

Im heutigen Informationszeitalter sind Bilder oder visuelle Inhalte längst zum wichtigsten Informationsträger im täglichen Leben geworden. Deep-Learning-Modelle verlassen sich auf ihr leistungsstarkes Verständnis visueller Inhalte, um verschiedene Verarbeitungs- und Verarbeitungsvorgänge durchzuführen Optimierung darauf.
Allerdings haben wir bei der Entwicklung und Anwendung visueller Modelle in der Vergangenheit mehr Wert auf die Optimierung des Modells selbst gelegt, um seine Geschwindigkeit und Wirkung zu verbessern. Im Gegenteil, bei der Vor- und Nachbearbeitung von Bildern wird kaum ernsthaft darüber nachgedacht, wie man sie optimieren kann. Wenn daher die Recheneffizienz des Modells immer höher wird, habe ich im Rückblick auf die Vor- und Nachbearbeitung des Bildes nicht erwartet, dass sie zum Engpass der gesamten Bildaufgabe geworden sind.
Um solche Engpässe zu lösen, hat NVIDIA mit dem ByteDance-Team für maschinelles Lernen zusammengearbeitet, um viele Bildvorverarbeitungs-Operatorbibliotheken CV-CUDA zu öffnen. Sie können effizient auf der GPU ausgeführt werden, und die Operatorgeschwindigkeit kann OpenCV (laufend) erreichen auf der CPU) Ungefähr hundertmal. Wenn wir CV-CUDA als Backend verwenden, um OpenCV und TorchVision zu ersetzen, kann der Durchsatz der gesamten Inferenz mehr als das 20-fache des Originals erreichen. Darüber hinaus wird nicht nur die Geschwindigkeit verbessert, sondern CV-CUDA wurde auch in Bezug auf die Berechnungsgenauigkeit an OpenCV angepasst, sodass Training und Inferenz nahtlos verbunden werden können, was die Arbeitsbelastung der Ingenieure erheblich reduziert.
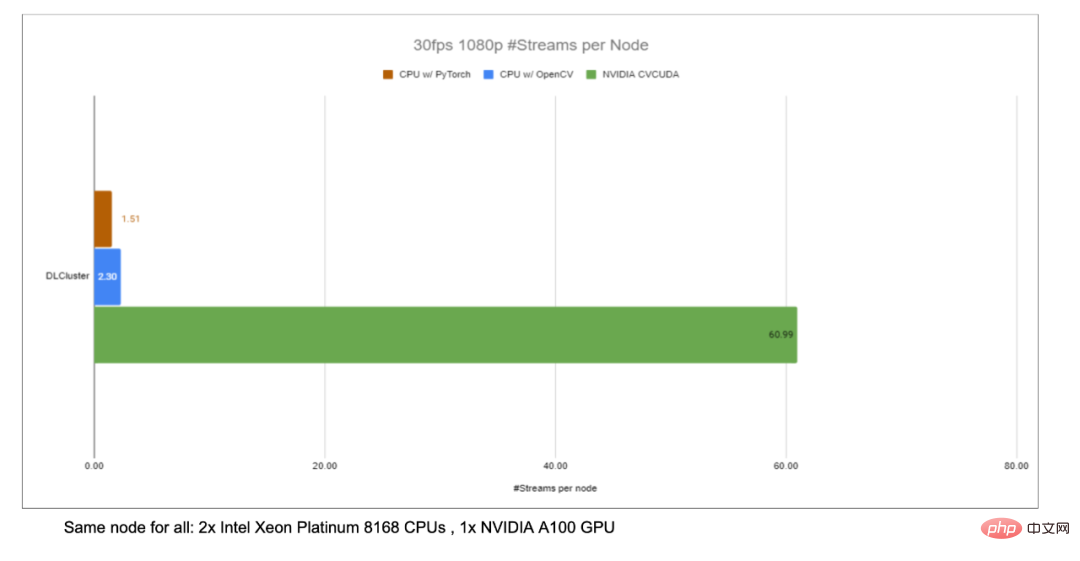
