
 Technologie-Peripheriegeräte
KI
Neue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern
Technologie-Peripheriegeräte
KI
Neue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern
Neue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern

Derzeit sind Transformer zu einer leistungsstarken neuronalen Netzwerkarchitektur für die Sequenzmodellierung geworden. Eine bemerkenswerte Eigenschaft vortrainierter Transformatoren ist ihre Fähigkeit, sich durch Cue-Konditionierung oder kontextbezogenes Lernen an nachgelagerte Aufgaben anzupassen. Nach einem Vortraining an großen Offline-Datensätzen hat sich gezeigt, dass große Transformatoren eine effiziente Verallgemeinerung auf nachgelagerte Aufgaben bei der Textvervollständigung, dem Sprachverständnis und der Bilderzeugung ermöglichen.
Neuere Arbeiten haben gezeigt, dass Transformatoren auch Richtlinien aus Offline-Daten lernen können, indem sie Offline-Reinforcement Learning (RL) als sequentielles Vorhersageproblem behandeln. Arbeiten von Chen et al. (2021) zeigten, dass Transformer durch Nachahmungslernen Einzeltask-Richtlinien aus Offline-RL-Daten lernen können, und nachfolgende Arbeiten zeigten, dass Transformer sowohl in derselben Domäne als auch in domänenübergreifenden Umgebungen Richtlinien für mehrere Aufgaben extrahieren können. Diese Arbeiten zeigen alle ein Paradigma für die Extraktion allgemeiner Multitasking-Richtlinien, d. h. zunächst das Sammeln großer und vielfältiger Datensätze zu Umweltinteraktionen und das anschließende Extrahieren von Richtlinien aus den Daten durch sequentielle Modellierung. Diese Methode zum Erlernen von Richtlinien aus Offline-RL-Daten durch Nachahmungslernen wird als Offline-Richtliniendestillation (Offline Policy Distillation) oder Richtliniendestillation (Policy Distillation, PD) bezeichnet.
PD bietet Einfachheit und Skalierbarkeit, aber einer seiner großen Nachteile besteht darin, dass sich die generierten Richtlinien durch zusätzliche Interaktionen mit der Umgebung nicht schrittweise verbessern. Beispielsweise lernte Googles Generalist-Agent Multi-Game Decision Transformers eine rückgabebedingte Richtlinie, mit der viele Atari-Spiele gespielt werden können, während DeepMinds Generalist-Agent Gato eine Lösung für verschiedene Probleme durch kontextbezogene Aufgabenbegründungsstrategien für Aufgaben in der Umgebung erlernte. Leider kann keiner der Agenten die Richtlinie im Kontext durch Versuch und Irrtum verbessern. Daher lernt die PD-Methode eher Richtlinien als verstärkende Lernalgorithmen.
In einem aktuellen DeepMind-Artikel stellten Forscher die Hypothese auf, dass der Grund dafür, dass sich PD durch Versuch und Irrtum nicht verbesserte, darin lag, dass die für das Training verwendeten Daten keinen Lernfortschritt anzeigen konnten. Aktuelle Methoden lernen entweder eine Richtlinie aus Daten, die kein Lernen enthalten (z. B. feste Expertenrichtlinie über Destillation) oder lernen eine Richtlinie aus Daten, die zwar Lernen enthalten (z. B. der Wiedergabepuffer eines RL-Agenten), aber die Kontextgröße des letzteren ( zu klein) Fehler bei der Erfassung politischer Verbesserungen.

Papieradresse: https://arxiv.org/pdf/2210.14215.pdf#🎜 Die wichtigste Beobachtung der Forscher ist, dass die sequentielle Natur des Lernens beim Training von RL-Algorithmen im Prinzip das verstärkende Lernen selbst als ein Problem der kausalen Sequenzvorhersage modellieren kann. Insbesondere wenn der Kontext eines Transformators lang genug ist, um die durch Lernaktualisierungen hervorgerufenen Richtlinienverbesserungen einzubeziehen, sollte er nicht nur in der Lage sein, eine feste Richtlinie darzustellen, sondern auch in der Lage sein, einen Richtlinienverbesserungsalgorithmus darzustellen, indem er sich auf die Zustände konzentriert , Aktionen und Belohnungen früherer Episoden, Sohn.
