

Steht die Netzwerkstruktur des Computer Vision vor einer weiteren Innovation?
Von Faltungs-Neuronalen Netzen bis hin zu visuellen Transformern mit Aufmerksamkeitsmechanismen behandeln neuronale Netzmodelle das Eingabebild als Raster oder Patch-Sequenz, aber diese Methode kann sich ändernde oder komplexe Objekte nicht erfassen.
Wenn Menschen beispielsweise ein Bild betrachten, teilen sie das gesamte Bild auf natürliche Weise in mehrere Objekte auf und stellen räumliche und andere Positionsbeziehungen zwischen den Objekten her. Mit anderen Worten, das gesamte Bild ist tatsächlich ein Diagramm gezeichnet, und Objekte sind Knoten im Diagramm.
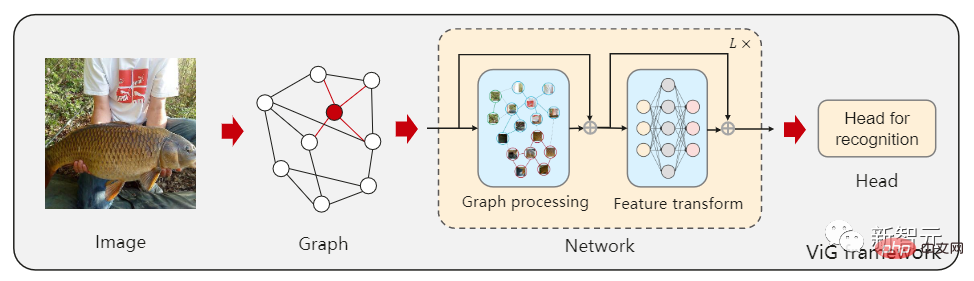
Kürzlich haben Forscher des Instituts für Software der Chinesischen Akademie der Wissenschaften, des Noah's Ark Laboratory von Huawei, der Peking-Universität und der Universität Macau gemeinsam eine neue Modellarchitektur Vision GNN (ViG) vorgeschlagen, die extrahieren kann Bildfunktionen auf Diagrammebene werden in Sehaufgaben verwendet.

Link zum Papier: https://arxiv.org/pdf/2206.00272.pdf
Zuerst müssen Sie das Bild in mehrere Patches als Knoten im Diagramm aufteilen und ein Diagramm erstellen, indem Sie die Patches mit den nächsten Nachbarn verbinden , und verwenden Sie dann das ViG-Modell, um die Informationen aller Knoten im gesamten Diagramm zu transformieren und auszutauschen.
ViG besteht aus zwei Grundmodulen. Das Grapher-Modul verwendet Graphenfaltung, um Diagramminformationen zu aggregieren und zu aktualisieren, und das FFN-Modul verwendet zwei lineare Schichten, um Knotenmerkmale zu transformieren.
Experimente zu Bilderkennungs- und Objekterkennungsaufgaben haben auch die Überlegenheit der ViG-Architektur bewiesen. Die bahnbrechende Forschung von GNN zu allgemeinen Sehaufgaben wird nützliche Inspiration und Erfahrungen für zukünftige Forschungen liefern.
Der Autor des Artikels ist Professor Wu Enhua, Doktorvater am Institut für Software der Chinesischen Akademie der Wissenschaften und Honorarprofessor an der Universität Macau. Er absolvierte die Fakultät für Technische Mechanik und Mathematik der Tsinghua-Universität 1970 und promovierte 1980 am Institut für Informatik der Universität Manchester im Vereinigten Königreich. Die Hauptforschungsbereiche sind Computergrafik und virtuelle Realität, darunter: virtuelle Realität, fotorealistische Grafikerzeugung, physikbasierte Simulation und Echtzeit-Computing, physikbasierte Modellierung und Rendering, Bild- und Videoverarbeitung und -modellierung, visuelles Computing und Maschinenforschung.
Die Netzwerkstruktur ist oft der kritischste Faktor für die Verbesserung der Leistung. Solange die Menge und Qualität der Daten sichergestellt werden kann, können Sie durch einen Wechsel des Modells von CNN zu ViT ein Modell mit besserer Leistung erhalten.