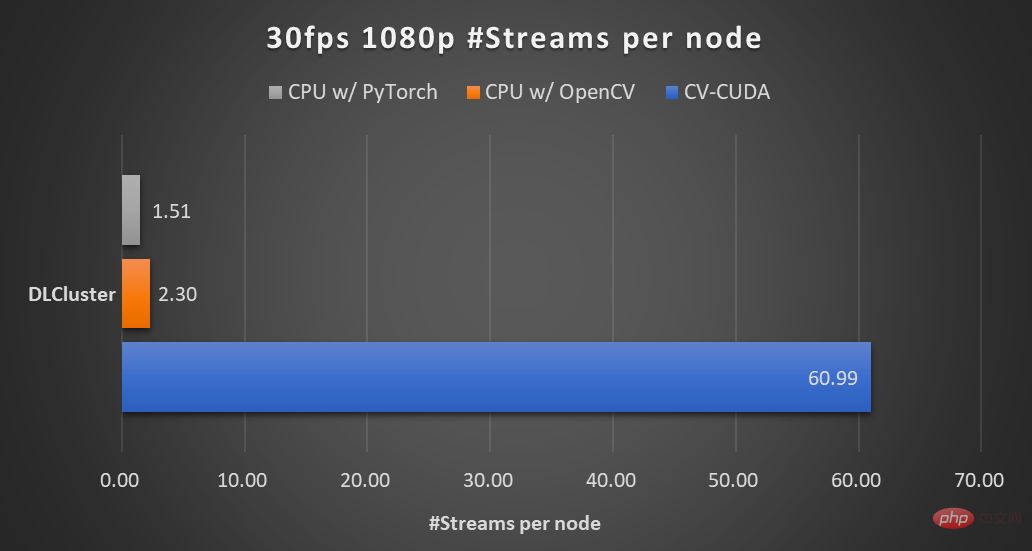
Ersetzen Sie am Beispiel des Bildhintergrundunschärfealgorithmus OpenCV durch CV -CUDA Als Backend der Bildvor-/-nachbearbeitung kann der Durchsatz des gesamten Inferenzprozesses um mehr als das 20-fache gesteigert werden.
Wenn Sie eine schnellere und bessere visuelle Vorverarbeitungsbibliothek ausprobieren möchten, können Sie dieses Open-Source-Tool ausprobieren. Open-Source-Adresse: https://github.com/CVCUDA/CV-CUDA
Viele Algorithmeningenieure, die sich mit Technik und Produkten befassen, wissen das, obwohl wir oft nur über die Modellstruktur sprechen. „Spitzenforschung“ und Schulungsaufgaben, aber um tatsächlich ein zuverlässiges Produkt herzustellen, werden Sie dabei auf viele technische Probleme stoßen. Im Gegenteil, das Modelltraining ist der einfachste Teil. Die Bildvorverarbeitung ist ein solches technisches Problem. Möglicherweise rufen wir während Experimenten oder Schulungen einfach einige APIs auf, um eine geometrische Transformation, Filterung, Farbtransformation usw. am Bild durchzuführen, und es ist uns möglicherweise nicht besonders wichtig. Wenn wir jedoch den gesamten Argumentationsprozess überdenken, stellen wir fest, dass die Bildvorverarbeitung zu einem Leistungsengpass geworden ist, insbesondere bei visuellen Aufgaben mit komplexen Vorverarbeitungsprozessen.
Solche Leistungsengpässe spiegeln sich hauptsächlich in der CPU wider. Im Allgemeinen führen wir bei herkömmlichen Bildverarbeitungsprozessen zunächst eine Vorverarbeitung auf der CPU durch, legen sie dann auf die GPU, um das Modell auszuführen, und kehren schließlich zur CPU zurück. Möglicherweise müssen wir eine Nachbearbeitung durchführen.
