

So wenden Sie Python in der Kohortenanalyse an

Kohortenanalyse
Kohortenanalysekonzept
Kohorte bedeutet wörtlich eine Gruppe von Menschen (mit gemeinsamen Merkmalen oder ähnlichen Verhaltensweisen), wie z. B. unterschiedlichem Geschlecht und unterschiedlichem Alter.
Kohortenanalyse: Vergleicht Veränderungen in ähnlichen Gruppen im Zeitverlauf.
Das Produkt iteriert weiter, während Sie es entwickeln und testen, was dazu führt, dass Benutzer in der ersten Woche der Produktveröffentlichung beitreten und Benutzer später beitreten, um unterschiedliche Erfahrungen zu machen. Beispielsweise durchläuft jeder Benutzer einen Lebenszyklus: von der kostenlosen Testversion über die kostenpflichtige Nutzung bis hin zur Beendigung der Nutzung. Gleichzeitig nehmen Sie in dieser Zeit ständig Anpassungen an Ihrem Geschäftsmodell vor. Daher werden Benutzer, die im ersten Monat nach der Einführung des Produkts „Krabben essen“, zwangsläufig ein anderes Onboarding-Erlebnis haben als Benutzer, die nach vier Monaten beitreten. Welche Auswirkungen wird dies auf die Abwanderungsraten haben? Um das herauszufinden, haben wir eine Kohortenanalyse verwendet.
Jede Benutzergruppe bildet eine Kohorte und nimmt am gesamten Testprozess teil. Durch den Vergleich verschiedener Kohorten können Sie herausfinden, ob die Gesamtleistung bei wichtigen Kennzahlen besser wird.
Kombiniert mit der Ebene der Benutzeranalyse, z. B. in verschiedenen Monaten gewonnene Benutzer, neue Benutzer aus verschiedenen Kanälen, Benutzer mit unterschiedlichen Merkmalen (z. B. Benutzer auf WeChat, die täglich mit mindestens 10 Freunden auf WeChat kommunizieren).
Kohortenanalyse, vergleichende Analyse dieser Personengruppen mit unterschiedlichen Merkmalen, um ihre Verhaltensunterschiede in der Zeitdimension zu entdecken.
Daher wird die Kohortenanalyse hauptsächlich für die folgenden zwei Punkte verwendet:
Vergleichen Sie die Datenindikatoren desselben Erfahrungszyklus verschiedener Kohortengruppen, um die Wirkung der iterativen Produktoptimierung zu überprüfen.
Vergleichen Sie die verschiedenen Erfahrungszyklen ( Lebenszeit) derselben Kohortengruppe Zeitraum) Datenindikatoren zur Erkennung langfristiger Erfahrungsprobleme
Wenn wir eine Kohortenanalyse durchführen, kann diese grob in zwei Prozesse unterteilt werden: Bestimmung der Kohortengruppe Gruppierungslogik und Bestimmung des Schlüssels Datenindikatoren der Kohortenanalyse.
Gruppen mit ähnlichen Verhaltensmerkmalen
Gruppen mit demselben Zeitraum
Zum Beispiel:
Nach Kundengewinnungsmonat (gruppiert nach Woche oder sogar Tag)
Nach Kundengewinnungskanal
Kategorisiert nach bestimmten von Benutzern durchgeführten Aktionen, z. B. der Häufigkeit, mit der Benutzer die Website besuchen, oder der Anzahl der Käufe.
Was wichtige Datenindikatoren betrifft, müssen diese auf der Zeitdimension basieren, wie z. B. Kundenbindung, Umsatz, Selbstausbreitungskoeffizient usw.
Das Folgende ist ein Fallbeispiel, bei dem die Retention-Rate als Indikator verwendet wird:
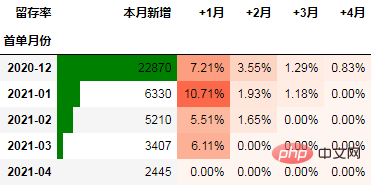
Das Folgende sind die Betriebsdaten eines E-Commerce-Unternehmens. Wir werden diese Daten verwenden, um eine Kohortenanalyse mit Python zu demonstrieren.
Detaillierte Erläuterung des Kohortenanalysefalls:
Bei den Daten handelt es sich um das Zahlungsprotokoll eines E-Commerce-Benutzers. Die Protokollfelder umfassen Datum, Zahlungsbetrag und Benutzer-ID, die desensibilisiert wurden.
Daten lesen
import pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
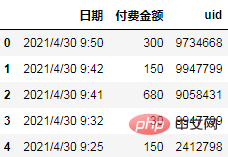
Analyserichtung
Gruppenlogik:
Dies wird nur nach dem ersten Kaufmonat des Benutzers gruppiert, wenn das Protokoll weitere Klassifizierungsfelder enthält (wie Kanal, Geschlecht oder Alter usw.). können Sie weitere Arten der Gruppierungslogik in Betracht ziehen.
