

Pipeline ist eine Kommunikationsmethode zwischen Linux-Prozessen, die Informationen über einen gemeinsam genutzten Speicherbereich übertragen können, und die Daten in der Pipeline können nur in eine Richtung fließen, was bedeutet, dass es nur feste Schreibprozesse und Leseprozesse geben kann. Derzeit können Sie in jeder Shell zwei Befehle mit „|“ verbinden. Die Shell verbindet die Eingabe und Ausgabe der beiden Prozesse mit einer Pipe, um den Zweck der Kommunikation zwischen Prozessen zu erreichen.

Die Betriebsumgebung dieses Tutorials: Linux7.3-System, Dell G3-Computer.
Pipes sind die älteste Methode zur prozessübergreifenden Kommunikation in UNIX-Umgebungen. In diesem Artikel wird hauptsächlich die Verwendung von Pipes in der Linux-Umgebung erläutert.
Pipe, Englisch ist Pfeife. Pipes sind eine Kommunikationsmethode zwischen Linux-Prozessen, die Informationen über einen gemeinsamen Speicherbereich übertragen können, und die Daten in der Pipe können nur in eine Richtung fließen, was bedeutet, dass es nur feste Schreibprozesse und Leseprozesse geben kann.
Der Erfinder der Pipeline ist Douglas McElroy, der auch der Erfinder der frühen Shell unter UNIX war. Nachdem er die Shell erfunden hatte, stellte er fest, dass es beim Ausführen von Befehlen in Systemoperationen häufig erforderlich war, die Ausgabe eines Programms zur Verarbeitung an ein anderes Programm zu übertragen. Dieser Vorgang kann durch Eingabe- und Ausgabeumleitung und das Hinzufügen von Dateien erreicht werden, z :
Aber das scheint zu mühsam zu sein. Daher entstand das Konzept der Pipeline. Derzeit können Sie in jeder Shell zwei Befehle mit „|“ verbinden. Die Shell verbindet die Eingabe und Ausgabe der beiden Prozesse mit einer Pipe, um den Zweck der Kommunikation zwischen Prozessen zu erreichen:
[zorro@zorro-pc pipe]$ ls -l /etc/ > etc.txt [zorro@zorro-pc pipe]$ wc -l etc.txt 183 etc.txt
Vergleichen Sie die beiden oben genannten Methoden Wir können auch verstehen, dass eine Pipe im Wesentlichen eine Datei ist. Der vorherige Prozess öffnet die Datei im Schreibmodus und der nachfolgende Prozess öffnet sie im Lesemodus. Auf diese Weise wird Kommunikation erreicht, nachdem man vorne geschrieben und später gelesen hat. Tatsächlich folgt das Design der Pipeline auch dem UNIX-Designprinzip „Alles ist eine Datei“. Es handelt sich im Wesentlichen um eine Datei. Das Linux-System implementiert die Pipeline direkt in ein Dateisystem und verwendet VFS, um Betriebsschnittstellen für Anwendungen bereitzustellen.
Obwohl die Implementierung in Form einer Datei erfolgt, belegt die Pipeline selbst keinen Festplatten- oder anderen externen Speicherplatz. In der Linux-Implementierung belegt es Speicherplatz. Daher ist eine Pipe unter Linux ein Speicherpuffer, dessen Betriebsmodus eine Datei ist.
Unter Linux gibt es zwei Arten von Pipes:
Anonyme Pipes
Benannte Pipes
Diese beiden Pipes werden auch benannte oder unbenannte Pipes genannt. Die häufigste Form anonymer Pipes ist das „|“, das wir am häufigsten bei Shell-Operationen verwenden. Sein Merkmal besteht darin, dass es nur in übergeordneten Prozessen verwendet werden kann, bevor der untergeordnete Prozess eine Pipe-Datei öffnet und dann den untergeordneten Prozess erzeugt Kopieren Sie den Prozessadressraum des übergeordneten Prozesses in dieselbe Pipe-Datei, um den Zweck zu erreichen, dieselbe Pipeline für die Kommunikation zu verwenden. Derzeit kennt niemand außer den übergeordneten und untergeordneten Prozessen den Deskriptor dieser Pipe-Datei, sodass die Informationen in dieser Pipe nicht an andere Prozesse übergeben werden können. Dies gewährleistet die Sicherheit der übertragenen Daten, verringert aber natürlich auch die Vielseitigkeit der Pipe, sodass das System auch Named Pipes bereitstellt.