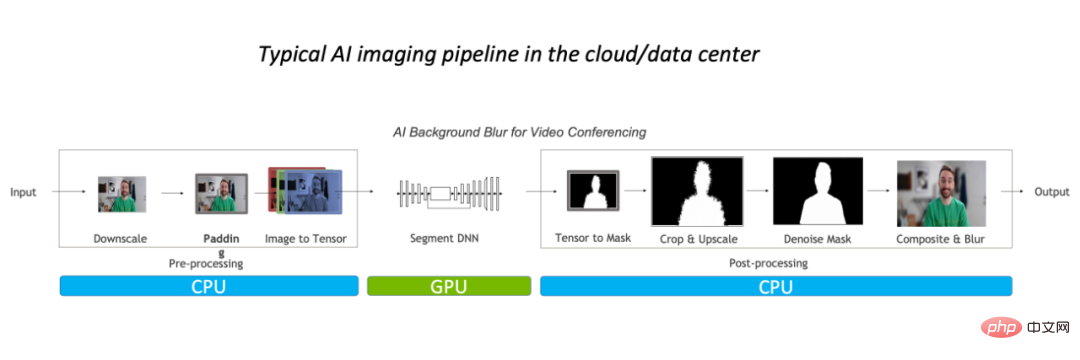
Am Beispiel des Bildhintergrundunschärfealgorithmus im herkömmlichen Bild Verarbeitungsprozess Die Prognoseverarbeitung erfolgt hauptsächlich auf der CPU und macht 90 % der Gesamtarbeitslast aus, was zum Engpass dieser Aufgabe geworden ist.
Daher für Videoanwendungen oder komplexe Szenen wie 3D-Bildmodellierung, da die Anzahl der Bildrahmen oder Bildinformationen groß ist Wenn der Verarbeitungsprozess komplex genug und die Latenzanforderungen niedrig genug sind, ist es dringend erforderlich, die Vor-/Nachverarbeitungsoperatoren zu optimieren. Ein besserer Ansatz besteht natürlich darin, OpenCV durch eine schnellere Lösung zu ersetzen. Warum ist es nicht gut genug?
In CV ist natürlich die seit langem gepflegte OpenCV die am weitesten verbreitete Bildverarbeitungsbibliothek. Sie verfügt über ein sehr breites Spektrum an Bildverarbeitungsoperationen Grundsätzlich kann es die Vor-/Nachbearbeitungsanforderungen verschiedener visueller Aufgaben erfüllen. Mit zunehmender Auslastung der Bildaufgabe kann die Geschwindigkeit jedoch langsam nicht mehr mithalten, da die meisten Bildvorgänge von OpenCV von der CPU implementiert werden, die GPU-Implementierung fehlt oder es Probleme mit der GPU-Implementierung gibt. In der Forschungs- und Entwicklungserfahrung von NVIDIA- und ByteDance-Algorithmusstudenten stellten sie fest, dass die wenigen Operatoren in OpenCV, die von der GPU implementiert werden, drei Hauptprobleme haben: GPU Bildverarbeitungsbeschleunigungsbibliothek: CV-CUDA CV-CUDADie Geschwindigkeit von CV-CUDA spiegelt sich zunächst in der effizienten Operatorimplementierung wider. Schließlich muss der CUDA-Parallel-Computing-Code einer viel Optimierung. Zweitens unterstützt es Batch-Operationen, die die Rechenleistung des GPU-Geräts voll ausnutzen können. Im Vergleich zur seriellen Ausführung von Bildern einzeln auf der CPU sind Batch-Operationen definitiv viel schneller. Dank der GPU-Architekturen wie Volta, Turing und Ampere, an die CV-CUDA angepasst ist, wird schließlich die Leistung auf der CUDA-Kernel-Ebene jeder GPU stark optimiert, um die besten Ergebnisse zu erzielen. Mit anderen Worten: Je besser die von Ihnen verwendete GPU-Karte ist, desto übertriebener sind ihre Beschleunigungsfähigkeiten. Wie im vorherigen Diagramm zum Beschleunigungsverhältnis des Hintergrundunschärfe-Durchsatzes gezeigt, erhöht sich der Durchsatz des gesamten Inferenzprozesses um mehr als das Zwanzigfache, wenn CV-CUDA als Ersatz für die Vor- und Nachbearbeitung von OpenCV und TorchVision verwendet wird. Unter anderem führt die Vorverarbeitung Vorgänge wie Größenänderung, Auffüllung und Image2Tensor für das Bild aus, und die Nachverarbeitung führt Vorgänge wie Tensor2Mask, Crop, Resize und Denoise für die Vorhersageergebnisse aus. Für die Leistung eines einzelnen Operators haben die Partner von NVIDIA und ByteDance auch Leistungstests durchgeführt. Der Durchsatz vieler Operatoren auf der GPU kann das Hundertfache des CPU-Durchsatzes erreichen. Die Bildgröße beträgt 480*360, die CPU-Auswahl ist Intel(R) Core(TM) i9-7900X, die BatchSize-Größe beträgt 1 und die Anzahl der Prozesse beträgt 1 Obwohl viele Vor-/ Nachbearbeitungsoperatoren sind nicht vorhanden. Um die oben erwähnte