
 Technologie-Peripheriegeräte
KI
Leitet die KI-Entwicklung die Vereinigung in 70 Jahren ein? Ma Yi, Cao Ying, Shen Xiangyangs neueste KI-Rezension: Erkundung der Grundprinzipien und des „Standardmodells' der Intelligenzgenerierung
Technologie-Peripheriegeräte
KI
Leitet die KI-Entwicklung die Vereinigung in 70 Jahren ein? Ma Yi, Cao Ying, Shen Xiangyangs neueste KI-Rezension: Erkundung der Grundprinzipien und des „Standardmodells' der Intelligenzgenerierung
Leitet die KI-Entwicklung die Vereinigung in 70 Jahren ein? Ma Yi, Cao Ying, Shen Xiangyangs neueste KI-Rezension: Erkundung der Grundprinzipien und des „Standardmodells' der Intelligenzgenerierung

Künstliche Intelligenz entwickelt sich seit siebzig Jahren weiter. Obwohl die technischen Indikatoren kontinuierlich aktualisiert wurden, gibt es immer noch keine Antwort darauf, was genau „Intelligenz“ ist und wie sie entstanden und entwickelt ist.
Kürzlich hat sich Professor Ma Yi mit dem Informatiker Dr. Shen Xiangyang und dem Neurowissenschaftler Professor Cao Ying zusammengetan, um einen Forschungsbericht über die Entstehung und Entwicklung von Intelligenz zu veröffentlichen, in der Hoffnung, die Forschung zur Intelligenz in der Theorie zu vereinheitlichen und das Verständnis davon zu verbessern Verständnis und Interpretierbarkeit von Modellen der künstlichen Intelligenz.

Link zum Papier: http://arxiv.org/abs/2207.04630
Der Artikel stellt zwei Grundprinzipien vor: Sparsamkeit und Selbstkonsistenz.
Der Autor glaubt, dass dies der Grundstein für den Aufstieg künstlicher oder natürlicher Intelligenz ist. Obwohl es zu jedem dieser beiden Prinzipien in der klassischen Literatur zahlreiche Diskussionen und Ausarbeitungen gibt, werden diese beiden Prinzipien in diesem Artikel auf völlig messbare und berechenbare Weise neu interpretiert.
Basierend auf diesen beiden ersten Prinzipien leiten die Autoren ein effizientes Rechengerüst ab: die komprimierte Closed-Loop-Transkription, die die Entwicklung moderner tiefer Netzwerke und vieler Praktiken der künstlichen Intelligenz vereinheitlicht und erklärt.
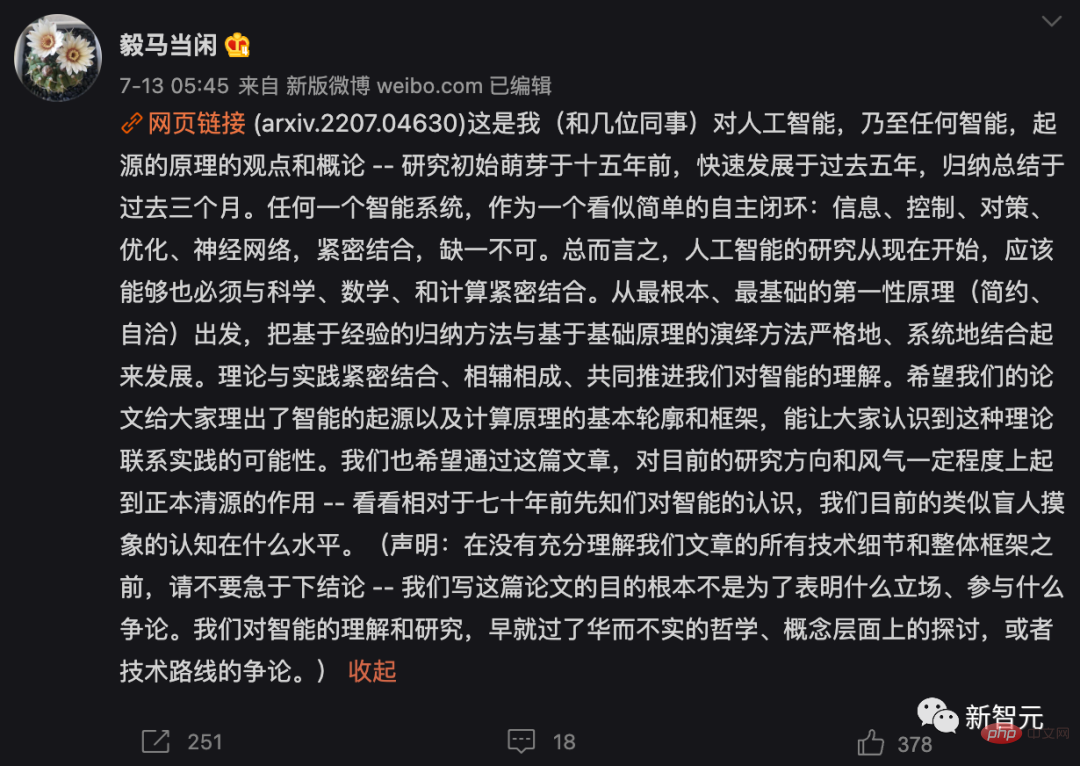
Zwei Grundprinzipien: Einfachheit und Selbstkonsistenz
Mit dem Segen des Deep Learning beruhen die im letzten Jahrzehnt erzielten Fortschritte in der künstlichen Intelligenz hauptsächlich auf dem Training homogener Black-Box-Modelle unter Verwendung von Rohöl Technische Methoden zum Training großer neuronaler Netze.