Wir können den Befehl mkfifo oder mknod verwenden, um eine benannte Pipe zu erstellen, was sich nicht vom Erstellen einer Datei unterscheidet:
[zorro@zorro-pc pipe]$ ls -l /etc/ | wc -l 183
Sie können sehen, dass der erstellte Dateityp etwas ganz Besonderes ist, es ist der Typ p. Zeigt an, dass es sich um eine Pipelinedatei handelt. Mit dieser Pipe-Datei gibt es einen globalen Namen für eine Pipe im System, sodass zwei beliebige, nicht miteinander verbundene Prozesse über diese Pipe-Datei kommunizieren können. Lassen wir nun beispielsweise einen Prozess diese Pipe-Datei schreiben:
[zorro@zorro-pc pipe]$ mkfifo pipe [zorro@zorro-pc pipe]$ ls -l pipe prw-r--r-- 1 zorro zorro 0 Jul 14 10:44 pipe
Zu diesem Zeitpunkt wird der Schreibvorgang blockiert, da am anderen Ende der Pipe niemand liest. Dies ist das Standardverhalten des Kernels für Pipe-Dateidefinitionen. Wenn zu diesem Zeitpunkt ein Prozess diese Pipe liest, wird die Blockierung dieses Schreibvorgangs aufgehoben:
[zorro@zorro-pc pipe]$ echo xxxxxxxxxxxxxx > pipe
Sie können beobachten, dass der Echo-Befehl am anderen Ende ebenfalls zurückkehrt, nachdem wir die Datei kategorisiert haben. Dies ist eine Named Pipe.
Das Linux-System verwendet auf der untersten Ebene dasselbe Dateisystem-Betriebsverhalten für Named Pipes und anonyme Pipes. Dieses Dateisystem wird Pipefs genannt. Ob Ihr System dieses Dateisystem unterstützt, können Sie in der Datei /etc/proc/filesystems herausfinden:
[zorro@zorro-pc pipe]$ cat pipe xxxxxxxxxxxxxx
观察完了如何在命令行中使用管道之后,我们再来看看如何在系统编程中使用管道。
我们可以把匿名管道和命名管道分别叫做PIPE和FIFO。这主要因为在系统编程中,创建匿名管道的系统调用是pipe(),而创建命名管道的函数是mkfifo()。使用mknod()系统调用并指定文件类型为为S_IFIFO也可以创建一个FIFO。
使用pipe()系统调用可以创建一个匿名管道,这个系统调用的原型为:
#include <unistd.h> int pipe(int pipefd[2]);
这个方法将会创建出两个文件描述符,可以使用pipefd这个数组来引用这两个描述符进行文件操作。pipefd[0]是读方式打开,作为管道的读描述符。pipefd[1]是写方式打开,作为管道的写描述符。从管道写端写入的数据会被内核缓存直到有人从另一端读取为止。我们来看一下如何在一个进程中使用管道,虽然这个例子并没有什么意义:
[zorro@zorro-pc pipe]$ cat pipe.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