effiziente Leistung für einfache Matrixmultiplikationen und andere Operationen zu erreichen, hat CV-CUDA tatsächlich viele Optimierungen auf Operatorebene durchgeführt. Beispielsweise wird eine große Anzahl von Kernel-Fusionsstrategien übernommen, um die Zugriffszeit beim Kernel-Start zu verkürzen, und der globale Speicherzugriff wird optimiert, um die Effizienz beim Lesen und Schreiben von Daten zu verbessern. Alle Operatoren werden asynchron verarbeitet, um die Zeit des synchronen Wartens zu verkürzen . Die Vielseitigkeit und Flexibilität von CV-CUDA Die Stabilität der Berechnungsergebnisse ist zu wichtig für tatsächliche Projekte wie gängige Größenänderungsvorgänge, OpenCV, OpenCV-gpu und Torchvision Die Implementierung Die Methoden sind unterschiedlich, sodass von der Schulung bis zur Bereitstellung viel mehr Arbeit erforderlich ist, um die Ergebnisse abzugleichen. CV-CUDAEinfach zu verwenden Vielleicht denken viele Ingenieure, dass CV-CUDA den zugrunde liegenden CUDA-Operator beinhaltet, also sollte es schwieriger zu verwenden sein? Dies ist jedoch nicht der Fall, selbst wenn es nicht auf APIs höherer Ebene angewiesen ist, stellt die unterste Ebene von CV-CUDA selbst Strukturen wie und die Allocator-Klasse bereit, sodass es nicht mühsam ist, sie in C++ anzupassen. Darüber hinaus bietet CV-CUDA auf der oberen Ebene Datenkonvertierungsschnittstellen für PyTorch, OpenCV und Pillow, sodass Ingenieure Bediener schnell austauschen und auf vertraute Weise anrufen können. C++-Schnittstelle von CV-CUDA für die Größenänderung während der ausbildung prozess schnittstelle, Tatsächlich ist die Verwendung sehr einfach. Es sind nur wenige einfache Schritte erforderlich, um alle Vorverarbeitungsvorgänge, die ursprünglich auf der CPU ausgeführt wurden, auf die GPU zu migrieren. Nehmen Sie als Beispiel die Bildklassifizierung. Im Grunde müssen wir das Bild in der Vorverarbeitungsphase in einen Tensor dekodieren und es zuschneiden, um es an die Modelleingabegröße anzupassen. Nach dem Zuschneiden müssen wir den Pixelwert in einen Gleitkomma-Datentyp konvertieren und führen Sie nach der Transformation eine Normalisierung durch, die dann zur Vorwärtsweitergabe an das Deep-Learning-Modell übergeben werden kann. Im Folgenden werden wir anhand einiger einfacher Codeblöcke erleben, wie CV-CUDA Bilder vorverarbeitet und mit Pytorch interagiert. Der Vorverarbeitungsprozess der herkömmlichen Bilderkennung unter Verwendung von CV-CUDA vereinheitlicht den Vorverarbeitungsprozess und die Modellberechnung auf der GPU. Wie folgt: Nach Verwendung der Torchvision-API zum Laden des Bildes auf die GPU kann der Torch-Tensor-Typ über as_tensor direkt in das CV-CUDA-Objekt nvcvInputTensor konvertiert werden, sodass die API des CV-CUDA-Vorverarbeitungsvorgangs ausgeführt werden kann Wird direkt aufgerufen, um die Bildverarbeitung in der GPU verschiedener Transformationen abzuschließen. Die folgenden Codezeilen verwenden CV-CUDA, um den Vorverarbeitungsprozess der Bilderkennung in der GPU abzuschließen: Bild zuschneiden und Pixel normalisieren. Unter anderem konvertiert resize() den Bildtensor in die Eingabetensorgröße des Modells. Convertto() wandelt den Pixelwert in einen Gleitkommawert mit einfacher Genauigkeit um das