
 Technologie-Peripheriegeräte
KI
Das Geheimnis des Sieges im Datenwettbewerb lüften: Analyse der Vorteile von A100 in 200 Spielen
Technologie-Peripheriegeräte
KI
Das Geheimnis des Sieges im Datenwettbewerb lüften: Analyse der Vorteile von A100 in 200 Spielen
Das Geheimnis des Sieges im Datenwettbewerb lüften: Analyse der Vorteile von A100 in 200 Spielen

2022 ist ein großes Jahr für KI, aber auch für Datenwettbewerbe, mit einem Gesamtpreisgeld von über 5 Millionen US-Dollar auf allen Plattformen.
Kürzlich hat die Analyseplattform für maschinelles Lernen-Wettbewerbe ML Contests eine groß angelegte Statistik zum Datenwettbewerb 2022 durchgeführt. Neuer Bericht wirft einen Blick auf alle bemerkenswerten Ereignisse im Jahr 2022. Im Folgenden finden Sie eine Zusammenstellung des Originaltextes.
Highlights:
- Werkzeugauswahl für erfolgreiche Teilnehmer: Python, Pydata, Pytorch und Gradienten-verstärkte Entscheidungsbäume.
- Deep Learning muss Gradienten-verstärkte Entscheidungsbäume noch ersetzen, obwohl erstere oft an Wert gewinnen, wenn man sich mit Boosting-Methoden vertraut macht.
- Transformer dominiert weiterhin im NLP und beginnt, mit Faltungs-Neuronalen Netzen in der Computer Vision zu konkurrieren.
- Der heutige Datenwettbewerb deckt ein breites Spektrum an Forschungsbereichen ab, darunter Computer Vision, NLP, Datenanalyse, Robotik, Zeitreihenanalyse usw.
- Große Ensemble-Modelle gehören immer noch häufig zu den Gewinnerlösungen, und einige Einzelmodelllösungen gewinnen ebenfalls.
- Es gibt mehrere aktive Datenwettbewerbsplattformen.
- Die Datenwettbewerbs-Community wächst weiter, auch im akademischen Bereich.
- Etwa 50 % der Gewinner sind Ein-Personen-Teams und 50 % der Gewinner sind Erstsieger.
- Manche Leute verwenden High-End-Hardware, aber auch kostenlose Ressourcen wie Google Colab können das Spiel gewinnen.
Wettbewerbe und Trends
Der Wettbewerb mit dem höchsten Preisgeld ist der Snow Cast Showdown Contest von Drivendata, der vom U.S. Bureau of Reclamation gesponsert wird. Die Teilnehmer erhalten ein Preisgeld von 500.000 US-Dollar und sollen dazu beitragen, das Wasserversorgungsmanagement zu verbessern, indem sie genaue Schätzungen des Schneewasserflusses für verschiedene Regionen im Westen liefern. Wie immer hat Drivendata einen ausführlichen Artikel zum Matchup geschrieben und einen ausführlichen Lösungsbericht, der durchaus lesenswert ist.
Der beliebteste Wettbewerb des Jahres 2022 ist der American Express Default Prediction-Wettbewerb von Kaggle, der darauf abzielt, vorherzusagen, ob Kunden ihre Kredite zurückzahlen werden. Mehr als 4.000 Teams nahmen teil, die vier besten Teams erhielten ein Preisgeld von insgesamt 100.000 US-Dollar. Zum ersten Mal in diesem Jahr wurde ein Erstbeitrag von einem Ein-Personen-Team gewonnen, das ein Ensemble aus neuronalen Netzen und LightGBM-Modellen nutzte.
Der größte unabhängige Wettbewerb ist die AI Audit Challenge der Stanford University, die einen Belohnungspool von 71.000 US-Dollar für die besten „Modelle, Lösungen, Datensätze und Tools“ bietet, um Wege zur Lösung des Problems „unrechtmäßige Diskriminierung“ zu finden .
Drei Wettbewerbe, die auf Finanzprognosen basieren, finden alle auf Kaggle statt: die Prognosen der Tokyo Stock Exchange von JPX, die Marktprognosen von Ubiquant und die Kryptoprognosen von G-Research.
Bei Vergleichen in verschiedene Richtungen hat Computer Vision den höchsten Anteil, NLP liegt an zweiter Stelle und sequentielle Entscheidungsprobleme (Reinforcement Learning) nehmen zu. Kaggle reagierte auf diese wachsende Popularität mit der Einführung von Simulationswettbewerben im Jahr 2020. Aicrowd veranstaltet auch viele Wettbewerbe zum verstärkten Lernen. Im Jahr 2022 beliefen sich die Gesamteinnahmen von 25 dieser interaktiven Veranstaltungen auf mehr als 300.000 US-Dollar.
