
 Backend-Entwicklung
Python-Tutorial
Was ist das Prinzip der Python-Collection-Set-Implementierung?
Backend-Entwicklung
Python-Tutorial
Was ist das Prinzip der Python-Collection-Set-Implementierung?
Was ist das Prinzip der Python-Collection-Set-Implementierung?

深入理解 Python 虚拟机:集合(set)的实现原理及源码剖析
数据结构介绍
typedef struct {
PyObject_HEAD
Py_ssize_t fill; /* Number active and dummy entries*/
Py_ssize_t used; /* Number active entries */
/* The table contains mask + 1 slots, and that's a power of 2.
* We store the mask instead of the size because the mask is more
* frequently needed.
*/
Py_ssize_t mask;
/* The table points to a fixed-size smalltable for small tables
* or to additional malloc'ed memory for bigger tables.
* The table pointer is never NULL which saves us from repeated
* runtime null-tests.
*/
setentry *table;
Py_hash_t hash; /* Only used by frozenset objects */
Py_ssize_t finger; /* Search finger for pop() */
setentry smalltable[PySet_MINSIZE]; // #define PySet_MINSIZE 8
PyObject *weakreflist; /* List of weak references */
} PySetObject;
typedef struct {
PyObject *key;
Py_hash_t hash; /* Cached hash code of the key */
} setentry;
static PyObject _dummy_struct;
#define dummy (&_dummy_struct)上面的数据结果用图示如下图所示:
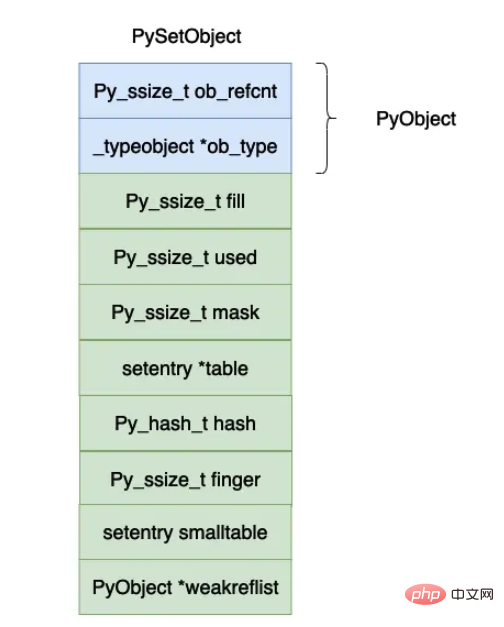
上面各个字段的含义如下所示:
dummy entries :如果在哈希表当中的数组原来有一个数据,如果我们删除这个 entry 的时候,对应的位置就会被赋值成 dummy,与 dummy 有关的定义在上面的代码当中已经给出,dummy 对象的哈希值等于 -1。
明白 dummy 的含义之后,fill 和 used 这两个字段的含义就比较容易理解了,used 就是数组当中真实有效的对象的个数,fill 还需要加上 dummy 对象的个数。
mask,数组的长度等于 2n2^n2n,mask 的值等于 2n−12^n - 12n−1 。
table,实际保存 entry 对象的数组。
hash,这个值对 frozenset 有用,保存计算出来的哈希值。如果你的数组很大的话,计算哈希值其实也是一个比较大的开销,因此可以将计算出来的哈希值保存下来,以便下一次求的时候可以将哈希值直接返回,这也印证了在 python 当中为什么只有 immutable 对象才能够放入到集合和字典当中,因为哈希值计算一次保存下来了,如果再加入对象对象的哈希值也会变化,这样做就会发生错误了。
finger,主要是用于记录下一个开始寻找被删除对象的下标。
smalltable,默认的小数组,cpython 设置的一半的集合对象不会超过这个大小(8),因此在申请一个集合对象的时候直接就申请了这个小数组的内存大小。
weakrelist,这个字段主要和垃圾回收有关,这里暂时不进行详细说明。
创建集合对象
首先先了解一下创建一个集合对象的过程,和前面其他的对象是一样的,首先先申请内存空间,然后进行相关的初始化操作。
这个函数有两个参数,使用第一个参数申请内存空间,然后后面一个参数如果不为 NULL 而且是一个可迭代对象的话,就将这里面的对象加入到集合当中。
static PyObject *
make_new_set(PyTypeObject *type, PyObject *iterable)
{
PySetObject *so = NULL;
/* create PySetObject structure */
so = (PySetObject *)type->tp_alloc(type, 0);
if (so == NULL)
return NULL;
// 集合当中目前没有任何对象,因此 fill 和 used 都是 0
so->fill = 0;
so->used = 0;
// 初始化哈希表当中的数组长度为 PySet_MINSIZE 因此 mask = PySet_MINSIZE - 1
so->mask = PySet_MINSIZE - 1;
// 让 table 指向存储 entry 的数组
so->table = so->smalltable;
// 将哈希值设置成 -1 表示还没有进行计算
so->hash = -1;
so->finger = 0;
so->weakreflist = NULL;
// 如果 iterable 不等于 NULL 则需要将它指向的对象当中所有的元素加入到集合当中
if (iterable != NULL) {
