
 Backend-Entwicklung
Python-Tutorial
Python-Tutorial: Wie teile ich große Dateien mit Python auf und füge sie zusammen?
Backend-Entwicklung
Python-Tutorial
Python-Tutorial: Wie teile ich große Dateien mit Python auf und füge sie zusammen?
Python-Tutorial: Wie teile ich große Dateien mit Python auf und füge sie zusammen?

Manchmal müssen wir eine große Datei an andere senden, aber aufgrund der Einschränkungen des Übertragungskanals, z. B. der Begrenzung der Größe von E-Mail-Anhängen oder der nicht sehr guten Netzwerkbedingungen, müssen wir die große Datei aufteilen in kleine Dateien aufteilen, mehrmals senden und empfangen. Am Ende werden diese kleinen Dateien dann zusammengeführt. Heute werde ich zeigen, wie man große Dateien mit Python aufteilt und zusammenführt.
Ideen und Umsetzung
Wenn es sich um eine Textdatei handelt, kann diese durch die Anzahl der Zeilen geteilt werden. Unabhängig davon, ob es sich um eine Textdatei oder eine Binärdatei handelt, kann sie entsprechend der angegebenen Größe aufgeteilt werden.
Mit der Dateilese- und -schreibfunktion von Python können Sie Dateien aufteilen und zusammenführen, die Größe jeder Datei festlegen und dann die Bytes der angegebenen Größe lesen und sie in eine neue Datei schreiben. Das empfangende Ende liest die kleinen Dateien nacheinander und schreibt die erhaltenen Bytes der Reihe nach in eine Datei, und die Zusammenführung kann abgeschlossen werden.
Teilen
size = 1024 * 1000 * 10# 10MB
with open("bigfile", "rb") as reader:
part = 1
while True:
part_content = reader.read(size)
if not part_content:
print("split done.")
break
with open(f"bigfile_part{part}","wb") as writer:
writer.write(part_content)Zusammenführen
total_parts = 5
with open("bigfile","wb") as writer:
for i in range(5):
with open(f"bigfile_part{i}", "rb") as reader:
writer.write(reader.read())Verwenden Sie eine Bibliothek eines Drittanbieters
Obwohl Sie es selbst schreiben können, aber andere haben es geschrieben, warum nicht etwas Zeit sparen und es direkt verwenden? Installieren Sie es einfach mit pip:
pip install filesplit
Split
from filesplit.split import Split
split = Split("./data.rar", "./output")
split.bysize(size = 1024*1000*10) # 每个文件最多 10MBNach der Ausführung können wir die geteilten Dateien im Ausgabeordner sehen:
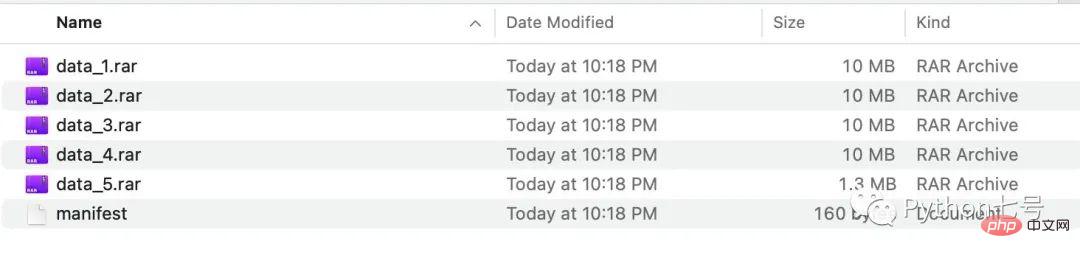
Sie können auch nach der Anzahl der Dateizeilen aufteilen:
split.bylinecount(linecount = 10000) # 每个文件最多 10000 行
Merge
Merge muss kleine Dateien im Ordner zusammenführen. Dieses Tool erfordert, dass sich eine Manifestdatei im Ordner befindet. Ihr Format ist wie folgt:
filename,filesize,header data_1.rar,10000000,False data_2.rar,10000000,False data_3.rar,10000000,False data_4.rar,10000000,False data_5.rar,1304145,False
Der Code zum Zusammenführen der Dateien muss nur das Verzeichnis angeben zusammengeführt werden und das Zielverzeichnis, der Name der zusammengeführten Datei, der Code lautet wie folgt:
from filesplit.merge import Merge merge = Merge(inputdir = "./output", outputdir="./merge", outputfilename = "merged.rar") merge.merge()
Nach der Ausführung können Sie die zusammengeführte Datei im Zusammenführungsverzeichnis sehen:
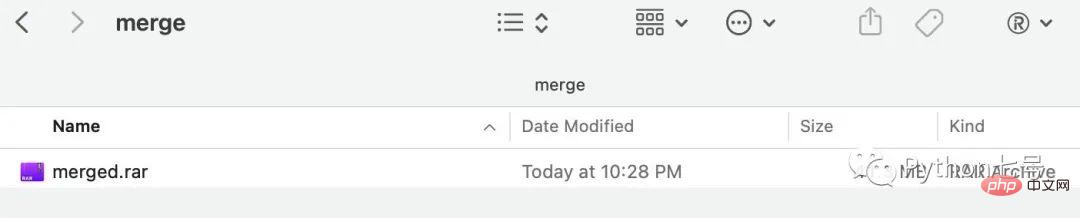
Das obige ist der detaillierte Inhalt vonPython-Tutorial: Wie teile ich große Dateien mit Python auf und füge sie zusammen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So überwachen Sie den HDFS -Status auf CentOs
Apr 14, 2025 pm 07:33 PM
So überwachen Sie den HDFS -Status auf CentOs
Apr 14, 2025 pm 07:33 PM
Es gibt viele Möglichkeiten, den Status von HDFs (Hadoop Distributed Dateisystem) auf CentOS -Systemen zu überwachen. In diesem Artikel werden mehrere häufig verwendete Methoden eingeführt, mit denen Sie die am besten geeignete Lösung auswählen können. 1. Verwenden Sie Hadoops eigenes Webui, Hadoops eigene Weboberfläche, um die Überwachungsfunktion der Cluster -Status zu ermöglichen. Schritte: Stellen Sie sicher, dass der Hadoop -Cluster in Betrieb ist. Greifen Sie in Ihrem Browser auf das Webui zu: Geben Sie http: //: 50070 (Hadoop2.x) oder http: //: 9870 (Hadoop3.x) ein. Der Standard -Benutzername und das Passwort sind normalerweise HDFS/HDFs. 2. Die Überwachung des Befehlszeilenwerkzeugs Hadoop bietet eine Reihe von Befehlszeilen -Tools, um die Überwachung zu erleichtern
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