Bei der Real Robot Challenge, dem offiziellen NeurIPS 2022-Wettbewerb, müssen die Teilnehmer lernen, einen dreifingrigen Roboter zu steuern, um einen Würfel an einen Zielort zu bewegen oder ihn an einem bestimmten Punkt im Raum zu positionieren, während er in die richtige Richtung blickt. Die Strategien der Teilnehmer werden jede Woche auf dem physischen Roboter ausgeführt und die Ergebnisse werden in der Bestenliste aktualisiert. Der Preis ist mit 5.000 US-Dollar dotiert und die akademische Ehre, auf dem NeurIPS-Symposium zu sprechen.
Plattform
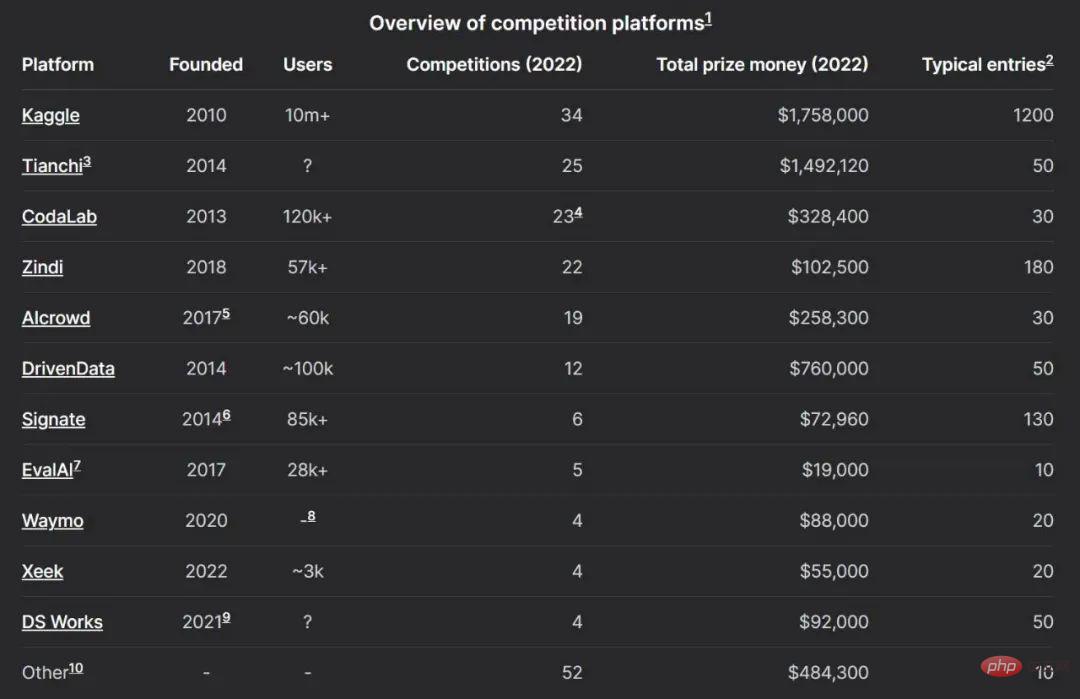
Obwohl die Leute mit Kaggle und Tianchi vertraut sind, gibt es derzeit viele Wettbewerbsplattformen für maschinelles Lernen, die ein aktives Ökosystem bilden.
Das Bild unten zeigt den Plattformvergleich 2022:
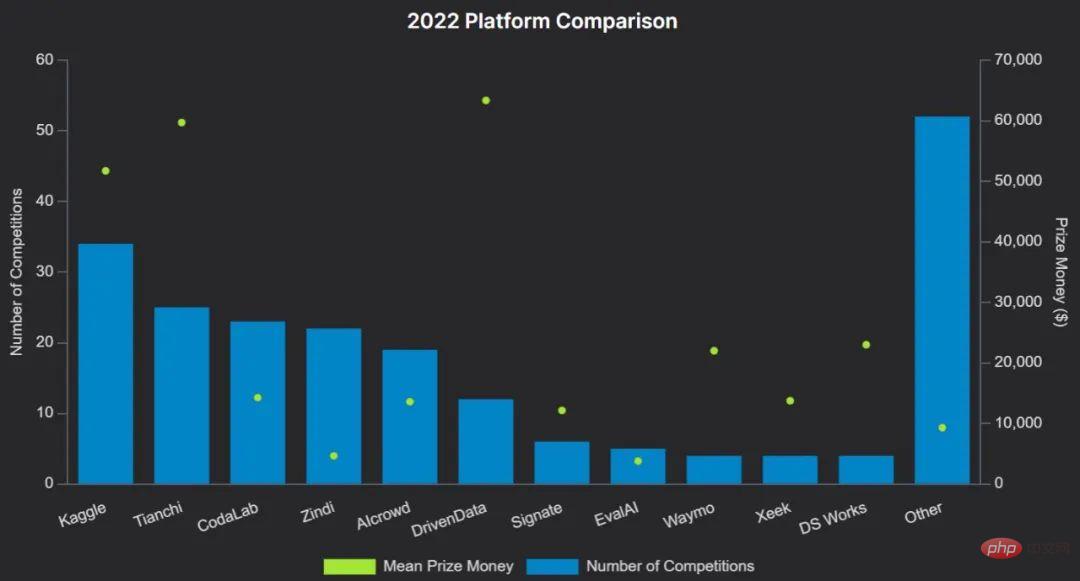
Nennen Sie einige Beispiele:
- Kaggle ist eine der etabliertesten Plattformen, sie wurde 2017 von Google übernommen und verfügt über die größte Community, die zuletzt 10 Millionen Nutzer anzog. Die Durchführung von Wettbewerben mit Preisen auf Kaggle kann sehr teuer sein. Neben der Ausrichtung von Wettbewerben ermöglicht Kaggle Benutzern das Hosten von Datensätzen, Notizen und Modellen.
