
 Technologie-Peripheriegeräte
KI
Ein 20-jähriger IT-Veteran erklärt, wie man ChatGPT zum Aufbau von Domänenwissen nutzt
Technologie-Peripheriegeräte
KI
Ein 20-jähriger IT-Veteran erklärt, wie man ChatGPT zum Aufbau von Domänenwissen nutzt
Ein 20-jähriger IT-Veteran erklärt, wie man ChatGPT zum Aufbau von Domänenwissen nutzt

Autor |. Cui Hao
Rezensent | Die Veröffentlichung von ChatGPT 4.0 ist ein revolutionäres Technologie-Upgrade und schockiert alle KI-Industrie. Jetzt können Computer nicht nur alltägliche Fragen in natürlicher Sprache erkennen und beantworten, ChatGPT kann durch die Modellierung von Branchendaten auch genauere Lösungen bereitstellen. Dieser Artikel vermittelt Ihnen ein detailliertes Verständnis der Architekturprinzipien und seiner
Entwicklungsaussichten. Außerdem wird erläutert, wie Sie die ChatGPT-API zum Trainieren von Branchendaten verwenden. Lassen Sie uns gemeinsam dieses neue und vielversprechende Feld erkunden und eine neue Ära der KI einläuten.Veröffentlichung von ChatGPT 4.0ChatGPT 4.0 wurde offiziell veröffentlicht! Diese Version von ChatGPT bietet im Vergleich zur vorherigen ChatGPT 3.5 eine enorme Verbesserung der Modellleistung und -geschwindigkeit.
Vor der Veröffentlichung von ChatGPT 4.0 hatten viele Menschen auf ChatGPT aufmerksam gemacht und seine Bedeutung im Bereich der Verarbeitung natürlicher Sprache erkannt. Allerdings bestehen in 3.5und früheren -Versionen immer noch Einschränkungen von ChatGPT, da sich seine Trainingsdaten hauptsächlich auf Sprachmodelle in allgemeinen Bereichen konzentrieren, was es schwierig macht, Inhalte zu generieren, die sich auf bestimmte Branchen beziehen. Mit der Veröffentlichung von ChatGPT 4.0 begannen jedoch immer mehr Menschen, es zum Trainieren ihrer eigenen Branchendaten zu verwenden, und es wurde in verschiedenen Branchen häufig eingesetzt. Dies bringt immer mehr Menschen dazu, auf ChatGPT aufmerksam zu machen. Als nächstes werde ich Ihnen die Architekturprinzipien, Entwicklungsperspektiven und die Anwendung von ChatGPT in Daten der Schulungsbranche vorstellen. Funktionen von ChatGPTChatGPTDie Architektur basiert auf einem Deep-Learning-Neuronalen Netzwerk, einer Technologie zur Verarbeitung natürlicher Sprache. Ihr Prinzip besteht darin, vorab trainierte Inhalte zu verwenden Groß angelegte Sprachmodelle. Um Text zu generieren, damit Maschinen natürliche Sprache verstehen und generieren können. Das Modellprinzip von ChatGPT basiert auf dem Transformer-Netzwerk, das mithilfe unbeaufsichtigter Sprachmodellierungstechnologie trainiert wird, um die Wahrscheinlichkeitsverteilung des nächsten Wortes vorherzusagen und fortlaufenden Text zu generieren. Zu den verwendeten Parametern gehören die Anzahl der Schichten des Netzwerks, die Anzahl der Neuronen in jeder Schicht, die Ausfallwahrscheinlichkeit, die Stapelgröße usw. Der Lernumfang umfasst allgemeine Sprachmodelle und domänenspezifische Sprachmodelle. Mit domänenallgemeinen Modellen können vielfältige Texte generiert werden, während domänenspezifische Modelle für spezifische Aufgaben fein abgestimmt und optimiert werden können.
OpenAI verwendet umfangreiche Textdaten als Trainingsdaten für GPT-3. Konkret nutzten sie mehr als 45 TB englische Textdaten und einige andere Sprachdaten, darunter Webtext, E-Books, Enzyklopädien, Wikipedia, Foren, Blogs usw. Sie verwendeten auch einige sehr große Datensätze wie Common Crawl, WebText, BooksCorpus usw. Diese Datensätze enthalten Billionen Wörter und Milliarden verschiedener Sätze und liefern sehr umfangreiche Informationen für das Modelltraining.