Obwohl die Leistung verbessert wurde und keine Notwendigkeit besteht, Features manuell zu entwerfen, ist die im neuronalen Netzwerk erlernte Feature-Darstellung nicht interpretierbar und große Modelle bringen andere Probleme mit sich, wie z. B. die steigenden Kosten für die Datenerfassung und -berechnung erlernten Darstellungen mangelt es an Reichtum, Stabilität (Moduskollaps), Anpassungsfähigkeit (anfällig für katastrophales Vergessen);
Der Autor ist der Ansicht, dass einer der grundlegenden Gründe für diese Probleme in der aktuellen Praxis von tiefen Netzwerken und künstlicher Intelligenz das Fehlen eines systematischen und umfassenden Verständnisses der Funktionen und Organisationsprinzipien intelligenter Systeme ist.
Zum Beispiel sind das Training eines diskriminativen Modells zur Klassifizierung und eines generativen Modells zum Sampling oder Wiederholen in der Praxis grundsätzlich getrennt. Auf diese Weise trainierte Modelle werden üblicherweise als Open-Loop-Systeme bezeichnet und erfordern ein durchgängiges Training durch Supervision oder Selbstsupervision.
In der Regelungstheorie können solche Open-Loop-Systeme Fehler in Vorhersagen nicht automatisch korrigieren und sind nicht an Veränderungen in der Umgebung anpassbar; genau aus diesem Grund verwenden wir in geregelten Systemen häufig „Closed-Loop-Feedback“. „um das System in die Lage zu versetzen, Fehler selbständig zu korrigieren.
Ähnliche Erfahrungen gelten auch beim Lernen: Sobald diskriminierende und generative Modelle zu einem vollständigen geschlossenen System kombiniert werden, kann das Lernen autonom (ohne externe Aufsicht), effizienter und stabiler und anpassungsfähiger werden.
Um die Funktionskomponenten zu verstehen, die in einem intelligenten System benötigt werden können, wie etwa Diskriminatoren oder Generatoren, müssen wir Intelligenz aus einer „prinzipielleren“ und „einheitlicheren“ Perspektive verstehen.
Der Artikel schlägt zwei Grundprinzipien vor: Sparsamkeit und Selbstkonsistenz, die jeweils zwei grundlegende Fragen zum Lernen beantworten.
- Was man lernen kann: Was kann man aus Daten lernen und wie kann man die Qualität des Lernens messen?
- Wie lernt man: Wie erreichen wir ein solches Lernziel durch ein effizientes und effektives Computer-Framework?
Was die erste Frage betrifft, „was man lernen soll“, lautet das Prinzip der Einfachheit:
Das Lernziel eines intelligenten Systems besteht darin, niedrigdimensionale Strukturen aus den Beobachtungsdaten der Außenwelt zu finden und auf die kompakteste und summativste Art und Weise neu organisieren und strukturiert darstellen.
Dies ist das „Occams Rasiermesser“-Prinzip: Fügen Sie keine Entitäten hinzu, es sei denn, dies ist erforderlich.
Ohne dieses Prinzip wäre Intelligenz nicht möglich! Wenn die Beobachtungsdaten der Außenwelt keine niedrigdimensionale Struktur aufweisen, gibt es nichts, was es wert wäre, gelernt oder erinnert zu werden, und eine gute Verallgemeinerung oder Vorhersage ist nicht möglich.