- Codalab ist eine Open-Source-Wettbewerbsplattform, die von der Universität Paris – Saclay betrieben wird. Jeder kann sich registrieren, einen Wettbewerb veranstalten oder daran teilnehmen. Es stellt kostenlose CPU-Ressourcen für die Inferenz bereit, die Wettbewerbsorganisatoren durch ihre eigene Hardware ergänzen können.
- Zindi ist eine kleinere Plattform mit einer sehr aktiven Community, die sich darauf konzentriert, Institutionen mit Datenwissenschaftlern in Afrika zu verbinden. Drivendata konzentriert sich auf Social-Impact-Wettbewerbe und hat Wettbewerbe für die NASA und andere Organisationen entwickelt. Den Wettbewerben folgen immer ausführliche Forschungsberichte.
- Aicrowd startete als Forschungsprojekt an der Eidgenössischen Technischen Hochschule (EPFL) und ist heute eine der fünf besten Wettbewerbsplattformen. Es veranstaltet mehrere offizielle NeurIPS-Wettbewerbe.
Wissenschaft
Der Großteil der Preisgelder für Wettbewerbe, die auf großen Plattformen laufen, kommt aus der Industrie, aber Wettbewerbe für maschinelles Lernen haben in der Wissenschaft eindeutig eine reichere Geschichte, wie Isabelle Guyon dieses Jahr bei NeurIPS tat. Wie bereits erwähnt in der Einladungsrede.
NeurIPS ist eine der renommiertesten akademischen Konferenzen zum Thema maschinelles Lernen weltweit, auf der regelmäßig die wichtigsten Beiträge zum maschinellen Lernen des letzten Jahrzehnts präsentiert werden, darunter AlexNet, GAN, Transformer und GPT-3.
NeurIPS veranstaltete 2014 erstmals einen Data Challenge in Machine Learning (CIML)-Workshop, seit 2017 gibt es eine Wettbewerbskomponente. Seitdem sind der Wettbewerb und das Gesamtpreisgeld weiter gewachsen und erreichten im Dezember 2022 fast 400.000 US-Dollar.
Andere Konferenzen zum Thema maschinelles Lernen veranstalten ebenfalls Wettbewerbe, darunter CVPR, ICPR, IJCAI, ICRA, ECCV, PCIC und AutoML.
Preise
Etwa die Hälfte aller Wettbewerbe für maschinelles Lernen haben Preispools von über 10.000 US-Dollar. Es besteht kein Zweifel, dass es bei vielen interessanten Wettbewerben kleine Preise gibt, und in diesem Bericht werden nur solche mit Geldpreisen oder akademischen Auszeichnungen berücksichtigt. Bei Datenwettbewerben im Zusammenhang mit prestigeträchtigen akademischen Konferenzen erhalten die Gewinner häufig Reisestipendien für die Teilnahme an der Konferenz.
Während einige Turnierplattformen im Durchschnitt tendenziell größere Preispools haben als andere (siehe Plattform-Vergleichstabelle), veranstalteten viele Plattformen im Jahr 2022 mindestens ein Turnier mit einem sehr großen Preispool – Gesamtpreise Die Top-Ten-Wettbewerbe umfassen diese laufen auf DrivenData, Kaggle, CodaLab und AIcrowd.
So gewinnen Sie
Diese Umfrage analysiert die vom Gewinneralgorithmus verwendeten Techniken anhand von Fragebögen und Codebeobachtungen.
Ganz konsequent war Python die Sprache der Wahl für die Gewinner des Wettbewerbs, was für die Leute vielleicht kein unerwartetes Ergebnis ist. Von denen, die Python verwenden, verwendet etwa die Hälfte hauptsächlich Jupyter Notebook und die andere Hälfte Standard-Python-Skripte.
