand des P2-Zeigers und lesen Sie ihn in den Speicher ein. [Festplatten-E/A-Vorgang zum zweiten Mal]
Vergleiche Schlüsselwort 28 Suchen Sie im Intervall (25,31) den Zeiger P2 von Festplattenblock 3.
Suchen Sie Plattenblock 8 entsprechend dem P2-Zeiger und lesen Sie ihn in den Speicher. [Festplatten-E/A-Vorgang 3.]
Suchen Sie das Schlüsselwort 28 in der Schlüsselwortliste im Festplattenblock 8.
Nachteile:
Jeder Knoten hat einen Schlüssel und bei Gleichzeitig Es enthält auch Daten und der Speicherplatz jeder Seite ist begrenzt. Wenn die Datenmenge relativ groß ist, wird die Anzahl der in jedem Knoten gespeicherten Schlüssel kleiner. 🎜🎜#Wenn die Datenmenge beim Speichern groß ist, ist die Tiefe groß, was die Anzahl der Festplatten-E/As während der Abfrage erhöht und sich somit auf die Abfrageleistung auswirkt.
1.2.2 B+Tree-Index
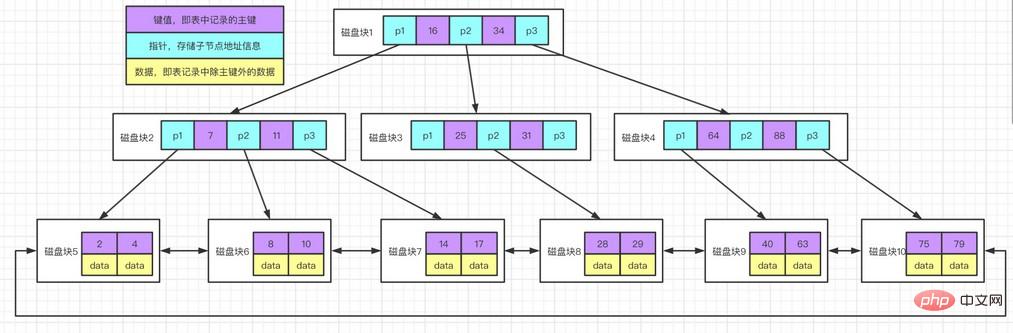
B+-Baum ist eine Variante des B-Baums. Unterschied zum B-Baum: Der B+-Baum speichert Daten nur in Blattknoten, und Nicht-Blattknoten speichern nur Schlüsselwerte und Zeiger.
Es gibt zwei Zeiger im B+-Baum, einer zeigt auf den Wurzelblattknoten, der andere zeigt auf den Blattknoten mit dem kleinsten Schlüsselwort, und zwischen allen Blattknoten (d. h. Daten) gibt es einen Kettenring Knoten)-Struktur, so dass zwei Suchoperationen für den B+-Baum durchgeführt werden können: eine ist eine Bereichssuche für die Komponente und die andere ist eine Zufallssuche ausgehend vom Wurzelknoten.
Der B*-Baum ähnelt der B+-Zahl. Der Unterschied besteht darin, dass die B*-Zahl auch eine Kettenringstruktur zwischen Nicht-Blattknoten aufweist.
1.2.3 Hash-Index
Der Hash-Index basiert auf der Hash-Tabelle und nur auf Abfragen, die genau mit allen übereinstimmen Spalten des Index wirksam ist. Für jede Datenzeile berechnet die Speicher-Engine einen Hash-Code für alle Indexspalten. Der Hash-Code ist kleiner und die für Zeilen mit unterschiedlichen Schlüsselwerten berechneten Hash-Codes sind ebenfalls unterschiedlich. Ein Hash-Index speichert alle Hash-Codes im Index und einen Zeiger auf jede Datenzeile in der Hash-Tabelle.
In MySQL ist nur der Standardindextyp des Speichers der verwendete Hash-Index, und der Speicher unterstützt auch B-Tree-Indizes. Gleichzeitig unterstützt die Speicher-Engine nicht eindeutige Hash-Indizes. Wenn die Hash-Werte mehrerer Spalten gleich sind, speichert der Index mehrere Zeiger im selben Hash-Eintrag in einer verknüpften Liste. Ähnlich wie HashMap.
Vorteile:
Der Index selbst muss nur den entsprechenden Hashwert speichern, also die Indexstruktur ist sehr kompakt und gehasht, sodass Suchvorgänge sehr schnell erfolgen.
Nachteile:
Wenn Sie Hash-Speicher verwenden, müssen Sie alle Datendateien zum Speicher hinzufügen, was mehr verbraucht Speicherplatz;# 🎜🎜#
Hash-Indexdaten werden nicht in der richtigen Reihenfolge gespeichert und können daher nicht zum Sortieren verwendet werden;
Wenn alle Abfragen gleichwertige Abfragen sind, ist das Hashing sehr schnell, aber in einem Unternehmen oder einer tatsächlichen Arbeitsumgebung müssen mehr Daten in Bereichen durchsucht werden als in äquivalenten Abfragen Hash ist nicht geeignet;
Wenn es viele Hash-Konflikte gibt, sind die Kosten für Indexwartungsvorgänge sehr hoch. Dies wird auch durch das Hinzufügen von Rot-Schwarz-Bäumen gelöst das spätere Stadium von HashMap.