Und intelligente Systeme müssen möglichst viele Ressourcen wie Energie, Raum, Zeit und Materie einsparen. In manchen Fällen wird dieses Prinzip auch „Kompressionsprinzip“ genannt. Die Sparsamkeit der Intelligenz besteht jedoch nicht darin, die beste Komprimierung zu erreichen, sondern darin, durch effiziente Rechenmittel den kompaktesten und strukturiertesten Ausdruck der Beobachtungsdaten zu erhalten.
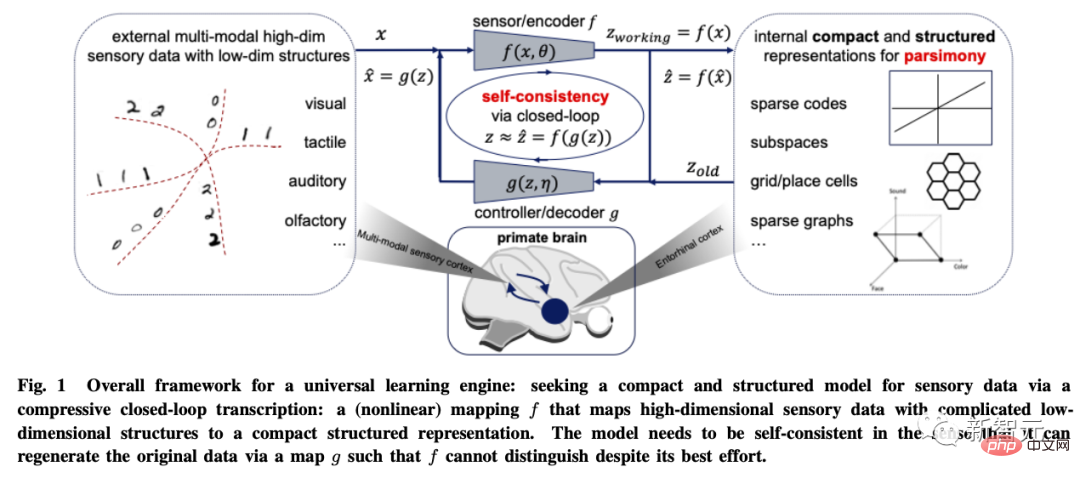
Wie misst man also Einfachheit?
Bei allgemeinen hochdimensionalen Modellen ist der Rechenaufwand vieler häufig verwendeter mathematischer oder statistischer „Maße“ exponentiell oder für Datenverteilungen mit niedrigdimensionalen Strukturen sogar undefiniert. Beispielsweise maximale Wahrscheinlichkeit, KL-Divergenz, gegenseitige Information , Jensen-Shannon- und Wasserstein-Distanz usw.
Der Autor glaubt, dass der Zweck des Lernens tatsächlich darin besteht, eine Zuordnung (normalerweise nichtlinear) zu erstellen, um eine niedrigdimensionale Darstellung aus der ursprünglichen hochdimensionalen Eingabe zu erhalten.
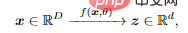
Auf diese Weise sollte die Verteilung des erhaltenen Merkmals z kompakter und strukturierter sein; kompakt bedeutet eine effizientere Speicherung und Nutzung: insbesondere lineare Strukturen, die interpoliert oder ideal sind zur Extrapolation.
Zu diesem Zweck führt der Autor die lineare Diskriminanzdarstellung (LDR) ein, um drei Unterziele zu erreichen:
- Komprimierung: Abbildung hochdimensionaler sensorischer Daten x auf niedrigdimensionale Darstellung z;
- Linearisierung : Ordnen Sie jeden im nichtlinearen Untergrund verteilten Objekttyp einem linearen Unterraum zu.
- Sparsifizierung: Ordnen Sie verschiedene Kategorien voneinander unabhängigen oder am wenigsten relevanten Unterräumen zu.
