

Der Bloom-Filter wurde 1970 von einem Mann namens Bloom vorgeschlagen.
Man kann es sich tatsächlich als eine Datenstruktur vorstellen, die aus einem binären Vektor (oder Bit-Array) und einer Reihe zufälliger Zuordnungsfunktionen (Hash-Funktionen) besteht.
Sein Vorteil besteht darin, dass die Speicherplatzeffizienz und die Abfragezeit viel besser sind als bei herkömmlichen Algorithmen. Der Nachteil besteht darin, dass es eine gewisse Fehlerkennungsrate und Schwierigkeiten beim Löschen gibt.

Machen wir zuerst ein Bild

Die Hauptidee des Bloom-Filteralgorithmus besteht darin, n Hash-Funktionen zu verwenden, um verschiedene Hash-Werte zu hashen und diese auf Different abzubilden Indexpositionen des Arrays (die Länge dieses Arrays kann sehr lang sein) und dann den Wert des entsprechenden Indexbits auf 1 setzen.
Um festzustellen, ob das Element in der Menge vorkommt, müssen k verschiedene Hash-Funktionen verwendet werden, um den Hash-Wert zu berechnen und zu prüfen, ob der Wert an der entsprechenden Indexposition des Hash-Werts 1 ist. Wenn einer nicht 1 ist, bedeutet dies, dass der Element Existiert nicht in der Sammlung.
Aber es ist auch möglich zu beurteilen, dass das Element in der Menge ist, das Element jedoch nicht. Die Einsen über allen Indexpositionen dieses Elements werden von anderen Elementen festgelegt, was zu einer gewissen Wahrscheinlichkeit einer Fehleinschätzung führt (aus diesem Grund). (Das Obige ist in einem Satz möglich.) Die Hauptursache ist, dass es einen bestimmten Hash-Konflikt geben wird.
Hinweis: Je niedriger die Falsch-Positiv-Rate, desto geringer ist die entsprechende Leistung.
Der Bloom-Filter kann verwendet werden, um festzustellen, ob sich ein Element (möglicherweise) in einer Menge befindet. Im Vergleich zu anderen Datenstrukturen weist der Bloom-Filter enorme Platz- und Zeitbeschränkungen auf.
Achten Sie auf das Wort oben: vielleicht. Hier bleibt eine Spannung erhalten, die im Folgenden im Detail analysiert wird.
Bestimmen Sie, ob die angegebenen Daten vorhanden sind
Verhindern Sie das Eindringen in den Cache (bestimmen Sie, ob die angeforderten Daten gültig sind, um zu vermeiden, dass der Cache direkt umgangen wird, um die Datenbank anzufordern) usw., Spam-Filterung von Postfächern, Blacklist-Funktionen usw.
Nachdem wir die Algorithmusidee des Bloom-Filters gelesen haben, beginnen wir mit der Erläuterung der spezifischen Implementierung.
Lassen Sie mich zunächst ein Beispiel geben. Angenommen, es gibt zwei Zeichenfolgen, Wangcai und Xiaoqiang. Sie wurden jeweils dreimal gehasht, und dann wird der Wert der Indexposition des entsprechenden Arrays festgelegt (vorausgesetzt, die Array-Länge beträgt 16). Wenn das Hash-Ergebnis 1 ist, schauen wir uns zunächst den Ausdruck wohlhabender Reichtum an:
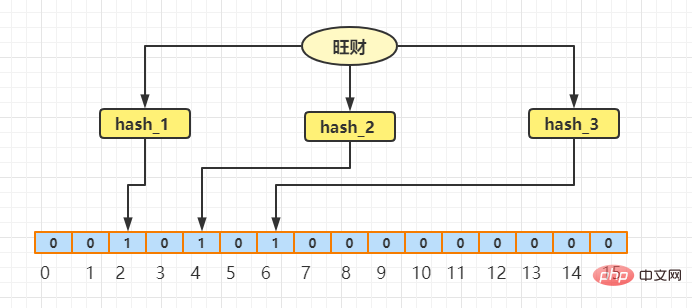
Wohlhabender Reichtum. Nach dreimaligem Hashing sind die Werte 2, 4 und 6. Dann können wir die Indexwerte erhalten 2, 4 und 6 sein, also werden wir den Wert des Index (2, 4, 6) des Arrays auf 1 setzen und der Rest wird als 0 behandelt. Nehmen wir nun an, dass Sie finden müssen Wangcai. Nach den gleichen drei Hashes finden Sie die Werte der Positionen, die den Indizes 2, 4 und 6 entsprechen. Wenn beide 1 sind, kann davon ausgegangen werden, dass möglicherweise Reichtum vorhanden ist.
Dann fügen Sie Xiaoqiang in den Bloom-Filter ein. Der eigentliche Vorgang ist der gleiche wie oben. Nehmen Sie an, dass die erhaltenen Indizes 1, 3, 5 sind Im Bloom-Filter sieht das tatsächliche Array mit Wangcai und Xiaoqiang wie folgt aus:
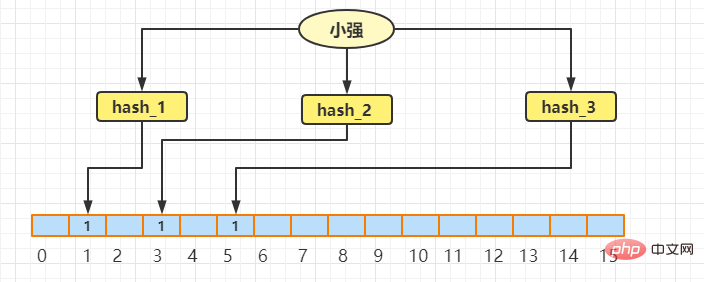
Jetzt gibt es Daten: 9527. Die aktuelle Anforderung besteht darin, festzustellen, ob 9527 nach drei Hashes erhalten wird sind: 5, 6, 7. Es stellt sich heraus, dass der Wert der Position mit dem Index 7 0 ist, sodass eindeutig beurteilt werden kann, dass 9527 nicht existieren darf.
Dann kam ein weiterer inländischer 007. Nach drei Hashes waren die erhaltenen Indizes: 2, 3, 5. Es wurde festgestellt, dass die Werte, die den Indizes 2, 3 und 5 entsprachen, alle 1 waren, sodass wir grob beurteilen können dass inländische 007 existieren könnte. Tatsächlich existiert 007 nach unserer Demonstration überhaupt nicht. Der Grund, warum die Werte der Indexpositionen 2, 3 und 5 1 sind, liegt in anderen Dateneinstellungen. 
<!--布隆过滤依赖-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class BloomFilterDemo {
public static void main(String[] args) {
/**
* 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器
* 不存在一定不存在
* 存在不一定存在
* ----------------
* Funnel 对象:预估的元素个数,误判率
* mightContain :方法判断元素是否存在
*/
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("死");
bloomFilter.put("磕");
bloomFilter.put("Redis");
System.out.println(bloomFilter.mightContain("Redis"));
System.out.println(bloomFilter.mightContain("Java"));
}
}的原理是这样子的:将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
其代码如下:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return value;
}Das obige ist der detaillierte Inhalt vonSo ermitteln Sie schnell, ob sich ein Element in einer Sammlung in Java befindet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



