

Was ist MySQL-Phantom-Lesen?

Phantom-Lesen bedeutet in MySQL, dass eine andere Transaktion eine neue Zeile in den Bereich einfügt, wenn der Benutzer die Datenzeilen im Bereich liest, und stellt fest, dass neue Zeilen vorhanden sind Das Sortiment. Die „Phantom“-Linie. Der sogenannte Phantom-Read bedeutet, dass der über SELECT abgefragte Datensatz kein realer Datensatz ist. Der Benutzer fragt über die SELECT-Anweisung ab, dass ein bestimmter Datensatz nicht vorhanden ist, er jedoch möglicherweise in der realen Tabelle vorhanden ist.

Die Betriebsumgebung dieses Tutorials: Windows7-System, MySQL8-Version, Dell G3-Computer.
Was ist Phantomlesen?
Lassen Sie uns zunächst den Isolationsgrad der Transaktion betrachten Phantomlesung, der entscheidende Punkt ist „Das Wort „Illusion“ ist sehr verträumt und mysteriös. Es ist ungewiss, ob es wahr ist oder nicht. Es ist, als wäre man mit einer Nebelschicht bedeckt. Man kann die andere Person nicht wirklich sehen. Den Menschen das Gefühl der Illusion vermitteln. Das ist „Illusion“. Der sogenannte Phantom-Read bedeutet, dass der Datensatz, den Sie über SELECT abfragen, kein echter Datensatz ist, den Sie über die SELECT-Anweisung abfragen, aber möglicherweise in der realen Tabelle vorhanden ist. 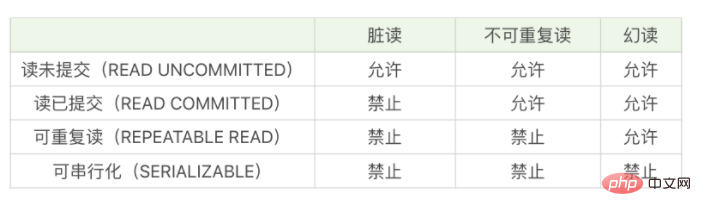 So verstehe ich Phantomlesen und nicht wiederholbares Lesen:
So verstehe ich Phantomlesen und nicht wiederholbares Lesen:
Beim Phantomlesen geht es darum, ob es existiert oder nicht: Wenn es vorher nicht existierte, aber jetzt existiert, dann ist es so Bei einer Phantomlesung li>
Nicht wiederholbare Lesung geht es um das Problem der Veränderung: Früher war es A, aber jetzt hat es sich in B geändert, dann ist es eine nicht wiederholbare LesungPhantomlesung, es gibt zwei Theorien, die ich bisher verstehe:
-
幻读说的是存不存在的问题:原来不存在的,现在存在了,则是幻读 -
不可重复读说的是变没变化的问题:原来是A,现在却变为了B,则为不可重复读
幻读,目前我了解的有两种说法:
说法一:事务 A 根据条件查询得到了 N 条数据,但此时事务 B 删除或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候真实的数据集已经发生了变化,但是A却查询不出来这种变化,因此产生了幻读。
这一种说法强调幻读在于某一个范围内的数据行变多或者是变少了,侧重说明的是数据集不一样导致了产生了幻读。
说法二:幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:A事务select 某记录是否存在,结果为不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。产生这样的原因是因为有另一个事务往表中插入了数据。
我个人更赞成第一种说法。
说法二这种情况也属于幻读,说法二归根到底还是数据集发生了改变,查询得到的数据集与真实的数据集不匹配。
对于说法二:当进行INSERT的时候,也需要隐式的读取,比如插入数据时需要读取有没有主键冲突,然后再决定是否能执行插入。如果这时发现已经有这个记录了,就没法插入。所以,SELECT 显示不存在,但是INSERT的时候发现已存在,说明符合条件的数据行发生了变化,也就是幻读的情况,而不可重复读指的是同一条记录的内容被修改了。
举例来说明:说法二说的是如下的情况:
有两个事务A和B,A事务先开启,然后A开始查询数据集中有没有id = 30的数据,查询的结果显示数据中没有id = 30的数据。紧接着又有一个事务B开启了,B事务往表中插入了一条id = 30的数据,然后提交了事务。然后A再开始往表中插入id = 30的数据,由于B事务已经插入了id = 30的数据,自然是不能插入,紧接着A又查询了一次,结果发现表中没有id = 30的数据呀,A事务就很纳闷了,怎么会插入不了数据呢。当A事务提交以后,再次查询,发现表中的确存在id = 30的数据。但是A事务还没提交的时候,却查不出来?