Da man so viele Inhalte lernen muss, ist auch die eingesetzte Rechenleistung beträchtlich. ChatGPT verbraucht viel Rechenleistung und erfordert viele GPU-Ressourcen für das Training. Laut einem technischen Bericht von OpenAI aus dem Jahr 2020 verbrauchte GPT-3 während des Trainings etwa 17,5 Milliarden Parameter und 28.500 TPU v3-Prozessoren.
Was ist die Anwendung von ChatGPT im beruflichen Bereich?
Aus der obigen Einführung wissen wir, dass ChatGPT über leistungsstarke Funktionen verfügt, aber auch einen enormen Rechen- und Ressourcenverbrauch, Schulung dies erfordert Große Sprachmodelle sind mit hohen Kosten verbunden. Aber das zu einem so hohen Preis hergestellte AIGC-Tool hat seine Einschränkungen , Fachwissen Felder. Habe mich nicht eingemischt. Wenn es beispielsweise um Berufsfelder wie Medizin oder Recht geht, ist ChatGPT nicht in der Lage, genaue Antworten zu generieren. Dies liegt daran, dass die Lerndaten von ChatGPT aus dem allgemeinen Korpus im Internet stammen und diese Daten keine Fachbegriffe und Kenntnisse in bestimmten spezifischen Bereichen enthalten. Damit ChatGPT in bestimmten Berufsfeldern eine bessere Leistung erzielen kann, ist es daher notwendig, professionelle Korpora in diesem Bereich für die Ausbildung zu nutzen, d. h. das Wissen von Experten in diesem Bereich Das Berufsfeld wird vermittelt. Gib „ChatGPT zum Lernen“. ChatGPT hat uns jedoch nicht enttäuscht. Wenn Sie ChatGPT auf eine bestimmte Branche anwenden, müssen Sie zunächst die Berufsdaten der Branche extrahieren und eine Vorverarbeitung durchführen. Insbesondere müssen eine Reihe von Prozessen wie Bereinigung, Deduplizierung, Segmentierung und Kennzeichnung von Daten durchgeführt werden. Anschließend werden die verarbeiteten Daten formatiert und in ein Datenformat konvertiert, das den Eingabeanforderungen des ChatGPT-Modells entspricht. Anschließend können Sie die API-Schnittstelle von ChatGPT verwenden, um die verarbeiteten Daten zum Training in das Modell einzugeben. Zeit und Kosten des Trainings hängen von der Datenmenge und der Rechenleistung ab. Nach Abschluss des Trainings kann das Modell auf tatsächliche Szenarien angewendet werden, um Benutzerfragen zu beantworten.
Verwenden Sie ChatGPT, um professionelles Domänenwissen zu trainieren! Tatsächlich ist es nicht schwierig, eine Wissensbasis im professionellen Bereich aufzubauen ,
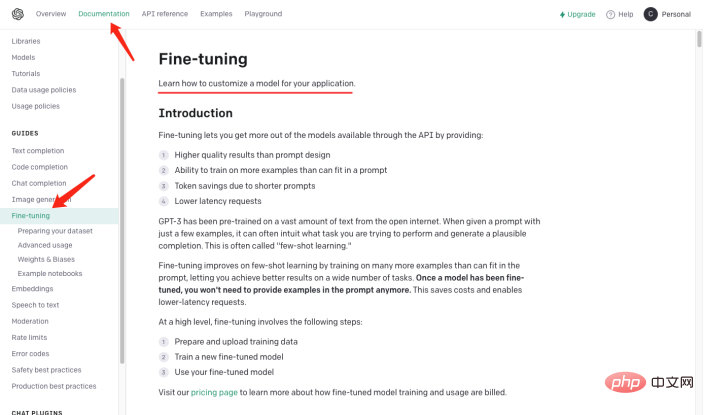
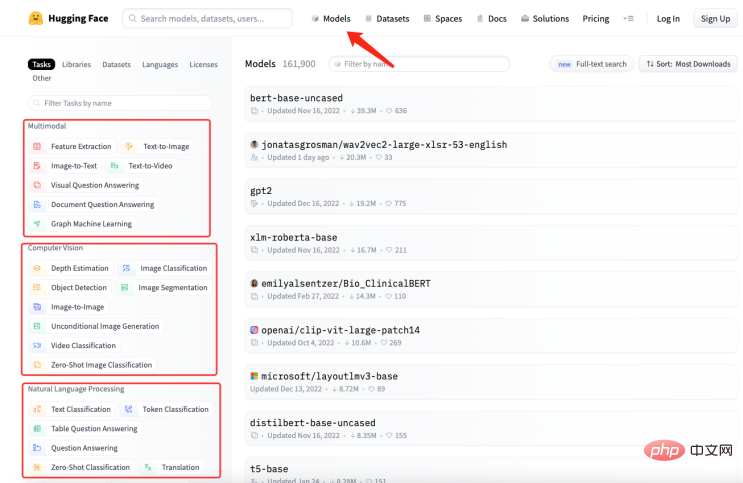
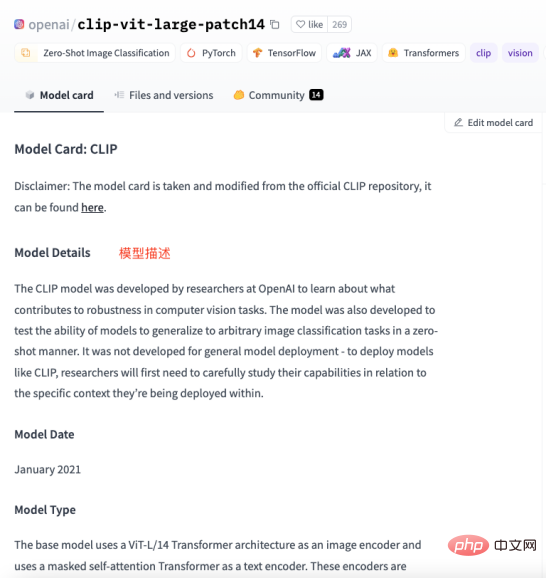
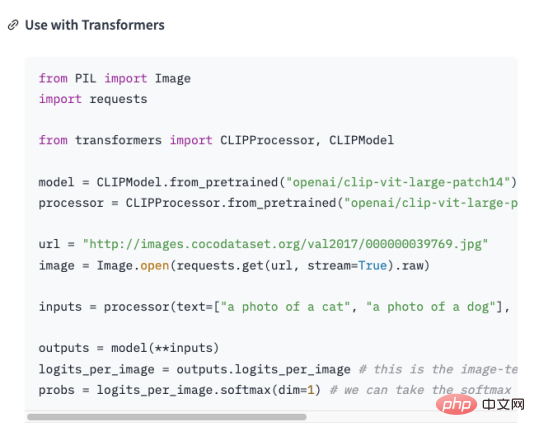