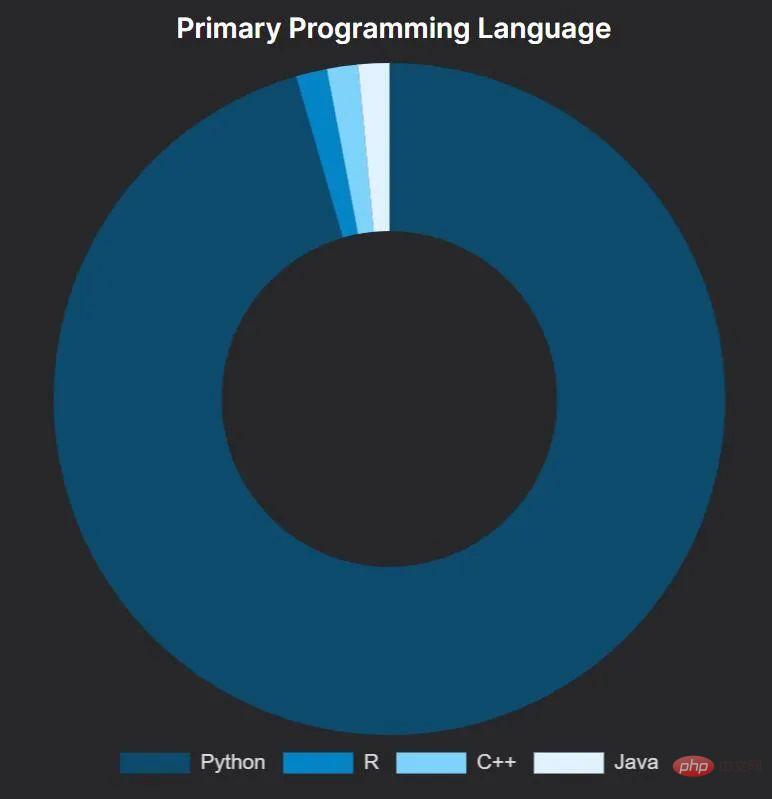
Eine erfolgreiche Lösung, die hauptsächlich R verwendet: Amir Ghazi gewann den Kaggle-Wettbewerb, um den Gewinner der US Men’s College Basketball Championship 2022 vorherzusagen. Er tat dies, indem er Code aus einer wettbewerbsgekrönten Lösung von Kaggle-Großmeister Darius Barušauskas aus dem Jahr 2018 verwendete – offenbar wörtlich kopierte. Unglaublich, dass Darius auch 2022 an diesem Rennen teilnahm, einen neuen Ansatz verfolgte und den 593. Platz belegte.
Von Gewinnern verwendete Python-Pakete
Bei der Betrachtung der in den Gewinnerlösungen verwendeten Pakete stellte sich heraus, dass alle Gewinner, die Python verwendeten, in gewissem Umfang den PyData-Stack nutzten.
Die beliebtesten Softwarepakete sind in drei Kategorien unterteilt: Kern-Toolkits, NLP-Kategorien und Computer-Vision-Kategorien.

Unter ihnen war das Wachstum des Deep-Learning-Frameworks PyTorch stetig und sein Sprung von 2021 auf 2022 ist sehr offensichtlich: PyTorch stieg von 77 % auf 96 % der Gewinnerlösungen.
Von den 46 Gewinnerlösungen mit Deep Learning verwendeten 44 PyTorch als primäres Framework und nur zwei verwendeten TensorFlow. Noch aussagekräftiger ist, dass einer der beiden Wettbewerbe, die mit TensorFlow gewonnen wurden, der Great Barrier Reef-Wettbewerb von Kaggle, dem Gewinnerteam, das TensorFlow nutzt, ein zusätzliches Preisgeld von 50.000 US-Dollar bietet. Ein weiterer mit TensorFlow gewonnener Wettbewerb nutzte die High-Level-Keras-API.
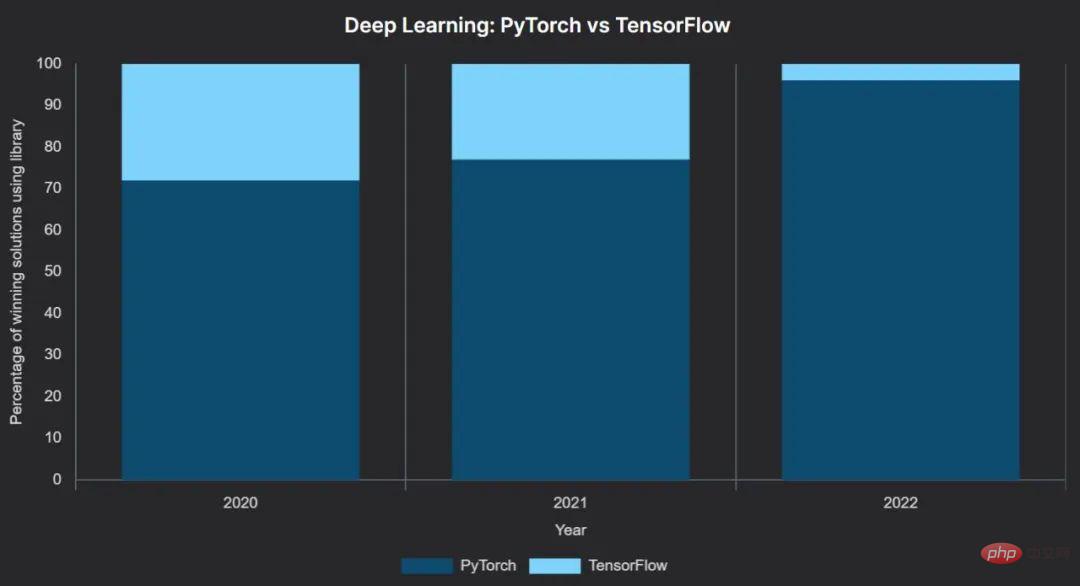
Während 3 Gewinner Pytorch-Lightning und 1 Fastai nutzten – beide bauten auf PyTorch auf – nutzte die überwiegende Mehrheit PyTorch direkt.