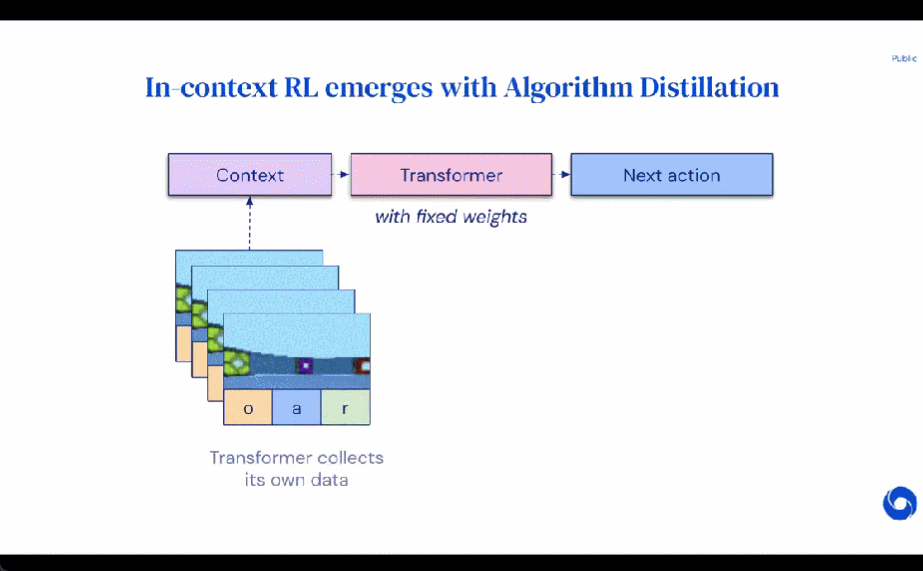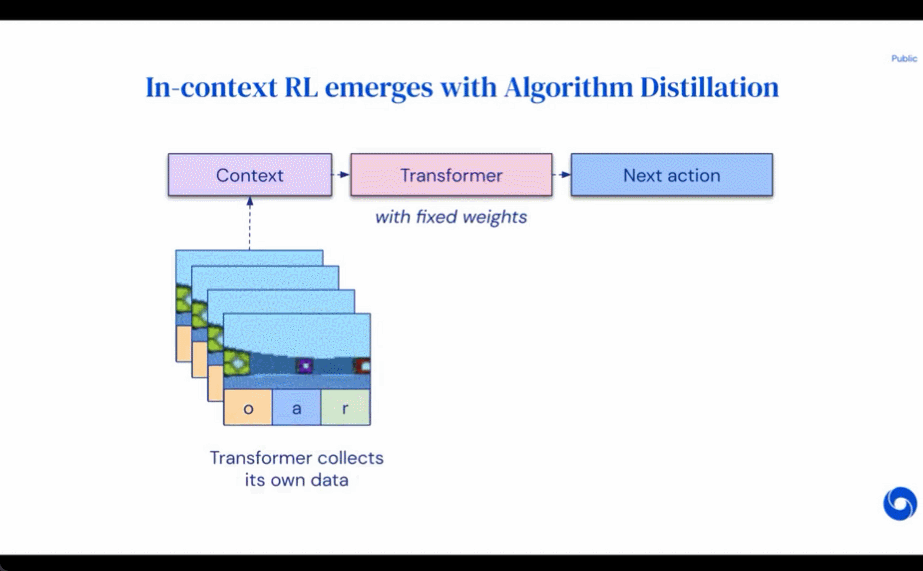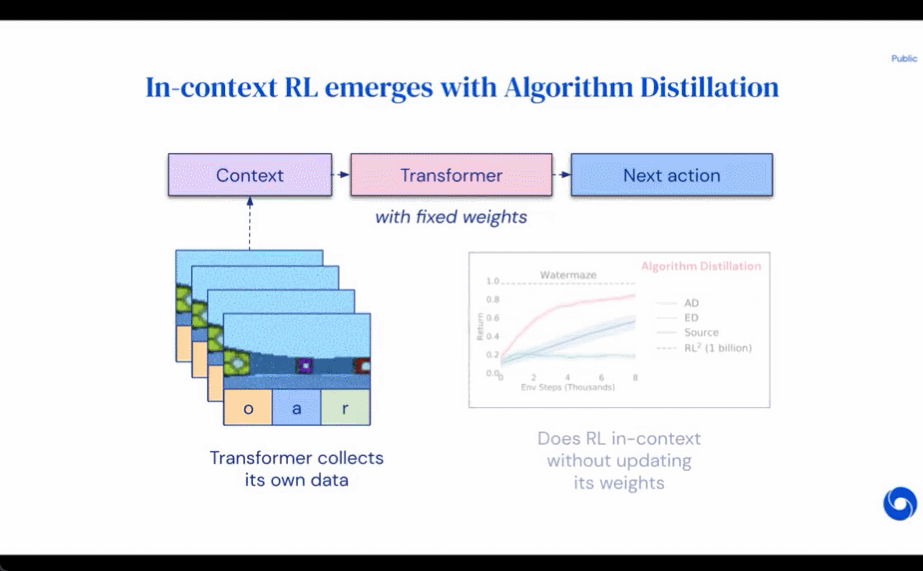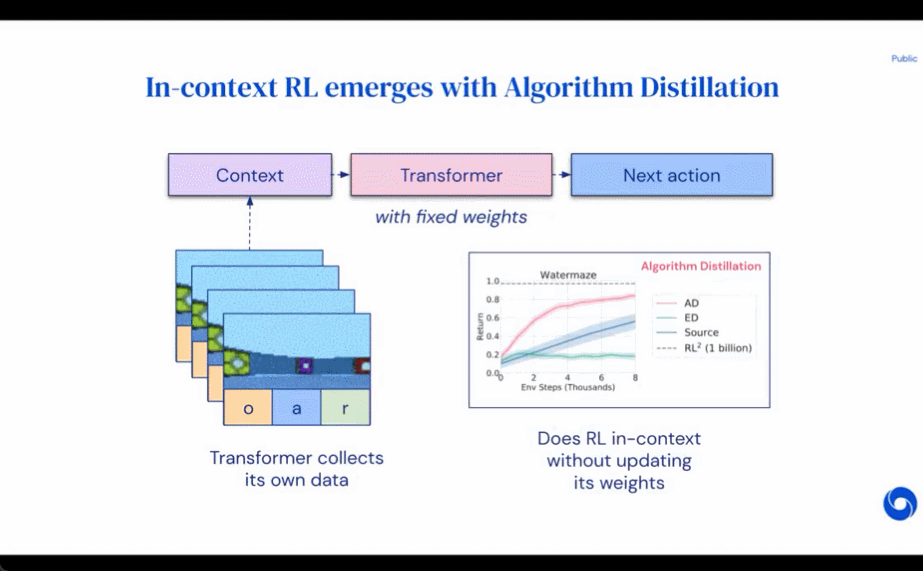
Dies eröffnet die Möglichkeit, dass jeder RL-Algorithmus durch Nachahmungslernen in ausreichend leistungsstarke Sequenzmodelle wie Transformatoren destilliert werden kann und diese Modelle in kontextbezogene RL-Algorithmen umgewandelt werden können.Der Forscher schlug die Algorithmusdestillation (AD) vor, eine Methode zum Lernen durch Optimierung des kausalen Sequenzvorhersageverlusts im Lernverlauf des RL-Algorithmus kontextbezogene Richtlinienverbesserungsoperatoren. Wie in Abbildung 1 unten dargestellt, besteht AD aus zwei Teilen. Ein großer Multitask-Datensatz wird zunächst generiert, indem der Trainingsverlauf eines RL-Algorithmus für eine große Anzahl einzelner Aufgaben gespeichert wird. Anschließend modelliert das Transformatormodell Aktionen kausal, indem es den vorherigen Lernverlauf als Kontext verwendet. Da sich die Richtlinie während des Trainings des Quell-RL-Algorithmus weiter verbessert, muss AD verbesserte Operatoren erlernen, um die Aktionen an jedem beliebigen Punkt im Trainingsverlauf genau zu modellieren. Entscheidend ist, dass der Transformatorkontext groß genug (d. h. episodisch) sein muss, um Verbesserungen in den Trainingsdaten zu erfassen.