und dann Das Frage- und Antwortformat wird mithilfe der Natural Language Processing (NLP)-Technologie modelliert, um die Frage zu beantworten. Mit der GPT-3-API von OpenAI (am Beispiel von GPT3 ) können Sie ein Frage- und Antwortmodell erstellen. Geben Sie einfach einige Beispiele an, und schon wird es funktionieren Arbeiten Sie basierend auf den von Ihnen gestellten Fragen und generieren Sie Antworten. Die groben Schritte zum Erstellen eines Frage- und Antwortmodells mithilfe der GPT-3-API sind wie folgt: Da nicht der Schwerpunkt dieses Artikels ist, werde ich hier nicht näher darauf eingehen. Erstellen eines DatensatzesAusgehend von den oben genannten Schritten ist die Konvertierung von Schritt 2 in das Frage- und Antwortformat eine Herausforderung für uns. Vorausgesetzt gibt es Domänenwissen über die Geschichte der künstlichen Intelligenz , das gelehrt werden muss. GPT , und nutzen Sie dieses Wissen in Modelle, die relevante Fragen beantworten. Dann muss es in folgende Form umgewandelt werden: Frage: Was ist die Geschichte der künstlichen Intelligenz? Antwort: Künstliche Intelligenz entstand in den 1950er Jahren als ein Zweig der Informatik, der sich mit der Erforschung der Frage beschäftigte, wie Computer in die Lage versetzt werden können, wie Menschen zu denken und zu handeln. #🎜 🎜 # Tatsächlich habe ich „nn“, nach der Frage und „n“ hinzugefügt . “ . Bei der Lösung des Problems mit dem Frage- und Antwortformat stellt sich wieder eine neue Frage: Wie organisieren wir das Branchenwissen in einer Frage und Antwort? Format ? In den meisten Fällen crawlen wir viel Domänenwissen aus dem Internet oder finden viele Domänendokumente. Egal was der Fall ist, die Eingabe von Dokumenten ist für uns am bequemsten. Es ist jedoch offensichtlich unrealistisch, reguläre Ausdrücke oder manuelle Methoden zu verwenden, um eine große Textmenge in ein Frage-Antwort-Format zu verarbeiten. Daher ist es notwendig, eine Technologie namens automatische Zusammenfassung (Automatic Summarization) einzuführen, die wichtige Informationen aus einem Artikel extrahieren und eine kurze Zusammenfassung erstellen kann. Es gibt zwei Arten der automatischen Zusammenfassung: extraktive automatische Zusammenfassung und generative automatische Zusammenfassung. Die extraktive automatische Zusammenfassung extrahiert die repräsentativsten Sätze aus dem Originaltext, um eine Zusammenfassung zu erstellen, während die generative automatische Zusammenfassung durch Modelllernen wichtige Informationen aus dem Originaltext extrahiert und auf der Grundlage dieser Informationen eine Zusammenfassung generiert. Tatsächlich besteht die automatische Zusammenfassung darin, aus dem Eingabetext einen Frage- und Antwortmodus zu generieren. Nachdem das Problem geklärt ist, verwenden wir NLTK, die Abkürzung für Natural Language Toolkit dem Bereich der Verarbeitung natürlicher Sprache. Es umfasst verschiedene Tools und Bibliotheken zur Verarbeitung natürlicher Sprache, wie