// 调用函数 set_update_internal 将对象 iterable 当中的元素加入到集合当中
if (set_update_internal(so, iterable)) {
Py_DECREF(so);
return NULL;
}
}
return (PyObject *)so;
}往集合当中加入数据
首先我们先大致理清楚往集合当中插入数据的流程:
首先根据对象的哈希值,计算需要将对象放在哪个位置,也就是对应数组的下标。
查看对应下标的位置是否存在对象,如果不存在对象则将数据保存在对应下标的位置。
如果对应的位置存在对象,则查看是否和当前要插入的对象相等,则返回。
如果不相等,则使用类似于线性探测的方式去寻找下一个要插入的位置(具体的实现可以查看相关代码,具体的操作为线性探测法 + 开放地址法)。
static PyObject *
set_add(PySetObject *so, PyObject *key)
{
if (set_add_key(so, key))
return NULL;
Py_RETURN_NONE;
}
static int
set_add_key(PySetObject *so, PyObject *key)
{
setentry entry;
Py_hash_t hash;
// 这里就查看一下是否是字符串,如果是字符串直接拿到哈希值
if (!PyUnicode_CheckExact(key) ||
(hash = ((PyASCIIObject *) key)->hash) == -1) {
// 如果不是字符串则需要调用对象自己的哈希函数求得对应的哈希值
hash = PyObject_Hash(key);
if (hash == -1)
return -1;
}
// 创建一个 entry 对象将这个对象加入到哈希表当中
entry.key = key;
entry.hash = hash;
return set_add_entry(so, &entry);
}
static int
set_add_entry(PySetObject *so, setentry *entry)
{
Py_ssize_t n_used;
PyObject *key = entry->key;
Py_hash_t hash = entry->hash;
assert(so->fill <= so->mask); /* at least one empty slot */
n_used = so->used;
Py_INCREF(key);
// 调用函数 set_insert_key 将对象插入到数组当中
if (set_insert_key(so, key, hash)) {
Py_DECREF(key);
return -1;
}
// 这里就是哈希表的核心的扩容机制
if (!(so->used > n_used && so->fill*3 >= (so->mask+1)*2))
return 0;
// 这是扩容大小的逻辑
return set_table_resize(so, so->used>50000 ? so->used*2 : so->used*4);
}
static int
set_insert_key(PySetObject *so, PyObject *key, Py_hash_t hash)
{
setentry *entry;
// set_lookkey 这个函数便是插入的核心的逻辑的实现对应的实现函数在下方
entry = set_lookkey(so, key, hash);
if (entry == NULL)
return -1;
if (entry->key == NULL) {
/* UNUSED */
entry->key = key;
entry->hash = hash;
so->fill++;
so->used++;
} else if (entry->key == dummy) {
/* DUMMY */
entry->key = key;
entry->hash = hash;
so->used++;
} else {
/* ACTIVE */
Py_DECREF(key);
}
return 0;
}
// 下面的代码就是在执行我们在前面所谈到的逻辑,直到找到相同的 key 或者空位置才退出 while 循环
static setentry *
set_lookkey(PySetObject *so, PyObject *key, Py_hash_t hash)
{
setentry *table = so->table;
setentry *freeslot = NULL;
setentry *entry;
size_t perturb = hash;
size_t mask = so->mask;
size_t i = (size_t)hash & mask; /* Unsigned for defined overflow behavior */
size_t j;
int cmp;
entry = &table[i];
if (entry->key == NULL)
return entry;
while (1) {
if (entry->hash == hash) {
PyObject *startkey = entry->key;
/* startkey cannot be a dummy because the dummy hash field is -1 */
assert(startkey != dummy);
if (startkey == key)
return entry;
if (PyUnicode_CheckExact(startkey)
&& PyUnicode_CheckExact(key)
&& unicode_eq(startkey, key))
return entry;
Py_INCREF(startkey);
// returning -1 for error, 0 for false, 1 for true