其实,这便是可重复读的作用。
过程如下图所示:

上图中操作的t表的创建语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
MySQL使用的InnoDB引擎默认的隔离级别是可重复读 Theorie 1
🎜Ich persönlich bevorzuge die erste Aussage. 🎜🎜Das zweite Argument ist ebenfalls ein Phantomwert. Das zweite Argument ist, dass sich der Datensatz geändert hat und der durch die Abfrage erhaltene Datensatz nicht mit dem realen Datensatz übereinstimmt. 🎜🎜 Zu Aussage 2: Beim Ausführen von INSERT ist auch ein implizites Lesen erforderlich. Wenn Sie beispielsweise Daten einfügen, müssen Sie lesen, ob ein Primärschlüsselkonflikt vorliegt, und dann entscheiden, ob das Einfügen durchgeführt werden kann. Wenn festgestellt wird, dass dieser Datensatz bereits vorhanden ist, kann er nicht eingefügt werden. Daher zeigt SELECT an, dass es nicht existiert, aber es wird beim INSERT als vorhanden erkannt, was bedeutet, dass sich die Datenzeilen, die die Bedingungen erfüllen, geändert haben, was beim Phantomlesen der Fall ist, während nicht wiederholbares Lesen bedeutet, dass der Inhalt von Derselbe Datensatz wurde geändert. 🎜🎜Um es an einem Beispiel zu veranschaulichen: Die zweite Aussage spricht von der folgenden Situation: 🎜 Es gibt zwei Transaktionen A und B. Zuerst wird Transaktion A geöffnet, und dann beginnt A abzufragen, ob in den Daten Daten mit der ID = 30 vorhanden sind Das Abfrageergebnis zeigt, dass die Daten keine Daten mit der ID = 30 enthalten. Unmittelbar danach wurde eine weitere Transaktion B geöffnet. Transaktion B fügte ein Datenelement mit der ID = 30 in die Tabelle ein und übermittelte dann die Transaktion. Dann beginnt A, die Daten mit der ID = 30 in die Tabelle einzufügen. Da die Transaktion B die Daten mit der ID = 30 bereits eingefügt hat, kann sie nicht auf natürliche Weise eingefügt werden. Dann stellt A eine erneute Abfrage fest und stellt fest, dass keine Daten mit der ID = 30 vorhanden sind Die Tabelle ist sehr verwirrt. Warum können keine Daten eingefügt werden? Nachdem Transaktion A übermittelt wurde, führen Sie eine erneute Abfrage durch und stellen Sie fest, dass die Daten mit der ID = 30 tatsächlich in der Tabelle vorhanden sind. Aber bevor Transaktion A eingereicht wurde, konnte sie nicht herausgefunden werden? 🎜 Tatsächlich ist dies die Rolle des
wiederholbaren Lesens. 🎜🎜Der Prozess ist wie folgt: 🎜🎜🎜🎜Die Erstellungsanweisung der in der obigen Abbildung betriebenen t-Tabelle lautet wie folgt: 🎜SELECT * FROM player WHERE ...
Repeatable Read, was bedeutet, dass die Ergebnisse identisch sein sollten, wenn Sie in derselben Transaktion dieselbe Abfrage zweimal ausführen. Obwohl Transaktion B vor dem Ende von Transaktion A Daten zur Tabelle hinzugefügt hat, können die neu hinzugefügten Daten daher nicht abgefragt werden, um ein wiederholbares Lesen aufrechtzuerhalten, unabhängig davon, wie sie in Transaktion A abgefragt werden. Aber für die reale Tabelle sind die Daten in der Tabelle tatsächlich gestiegen. 🎜
A查询不到这个数据,不代表这个数据不存在。查询得到了某条数据,不代表它真的存在。这样是是而非的查询,就像是幻觉一样,似真似假,故为幻读。
产生幻读的原因归根到底是由于查询得到的结果与真实的结果不匹配。
幻读 VS 不可重复读
幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。
简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。
可重复读隔离下为什么会产生幻读?
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在 当前读 下才会出现。
什么是快照读,什么是当前读?
快照读读取的是快照数据。不加锁的简单的 SELECT都属于快照读,比如这样:
SELECT * FROM player WHERE ...
