

Das verteilte Cache-System ist ein unverzichtbarer Bestandteil der Three-High-Architektur, was die Parallelität und Reaktionsgeschwindigkeit des gesamten Projekts erheblich verbessert, aber auch neue Probleme mit sich bringt, die gelöst werden müssen, nämlich: Cache-Verschleiß Penetration, Cache-Ausfall, Cache-Lawine und Cache-Konsistenzprobleme.
Das erste große Problem ist die Cache-Penetration. Dieses Konzept ist leichter zu verstehen und hängt mit der Trefferquote zusammen. Wenn die Trefferquote niedrig ist, konzentriert sich der Druck auf die Datenbankpersistenzschicht.
Wenn wir relevante Daten finden, können wir sie zwischenspeichern. Das Problem besteht jedoch darin, dass diese Anforderung den Cache oder die Persistenzschicht nicht erreicht hat. Diese Situation wird als Cache-Penetration bezeichnet.
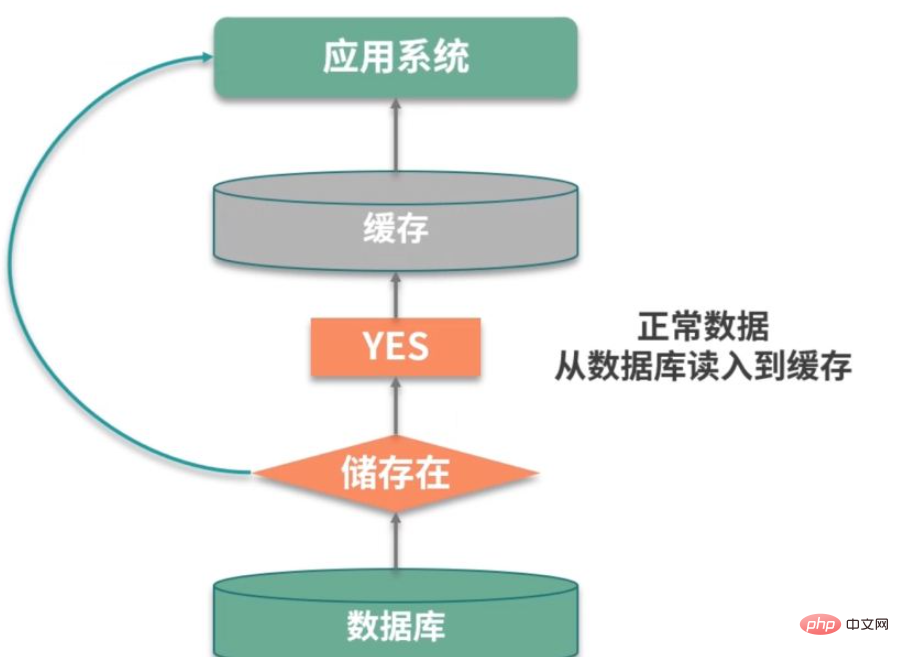
Zum Beispiel gibt es in einem Anmeldesystem, wie oben gezeigt, externe Angriffe und es wird ständig versucht, sich mit nicht vorhandenen Benutzern anzumelden. Diese Benutzer sind virtuell und können nicht jedes Mal effektiv zwischengespeichert werden. Sie werden jedes Mal in der Datenbank abgefragt, was letztendlich zu Leistungsausfällen des Dienstes führt.
Es gibt viele Lösungen für dieses Problem. Lassen Sie uns sie kurz vorstellen.
Die erste besteht darin, leere Objekte zwischenzuspeichern. Liegt es nicht daran, dass die Persistenzschicht die Daten nicht finden kann? Dann können wir das Ergebnis dieser Anfrage auf null setzen und in den Cache legen. Durch Festlegen einer angemessenen Ablaufzeit kann die Sicherheit der Back-End-Datenbank gewährleistet werden.
Das Zwischenspeichern leerer Objekte belegt zusätzlichen Cache-Speicherplatz und es entsteht ein Zeitfenster für Dateninkonsistenzen. Daher besteht die zweite Methode darin, Bloom-Filter für die Verarbeitung großer Datenmengen und regulärer Schlüsselwerte zu verwenden .
Das Vorhandensein oder Nichtvorhandensein eines Datensatzes ist ein Bool-Wert, der mit nur 1 Bit gespeichert werden kann. Bloom-Filter können diese Ja- und Nein-Operation in eine Datenstruktur komprimieren. Beispielsweise eignen sich Daten wie Mobiltelefonnummer und Benutzergeschlecht sehr gut für die Verwendung von Bloom-Filtern.
Cache-Ausfall bezieht sich auch auf die Situation, in der Benutzeranfragen in der Datenbank landen. In den meisten Fällen wird dies durch den Stapelablauf der Cache-Zeit verursacht.
Wir legen im Allgemeinen eine Ablaufzeit für die Daten im Cache fest. Wenn zu einem bestimmten Zeitpunkt eine große Datenmenge aus der Datenbank abgerufen wird und dieselbe Ablaufzeit festgelegt ist, laufen diese gleichzeitig ab, was zu einem Cache-Ausfall führt.