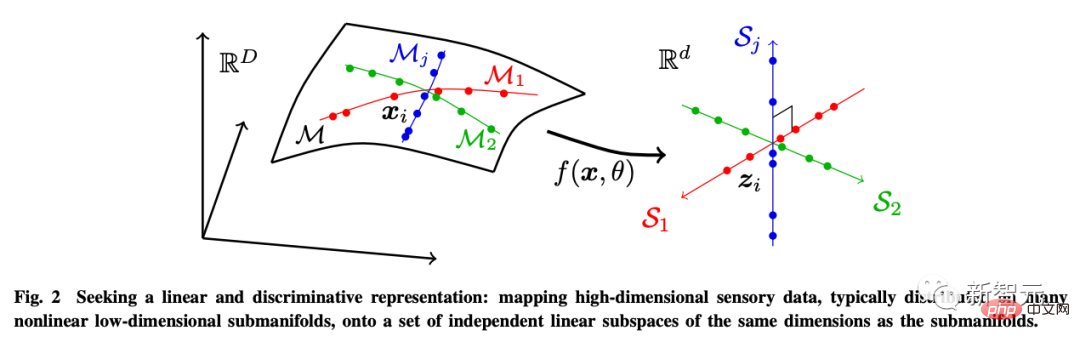
Diese Ziele können durch maximale Reduzierung der Codierungsrate (Ratenreduzierung) erreicht werden, um sicherzustellen, dass das erlernte LDR-Modell die optimale sparsame Leistung aufweist.
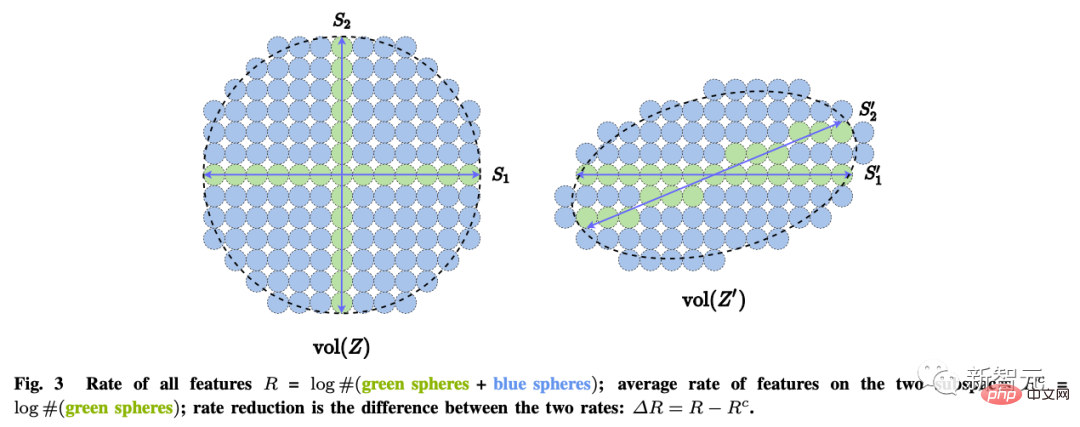
In Bezug auf die zweite Frage „Wie lernt man?“ besagt das Prinzip der Selbstkonsistenz:
Ein autonomes intelligentes System wird intern durch die Minimierung der beobachteten Daten und regenerierten Daten ausgedrückt konsistentestes Modell für die Beobachtung der Außenwelt.
Das Prinzip der Sparsamkeit allein stellt nicht sicher, dass das erlernte Modell alle wichtigen Informationen über die Daten über die Außenwelt erfasst. Beispielsweise kann die Abbildung jeder Kategorie auf einen eindimensionalen One-Hot-Vektor durch Minimierung der Kreuzentropie als eine Form der Sparsamkeit angesehen werden.
Es kann ein guter Klassifikator erlernt werden, aber die erlernten Merkmale können auch zu einem Singleton zusammenfallen, was auch als neuronaler Kollaps bezeichnet wird. Solche erlernten Features enthalten nicht mehr genügend Informationen, um die Originaldaten wiederherzustellen.
Selbst wenn wir das allgemeinere LDR-Modell betrachten, kann die Maximierung der Codierungsratendifferenz allein nicht automatisch die korrekten Abmessungen des Umgebungsmerkmalsraums bestimmen.
Wenn die Dimensionalität des Merkmalsraums zu niedrig ist, stimmt das erlernte Modell nicht mit den Daten überein, wenn sie zu hoch ist, kann es sein, dass das Modell zu stark übereinstimmt.
Generell betrachten wir wahrnehmungsbezogenes Lernen als etwas anderes als das Erlernen spezifischer Aufgaben. Das Ziel der Wahrnehmung besteht darin, alles Vorhersehbare über das Wahrgenommene zu erfahren.