Aber verschiedene Netzwerke behandeln Eingabebilder unterschiedlich. CNN verschiebt das Fenster auf das Bild und führt Übersetzungsinvarianz und lokale Funktionen ein.
ViT und Multi-Layer-Perceptron (MLP) konvertieren das Bild in eine Patch-Sequenz, z. B. ein 224 × 224-Bild in mehrere 16 × 16-Patches, und bilden schließlich eine Eingabesequenz mit einer Länge von 196.
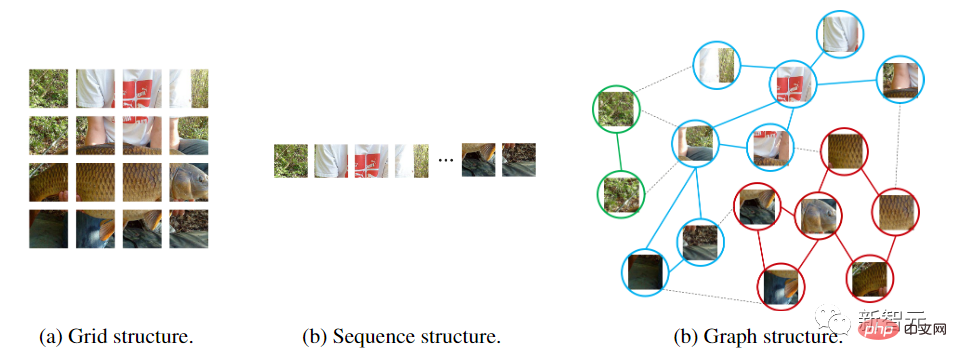
Graphische neuronale Netze sind flexibler. Beispielsweise besteht eine grundlegende Aufgabe beim Computer Vision darin, Objekte in Bildern zu identifizieren. Da Objekte normalerweise nicht viereckig sind und unregelmäßige Formen haben können, sind die in früheren Netzwerken wie ResNet und ViT üblicherweise verwendeten Gitter- oder Sequenzstrukturen redundant und unflexibel zu handhaben.
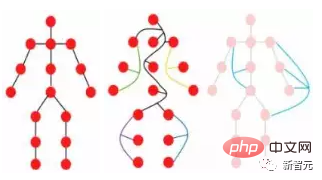
Ein Objekt besteht aus mehreren Teilen. Beispielsweise kann eine Person grob in Kopf, Oberkörper, Arme und Beine unterteilt werden.
Diese durch Gelenke verbundenen Teile bilden auf natürliche Weise eine grafische Struktur. Durch die Analyse des Diagramms konnten wir schließlich erkennen, dass es sich bei dem Objekt möglicherweise um einen Menschen handelt.
Darüber hinaus ist der Graph eine allgemeine Datenstruktur, und Gitter und Sequenz können als Sonderfall des Graphen betrachtet werden. Ein Bild als Diagramm zu betrachten, ist für die visuelle Wahrnehmung flexibler und effizienter.
Die Verwendung einer Diagrammstruktur erfordert die Aufteilung des Eingabebildes in mehrere Patches und die Behandlung jedes Patches als Knoten. Wenn jedes Pixel als Knoten behandelt wird, führt dies zu zu vielen Knoten im Diagramm (>10 KB).
Nach der Erstellung des Diagramms werden die Merkmale zwischen benachbarten Knoten zunächst über ein grafisches Faltungs-Neuronales Netzwerk (GCN) aggregiert und die Darstellung des Bildes extrahiert.
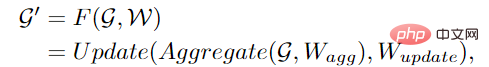
Damit GCN vielfältigere Funktionen erhalten kann, wendet der Autor eine Mehrkopfoperation auf die Diagrammfaltung an. Die aggregierten Funktionen werden durch Köpfe mit unterschiedlichen Gewichten aktualisiert und schließlich in die Bilddarstellung kaskadiert.