Nun kann man sagen, dass PyTorch zumindest im Datenwettlauf den Kampf der Machine-Learning-Frameworks gewonnen hat. Dies steht im Einklang mit breiteren Forschungstrends zum maschinellen Lernen.
Es ist erwähnenswert, dass wir keine Instanzen des Gewinnerteams gefunden haben, die andere neuronale Netzwerkbibliotheken wie JAX (von Google entwickelt und von DeepMind verwendet), PaddlePaddle (von Baidu entwickelt) oder MindSpore (von Huawei entwickelt) verwendet haben ).
Computer Vision
Werkzeuge neigen dazu, die Welt zu dominieren, Technologie jedoch nicht. Auf der CVPR 2022 wurde die ConvNext-Architektur als „ConvNet der 2020er Jahre“ vorgestellt und zeigte, dass sie aktuelle Transformer-basierte Modelle übertrifft. Es wurde in mindestens zwei preisgekrönten Computer-Vision-Lösungen verwendet, und CNN bleibt insgesamt bis heute die beliebteste neuronale Netzwerkarchitektur unter den Gewinnern von Computer-Vision-Wettbewerben.
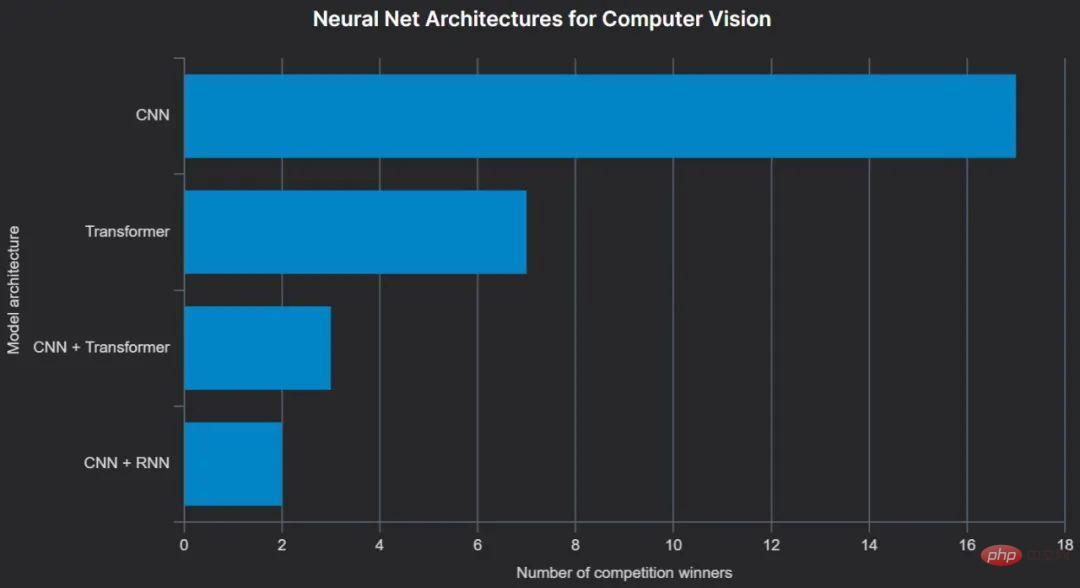
Computer Vision ist der Sprachmodellierung bei der Verwendung vorab trainierter Modelle sehr ähnlich: leicht verständliche Architekturen, die auf öffentlichen Datensätzen wie ImageNet trainiert werden. Das beliebteste Repository ist Hugging Face Hub, auf das über timm zugegriffen werden kann und das das Laden vorab trainierter Versionen von Dutzenden verschiedener Computer-Vision-Modelle äußerst bequem macht.
Die Vorteile der Verwendung vorab trainierter Modelle liegen auf der Hand: Bilder aus der realen Welt und von Menschen erstellter Text weisen einige gemeinsame Merkmale auf, und die Verwendung vorab trainierter Modelle kann zu gesundem Menschenverstand führen, ähnlich wie bei der Verwendung größerer und allgemeinerer Modelle. Trainingsdatensatz.