Wie Einstein sagte: „Die Dinge sollten einfach gehalten werden, aber nicht zu einfach.“
Universal Learning Engine
Basierend auf diesen beiden Prinzipien wird der Artikel anhand visueller Bilddaten modelliert. Das komprimierende Transkriptionsgerüst mit geschlossenem Regelkreis wird abgeleitet.
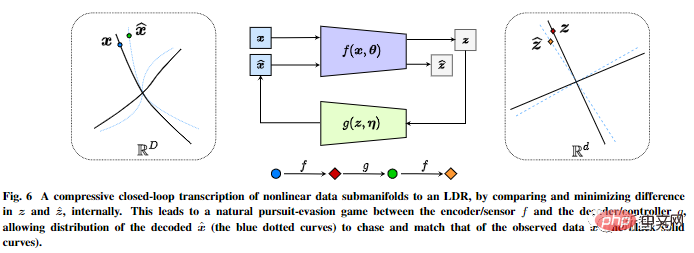
Es führt intern eine komprimierte Closed-Loop-Transkription nichtlinearer Datenunterflussmuster durch, indem es die Unterschiede in internen Darstellungen vergleicht und minimiert, um LDR zu erreichen.
Das Chase-and-Escape-Spiel zwischen dem Encoder/Sensor und dem Decoder/Controller ermöglicht die Verteilung der von der dekodierten Darstellung erzeugten Daten, um die beobachteten zu verfolgen und abzugleichen echte Daten verteilt.
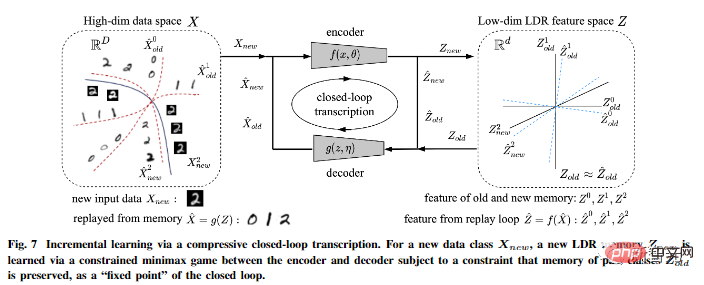
Darüber hinaus wies der Autor darauf hin, dass eine komprimierte Closed-Loop-Transkription dies kann Inkrementstudie effektiv durchführen.
Ein LDR-Modell für eine neue Datenklasse kann durch ein eingeschränktes Spiel zwischen dem Encoder und dem Decoder gelernt werden: Die Erinnerung an früher gelernte Klassen kann auf natürliche Weise beibehalten werden eine Einschränkung im Spiel, das heißt als „Fixpunkt“ für die Transkription im geschlossenen Regelkreis.
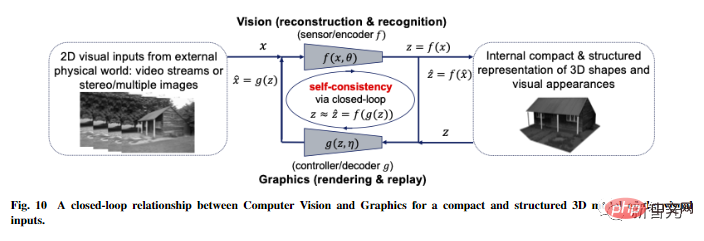
Der Artikel enthält auch weitere Ideen zur Universalität dieses spekulativen Rahmens Ideen, erweitern sie auf dreidimensionales Sehen und verstärkendes Lernen und prognostizieren ihre Auswirkungen auf Neurowissenschaften, Mathematik und fortgeschrittene Intelligenz.

Das obige ist der detaillierte Inhalt vonLeitet die KI-Entwicklung die Vereinigung in 70 Jahren ein? Ma Yi, Cao Ying, Shen Xiangyangs neueste KI-Rezension: Erkundung der Grundprinzipien und des „Standardmodells' der Intelligenzgenerierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
 O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
Openais O1: Ein 12-tägiger Geschenkbummel beginnt mit ihrem bisher mächtigsten Modell Die Ankunft im Dezember bringt eine globale Verlangsamung, Schneeflocken in einigen Teilen der Welt, aber Openai fängt gerade erst an. Sam Altman und sein Team starten ein 12-tägiges Geschenk Ex
 So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
Mistral OCR: revolutionäre retrieval-ausgereifte Generation mit multimodalem Dokumentverständnis RAG-Systeme (Abrufen-Augment-Augmented Generation) haben erheblich fortschrittliche KI