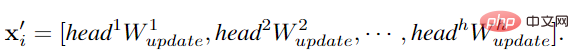
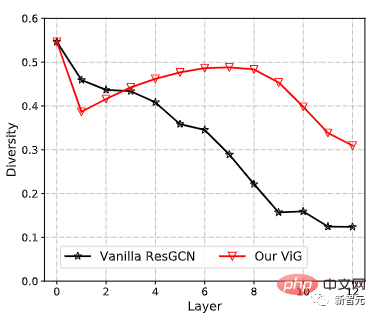
Frühere GCNs verwendeten normalerweise mehrere Faltungsschichten für Diagramme, um die aggregierten Merkmale von Diagrammdaten zu extrahieren, während das Phänomen der übermäßigen Glättung in tiefen GCNs die Eindeutigkeit der Knoten verringert. Dies führt zu einer verminderten Leistung bei der visuellen Erkennung.
Um dieses Problem zu lindern, führten die Forscher weitere Feature-Transformationen und nichtlineare Aktivierungsfunktionen in den ViG-Block ein.
Wenden Sie zunächst vor und nach der Diagrammfaltung eine lineare Ebene an, um Knotenmerkmale in dieselbe Domäne zu projizieren und die Merkmalsvielfalt zu erhöhen. Einfügen einer nichtlinearen Aktivierungsfunktion nach der Graphfaltung, um einen Ebenenkollaps zu vermeiden.
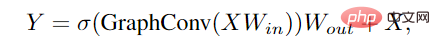
Um die Feature-Konvertierungsfähigkeit weiter zu verbessern und das Phänomen der übermäßigen Glättung zu lindern, ist es auch notwendig, ein Feedforward-Netzwerk (FFN) zu verwenden jeder Knoten. Das FFN-Modul ist ein einfaches mehrschichtiges Perzeptron mit zwei vollständig verbundenen Schichten.
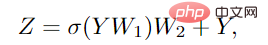
In den Grapher- und FFN-Modulen müssen die Stapelnormalisierung, das Grapher-Modul und das FFN-Modul nach jeder vollständig verbundenen Schicht oder Diagrammfaltungsschicht durchgeführt werden Der Stapel bildet sich ein ViG-Block, der auch die Grundeinheit für den Aufbau eines großen Netzwerks ist.
Im Vergleich zum ursprünglichen ResGCN kann das neu vorgeschlagene ViG die Vielfalt der Funktionen beibehalten, da mehr Ebenen hinzugefügt werden und das Netzwerk auch stärkere Darstellungen lernen kann.
In der Netzwerkarchitektur von Computer Vision hat das häufig verwendete Transformer-Modell normalerweise eine isotrope (isotrope) Struktur (wie ViT), während CNN bevorzugt eine Pyramidenstruktur (wie ResNet) verwendet.
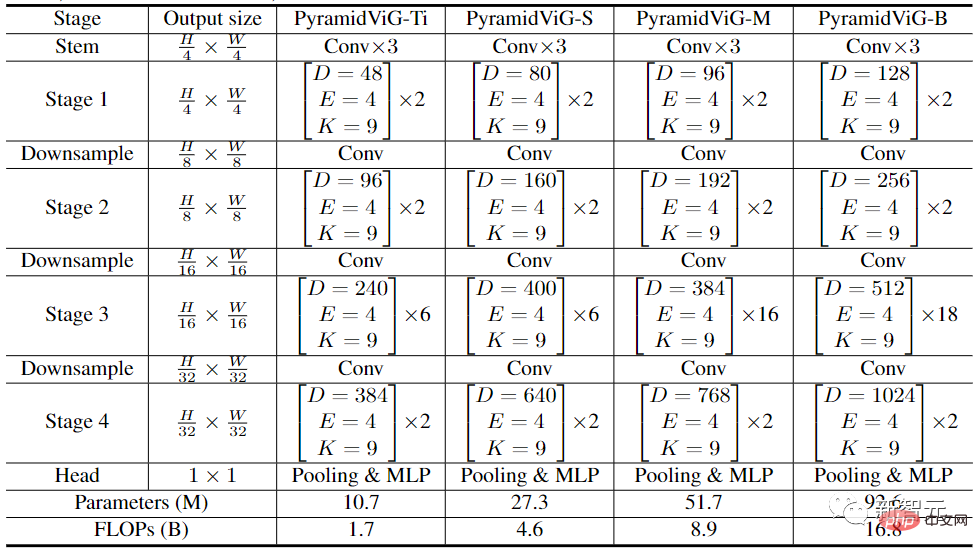
Um den Vergleich mit anderen Arten neuronaler Netze zu ermöglichen, etablierten die Forscher gleichzeitig zwei Netzwerkarchitekturen für ViG: isotrop und pyramidenförmig.