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0) /* unlikely */
return NULL;
if (table != so->table || entry->key != startkey) /* unlikely */
return set_lookkey(so, key, hash);
if (cmp > 0) /* likely */
return entry;
mask = so->mask; /* help avoid a register spill */
}
if (entry->hash == -1 && freeslot == NULL)
freeslot = entry;
if (i + LINEAR_PROBES <= mask) {
for (j = 0 ; j < LINEAR_PROBES ; j++) {
entry++;
if (entry->key == NULL)
goto found_null;
if (entry->hash == hash) {
PyObject *startkey = entry->key;
assert(startkey != dummy);
if (startkey == key)
return entry;
if (PyUnicode_CheckExact(startkey)
&& PyUnicode_CheckExact(key)
&& unicode_eq(startkey, key))
return entry;
Py_INCREF(startkey);
// returning -1 for error, 0 for false, 1 for true
cmp = PyObject_RichCompareBool(startkey, key, Py_EQ);
Py_DECREF(startkey);
if (cmp < 0)
return NULL;
if (table != so->table || entry->key != startkey)
return set_lookkey(so, key, hash);
if (cmp > 0)
return entry;
mask = so->mask;
}
if (entry->hash == -1 && freeslot == NULL)
freeslot = entry;
}
}
perturb >>= PERTURB_SHIFT; // #define PERTURB_SHIFT 5
i = (i * 5 + 1 + perturb) & mask;
entry = &table[i];
if (entry->key == NULL)
goto found_null;
}
found_null:
return freeslot == NULL ? entry : freeslot;
}哈希表数组扩容
在 cpython 当中对于给哈希表数组扩容的操作,很多情况下都是用下面这行代码,从下面的代码来看对应扩容后数组的大小并不简单,当你的哈希表当中的元素个数大于 50000 时,新数组的大小是原数组的两倍,而如果你哈希表当中的元素个数小于等于 50000,那么久扩大为原来长度的四倍,这个主要是怕后面如果继续扩大四倍的话,可能会浪费很多内存空间。
set_table_resize(so, so->used>50000 ? so->used*2 : so->used*4);
首先需要了解一下扩容机制,当哈希表需要扩容的时候,主要有以下两个步骤:
创建新的数组,用于存储哈希表的键。
遍历原来的哈希表,将原来哈希表当中的数据加入到新的申请的数组当中。
这里需要注意的是因为数组的长度发生了变化,但是 key 的哈希值却没有发生变化,因此在新的数组当中数据对应的下标位置也会发生变化,因此需重新将所有的对象重新进行一次插入操作,下面的整个操作相对来说比较简单,这里不再进行说明了。
static int
set_table_resize(PySetObject *so, Py_ssize_t minused)
{
Py_ssize_t newsize;
setentry *oldtable, *newtable, *entry;
Py_ssize_t oldfill = so->fill;
Py_ssize_t oldused = so->used;
int is_oldtable_malloced;
setentry small_copy[PySet_MINSIZE];
assert(minused >= 0);
/* Find the smallest table size > minused. */
/* XXX speed-up with intrinsics */
for (newsize = PySet_MINSIZE;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
/* Get space for a new table. */
oldtable = so->table;
assert(oldtable != NULL);
is_oldtable_malloced = oldtable != so->smalltable;
if (newsize == PySet_MINSIZE) {
/* A large table is shrinking, or we can't get any smaller. */
newtable = so->smalltable;
if (newtable == oldtable) {
if (so->fill == so->used) {
/* No dummies, so no point doing anything. */
return 0;
}
/* We're not going to resize it, but rebuild the
table anyway to purge old dummy entries.