if (write(pipefd[1], STRING, strlen(STRING)) < 0) {
perror("write()");
exit(1);
}
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
exit(0);
}这个程序创建了一个管道,并且对管道写了一个字符串之后从管道读取,并打印在标准输出上。用一个图来说明这个程序的状态就是这样的:

一个进程自己给自己发送消息这当然不叫进程间通信,所以实际情况中我们不会在单个进程中使用管道。进程在pipe创建完管道之后,往往都要fork产生子进程,成为如下图表示的样子:
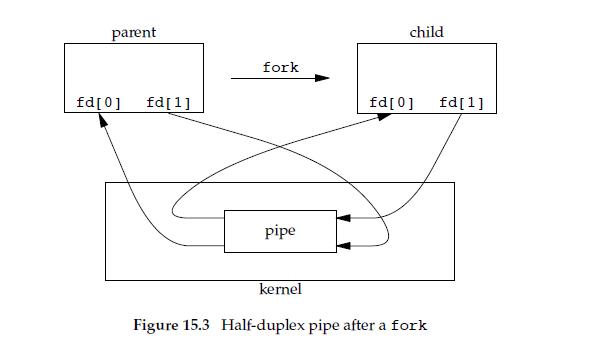
如图中描述,fork产生的子进程会继承父进程对应的文件描述符。利用这个特性,父进程先pipe创建管道之后,子进程也会得到同一个管道的读写文件描述符。从而实现了父子两个进程使用一个管道可以完成半双工通信。此时,父进程可以通过fd[1]给子进程发消息,子进程通过fd[0]读。子进程也可以通过fd[1]给父进程发消息,父进程用fd[0]读。程序实例如下:
[zorro@zorro-pc pipe]$ cat pipe_parent_child.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
bzero(buf, BUFSIZ);
snprintf(buf, BUFSIZ, "Message from child: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
} else {
/* this is parent */
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
sleep(1);
bzero(buf, BUFSIZ);
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
wait(NULL);
}
exit(0);
}父进程先给子进程发一个消息,子进程接收到之后打印消息,之后再给父进程发消息,父进程再打印从子进程接收到的消息。程序执行效果:
[zorro@zorro-pc pipe]$ ./pipe_parent_child Parent pid is: 8309 Child pid is: 8310 Message from parent: My pid is: 8309 Message from child: My pid is: 8310
从这个程序中我们可以看到,管道实际上可以实现一个半双工通信的机制。使用同一个管道的父子进程可以分时给对方发送消息。我们也可以看到对管道读写的一些特点,即:
在管道中没有数据的情况下,对管道的读操作会阻塞,直到管道内有数据为止。当一次写的数据量不超过管道容量的时候,对管道的写操作一般不会阻塞,直接将要写的数据写入管道缓冲区即可。
当然写操作也不会再所有情况下都不阻塞。这里我们要先来了解一下管道的内核实现。上文说过,管道实际上就是内核控制的一个内存缓冲区,既然是缓冲区,就有容量上限。我们把管道一次最多可以缓存的数据量大小叫做PIPESIZE。内核在处理管道数据的时候,底层也要调用类似read和write这样的方法进行数据拷贝,这种内核操作每次可以操作的数据量也是有限的,一般的操作长度为一个page,即默认为4k字节。我们把每次可以操作的数据量长度叫做PIPEBUF。POSIX标准中,对PIPEBUF有长度限制,要求其最小长度不得低于512字节。PIPEBUF的作用是,内核在处理管道的时候,如果每次读写操作的数据长度不大于PIPEBUF时,保证其操作是原子的。而PIPESIZE的影响是,大于其长度的写操作会被阻塞,直到当前管道中的数据被读取为止。
在Linux 2.6.11之前,PIPESIZE和PIPEBUF实际上是一样的。在这之后,Linux重新实现了一个管道缓存,并将它与写操作的PIPEBUF实现成了不同的概念,形成了一个默认长度为65536字节的PIPESIZE,而PIPEBUF只影响相关读写操作的原子性。从Linux 2.6.35之后,在fcntl系统调用方法中实现了F_GETPIPE_SZ和F_SETPIPE_SZ操作,来分别查看当前管道容量和设置管道容量。管道容量容量上限可以在/proc/sys/fs/pipe-max-size进行设置。
#define BUFSIZE 65536
......