2 Hochleistungsindexstrategie
2.1 Clustered-Index und Nicht-Clustered-Index
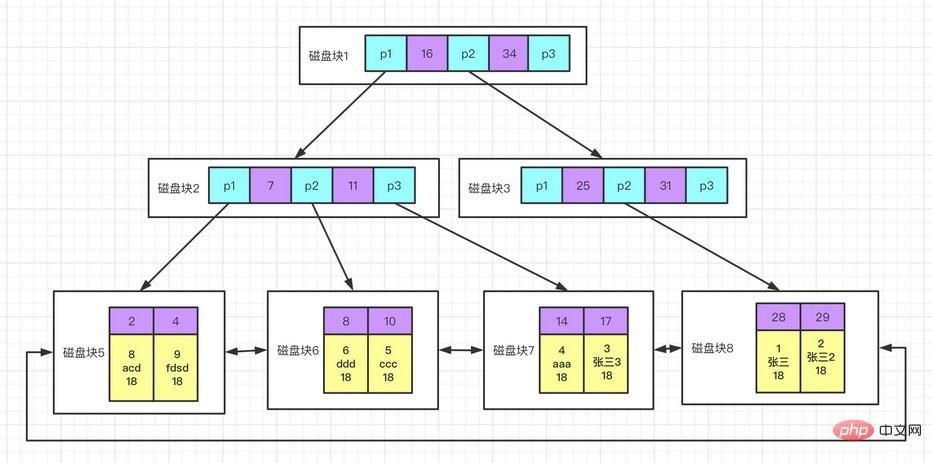
#🎜🎜 #Clustered Index ist kein separater Indextyp, sondern eine Datenspeichermethode. In der InnoDB-Speicher-Engine speichert der Clustered-Index tatsächlich Schlüsselwerte und Datenzeilen die gleiche Struktur. Wenn eine Tabelle über einen Clustered-Index verfügt, werden ihre Datenzeilen tatsächlich in den Blattseiten des Index gespeichert. Da Datenzeilen nicht gleichzeitig an verschiedenen Orten gespeichert werden können, kann es in einer Tabelle nur einen Clustered-Index geben (die Indexabdeckung kann die Situation mehrerer Clustered-Indizes simulieren).
Vorteile des Clustered-Index: Kann verwandte Daten zusammen speichern; der Datenzugriff ist schneller, da der Index und die Daten gespeichert werden Derselbe Baum; Abfragen, die abdeckende Indexscans verwenden, können den Primärschlüsselwert im Seitenknoten direkt verwenden. Wenn sich alle Daten im Speicher befinden, hat die Einfügungsgeschwindigkeit keinen Vorteil Die Einfügereihenfolge hängt stark davon ab, und das Einfügen in der Reihenfolge des Primärschlüssels ist der schnellste Weg. Das Aktualisieren der Clustered-Index-Spalten ist sehr kostspielig, da jede aktualisierte Zeile auf der Grundlage eines Clustered-Index an eine neue Position verschoben werden muss Wenn eine neue Zeile eingefügt wird oder der Primärschlüssel aktualisiert wird und die Zeile verschoben werden muss, kann es zu Problemen mit der Seitenaufteilung kommen. Dies führt möglicherweise dazu, dass der vollständige Tabellenscan langsamer wird, insbesondere wenn die Zeilen spärlich sind Die Datenspeicherung ist aufgrund der Seitenaufteilung diskontinuierlich. Separat speichern. Normalerweise können Sie eine Spalte verwenden, die mit einem Teil der Zeichenfolge beginnt. Dies spart erheblich Indexplatz und verbessert dadurch die Indexeffizienz. Dies verringert jedoch die Selektivität des Index. Die Selektivität des Index bezieht sich auf: den eindeutigen Indexwert (auch genannt). Kardinalität) und die Gesamtzahl der Datentabellendatensätze im Bereich von 1/#T bis 1. Je höher die Selektivität des Index, desto höher die Abfrageeffizienz, da ein selektiverer Index es MySQL ermöglicht, bei der Suche mehr Zeilen herauszufiltern. Im Allgemeinen ist die Selektivität eines bestimmten Spaltenpräfixes hoch genug, um die Abfrageleistung zu erfüllen. Für Spalten der Typen BLOB, TEXT und VARCHAR müssen jedoch Präfixindizes verwendet werden, da dies bei MySQL nicht der Fall ist Lassen Sie es zu. Der Trick bei dieser Methode besteht darin, ein Präfix zu wählen, das lang genug ist, um eine hohe Selektivität zu gewährleisten. BeispielTabellenstruktur und Datendownload von der offiziellen MySQL-Website oder GitHub. Stadttabellenspalten