Oftmals werden vorab trainierte Modelle auf der Grundlage aufgabenspezifischer Daten (z. B. von Wettbewerbsorganisatoren bereitgestellte Daten) verfeinert – weiter trainiert –, aber nicht immer. Der Gewinner der Image Matching Challenge verwendete ein vorab trainiertes Modell ohne jegliche Feinabstimmung: „Aufgrund der (unterschiedlichen) Qualität der Trainings- und Testdaten in diesem Wettbewerb haben wir das bereitgestellte Training nicht zur Feinabstimmung verwendet.“ weil wir dachten, es wäre nicht sehr effektiv.“ Die Entscheidung hat sich ausgezahlt.
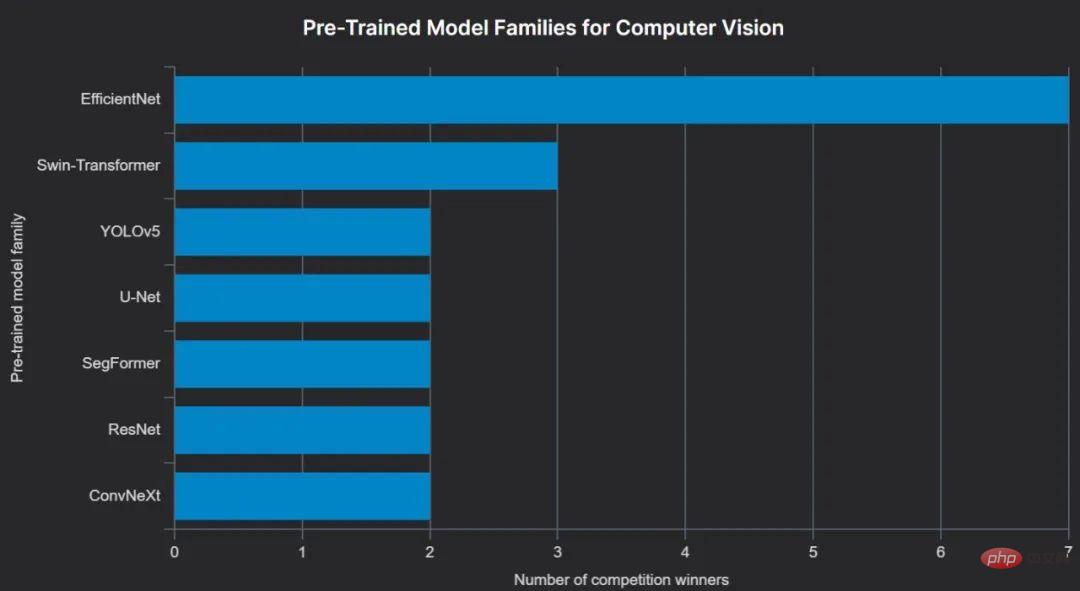
Der bisher beliebteste vorab trainierte Computer-Vision-Modelltyp unter den Gewinnern 2022 ist EfficientNet, das, wie der Name schon sagt, den Vorteil hat, dass es weniger ressourcenintensiv ist als viele andere Modelle.
Verarbeitung natürlicher Sprache
Seit ihrer Einführung im Jahr 2017 dominieren Transformer-basierte Modelle den Bereich der Verarbeitung natürlicher Sprache (NLP). Transformer ist das „T“ in BERT und GPT und auch der Kern von ChatGPT.
Es ist also keine Überraschung, dass alle Gewinnerlösungen in Wettbewerben zur Verarbeitung natürlicher Sprache im Kern auf Transformer-basierten Modellen basieren. Es ist keine Überraschung, dass sie alle in PyTorch implementiert sind. Sie alle verwendeten vorab trainierte Modelle, die mithilfe der Transformers-Bibliothek von Hugging Face geladen wurden, und fast alle verwendeten die Version des DeBERTa-Modells von Microsoft Research – normalerweise deberta-v3-large.
Viele davon erfordern große Mengen an Rechenressourcen. Beispielsweise ließ der Google AI4Code-Gewinner einen A100 (80 GB) etwa 10 Tage lang laufen, um einen einzelnen Deberta-v3-large für seine endgültige Lösung zu trainieren. Dieser Ansatz ist die Ausnahme (unter Verwendung eines einzelnen Mastermodells und einer festen Zug-/Bewertungsaufteilung) – alle anderen Lösungen nutzen intensiv Ensemblemodelle und fast alle verwenden irgendeine Form der k-fachen Kreuzvalidierung. Beispielsweise verwendete der Gewinner des Jigsaw Toxic Comments-Wettbewerbs einen gewichteten Durchschnitt der Ergebnisse von 15 Modellen.