In der experimentellen Vergleichsphase wählten die Forscher den ImageNet ILSVRC 2012-Datensatz in der Bildklassifizierungsaufgabe aus, der 1000 Kategorien, 120 Millionen Trainingsbilder usw. enthält 50.000 Verifizierungsbilder.
In der Zielerkennungsaufgabe wurde der COCO 2017-Datensatz mit 80 Zielkategorien ausgewählt, darunter 118.000 Trainingsbilder und 5000 Verifizierungssatzbilder.

In der isotropen ViG-Architektur kann die Featuregröße während des Hauptberechnungsprozesses unverändert bleiben, was einfach zu erweitern und hardwarebeschleunigungsfreundlich ist. Nach dem Vergleich mit vorhandenen isotropen CNNs, Transformern und MLPs können wir sehen, dass ViG eine bessere Leistung als andere Netzwerktypen erbringt. Unter ihnen erreichte ViG-Ti eine Top-1-Genauigkeit von 73,9 %, was 1,7 % höher ist als das DeiT-Ti-Modell, während der Rechenaufwand ähnlich ist.
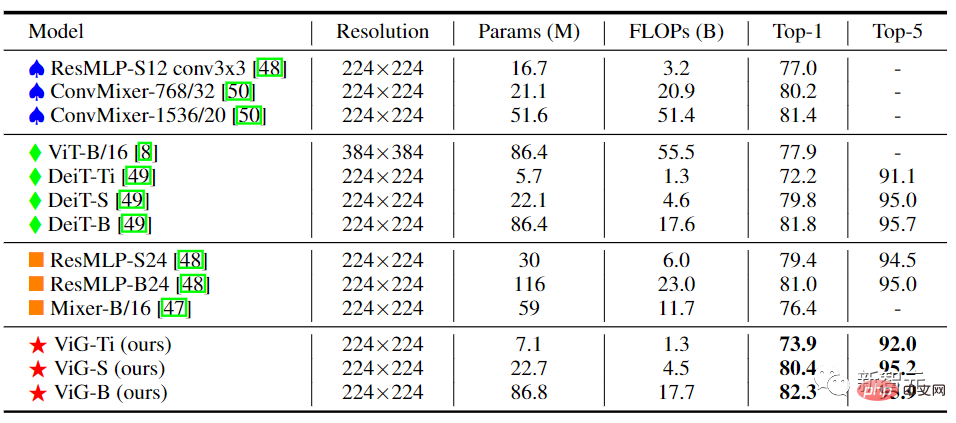
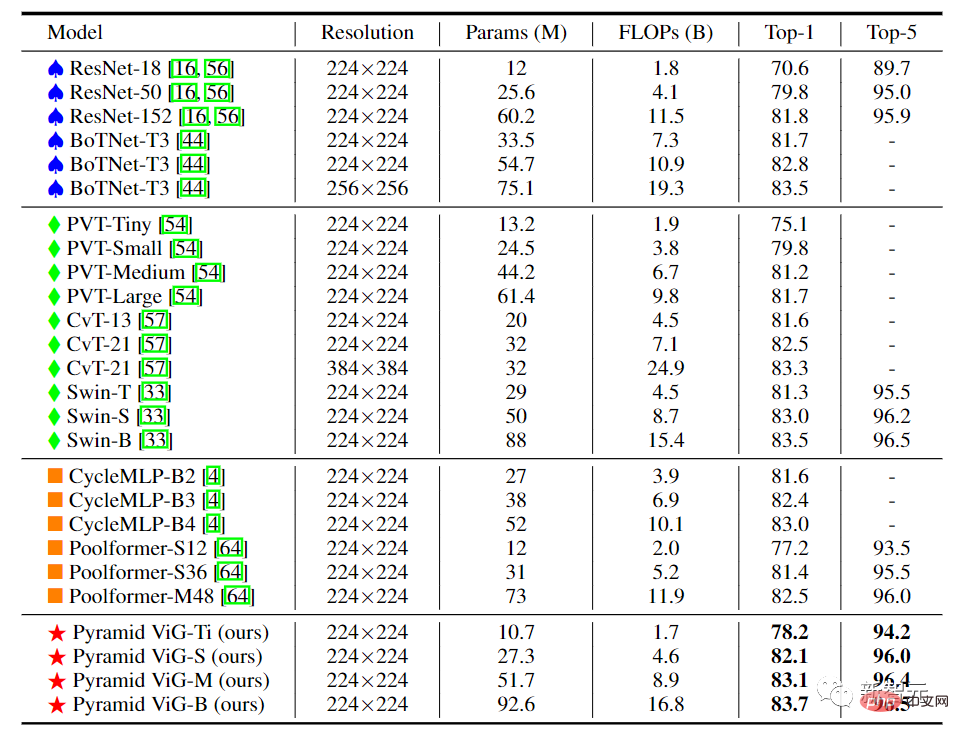
Im ViG mit Pyramidenstruktur wird mit zunehmender Netzwerktiefe die räumliche Größe der Feature-Map allmählich reduziert und die skaleninvarianten Eigenschaften der Das Bild wird zum Generieren von Multiskalen-Features verwendet.