Modell. Mit Hilfe verschiedener APIs von CV-CUDA wurde nun die Vorverarbeitung der Bildklassifizierungsaufgabe abgeschlossen, die das parallele Rechnen auf der GPU effizient abschließen und problemlos in PyTorch integrieren kann Modellierungsprozess gängiger Deep-Learning-Frameworks. Im Übrigen müssen Sie nur das CV-CUDA-Objekt nvcvPreprocessedTensor in den Typ Torch Tensor konvertieren, um es dem Modell zuzuführen. Auch dieser Schritt ist sehr einfach. Die Konvertierung erfordert nur eine Codezeile: Anhand dieses einfachen Beispiels lässt sich leicht erkennen, dass CV-CUDA tatsächlich problemlos in die normale Modelltrainingslogik eingebettet werden kann. Wenn Leser weitere Nutzungsdetails erfahren möchten, können sie dennoch die oben genannte Open-Source-Adresse von CV-CUDA überprüfen. CV-CUDA wurde tatsächlich im tatsächlichen Geschäftsbetrieb getestet. Bei visuellen Aufgaben, insbesondere bei Aufgaben mit relativ komplexen Bildvorverarbeitungsprozessen, kann die Nutzung der enormen Rechenleistung der GPU für die Vorverarbeitung die Effizienz des Modelltrainings und der Inferenz effektiv verbessern. CV-CUDA wird derzeit in mehreren Online- und Offline-Szenarien innerhalb der Douyin Group verwendet, wie z. B. multimodale Suche, Bildklassifizierung usw. Bei Bytedance OCR und multimodalen Videoaufgaben kann durch die Verwendung von CV-CUDA die Gesamttrainingsgeschwindigkeit um das 1- bis 2-fache erhöht werden (Hinweis: Es handelt sich um eine Erhöhung der Gesamttrainingsgeschwindigkeit von Dasselbe gilt für den Inferenzprozess. Das ByteDance-Team für maschinelles Lernen gab an, dass nach der Verwendung von CV-CUDA in einer multimodalen Suchaufgabe der gesamte Online-Durchsatz doppelt so hoch war wie bei Verwendung der CPU für die Vorverarbeitung. Es ist erwähnenswert, dass die CPU-Basisergebnisse hier bereits stark für Multi-Core optimiert sind und die Vorverarbeitungslogik für diese Aufgabe relativ einfach ist, der Beschleunigungseffekt jedoch nach der Verwendung von CV-CUDA immer noch sehr offensichtlich ist. Es ist effizient genug in Bezug auf die Geschwindigkeit, um den Vorverarbeitungsengpass bei visuellen Aufgaben zu überwinden, und es ist außerdem einfach und flexibel zu verwenden. CV-CUDA hat bewiesen, dass es die Modellbegründung und Trainingseffekte in tatsächlichen Anwendungsszenarien erheblich verbessern kann. Wenn also Leser Vision-Aufgaben auch durch die Vorverarbeitungseffizienz eingeschränkt sind, versuchen Sie es mit dem neuesten Open-Source-CV-CUDA.
Vollständige Vor- und Nachbearbeitung auf der GPU, wodurch der CPU-Engpass im Bildverarbeitungsteil erheblich reduziert wird. 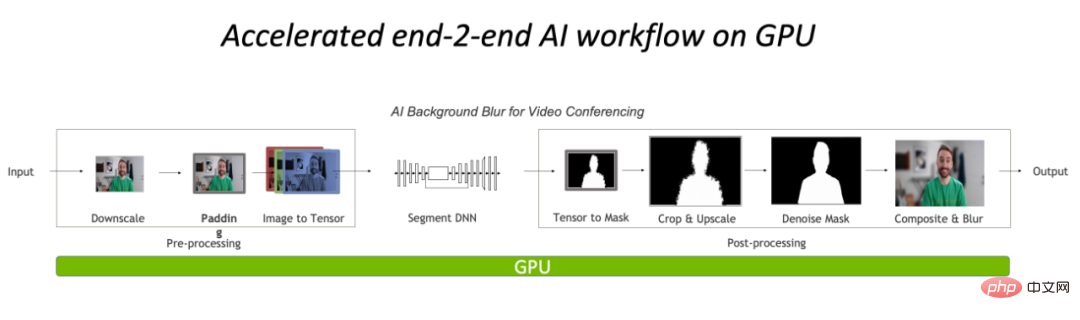
Als auf CUDA basierende Vor-/Nachbearbeitungs-Operatorbibliothek können sich Algorithmeningenieure am meisten auf drei Dinge freuen: schnell genug, vielseitig genug , und ausreichend einfach zu bedienen. CV-CUDA, gemeinsam entwickelt von NVIDIA und dem Team für maschinelles Lernen von ByteDance, kann genau diese drei Punkte erfüllen. Es nutzt die parallele Rechenleistung der GPU, um die Bedienergeschwindigkeit zu verbessern, richtet die OpenCV-Betriebsergebnisse so aus, dass sie vielseitig genug sind, und ist einfach zu verwenden mit der C++/Python-Schnittstelle.