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。
说多了,我们继续来看,如下的操作都会进行 当前读。
SELECT * FROM player LOCK IN SHARE MODE; SELECT * FROM player FOR UPDATE; INSERT INTO player values ... DELETE FROM player WHERE ... UPDATE player SET ...
说白了,快照读就是普通的读操作,而当前读包括了 加锁的读取 和 DML(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
比如在可重复读的隔离条件下,我开启了两个事务,在另一个事务中进行了插入操作,当前事务如果使用当前读 是可以读到最新的数据的。

MySQL中如何实现可重复读
当隔离级别为可重复读的时候,事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View。也就是说:对于A事务而言,不管其他事务怎么修改数据,对于A事务而言,它能看到的数据永远都是第一次SELECT时看到的数据。这显然不合理,如果其它事务插入了数据,A事务却只能看到过去的数据,读取不了当前的数据。
既然都说到 Read View 了,就不得不说 MVCC (多版本并发控制) 机制了。MVCC 其实字面意思还比较好理解,为了防止数据产生冲突,我们可以使用时间戳之类的来进行标识,不同的时间戳对应着不同的版本。比如你现在有1000元,你借给了张三 500 元, 之后李四给了你 500 元,虽然你的钱的总额都是 1000元,但是其实已经和最开始的 1000元不一样了,为了判断中途是否有修改,我们就可以采用版本号来区分你的钱的变动。
如下,在数据库的数据表中,id,name,type 这三个字段是我自己建立的,但是除了这些字段,其实还有些隐藏字段是 MySQL 偷偷为我们添加的,我们通常是看不到这样的隐藏字段的。

我们重点关注这两个隐藏的字段:
db_trx_id: Die Transaktions-ID, die diese Datenzeile verwaltet, d. h. die letzte Transaktions-ID, die die Daten eingefügt oder aktualisiert hat. Jedes Mal, wenn wir eine Transaktion starten, erhalten wir eine Transaktions-ID (dh die Transaktionsversionsnummer) aus der Datenbank. Anhand der ID-Größe können wir die zeitliche Abfolge der Transaktion beurteilen.
db_roll_ptr: Rollback-Zeiger, der auf die Rückgängig-Protokoll-Informationen dieses Datensatzes zeigt. Was ist ein Rückgängig-Protokoll? Es versteht sich, dass MySQL befürchtet, dass die Änderung in Zukunft möglicherweise widerrufen und auf den vorherigen Status zurückgesetzt wird, wenn wir einen bestimmten Datensatz ändern müssen. Speichern Sie daher vor der Änderung die aktuellen Daten in einer Datei und ändern Sie sie dann , Protokoll rückgängig machen Es kann als diese Archivdatei verstanden werden. Das ist so, als ob wir ein bestimmtes Level erreichen, indem wir zuerst eine Datei speichern und dann mit dem nächsten Level fortfahren. Wenn es uns nicht gelingt, das nächste Level herauszufordern, kehren wir stattdessen zum vorherigen Speicherpunkt zurück von vorne anzufangen.
Im MVCC-Mechanismus (Multiple Version Concurrency Control) generieren mehrere Transaktionen, die denselben Zeilendatensatz aktualisieren, mehrere historische Snapshots, und diese historischen Snapshots werden im „Undo-Protokoll“ gespeichert. Wie in der folgenden Abbildung gezeigt, zeigt der in der aktuellen Zeile aufgezeichnete Rollback-Zeiger auf seinen vorherigen Status, und der Rollback-Zeiger seines vorherigen Status zeigt auf den vorherigen Status des vorherigen Status. Auf diese Weise können wir theoretisch jeden Zustand der Datenzeile finden, indem wir den Rollback-Zeiger durchlaufen. Schematische Darstellung des Rückgängig-Protokolls
Wir hatten nicht erwartet, dass das, was wir sahen, nur ein Datenelement sein könnte, aber MySQL speicherte hinter den Kulissen mehrere Versionen dieser Daten und speicherte viele Dateien für diese Daten. Hier stellt sich die Frage: Wenn wir eine Transaktion starten, möchten wir ein bestimmtes Datenelement in der Transaktion abfragen, aber jedes Datenelement entspricht vielen Versionen. Welche Version des Zeilendatensatzes müssen wir zu diesem Zeitpunkt lesen?