Feldname
Bedeutung
city_id
Stadt-Primärschlüssel-ID
city
Stadtname#🎜 🎜 #
country_id
Country ID
last_update:
#🎜 🎜 # Erstellt oder zuletzt aktualisiert
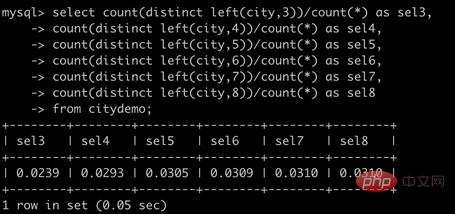
--计算完整列的选择性
select count(distinct left(city,3))/count(*) as sel3,
count(distinct left(city,4))/count(*) as sel4,
count(distinct left(city,5))/count(*) as sel5,
count(distinct left(city,6))/count(*) as sel6,
count(distinct left(city,7))/count(*) as sel7,
count(distinct left(city,8))/count(*) as sel8
from citydemo;
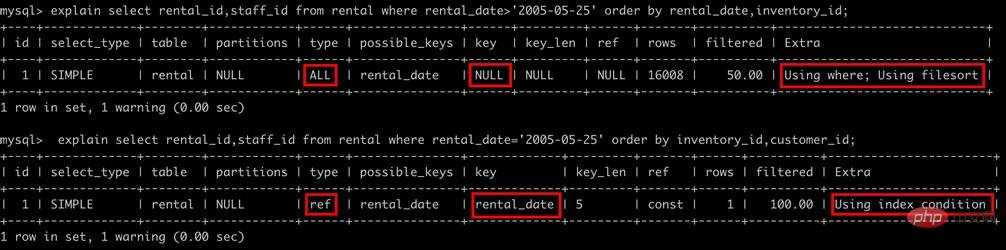
--该查询为索引的第一列提供了常量条件,而使用第二列进行排序,将两个列组合在一起,就形成了索引的最左前缀
explain select rental_id,staff_id from rental
where rental_date='2005-05-25' order by inventory_id desc
--下面的查询不会利用索引
explain select rental_id,staff_id from rental
where rental_date>'2005-05-25' order by rental_date,inventory_id
Nach dem Login kopieren
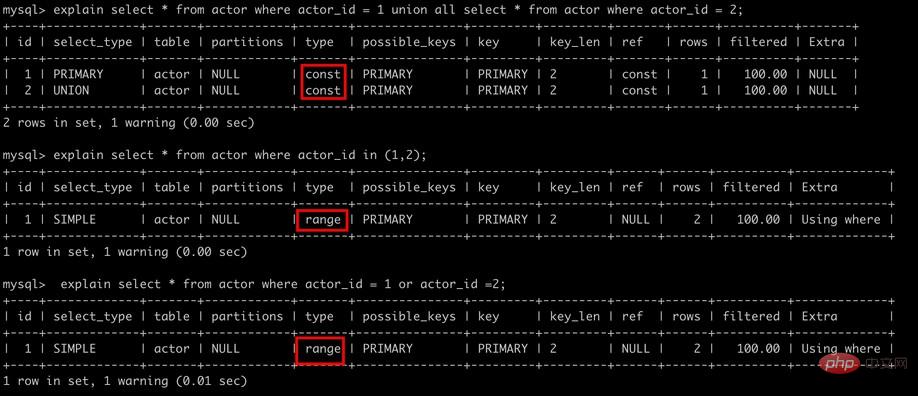
5. union all,in,or都能够使用索引,但是推荐使用in
explain select * from actor where actor_id = 1 union all select * from actor where actor_id = 2;
explain select * from actor where actor_id in (1,2);
explain select * from actor where actor_id = 1 or actor_id =2;
Das obige ist der detaillierte Inhalt vonSo erstellen Sie Hochleistungsindizes für MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn


 Der Hash-Index basiert auf der Hash-Tabelle und nur auf Abfragen, die genau mit allen übereinstimmen Spalten des Index wirksam ist. Für jede Datenzeile berechnet die Speicher-Engine einen Hash-Code für alle Indexspalten. Der Hash-Code ist kleiner und die für Zeilen mit unterschiedlichen Schlüsselwerten berechneten Hash-Codes sind ebenfalls unterschiedlich. Ein Hash-Index speichert alle Hash-Codes im Index und einen Zeiger auf jede Datenzeile in der Hash-Tabelle.
Der Hash-Index basiert auf der Hash-Tabelle und nur auf Abfragen, die genau mit allen übereinstimmen Spalten des Index wirksam ist. Für jede Datenzeile berechnet die Speicher-Engine einen Hash-Code für alle Indexspalten. Der Hash-Code ist kleiner und die für Zeilen mit unterschiedlichen Schlüsselwerten berechneten Hash-Codes sind ebenfalls unterschiedlich. Ein Hash-Index speichert alle Hash-Codes im Index und einen Zeiger auf jede Datenzeile in der Hash-Tabelle.  :
: 
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