Zu Beginn des Entwurfs von CV-CUDA wurde davon ausgegangen, dass viele Ingenieure es gewohnt sind, die CPU-Version von OpenCV in der aktuellen Bildverarbeitungsbibliothek zu verwenden. Daher gilt beim Entwerfen von Operatoren, ob es sich um Funktionsparameter oder Bildverarbeitungsergebnisse handelt. Richten Sie die OpenCV-CPU-Version so weit wie möglich an den Bediener aus. Daher sind bei der Migration von OpenCV zu CV-CUDA nur wenige Änderungen erforderlich, um konsistente Rechenergebnisse zu erhalten, und das Modell muss nicht neu trainiert werden.
Darüber hinaus wird CV-CUDA auf Bedienerebene entwickelt, sodass es unabhängig vom Vor-/Nachbearbeitungsprozess des Modells frei kombiniert werden kann und eine hohe Flexibilität aufweist.
Das Team für maschinelles Lernen von ByteDance gab an, dass im Unternehmen viele Modelle trainiert werden und die erforderliche Vorverarbeitungslogik ebenfalls vielfältig ist und viele maßgeschneiderte Anforderungen an die Vorverarbeitungslogik aufweist. Die Flexibilität von CV-CUDA kann sicherstellen, dass jedes OP den Eingang von Stream-Objekten und Videospeicherobjekten (Puffer- und Tensorklassen, die Videospeicherzeiger intern speichern) unterstützt, sodass entsprechende GPU-Ressourcen flexibler konfiguriert werden können. Bei der Konzeption und Entwicklung jeder einzelnen Operation berücksichtigen wir nicht nur die Vielseitigkeit, sondern stellen bei Bedarf auch maßgeschneiderte Schnittstellen bereit, die verschiedene Anforderungen an die Bildvorverarbeitung abdecken.
Da CV-CUDA außerdem über eine C++-Schnittstelle und eine Python-Schnittstelle verfügt, kann es sowohl in Trainings- als auch in Servicebereitstellungsszenarien verwendet werden. Die Python-Schnittstelle wird verwendet, um die Modellfunktionen während des Trainings schnell zu überprüfen, und die C++-Schnittstelle wird für verwendet Effizientere Vorhersagen während der Bereitstellung. CV-CUDA vermeidet den umständlichen Prozess der Ergebnisausrichtung vor der Verarbeitung und verbessert die Effizienz des Gesamtprozesses. 