z. B. Textvorverarbeitung, Wortart-Tagging, Erkennung benannter Entitäten, Syntaxanalyse, Stimmungsanalyse usw. Wir müssen den Text nur an NLTK übergeben, das Datenvorverarbeitungsvorgänge für den Text durchführt, einschließlich der Entfernung von Stoppwörtern, der Wortsegmentierung, der Kennzeichnung von Wortarten usw. Nach der Vorverarbeitung kann das Textzusammenfassungsgenerierungsmodul in NLTK zum Generieren von Zusammenfassungen verwendet werden. Sie können verschiedene Algorithmen auswählen, z. B. basierend auf der Worthäufigkeit, basierend auf TF-IDF usw. Beim Generieren der Zusammenfassung kann die Fragenvorlage kombiniert werden, um eine Frage-und-Antwort-Zusammenfassung zu erstellen, wodurch die generierte Zusammenfassung lesbarer und verständlicher wird. Gleichzeitig kann die Zusammenfassung auch verfeinert werden, z. B. können nicht zusammenhängende Sätze, ungenaue Antworten usw. angepasst werden. Schauen Sie sich den Code unten an: aus Transformatoren importieren AutoTokenizer, AutoModelForSeq2SeqLM, Pipeline nltk#🎜🎜 # 🎜 # # Text eingeben #🎜 🎜# # 🎜 🎜 ## 🎜🎜##🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Partizip#🎜🎜 ## 🎜🎜 ## Wörter sexuelle Kennzeichnung #🎜 🎜 ## 🎜🎜#Syntaktische Analyse# 🎜 🎜 # Stimmungsanalyse# 🎜🎜 # #🎜 🎜## 🎜🏜 # #🎜 🎜# # 🎜 🎜# """ #🎜 🎜# #🎜 🎜 ## 🎜🎜#Sentences = nltk.sent_tokenize(text) 🎜 ## 🎜 🎜 #summary = " ".join(sentences[:2]) # Nimm die ersten beiden Sätze als Zusammenfassung # 🎜🎜 #print("summary:", summary) # Generierte Zusammenfassung verwenden ine- t#🎜🎜 #uning, hol dir das Modell 🎜🎜#tokenizer = AutoTokenizer.from_pretrained("t5-base")#🎜 🎜##🎜 🎜##🎜 🎜 #model =. AutoModelForSeq2SeqLM.from_pretrained("t5-base") #🎜🎜 # text = "zusammenfassen: " + Zusammenfassung # Eingabeformat erstellen #🎜 🎜##🎜 🎜#inputs = tokenizer(text, return_tensors="pt" , padding=True) #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ###🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # 🎜🎜# #🎜🎜 ## 🎜🎜 ## 🎜🎜#Modell. ## 🎜🎜# # Testmodell#🎜 🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#qa = pipeline („Frage-Antwort“, Modell=Modellname, Tokenizer=Modellname)#🎜 🎜# context = „Wofür wird NLTK verwendet?“ # Zu beantwortende Frage # 🎜🎜 ## 🎜🎜 ## 🎜🎜##🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##Antwort = qa (questInotal = context, cnotallow=text["input_ids"]) # 🎜🎜#print("Frage:", Kontext)#🎜🎜 ## 🎜🎜# print("Antwort:", Antwort["Antwort"])#🎜 🎜# # 🎜🎜##🎜 🎜 # Die Ausgabeergebnisse sind wie folgt: Zusammenfassung: Natural Language Toolkit (Natural Language Processing Toolkit, abgekürzt NLTK) ist eine Reihe von Python-Bibliotheken für Lösen von Problemen bei der Verarbeitung menschlicher Sprachdaten, wie z. B.: - Wortsegmentierung - Teil-of-Speech-Tagging Problem: NLTK Wofür wird es verwendet? Bausatz Der