Transformer-basierte Ensembles werden manchmal in Verbindung mit LSTM oder LightGBM verwendet, und es gibt auch mindestens zwei Fälle von Pseudo-Labeling, die effektiv für die Gewinnerlösung verwendet wurden.
XGBoost war früher ein Synonym für Kaggle. Allerdings ist LightGBM eindeutig die beliebteste GBDT-Bibliothek für die Gewinner des Jahres 2022 – die Gewinner erwähnten LightGBM so oft in ihren Lösungsberichten oder Fragebögen wie CatBoost und XGBoost zusammen, CatBoost belegte den zweiten Platz und XGBoost überraschenderweise den dritten Platz.
Computing und Hardware
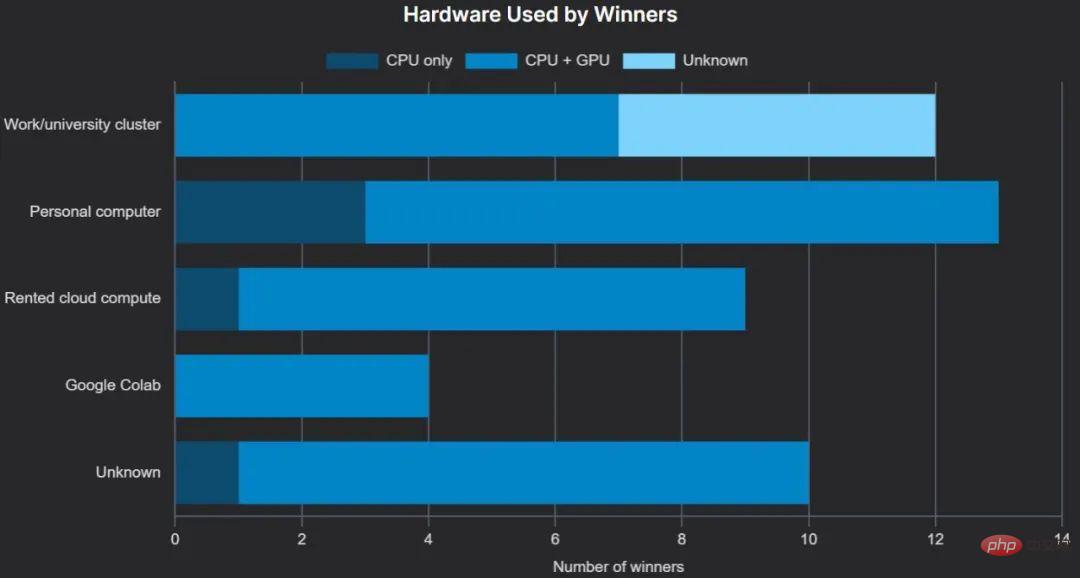
Wie grob erwartet verwendeten die meisten Gewinner GPUs für das Training – dies kann die Trainingsleistung von Gradient-Boosted-Bäumen erheblich verbessern und ist tatsächlich für tiefe neuronale Netze von erforderlich. Eine beträchtliche Anzahl von Preisträgern hat Zugriff auf Cluster, die von ihrem Arbeitgeber oder ihrer Universität bereitgestellt werden, häufig einschließlich GPUs.
Etwas überraschenderweise haben wir keine Fälle gefunden, in denen die Tensor Processing Unit (TPU) von Google zum Trainieren eines erfolgreichen Modells verwendet wurde. Wir haben auch keine Gewinnermodelle gesehen, die auf den Chips der M-Serie von Apple trainiert wurden, die seit Mai 2022 von PyTorch unterstützt werden.
Die Cloud-Notebook-Lösung von Google, Colab, ist beliebt, mit einem Gewinner im kostenlosen Plan, einem im Pro-Plan und einem weiteren im Pro+ (wir können nicht bestätigen, auf welchem Plan der vierte Gewinner Colab verwendet).
Lokale persönliche Hardware war beliebter als Cloud-Hardware, und obwohl neun Gewinner die GPU nannten, die sie für das Training verwendeten, gaben sie nicht an, ob sie eine lokale GPU oder eine Cloud-GPU verwendeten.