Die Forscher gaben an, dass durch die Verwendung eines Kausaltransformators mit einem ausreichend großen Kontext der Gradienten-basierte RL-Algorithmus nachgeahmt werden könne , AD ist völlig neues Aufgabenlernen und kann im Kontext verstärkt werden. Wir haben AD in einer Reihe teilweise beobachtbarer Umgebungen untersucht, die erkundet werden müssen, darunter das pixelbasierte Watermaze von DMLab, und gezeigt, dass AD zur Kontexterkundung, zeitlichen Konfidenzzuweisung und Verallgemeinerung fähig ist. Darüber hinaus ist der von AD erlernte Algorithmus effizienter als der Algorithmus, der die Quelldaten des Transformatortrainings generiert hat.
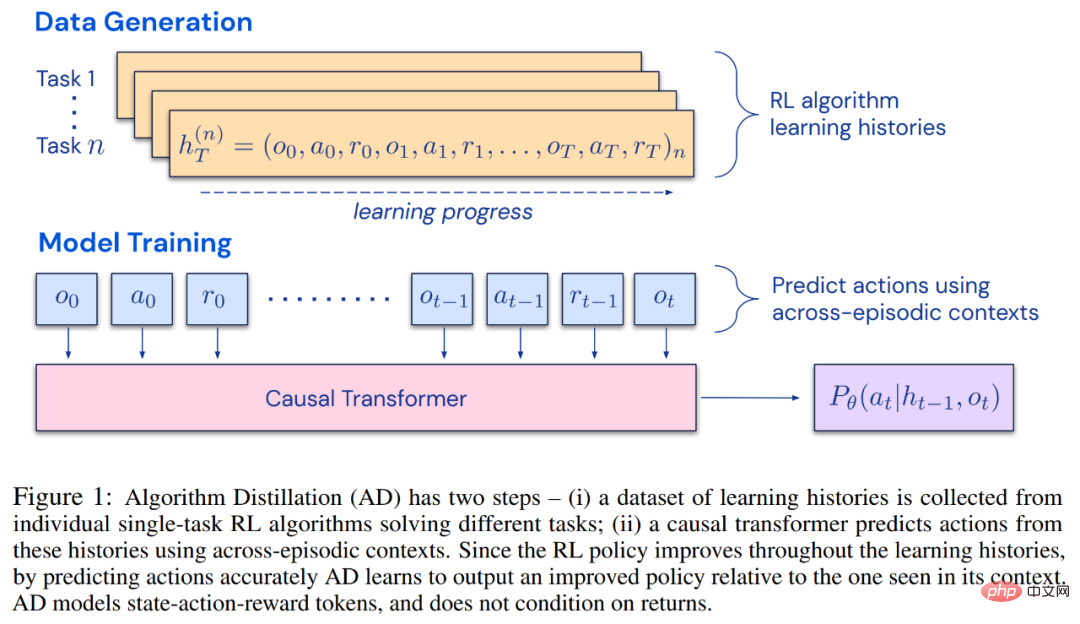
Abschließend ist es erwähnenswert, dass AD die erste Methode ist, um kontextuelles Verstärkungslernen durch sequentielle Modellierung von Offline-Daten mit Imitationsverlust zu demonstrieren. #? gute Leistung bei der Ausführung komplexer Bewegungen. Für einen intelligenten Agenten kann er unabhängig von seiner Umgebung, internen Struktur und Ausführung auf der Grundlage vergangener Erfahrungen als abgeschlossen angesehen werden. Es kann in der folgenden Form ausgedrückt werden:
Forscher betrachten die „lange geschichtsbedingte“ Strategie auch als An Algorithmus, der Folgendes ergibt:
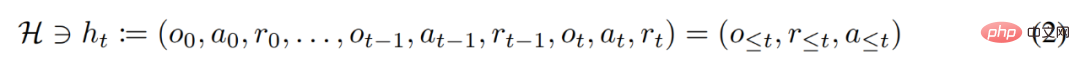 wobei Δ(A) den Wahrscheinlichkeitsverteilungsraum auf dem Aktionsraum A darstellt. Gleichung (3) zeigt, dass der Algorithmus in der Umgebung entfaltet werden kann, um Sequenzen von Beobachtungen, Belohnungen und Aktionen zu generieren. Der Einfachheit halber stellt diese Studie den Algorithmus als P und die Umgebung (d. h. Aufgabe) als
wobei Δ(A) den Wahrscheinlichkeitsverteilungsraum auf dem Aktionsraum A darstellt. Gleichung (3) zeigt, dass der Algorithmus in der Umgebung entfaltet werden kann, um Sequenzen von Beobachtungen, Belohnungen und Aktionen zu generieren. Der Einfachheit halber stellt diese Studie den Algorithmus als P und die Umgebung (d. h. Aufgabe) als
dar. Die Lernhistorie wird durch den Algorithmus dargestellt, sodass für jede gegebene Aufgabe
 Generiert. Sie können
Generiert. Sie können
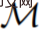