Subtle: This is *necessary* if fill==size,
as set_lookkey needs at least one virgin slot to
terminate failing searches. If fill < size, it's
merely desirable, as dummies slow searches. */
assert(so->fill > so->used);
memcpy(small_copy, oldtable, sizeof(small_copy));
oldtable = small_copy;
}
}
else {
newtable = PyMem_NEW(setentry, newsize);
if (newtable == NULL) {
PyErr_NoMemory();
return -1;
}
}
/* Make the set empty, using the new table. */
assert(newtable != oldtable);
memset(newtable, 0, sizeof(setentry) * newsize);
so->fill = 0;
so->used = 0;
so->mask = newsize - 1;
so->table = newtable;
/* Copy the data over; this is refcount-neutral for active entries;
dummy entries aren't copied over, of course */
if (oldfill == oldused) {
for (entry = oldtable; oldused > 0; entry++) {
if (entry->key != NULL) {
oldused--;
set_insert_clean(so, entry->key, entry->hash);
}
}
} else {
for (entry = oldtable; oldused > 0; entry++) {
if (entry->key != NULL && entry->key != dummy) {
oldused--;
set_insert_clean(so, entry->key, entry->hash);
}
}
}
if (is_oldtable_malloced)
PyMem_DEL(oldtable);
return 0;
}
static void
set_insert_clean(PySetObject *so, PyObject *key, Py_hash_t hash)
{
setentry *table = so->table;
setentry *entry;
size_t perturb = hash;
size_t mask = (size_t)so->mask;
size_t i = (size_t)hash & mask;
size_t j;
// #define LINEAR_PROBES 9
while (1) {
entry = &table[i];
if (entry->key == NULL)
goto found_null;
if (i + LINEAR_PROBES <= mask) {
for (j = 0; j < LINEAR_PROBES; j++) {
entry++;
if (entry->key == NULL)
goto found_null;
}
}
perturb >>= PERTURB_SHIFT;
i = (i * 5 + 1 + perturb) & mask;
}
found_null:
entry->key = key;
entry->hash = hash;
so->fill++;
so->used++;
}从集合当中删除元素 pop
从集合当中删除元素的代码如下所示:
static PyObject *
set_pop(PySetObject *so)
{
/* Make sure the search finger is in bounds */
Py_ssize_t i = so->finger & so->mask;
setentry *entry;
PyObject *key;
assert (PyAnySet_Check(so));
if (so->used == 0) {
PyErr_SetString(PyExc_KeyError, "pop from an empty set");
return NULL;
}
while ((entry = &so->table[i])->key == NULL || entry->key==dummy) {
i++;
if (i > so->mask)
i = 0;
}
key = entry->key;
entry->key = dummy;
entry->hash = -1;
so->used--;
so->finger = i + 1; /* next place to start */
return key;
}上面的代码相对来说也比较清晰,从 finger 开始寻找存在的元素,并且删除他。我们在前面提到过,当一个元素被删除之后他会被赋值成 dummy 而且哈希值为 -1 。
Das obige ist der detaillierte Inhalt vonWas ist das Prinzip der Python-Collection-Set-Implementierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt. Was soll ich tun? Wenn Sie MySQL herunterladen, können Sie die Korruption der Datei begegnen. Es ist heutzutage wirklich nicht einfach! In diesem Artikel wird darüber gesprochen, wie dieses Problem gelöst werden kann, damit jeder Umwege vermeiden kann. Nach dem Lesen können Sie nicht nur das beschädigte MySQL -Installationspaket reparieren, sondern auch ein tieferes Verständnis des Download- und Installationsprozesses haben, um zu vermeiden, dass Sie in Zukunft stecken bleiben. Lassen Sie uns zunächst darüber sprechen, warum das Herunterladen von Dateien beschädigt wird. Dafür gibt es viele Gründe. Netzwerkprobleme sind der Schuldige. Unterbrechung des Download -Prozesses und der Instabilität im Netzwerk kann zu einer Korruption von Dateien führen. Es gibt auch das Problem mit der Download -Quelle selbst. Die Serverdatei selbst ist gebrochen und natürlich auch unterbrochen, wenn Sie sie herunterladen. Darüber hinaus kann das übermäßige "leidenschaftliche" Scannen einer Antiviren -Software auch zu einer Beschädigung von Dateien führen. Diagnoseproblem: Stellen Sie fest, ob die Datei wirklich beschädigt ist
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
MySQL hat sich geweigert, anzufangen? Nicht in Panik, lass es uns ausprobieren! Viele Freunde stellten fest, dass der Service nach der Installation von MySQL nicht begonnen werden konnte, und sie waren so ängstlich! Mach dir keine Sorgen, dieser Artikel wird dich dazu bringen, ruhig damit umzugehen und den Mastermind dahinter herauszufinden! Nachdem Sie es gelesen haben, können Sie dieses Problem nicht nur lösen, sondern auch Ihr Verständnis von MySQL -Diensten und Ihren Ideen zur Fehlerbehebungsproblemen verbessern und zu einem leistungsstärkeren Datenbankadministrator werden! Der MySQL -Dienst startete nicht und es gibt viele Gründe, von einfachen Konfigurationsfehlern bis hin zu komplexen Systemproblemen. Beginnen wir mit den häufigsten Aspekten. Grundkenntnisse: Eine kurze Beschreibung des Service -Startup -Prozesses MySQL Service Startup. Einfach ausgedrückt, lädt das Betriebssystem MySQL-bezogene Dateien und startet dann den MySQL-Daemon. Dies beinhaltet die Konfiguration
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