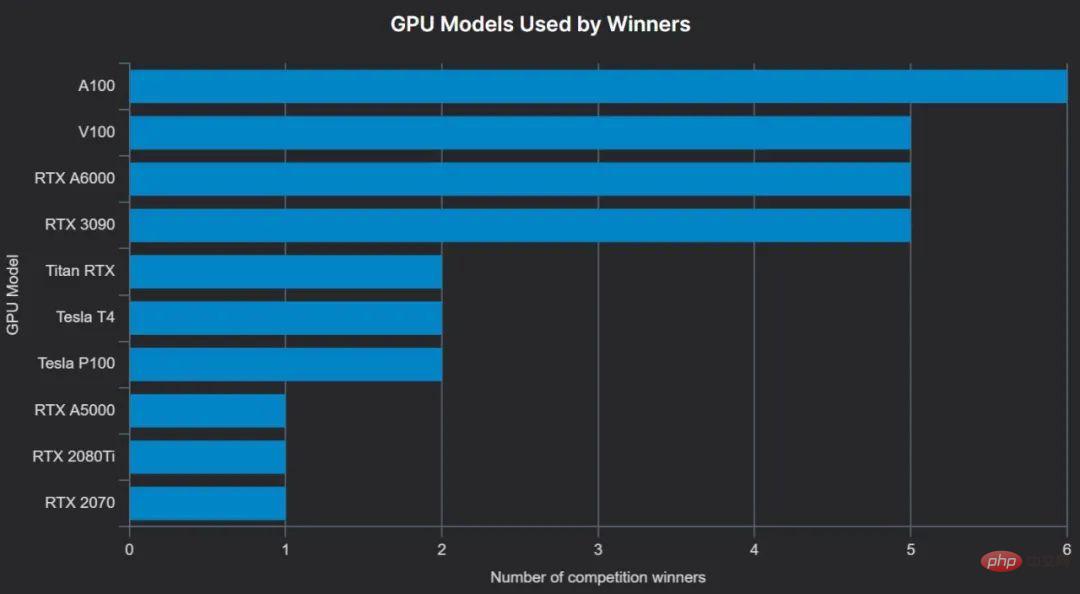
Die beliebteste GPU ist die neueste High-End-KI-Beschleunigerkarte NVIDIA A100 (A100 40 GB und A100 80 GB werden hier zusammengefasst, da der Gewinner nicht immer zwischen den beiden unterscheiden kann) und wird häufig verwendet Mehrere A100s – Beispielsweise nutzte der Gewinner von Zindis Turtle Recall-Wettbewerb 8 A100 (40 GB) GPUs und die anderen beiden Gewinner nutzten 4 A100.
Teambildung
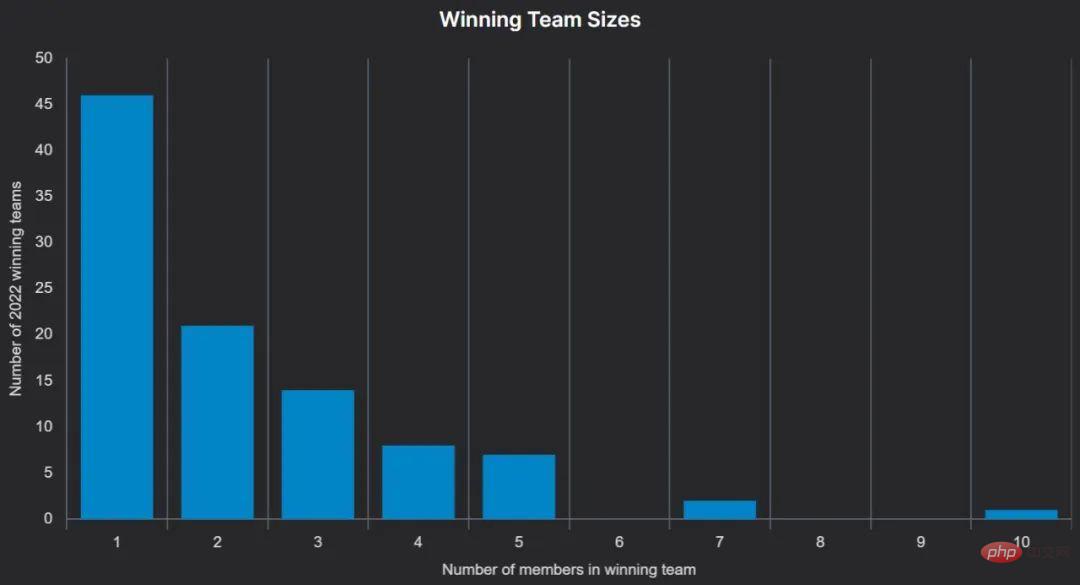
Viele Wettbewerbe erlauben bis zu 5 Teilnehmer pro Team, und Teams können aus Einzelpersonen oder kleineren Teams gebildet werden, die bis zu einer bestimmten Frist vor dem Abgabetermin der Ergebnisse „zusammengeführt“ werden.
Einige Wettbewerbe erlauben größere Teams, zum Beispiel sind bei der Open Data Challenge von Waymo bis zu 10 Personen pro Team zugelassen.
Fazit
Dies ist ein grober Blick auf den maschinellen Lernwettbewerb 2022. Ich hoffe, Sie finden darin einige nützliche Informationen.
Im Jahr 2023 stehen viele spannende neue Wettbewerbe an und wir freuen uns darauf, nach ihrem Ende weitere Erkenntnisse zu veröffentlichen.
Das obige ist der detaillierte Inhalt vonDas Geheimnis des Sieges im Datenwettbewerb lüften: Analyse der Vorteile von A100 in 200 Spielen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