ret = fcntl(pipefd[1], F_GETPIPE_SZ);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
printf("PIPESIZE: %d\n", ret);
ret = fcntl(pipefd[1], F_SETPIPE_SZ, BUFSIZE);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
......PIPEBUF和PIPESIZE对管道操作的影响会因为管道描述符是否被设置为非阻塞方式而有行为变化,n为要写入的数据量时具体为:
O_NONBLOCK关闭,n <= PIPE_BUF:
n个字节的写入操作是原子操作,write系统调用可能会因为管道容量(PIPESIZE)没有足够的空间存放n字节长度而阻塞。
O_NONBLOCK打开,n <= PIPE_BUF:
如果有足够的空间存放n字节长度,write调用会立即返回成功,并且对数据进行写操作。空间不够则立即报错返回,并且errno被设置为EAGAIN。
O_NONBLOCK关闭,n > PIPE_BUF:
对n字节的写入操作不保证是原子的,就是说这次写入操作的数据可能会跟其他进程写这个管道的数据进行交叉。当管道容量长度低于要写的数据长度的时候write操作会被阻塞。
O_NONBLOCK打开,n > PIPE_BUF:
如果管道空间已满。write调用报错返回并且errno被设置为EAGAIN。如果没满,则可能会写入从1到n个字节长度,这取决于当前管道的剩余空间长度,并且这些数据可能跟别的进程的数据有交叉。
以上是在使用半双工管道的时候要注意的事情,因为在这种情况下,管道的两端都可能有多个进程进行读写处理。如果再加上线程,则事情可能变得更复杂。实际上,我们在使用管道的时候,并不推荐这样来用。管道推荐的使用方法是其单工模式:即只有两个进程通信,一个进程只写管道,另一个进程只读管道。实现为:
[zorro@zorro-pc pipe]$ cat pipe_parent_child2.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
close(pipefd[1]);
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
} else {
/* this is parent */
close(pipefd[0]);
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
wait(NULL);
}
exit(0);
}这个程序实际上比上一个要简单,父进程关闭管道的读端,只写管道。子进程关闭管道的写端,只读管道。整个管道的打开效果最后成为下图所示:
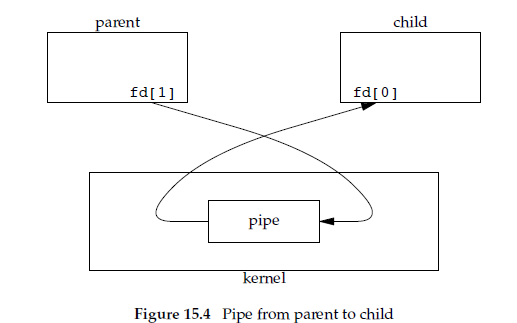
此时两个进程就只用管道实现了一个单工通信,并且这种状态下不用考虑多个进程同时对管道写产生的数据交叉的问题,这是最经典的管道打开方式,也是我们推荐的管道使用方式。另外,作为一个程序员,即使我们了解了Linux管道的实现,我们的代码也不能依赖其特性,所以处理管道时该越界判断还是要判断,该错误检查还是要检查,这样代码才能更健壮。
命名管道在底层的实现跟匿名管道完全一致,区别只是命名管道会有一个全局可见的文件名以供别人open打开使用。再程序中创建一个命名管道文件的方法有两种,一种是使用mkfifo函数。另一种是使用mknod系统调用,例子如下:
[zorro@zorro-pc pipe]$ cat mymkfifo.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "Argument error!\n");
exit(1);
}
/*
if (mkfifo(argv[1], 0600) < 0) {
perror("mkfifo()");
exit(1);
}
*/
if (mknod(argv[1], 0600|S_IFIFO, 0) < 0) {
perror("mknod()");
exit(1);
}
exit(0);
}我们使用第一个参数作为创建的文件路径。创建完之后,其他进程就可以使用open()、read()、write()标准文件操作等方法进行使用了。其余所有的操作跟匿名管道使用类似。需要注意的是,无论命名还是匿名管道,它的文件描述都没有偏移量的概念,所以不能用lseek进行偏移量调整。
相关推荐:《Linux视频教程》
Das obige ist der detaillierte Inhalt vonWas ist ein Linux-Kanal?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!










![[Einführung für Anfänger, leicht verständlich] Lernen Sie Linux in einer Woche](https://img.php.cn/upload/course/000/000/068/6242a86a890b1568.png)








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