Hochleistungsnetzwerke nutzen meist Pyramidenstrukturen wie ResNet, Swin Transformer und CycleMLP. Nach dem Vergleich von Pyramid ViG mit diesen repräsentativen Pyramidennetzwerken zeigt sich, dass die Pyramid ViG-Serie die hochmodernen Pyramidennetzwerke einschließlich CNN, MLP und Transformer übertreffen oder mit ihnen konkurrieren kann.
Die Ergebnisse zeigen, dass graphische neuronale Netze visuelle Aufgaben gut erledigen können und zu einer Grundkomponente in Computer-Vision-Systemen werden können.
Um den Arbeitsablauf des ViG-Modells besser zu verstehen, visualisierten die Forscher die in ViG-S erstellte Diagrammstruktur. Probendiagramme in zwei verschiedenen Tiefen (Blöcke 1 und 12). Das Pentagramm ist der zentrale Knoten und Knoten mit derselben Farbe sind seine Nachbarn. Es werden nur die beiden zentralen Knoten visualisiert, da das Zeichnen aller Kanten unübersichtlich wirken würde.

Es ist zu beobachten, dass das ViG-Modell inhaltsbezogene Knoten als Nachbarn erster Ordnung auswählen kann. Auf flachen Ebenen werden Nachbarknoten häufig basierend auf niedrigen und lokalen Merkmalen wie Farbe und Textur ausgewählt. Auf tiefen Ebenen sind die Nachbarn des zentralen Knotens semantischer und gehören derselben Kategorie an. Das ViG-Netzwerk kann Knoten schrittweise über ihren Inhalt und ihre semantische Darstellung verbinden und so zur besseren Identifizierung von Objekten beitragen.
Das obige ist der detaillierte Inhalt vonDie chinesische Akademie der Wissenschaften hat ein neues CV-Modell ViG veröffentlicht, das ViT in seiner Leistung übertrifft. Wird es in Zukunft ein Vertreter graphischer neuronaler Netze werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wo Sie Douyin-Live-Wiederholungen sehen können
Wo Sie Douyin-Live-Wiederholungen sehen können
 Was ist der Unterschied zwischen WeChat und WeChat?
Was ist der Unterschied zwischen WeChat und WeChat?
 SO INSTALLIEREN SIE LINUX
SO INSTALLIEREN SIE LINUX
 Kostenlose ERP-Software
Kostenlose ERP-Software
 So lösen Sie verstümmelten SecureCRT-Code
So lösen Sie verstümmelten SecureCRT-Code
 Warum kann ich die letzte leere Seite in Word nicht löschen?
Warum kann ich die letzte leere Seite in Word nicht löschen?
 Aktueller Bitcoin-Preistrend
Aktueller Bitcoin-Preistrend
 Welche Kerntechnologien sind für die Java-Entwicklung erforderlich?
Welche Kerntechnologien sind für die Java-Entwicklung erforderlich?
 Auf welcher Plattform kann ich Ripple-Coins kaufen?
Auf welcher Plattform kann ich Ripple-Coins kaufen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