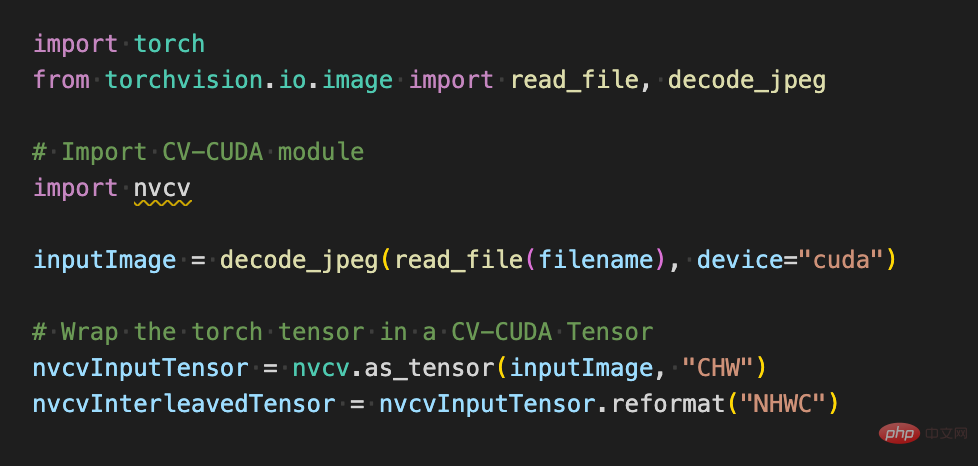
Die Verwendung verschiedener Vorverarbeitungsvorgänge in CV-CUDA unterscheidet sich nicht wesentlich von denen in OpenCV oder Torchvision. Es handelt sich lediglich um eine einfache Anpassung der Methode, und die Berechnungen sind bereits auf der dahinter liegenden GPU abgeschlossen. 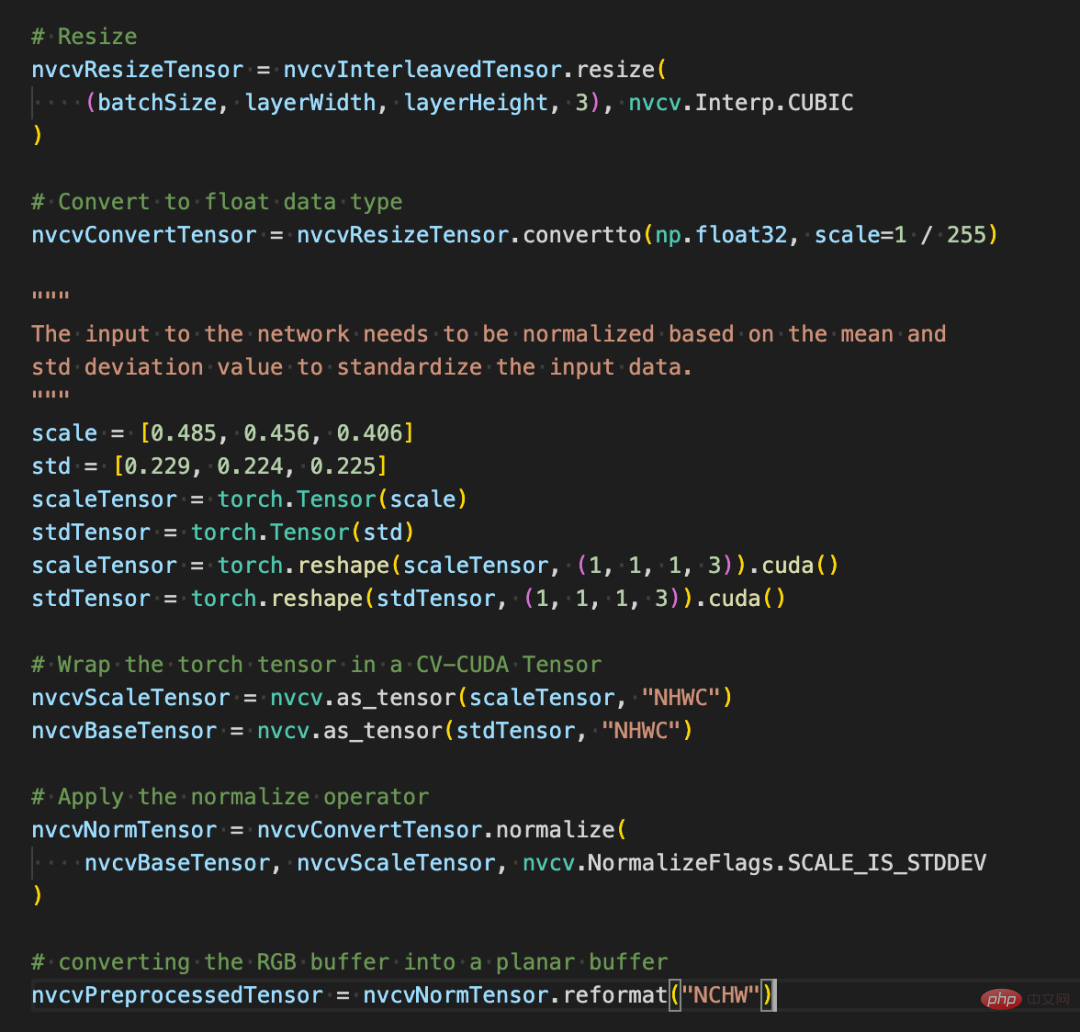
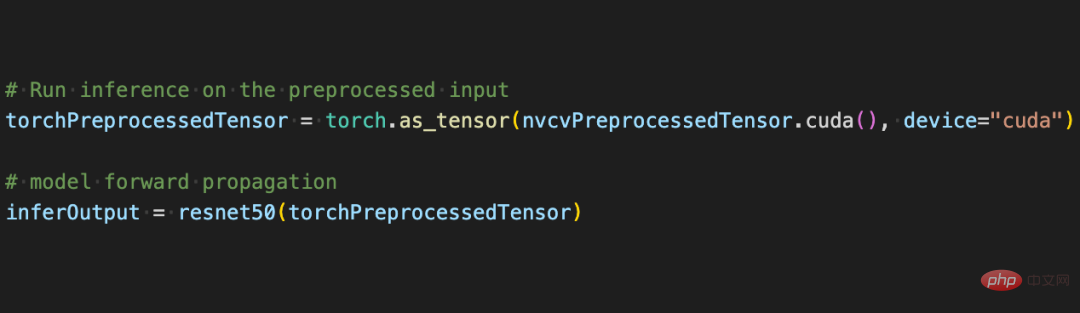
CV-CUDAVerbesserung des tatsächlichen Geschäftsbetriebs
Das maschinelle Lernteam von ByteDance gab an, dass die interne Verwendung von CV-CUDA die Leistung von Training und Inferenz erheblich verbessern kann. In Bezug auf das Training ist Bytedance beispielsweise eine videobezogene multimodale Aufgabe. Der Vorverarbeitungsteil umfasst die Dekodierung von Multi-Frame-Videos und viele Datenverbesserungen, was