Zu diesem Zeitpunkt müssen wir den
-Mechanismus verwenden, der uns hilft, das Problem der Zeilensichtbarkeit zu lösen. Die Leseansicht speichert eine Liste aller aktiven (noch nicht festgeschriebenen) Transaktionen, wenn die aktuelle Transaktion geöffnet wird.Read ViewEs gibt mehrere wichtige Attribute in der Leseansicht:
- trx_ids
- , der Satz von Transaktions-IDs, die derzeit im System aktiv sind low_limit_id
- , die größte Transaktions-ID unter den aktiven Transaktionen up_limit_id
- , aktiv Die kleinste Transaktions-ID in der Transaktion creator_trx_id
- , die Transaktions-ID, die diese Leseansicht erstellt hat Wie bereits erwähnt, gibt es in jeder Datensatzzeile ein verstecktes Feld
, das die Transaktions-ID darstellt, die diese Zeile betreibt von Daten und die Transaktions-ID erhöht sich selbst. Anhand der ID-Größe können wir die zeitliche Abfolge der Transaktion beurteilen. Nachdem wir die Transaktion gestartet haben, werden wir einen bestimmten Datensatz abfragen und die db_trx_id
<up_limit_id des Datensatzes finden. Das bedeutet, dass dieser Datensatz vor Beginn dieser Transaktion übermittelt worden sein muss. Es handelt sich hierbei um historische Daten und wir können diesen Datensatz daher definitiv über select finden. Aber wenn gefunden, wird die db_trx_id
>up_limit_id des abzufragenden Datensatzes angezeigt. Was bedeutet das? Es bedeutet, dass dieser Datensatz beim Öffnen der Transaktion noch nicht vorhanden sein darf und von der aktuellen Transaktion nicht angezeigt werden sollte Finden Sie die historische Version des Datensatzes und geben Sie sie an die aktuelle Transaktion zurück. In diesem Artikel Was ist Phantomlesen? Ein Beispiel in diesem Kapitel. Wenn Transaktion A gestartet wird, gibt es keinen Datensatz (30, 30, 30) in der Datenbank. Nachdem Transaktion A gestartet wurde, fügt Transaktion B den Datensatz (30, 30, 30) in die Datenbank ein. Zu diesem Zeitpunkt kann Transaktion A diesen Datensatz nicht abfragen, wenn sie select ohne Sperre verwendet, um Snapshot-Lesen durchzuführen entspricht unseren Erwartungen. Für Transaktion A muss die db_trx_id dieses Datensatzes (30, 30, 30) größer sein als die up_limit_id, wenn Transaktion A gestartet wird, sodass dieser Datensatz von Transaktion A nicht gesehen werden sollte. Wenn die trx_id des abzufragenden Datensatzes die Bedingung up_limit_id
<trx_id < low_limit_id erfüllt, bedeutet dies, dass die Transaktion trx_id in der sich der Zeilendatensatz befindet Die aktuelle creator_trx_id-Transaktion wurde erstellt und befindet sich möglicherweise noch in einem aktiven Zustand. Wenn trx_id in der trx_ids-Sammlung vorhanden ist, beweist dies, dass diese Transaktion trx_id ist ist immer noch aktiv und unsichtbar. Wenn der Datensatz über ein Undo-Protokoll verfügt, können wir den Rollback-Zeiger durchlaufen und die historischen Versionsdaten des Datensatzes abfragen. Wenn trx_id nicht in der trx_ids-Sammlung vorhanden ist, beweist dies, dass die Transaktion trx_id übermittelt wurde und der Zeilendatensatz sichtbar ist.