Wichtige Datenindikatoren:
Für diese Daten gibt es mindestens 3 Datenindikatoren, die analysiert werden können:
Retentionsrate
Zahlungsbetrag pro Kopf
Anzahl der Einkäufe pro Kopf
Datenvorverarbeitung
Da wir nach Monaten gruppieren, müssen wir die Daten zunächst in Monate umrechnen:
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()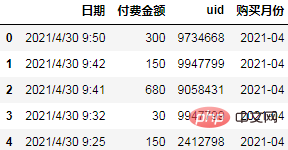
Berechnen Sie die Gesamtzahlung für jeden Benutzer in jedem Monat:
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()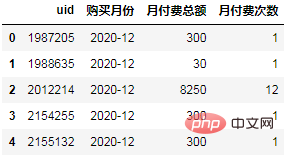
Berechnen Sie jeden Benutzer Der erste Kaufmonat wird im gleichen Zeitraum gruppiert und den Originaldaten zugeordnet:
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()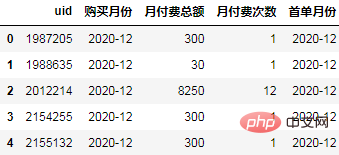
Berechnen Sie die Monatsdifferenz zwischen dem Zeitpunkt jedes Kaufdatensatzes und dem ersten Kaufzeitpunkt und setzen Sie die Monatsdifferenzbezeichnung zurück:
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head() 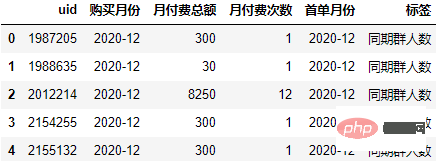
Beide Monate sind Periodentypen. Nach der Subtraktion wird eine Spalte vom Objekttyp erhalten, und der Typ jedes Elements dieser Spalte ist pandas._libs.tslibs.offsets.MonthEnd
Der MonthEnd-Typ hat das Attribut n und kann Gibt eine bestimmte Differenz-Ganzzahl zurück.
Gleiche Kohortenanalyse
Wir haben vorhin gesagt, dass es mindestens 3 Datenindikatoren gibt, die analysiert werden können:
Retentionsrate
Zahlungsbetrag pro Kopf
Anzahl der Einkäufe pro Kopf
从留存率角度进行同期群分析
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number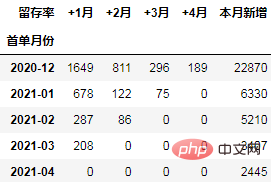
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number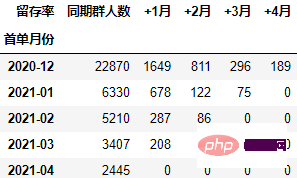
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
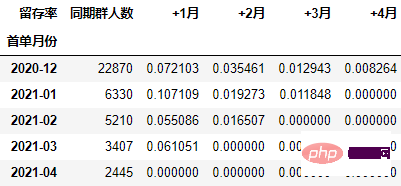
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1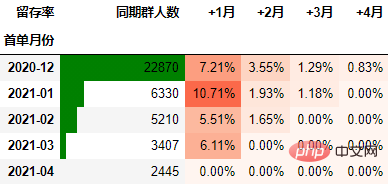
至此计算完毕。
从人均付款金额角度进行同期群分析
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2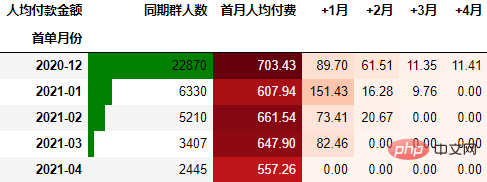
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
从人均购买次数角度进行同期群分析
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3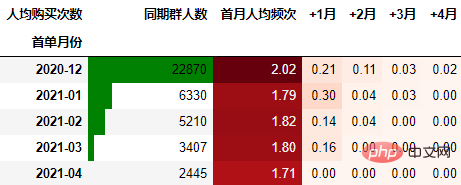
可以得到类似上述一致的结论。
每月总体付费情况
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)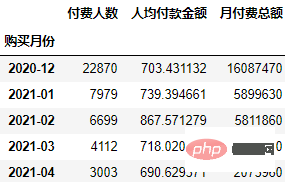
可以看到总体付费人数和付费金额都在逐月下降。
将结果导出网页或截图
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
整体完整代码
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')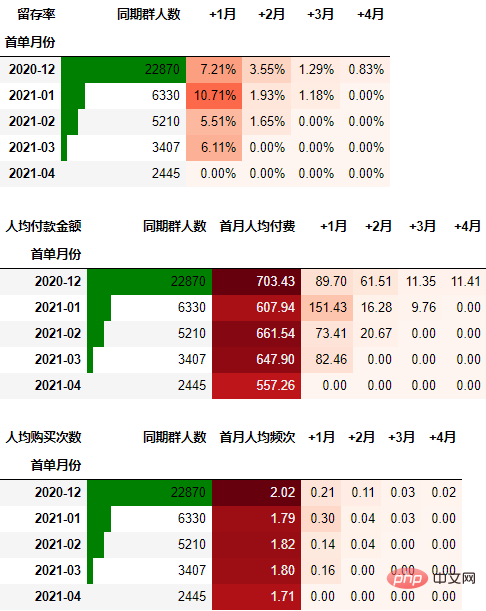
Das obige ist der detaillierte Inhalt vonSo wenden Sie Python in der Kohortenanalyse an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
VS Code ist der vollständige Name Visual Studio Code, der eine kostenlose und open-Source-plattformübergreifende Code-Editor und Entwicklungsumgebung von Microsoft ist. Es unterstützt eine breite Palette von Programmiersprachen und bietet Syntax -Hervorhebung, automatische Codebettel, Code -Snippets und intelligente Eingabeaufforderungen zur Verbesserung der Entwicklungseffizienz. Durch ein reiches Erweiterungs -Ökosystem können Benutzer bestimmte Bedürfnisse und Sprachen wie Debugger, Code -Formatierungs -Tools und Git -Integrationen erweitern. VS -Code enthält auch einen intuitiven Debugger, mit dem Fehler in Ihrem Code schnell gefunden und behoben werden können.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