diesen Teil der Logik sehr kompliziert macht. Die komplexe Vorverarbeitungslogik führt dazu, dass die Multi-Core-Leistung der CPU während des Trainings immer noch nicht mithalten kann. Daher wird CV-CUDA verwendet, um die gesamte Vorverarbeitungslogik auf der CPU auf die GPU zu migrieren, wodurch eine Beschleunigung der gesamten Trainingsgeschwindigkeit um 90 % erreicht wird . Beachten Sie, dass dies eine Steigerung der gesamten Trainingsgeschwindigkeit darstellt, nicht nur im Vorverarbeitungsteil. 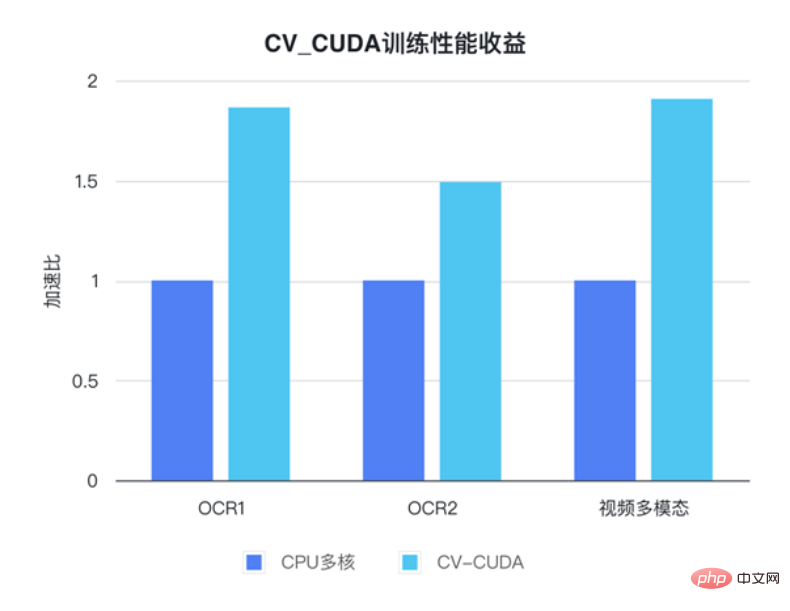
Das obige ist der detaillierte Inhalt vonDie Bildvorverarbeitungsbibliothek CV-CUDA ist Open Source, wodurch der Vorverarbeitungsengpass überwunden und der Inferenzdurchsatz um mehr als das Zwanzigfache erhöht wird.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