Für Hot-Daten können wir festlegen, dass sie beim Zugriff nicht ablaufen; oder Cache-Elemente, die in Stapeln importiert werden, sollten auch versuchen, eine durchschnittlichere Ablaufzeit zuzuweisen, um Fehler zu vermeiden zur gleichen Zeit.
Das Wort Lawine sieht beängstigend aus, aber die tatsächliche Situation ist tatsächlich ernster. Caching wird verwendet, um das System zu beschleunigen, und die Back-End-Datenbank ist nur eine Datensicherung und keine Alternative für hohe Verfügbarkeit.
Wenn das Cache-System ausfällt, wird der Datenverkehr sofort an die Back-End-Datenbank übertragen. Bald wird die Datenbank durch den starken Datenverkehr überlastet sein und sich aufhängen. Dieser kaskadierende Dienstausfall kann treffend als Lawine bezeichnet werden.
Der Aufbau des Caches mit hoher Verfügbarkeit ist sehr wichtig. Redis bietet Master-Slave- und Cluster-Modi. Der Cluster-Modus ist einfach zu verwenden und jeder Shard kann auch unabhängig als Master-Slave fungieren, was eine extrem hohe Verfügbarkeit gewährleistet.
Zusätzlich haben wir eine allgemeine Einschätzung des Leistungsengpasses der Datenbank. Wenn das Cache-System abstürzt, können Sie die Strombegrenzungskomponente verwenden, um an die Datenbank fließende Anforderungen abzufangen.
Nach der Einführung der Cache-Komponente besteht ein weiteres schwieriges Problem in der Cache-Konsistenz.
Schauen wir uns zunächst an, wie das Problem auftritt. Für ein Cache-Element gibt es vier häufig verwendete Vorgänge: Schreiben, Aktualisieren, Lesen und Löschen.
Schreiben: Der Cache und die Datenbank sind zwei unterschiedliche Komponenten, solange es um doppeltes Schreiben geht, besteht die Möglichkeit, dass nur einer der Schreibvorgänge erfolgreich ist, was dazu führt Dateninkonsistenz.
Update: Die Update-Situation ist ähnlich und es müssen zwei verschiedene Komponenten aktualisiert werden.
Lesen: Lesen, um sicherzustellen, dass die aus dem Cache gelesenen Informationen aktuell sind und mit denen in der Datenbank übereinstimmen.
Löschen: Wie lösche ich beim Löschen von Datenbankeinträgen die Daten im Cache?
Denn Geschäftslogik ist in den meisten Fällen relativ komplex. Die Aktualisierungsvorgänge sind sehr kostspielig. Beispielsweise ist der Kontostand eines Benutzers eine Zahl, die durch die Berechnung einer Reihe von Vermögenswerten berechnet wird. Wenn diese zugehörigen Assets den Cache jedes Mal aktualisieren müssen, wenn sie geändert werden, wird die Codestruktur sehr verwirrend und unmöglich zu pflegen.
Ich empfehle die Verwendung der Methode der ausgelösten Cache-Konsistenz. Die Verwendung der Lazy-Loading-Methode kann die Cache-Synchronisierung sehr einfach machen:
Wenn sich die mit dem Cache-Element verbundenen Ressourcen ändern, wird zuerst das entsprechende Cache-Element gelöscht, dann wird die Ressource in der Datenbank aktualisiert und schließlich wird das entsprechende Cache-Element gelöscht.
Neben dem einfachen Programmiermodell hat dieser Vorgang einen offensichtlichen Vorteil. Ich lade diesen Cache nur dann in das Cache-System, wenn ich ihn verwende. Wenn bei jeder Änderung Ressourcen erstellt und aktualisiert werden, befinden sich viele kalte Daten im Cache-System. Dadurch wird tatsächlich das Cache-Aside-Muster implementiert, das bei Bedarf Daten aus dem Datenspeicher in den Cache lädt. Der größte Effekt besteht darin, die Leistung zu verbessern und unnötige Abfragen zu reduzieren.
Aber es gibt immer noch Probleme damit. Das als nächstes vorgestellte Szenario ist auch eine häufig in Interviews gestellte Frage.
Die oben erwähnte Datenbankaktualisierungsaktion und Cache-Löschaktion befinden sich offensichtlich nicht in derselben Transaktion. Dies kann dazu führen, dass der Inhalt der Datenbank und der Inhalt im Cache während des Aktualisierungsvorgangs inkonsistent sind.
Solange Sie im Vorstellungsgespräch auf diese Frage hinweisen, hebt der Interviewer den Daumen.
Sie können verteilte Sperren verwenden, um dieses Problem zu lösen. Sie können Sperren verwenden, um Datenbankvorgänge und Cache-Vorgänge von anderen Cache-Lesevorgängen zu isolieren. Im Allgemeinen muss der Lesevorgang nicht gesperrt werden. Wenn er auf eine Sperre stößt, wird er erneut versucht und gewartet, bis das Zeitlimit überschritten wird.
Das obige ist der detaillierte Inhalt vonWas sind die vier Hauptprobleme, die das verteilte Java-Cache-System lösen muss?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