obige Code verwendet die Methode nltk.sent_tokenize, um die Zusammenfassung des Eingabetextes zu extrahieren, also die Frage und Antwort zu formatieren. Dann#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#,#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Anrufe#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #FDie AutoModelForSeq2SeqLM.from_pretrained-Methode vonine-tuning modelliert es, again#🎜 🎜# #🎜 🎜#Speichern Sie das Modell mit dem Namen „erstes Modell“. Rufen Sie abschließend das trainierte Modell auf, um die Ergebnisse zu testen. Das Obige geschieht nicht nur durch #🎜🎜 ##🎜 🎜#NLTK generiert eine Zusammenfassung der Frage und Antwort, Sie müssen auch #🎜 verwenden 🎜##🎜 🎜#F ine-t# 🎜🎜## 🎜🎜#uning-Funktionalität. Fein-tuning basiert auf dem vorab trainierten Modell, durch eine kleine Anzahl von beschriftet Die Daten passen das Modell genau an die spezifische Aufgabe an. Tatsächlich besteht darin, das Originalmodell zu verwenden, um Ihre Daten zu installieren, um Ihr Modell zu bilden Natürlich ist es auch möglich, die internen Ergebnisse des Modells anzupassen, z. B. Einstellungen und Parameter für verborgene Ebenen usw. Hier verwendet seine einfachste Funktion #🎜🎜 #, Erfahren Sie mehr über Fine- t unings Informationen. # 🎜🎜#Was erklärt werden muss, ist: AutoModelForSeq2SeqLM-Klasse, geladen aus dem vorab trainierten Modell „t5-base“T #🎜🎜 #okenizer und Modell. AutoTokenizer ist eine der Hugging Face Transformers-Bibliotheksklassen, der entsprechende Tokenizer kann automatisch erstellt werden basierend auf dem vorab trainierten Modell ausgewählt und geladen. T AutoModelForSeq2SeqLM ist auch eine Klasse in der Hugging Face Transformers-Bibliothek, die basierend auf dem vorab trainierten Modell automatisch das entsprechende Sequenz-zu-Sequenz-Modell auswählt und lädt. Hier wird ein Sequenz-zu-Sequenz-Modell basierend auf der T5-Architektur für Aufgaben wie die Generierung von Zusammenfassungen oder Übersetzungen verwendet. Nachdem Sie ein vorab trainiertes Modell geladen haben, können Sie dieses Modell zur Feinabstimmung von F oder zum Generieren einer aufgabenbezogenen Ausgabe verwenden. Wir haben oben den Modellierungscode erklärt, der die Fine-Tuning und Hugging Gesichtsteile beinhaltet, was verwirrend klingen kann. Hier ist ein Beispiel, das Ihnen das Verständnis erleichtert. Angenommen, dass Sie bereits über die Zutaten (Branchenkenntnisse) verfügen, aber nicht wissen, wie man es zubereitet. Also du fragst deinen Kochfreund, du sagst ihm, welche Zutaten du hast (Branchenkenntnisse) und welches Gericht du kochen möchtest (zu lösendes Problem), dein Freund orientiert sich an seiner Erfahrung und Wissen (allgemeines Modell) liefert Ihnen einige Vorschläge , dieser Prozess ist FFeinabstimmung ( Branchenwissen in eine universelle Form bringen Modell für die Ausbildung). Die Erfahrung und das Wissen Ihres Freundes ist ein vorab trainiertes Modell, Sie müssen das Branchenwissen und das zu lösende Problem eingeben und das Vormodell verwenden - Das trainierte Modell, , kann natürlich fein abgestimmt werden, beispielsweise hinsichtlich des Inhalts der Gewürze und der Hitze des Kochens. Der Zweck besteht darin, die Probleme Ihrer Branche zu lösen. Und Hugging Face ist ein Rezeptlager („t5-base“ im Code ist ein Rezept), das viele definierte Rezepte (Modelle) enthält, wie zum Beispiel: Geschnetzeltes Schweinefleisch mit Fischgeschmack , Wie man Kung-Pao-Hähnchen und gekochte Schweinefleischscheiben zubereitet. Diese vorgefertigten Rezepte können verwendet werden, um unsere Rezepte basierend auf den von uns bereitgestellten Zutaten und den Gerichten, die wir kochen müssen, zu erstellen. Wir müssen diese Rezepte nur anpassen und dann trainieren, und schon werden sie zu unseren eigenen Rezepten. Von nun an, können wir unsere eigenen Rezepte zum Kochen verwenden (Branchenprobleme lösen). Wie wähle ich ein Modell aus, das zu mir passt? Sie können in der Modellbibliothek von Hugging Face nach dem Modell suchen, das Sie benötigen. Wie in der Abbildung unten gezeigt, klicken Sie auf der offiziellen Website von Hugging Face auf „Modelle“, um die Klassifizierung der Modelle anzuzeigen. Sie können auch das Suchfeld verwenden, um nach Modellnamen zu suchen. Wie in der Abbildung unten dargestellt, bietet jede Modellseite relevante Informationen wie Modellbeschreibung, Anwendungsbeispiele, Download-Links zum Gewicht vor dem Training usw. Hier werden wir mit allen den Prozess der Sammlung, Transformation, Schulung und Nutzung des gesamten Branchenwissens durchlaufen. Wie in der folgenden Abbildung dargestellt: 
#
Was ist die Geschichte der künstlichen Intelligenz? nnKünstliche Intelligenz entstand in den 1950er Jahren und ist ein Zweig der Informatik, der sich mit der Erforschung befasst, wie Computer in die Lage versetzt werden können, wie Menschen zu denken und zu handeln. Die derzeit fortschrittlichste Technologie für künstliche Intelligenz ist Was? nnEine der fortschrittlichsten Technologien der künstlichen Intelligenz ist derzeit Deep Learning, ein auf neuronalen Netzwerken basierender Algorithmus, der auf großen Datenmengen trainieren und daraus Merkmale und Muster extrahieren kann.
Schnell ein Modell für das Frage- und Antwortformat generieren
Welche Beziehung besteht zwischen Feinabstimmung und Hugging Face?
Zusammenfassung
Das obige ist der detaillierte Inhalt vonEin 20-jähriger IT-Veteran erklärt, wie man ChatGPT zum Aufbau von Domänenwissen nutzt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
