
 Backend-Entwicklung
Python-Tutorial
Verwenden Sie Python, um einen einfachen Interpreter für vier Arithmetik zu implementieren
Backend-Entwicklung
Python-Tutorial
Verwenden Sie Python, um einen einfachen Interpreter für vier Arithmetik zu implementieren
Verwenden Sie Python, um einen einfachen Interpreter für vier Arithmetik zu implementieren

Demonstration der Berechnungsfunktion
Hier zeigen wir zuerst die Hilfeinformationen des Programms und dann ein paar einfache Tests mit vier Rechenoperationen. Es scheint, dass es kein Problem gibt (ich kann nicht garantieren, dass das Programm keine Fehler hat!).
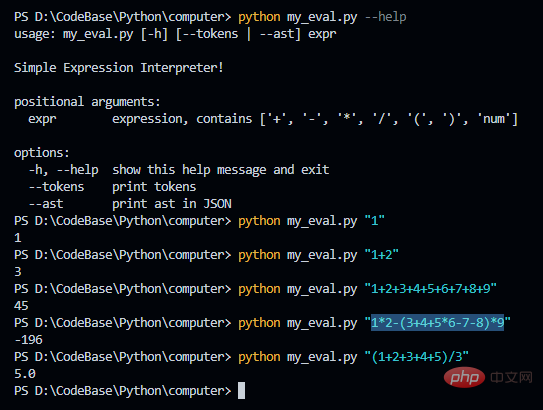
Token ausgeben
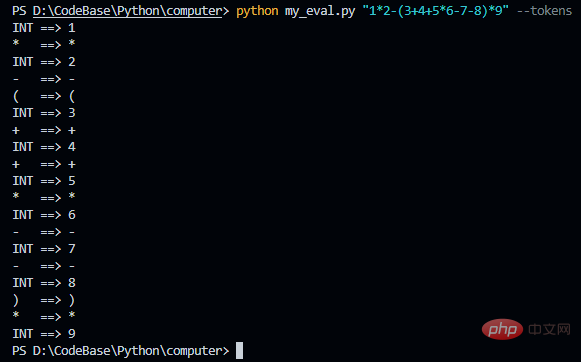
AST ausgeben
Diese formatierten JSON-Informationen sind zu lang und eignen sich nicht für die direkte Anzeige. Wir rendern es, um das endgültig generierte Baumdiagramm zu sehen (Methoden finden Sie in den beiden vorherigen Blogs). Speichern Sie den folgenden JSON in einer Datei, hier nenne ich ihn demo.json, und führen Sie dann den folgenden Befehl aus: pytm-cli -d LR -i demo.json -o demo.html und öffnen Sie ihn dann Es wird im Browser eine HTML-Datei generiert. pytm-cli -d LR -i demo.json -o demo.html,然后再浏览器打开生成的 html 文件。

代码
所有的代码都在这里了,只需要一个文件 my_eval.py,想要运行的话,复制、粘贴,然后按照演示的步骤执行即可。
Node、BinOp、Constan 是用来表示节点的类.