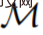 erhalten. Forscher verwenden lateinische Großbuchstaben, um Zufallsvariablen wie O, A, R und ihre darzustellen entsprechende Kleinbuchstabenformen o, α, r. Indem sie Algorithmen als langfristige, geschichtsbedingte Richtlinien betrachteten, stellten sie die Hypothese auf, dass jeder Algorithmus, der eine Lernhistorie generiert, durch Verhaltensklonen von Aktionen in ein neuronales Netzwerk umgewandelt werden kann. Als nächstes schlägt die Studie einen Ansatz vor, der Agenten das lebenslange Lernen von Sequenzmodellen mit Verhaltensklonen ermöglicht, um den Langzeitverlauf auf Aktionsverteilungen abzubilden.
erhalten. Forscher verwenden lateinische Großbuchstaben, um Zufallsvariablen wie O, A, R und ihre darzustellen entsprechende Kleinbuchstabenformen o, α, r. Indem sie Algorithmen als langfristige, geschichtsbedingte Richtlinien betrachteten, stellten sie die Hypothese auf, dass jeder Algorithmus, der eine Lernhistorie generiert, durch Verhaltensklonen von Aktionen in ein neuronales Netzwerk umgewandelt werden kann. Als nächstes schlägt die Studie einen Ansatz vor, der Agenten das lebenslange Lernen von Sequenzmodellen mit Verhaltensklonen ermöglicht, um den Langzeitverlauf auf Aktionsverteilungen abzubilden.  Tatsächliche Ausführung
Tatsächliche Ausführung
In der Praxis implementiert diese Forschung den Algorithmusdestillationsprozess (Algorithmusdestillation, AD) als zweistufigen Prozess. Zunächst wird ein Lernverlaufsdatensatz erfasst, indem einzelne, auf Gradienten basierende RL-Algorithmen für viele verschiedene Aufgaben ausgeführt werden. Als nächstes wird ein Sequenzmodell mit Kontext aus mehreren Episoden trainiert, um Aktionen im Verlauf vorherzusagen. Der spezifische Algorithmus lautet wie folgt: 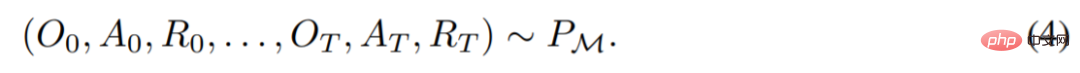
Experiment
Die für das Experiment erforderliche Umgebung Es unterstützt viele Aufgaben, die nicht einfach aus Beobachtungen abgeleitet werden können, und die Episoden sind kurz genug, um episodenübergreifende kausale Transformatoren effizient zu trainieren. Das Hauptziel dieser Arbeit bestand darin, zu untersuchen, inwieweit AD-Verstärkung im Vergleich zu früheren Arbeiten im Kontext gelernt wird. Das Experiment verglich AD, ED (Expert Distillation), RL^2 usw.