从图中你能看到回滚指针将数据行的所有快照记录都通过链表的结构串联了起来,每个快照的记录都保存了当时的 db_trx_id,也是那个时间点操作这个数据的事务 ID。这样如果我们想要找历史快照,就可以通过遍历回滚指针的方式进行查找。
最后,再来强调一遍:事务只在第一次 SELECT 的时候会获取一次 Read View
因此,如下图所示,在 可重复读 的隔离条件下,在该事务中不管进行多少次 以WHERE heigh > 2.08为条件 的查询,最终结果得到都是一样的,尽管可能会有其它事务对这个结果集进行了更改。

如何解决幻读
即便是给每行数据都加上行锁,也无法解决幻读,行锁只能阻止修改,无法阻止数据的删除。而且新插入的数据,自然是数据库中不存在的数据,原本不存在的数据自然无法对其加锁,因此仅仅使用行锁是无法阻止别的事务插入数据的。
为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。
表 t 主键索引上的行锁和间隙锁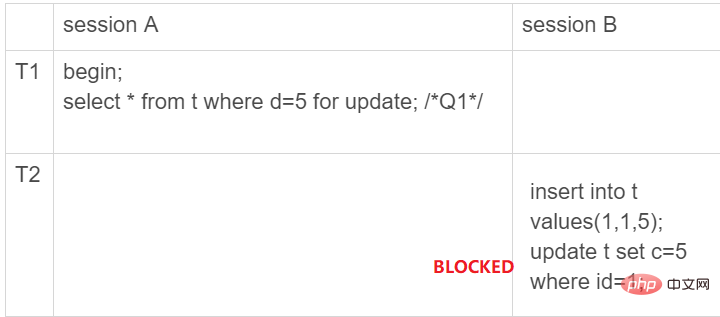
也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。现在你知道了,数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。
- 间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。也就是说,我们的表 t 初始化以后,如果用
SELECT * FEOM t FOR UPDATE要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (负无穷,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, 正无穷]。 - 间隙锁是在可重复读隔离级别下才会生效的
怎么加间隙锁呢?使用写锁(又叫排它锁,X锁)时自动生效,也就是说我们执行 SELECT * FEOM t FOR UPDATE时便会自动触发间隙锁。会给主键加上上图所示的锁。
如下图所示,如果在事务A中执行了SELECT * FROM t WHERE d = 5 FOR UPDATE以后,事务B则无法插入数据了,因此就避免了产生幻读。
数据表的创建语句如下
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
需要注意的是,由于创建数据表的时候仅仅只在c字段上创建了索引,因此使用条件WHERE id = 5查找时是会扫描全表的。因此,SELECT * FROM t WHERE d = 5 FOR UPDATE实际上锁住了整个表,如上图所示,产生了七个间隙,这七个间隙都不允许数据的插入。
因此当B想插入一条数据(1, 1, 1)时就会被阻塞住,因为它的主键位于位于(0, 5]这个区间,被禁止插入。
还需要注意的一点是,间隙锁和间隙锁是不会产生冲突的。读锁(又称共享锁,S锁)和写锁会冲突,写锁和写锁也会产生冲突。但是间隙锁和间隙锁是不会产生冲突的
如下:
A事务对id = 5的数据加了读锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁则会成功。读锁和读锁可以兼容,读锁和写锁则不能兼容。
A事务对id = 5的数据加了写锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁同样也会失败。
在加了间隙锁以后,当A事务开启以后,并对(5, 10]这个区间加了间隙锁,那么B事务则无法插入数据了。

但是当A事务对(5, 10]加了间隙锁以后,B事务也可以对这个区间加间隙锁。
Der Zweck der Lückensperre besteht darin, zu verhindern, dass Daten in dieses Intervall eingefügt werden. Daher fügt Transaktion B weiterhin Lückensperren hinzu. Bei Schreibsperren und Lesesperren ist es jedoch unterschiedlich.
Eine Schreibsperre erlaubt anderen Transaktionen nicht das Lesen oder Schreiben, während eine Lesesperre das Schreiben zulässt, sodass ein semantischer Konflikt vorliegt. Natürlich können Sie diese beiden Sperren nicht gleichzeitig hinzufügen.
Das Gleiche gilt für Schreibsperren, und Schreibsperren erlauben kein Lesen oder Schreiben. Transaktion A fügt den Daten eine Schreibsperre hinzu, was bedeutet, dass keine anderen Transaktionen ausgeführt werden sollen Wenn dann andere Daten vorhanden sind, entspricht das Hinzufügen einer Schreibsperre zu diesen Daten dem Ausführen einer Operation an den Daten, was gegen die Bedeutung der Schreibsperre verstößt und natürlich nicht zulässig ist.
【Verwandte Empfehlungen: MySQL-Video-Tutorial】
Das obige ist der detaillierte Inhalt vonWas ist MySQL-Phantom-Lesen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
Die Hauptaufgabe von MySQL in Webanwendungen besteht darin, Daten zu speichern und zu verwalten. 1.Mysql verarbeitet effizient Benutzerinformationen, Produktkataloge, Transaktionsunterlagen und andere Daten. 2. Durch die SQL -Abfrage können Entwickler Informationen aus der Datenbank extrahieren, um dynamische Inhalte zu generieren. 3.Mysql arbeitet basierend auf dem Client-Server-Modell, um eine akzeptable Abfragegeschwindigkeit sicherzustellen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