Calculator 中 lexizer 方法是进行分词的,本来我是打算使用正则的,如果你看过我前面的博客的话,可以发现我是用的正则来分词的(因为 Python 的官方文档正则表达式中有一个简易的分词程序)。不过我看其他人都是手写的分词,所以我也这样做了,不过感觉并不是很好,很繁琐,而且容易出错。
parse 方法是进行解析的,主要是解析表达式的结构,判断是否符合四则运算的文法,最终生成表达式树(它的 AST)。
"""
Grammar
G -> E
E -> T E'
E' -> '+' T E' | '-' T E' | ɛ
T -> F T'
T' -> '*' F T' | '/' F T' | ɛ
F -> '(' E ')' | num | name
"""
import json
import argparse
class Node:
"""
简单的抽象语法树节点,定义一些需要使用到的具有层次结构的节点
"""
def eval(self) -> float: ... # 节点的计算方法
def visit(self): ... # 节点的访问方法
class BinOp(Node):
"""
BinOp Node
"""
def __init__(self, left, op, right) -> None:
self.left = left
self.op = op
self.right = right
def eval(self) -> float:
if self.op == "+":
return self.left.eval() + self.right.eval()
if self.op == "-":
return self.left.eval() - self.right.eval()
if self.op == "*":
return self.left.eval() * self.right.eval()
if self.op == "/":
return self.left.eval() / self.right.eval()
return 0
def visit(self):
"""
遍历树的各个节点,并生成 JSON 表示
"""
return {
"name": "BinOp",
"children": [
self.left.visit(),
{
"name": "OP",
"children": [
{
"name": self.op
}
]
},
self.right.visit()
]
}
class Constant(Node):
"""
Constant Node
"""
def __init__(self, value) -> None:
self.value = value
def eval(self) -> float:
return self.value
def visit(self):
return {
"name": "NUMBER",
"children": [
{
"name": str(self.value) # 转成字符是因为渲染成图像时,需要该字段为 str
}
]
}
class Calculator:
"""
Simple Expression Parser
"""
def __init__(self, expr) -> None:
self.expr = expr # 输入的表达式
self.parse_end = False # 解析是否结束,默认未结束
self.toks = [] # 解析的 tokens
self.index = 0 # 解析的下标
def lexizer(self):
"""
分词
"""
index = 0
while index < len(self.expr):
ch = self.expr[index]
if ch in [" ", "\r", "\n"]:
index += 1
continue
if '0' <= ch <= '9':
num_str = ch
index += 1
while index < len(self.expr):
n = self.expr[index]
if '0' <= n <= '9':
if ch == '0':
raise Exception("Invalid number!")
num_str = n
index += 1
continue
break
self.toks.append({
"kind": "INT",
"value": int(num_str)
})
elif ch in ['+', '-', '*', '/', '(', ')']:
self.toks.append({
"kind": ch,
"value": ch
})
index += 1
else:
raise Exception("Unkonwn character!")
def get_token(self):
"""
获取当前位置的 token
"""
if 0 <= self.index < len(self.toks):
tok = self.toks[self.index]
return tok
if self.index == len(self.toks): # token解析结束
return {
"kind": "EOF",
"value": "EOF"
}
raise Exception("Encounter Error, invalid index = ", self.index)
def move_token(self):
"""
下标向后移动一位
"""
self.index += 1
def parse(self) -> Node:
"""
G -> E
"""
# 分词
self.lexizer()
# 解析
expr_tree = self.parse_expr()
if self.parse_end:
return expr_tree
else:
raise Exception("Invalid expression!")
def parse_expr(self):
"""
E -> T E'
E' -> + T E' | - T E' | ɛ
"""
# E -> E E'
left = self.parse_term()
# E' -> + T E' | - T E' | ɛ
while True:
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if tok["kind"] == "EOF":
# 解析结束的标志
self.parse_end = True
break
if kind in ["+", "-"]:
self.move_token()
left = BinOp(left, value, self.parse_term())
else:
break
return left
def parse_term(self):
"""
T -> F T'
T' -> * F T' | / F T' | ɛ
"""
# T -> F T'
left = self.parse_factor()
# T' -> * F T' | / F T' | ɛ
while True:
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if kind in ["*", "/"]:
self.move_token()
right = self.parse_factor()
left = BinOp(left, value, right)
else:
break
return left
def parse_factor(self):
"""
F -> '(' E ')' | num | name
"""
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if kind == '(':
self.move_token()
expr_node = self.parse_expr()
if self.get_token()["kind"] != ")":
raise Exception("Encounter Error, expected )!")
self.move_token()
return expr_node
if kind == "INT":
self.move_token()
return Constant(value=value)
raise Exception("Encounter Error, unknown factor: ", kind)
if __name__ == "__main__":
# 添加命令行参数解析器
cmd_parser = argparse.ArgumentParser(
description="Simple Expression Interpreter!")