Die Ergebnisse der Auswertung von AD, ED und RL^2 sind in Abbildung 3 dargestellt. Die Studie ergab, dass sowohl AD als auch RL^2 kontextbezogen anhand von Aufgaben aus der Trainingsverteilung lernen können, während ED dies nicht kann, obwohl ED bei der Auswertung innerhalb einer Verteilung besser abschneidet als zufälliges Raten. 
Bezüglich Abbildung 4 unten beantwortete der Forscher eine Reihe von Fragen. Zeigt AD kontextuelles Verstärkungslernen? Die Ergebnisse zeigen, dass AD kontextuelles Verstärkungslernen in allen Umgebungen lernen kann, ED dagegen in den meisten Situationen nicht im Kontext erforschen und lernen kann. Kann AD aus pixelbasierten Beobachtungen lernen? Die Ergebnisse zeigen, dass AD die episodische Regression durch kontextuelles RL maximiert, während ED nicht lernt.
AD Ist es möglich, einen RL-Algorithmus zu lernen, der effizienter ist als der Algorithmus, der die Quelldaten generiert hat? Die Ergebnisse zeigen, dass die Dateneffizienz von AD deutlich höher ist als die der Quellalgorithmen (A3C und DQN). Ist es möglich, AD mit einer Demo zu beschleunigen? Um diese Frage zu beantworten, behält diese Studie die Stichprobenstrategie an verschiedenen Punkten im Verlauf des Quellalgorithmus in den Testsatzdaten bei, verwendet dann diese Strategiedaten, um den Kontext von AD und ED vorab zu füllen, und führt beide Methoden im aus Kontext von Dark Room. Die Ergebnisse sind in Abbildung 5 dargestellt. Während ED die Leistung der Eingaberichtlinien beibehält, verbessert AD jede Richtlinie im Kontext, bis sie nahezu optimal ist. Wichtig ist: Je optimierter die Eingabestrategie ist, desto schneller verbessert AD sie, bis sie das Optimum erreicht.
Weitere Einzelheiten finden Sie im Originalpapier. 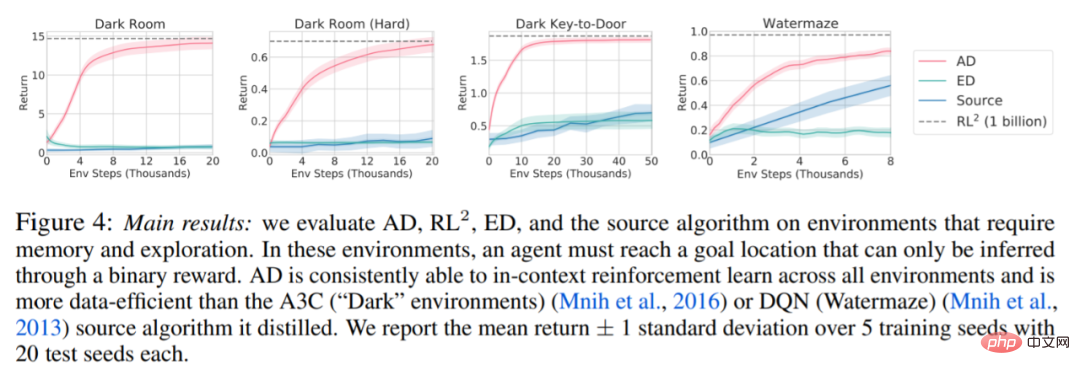
Das obige ist der detaillierte Inhalt vonNeue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