group = cmd_parser.add_mutually_exclusive_group()
group.add_argument("--tokens", help="print tokens", action="store_true")
group.add_argument("--ast", help="print ast in JSON", action="store_true")
cmd_parser.add_argument(
"expr", help="expression, contains ['+', '-', '*', '/', '(', ')', 'num']")
args = cmd_parser.parse_args()
calculator = Calculator(expr=args.expr)
tree = calculator.parse()
if args.tokens: # 输出 tokens
for t in calculator.toks:
print(f"{t['kind']:3s} ==> {t['value']}")
elif args.ast: # 输出 JSON 表示的 AST
print(json.dumps(tree.visit(), indent=4))
else: # 计算结果
print(tree.eval())总结
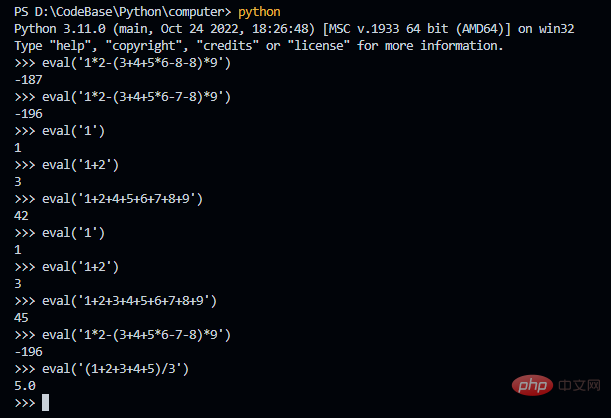
本来想在前面说一下为什么叫 my_eval.py,但是感觉看到后面的人不多,那就在这里说好了。如果写了一个复杂的表达式,那么怎么验证是否正确的。这里我们直接利用 Python 这个最完美的解释器就好了,哈哈。这里用 Python 的 eval 函数,你当然是不需要调用这个函数,直接复制计算的表达式即可。我用 eval 函数,只是想表达为什么我的程序会叫 my_eval
Code
Der gesamte Code ist hier. Sie benötigen nur eine Datei my_eval.py. Wenn Sie ihn ausführen möchten, kopieren Sie ihn, fügen Sie ihn ein und befolgen Sie dann die Schritte der Demonstration.
Die Lexizer-Methode in Calculator wird ursprünglich für die Wortsegmentierung verwendet. Wenn Sie meinen vorherigen Blog gelesen haben, können Sie das finden Ich bin Reguläre Ausdrücke werden zum Segmentieren von Wörtern verwendet (da es in den regulären Ausdrücken der offiziellen Python-Dokumentation ein einfaches Wortsegmentierungsprogramm gibt). Aber ich sah, dass andere Leute Partizipien von Hand schrieben, also tat ich dasselbe, aber es fühlte sich nicht sehr gut an, es war sehr mühsam und fehleranfällig.
Die Parse-Methode analysiert hauptsächlich die Struktur des Ausdrucks, bestimmt, ob er der Grammatik der vier arithmetischen Operationen entspricht, und generiert schließlich den Ausdrucksbaum (seinen AST). 🎜rrreee
Zusammenfassung
🎜Ich wollte ursprünglich darüber sprechen, warum esmy_eval.py heißt, aber ich habe das Gefühl, dass nicht viele Leute dahinter stecken, also werde ich es hier sagen . Wenn Sie einen komplexen Ausdruck schreiben, wie überprüfen Sie, ob er korrekt ist? Hier können wir einfach Python verwenden, den perfektesten Interpreter, haha. Hier wird die Eval-Funktion von Python verwendet. Natürlich müssen Sie diese Funktion nicht aufrufen, sondern kopieren Sie einfach den berechneten Ausdruck. Ich verwende die Funktion eval nur, um auszudrücken, warum mein Programm my_eval heißt. 🎜🎜🎜🎜🎜Nachdem es auf diese Weise implementiert wurde, kann es als einfacher Vier-Arithmetik-Interpreter betrachtet werden. Wenn Sie es jedoch noch einmal tun, werden Sie wahrscheinlich wie ich das Gefühl haben, dass der gesamte Vorgang sehr umständlich ist. Da es fertige Tools zur Wortsegmentierung und grammatikalischen Analyse gibt und diese nicht fehleranfällig sind, kann der Arbeitsaufwand erheblich reduziert werden. Es ist jedoch notwendig, dies selbst durchzuführen. Bevor Sie das Tool verwenden, müssen Sie zumindest die Funktion des Tools verstehen. 🎜Das obige ist der detaillierte Inhalt vonVerwenden Sie Python, um einen einfachen Interpreter für vier Arithmetik zu implementieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Es gibt kein absolutes Gehalt für Python- und JavaScript -Entwickler, je nach Fähigkeiten und Branchenbedürfnissen. 1. Python kann mehr in Datenwissenschaft und maschinellem Lernen bezahlt werden. 2. JavaScript hat eine große Nachfrage in der Entwicklung von Front-End- und Full-Stack-Entwicklung, und sein Gehalt ist auch beträchtlich. 3. Einflussfaktoren umfassen Erfahrung, geografische Standort, Unternehmensgröße und spezifische Fähigkeiten.
 Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Obwohl eindeutig und unterschiedlich mit der Unterscheidung zusammenhängen, werden sie unterschiedlich verwendet: Unterschieds (Adjektiv) beschreibt die Einzigartigkeit der Dinge selbst und wird verwendet, um Unterschiede zwischen den Dingen zu betonen; Das Unterscheidungsverhalten oder die Fähigkeit des Unterschieds ist eindeutig (Verb) und wird verwendet, um den Diskriminierungsprozess zu beschreiben. In der Programmierung wird häufig unterschiedlich, um die Einzigartigkeit von Elementen in einer Sammlung darzustellen, wie z. B. Deduplizierungsoperationen; Unterscheidet spiegelt sich in der Gestaltung von Algorithmen oder Funktionen wider, wie z. B. die Unterscheidung von ungeraden und sogar Zahlen. Bei der Optimierung sollte der eindeutige Betrieb den entsprechenden Algorithmus und die Datenstruktur auswählen, während der unterschiedliche Betrieb die Unterscheidung zwischen logischer Effizienz optimieren und auf das Schreiben klarer und lesbarer Code achten sollte.
 Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
! X Understanding! X ist ein logischer Nicht-Operator in der C-Sprache. Es booleschen den Wert von x, dh wahre Änderungen zu falschen, falschen Änderungen an True. Aber seien Sie sich bewusst, dass Wahrheit und Falschheit in C eher durch numerische Werte als durch Boolesche Typen dargestellt werden, ungleich Null wird als wahr angesehen und nur 0 wird als falsch angesehen. Daher handelt es sich um negative Zahlen wie positive Zahlen und gilt als wahr.
 Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Es gibt keine integrierte Summenfunktion in C für die Summe, kann jedoch implementiert werden durch: Verwenden einer Schleife, um Elemente nacheinander zu akkumulieren; Verwenden eines Zeigers, um auf die Elemente nacheinander zuzugreifen und zu akkumulieren; Betrachten Sie für große Datenvolumina parallele Berechnungen.
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Kopieren Sie den Liebescode und fügen Sie den Liebescode kostenlos kopieren und einfügen
Apr 04, 2025 am 06:48 AM
Das Kopieren und Einfügen des Codes ist nicht unmöglich, sollte aber mit Vorsicht behandelt werden. Abhängigkeiten wie Umgebung, Bibliotheken, Versionen usw. im Code stimmen möglicherweise nicht mit dem aktuellen Projekt überein, was zu Fehlern oder unvorhersehbaren Ergebnissen führt. Stellen Sie sicher, dass der Kontext konsistent ist, einschließlich Dateipfade, abhängiger Bibliotheken und Python -Versionen. Wenn Sie den Code für eine bestimmte Bibliothek kopieren und einfügen, müssen Sie möglicherweise die Bibliothek und ihre Abhängigkeiten installieren. Zu den häufigen Fehlern gehören Pfadfehler, Versionskonflikte und inkonsistente Codestile. Die Leistungsoptimierung muss gemäß dem ursprünglichen Zweck und den Einschränkungen des Codes neu gestaltet oder neu gestaltet werden. Es ist entscheidend, den Code zu verstehen und den kopierten kopierten Code zu debuggen und nicht blind zu kopieren und einzufügen.
 Was bedeutet die Summe in der C -Sprache?
Apr 03, 2025 pm 02:09 PM
Was bedeutet die Summe in der C -Sprache?
Apr 03, 2025 pm 02:09 PM
Methoden zum Summieren von Array -Elementen in C -Sprache: Verwenden Sie eine Schleife, um Array -Elemente nacheinander zu sammeln. Verwenden Sie für mehrdimensionale Arrays verschachtelte Schleifen, um zu durchqueren und zu akkumulieren. Überprüfen Sie unbedingt den Array-Index sorgfältig, um zu vermeiden, dass außerhalb des Gebrochenen Zugriffs verursacht und Programmabstürze verursacht werden.
