
 Technologie-Peripheriegeräte
KI
Von U-Net zu DiT: Anwendung der Transformatortechnologie im Dominanzdiffusionsmodell
Technologie-Peripheriegeräte
KI
Von U-Net zu DiT: Anwendung der Transformatortechnologie im Dominanzdiffusionsmodell
Von U-Net zu DiT: Anwendung der Transformatortechnologie im Dominanzdiffusionsmodell

In den letzten Jahren erlebt maschinelles Lernen, angetrieben durch Transformer, eine Renaissance. In den letzten fünf Jahren wurden neuronale Architekturen für die Verarbeitung natürlicher Sprache, Computer Vision und andere Bereiche weitgehend von Transformatoren dominiert.
Es gibt jedoch viele generative Modelle auf Bildebene, die von diesem Trend noch nicht betroffen sind. Beispielsweise haben Diffusionsmodelle im vergangenen Jahr erstaunliche Ergebnisse bei der Bildgenerierung erzielt, und fast alle dieser Modelle verwenden Faltungs-U-. Netz als Rückgrat. Das ist etwas überraschend! Die große Geschichte im Deep Learning der letzten Jahre war die Dominanz von Transformer in allen Bereichen. Gibt es etwas Besonderes an U-Net oder Faltungen, das sie in Diffusionsmodellen so gut funktionieren lässt?
Die Forschung, die das U-Net-Backbone-Netzwerk erstmals in das Diffusionsmodell einführte, geht auf Ho et al. zurück. Dieses Entwurfsmuster erbt das autoregressive generative Modell PixelCNN++ mit nur geringfügigen Änderungen. PixelCNN++ besteht aus Faltungsschichten, die viele ResNet-Blöcke enthalten. Im Vergleich zum Standard-U-Net wird der zusätzliche räumliche Selbstaufmerksamkeitsblock von PixelCNN++ zu einer Grundkomponente im Transformator. Im Gegensatz zu den Studien anderer eliminieren Dhariwal und Nichol et al. mehrere Architekturoptionen von U-Net, beispielsweise die Verwendung adaptiver Normalisierungsschichten, um Zustandsinformationen und Kanalzahlen in die Faltungsschichten einzufügen.
In diesem Artikel haben William Peebles von der UC Berkeley und Xie Senin von der New York University „Skalierbare Diffusionsmodelle mit Transformatoren“ geschrieben. Ziel ist es, die Bedeutung architektonischer Entscheidungen in Diffusionsmodellen aufzudecken und eine empirische Grundlage für zukünftige generative Modelle bereitzustellen Modellforschung. Diese Studie zeigt, dass die induktive Vorspannung von U-Net für die Leistung von Diffusionsmodellen nicht entscheidend ist und leicht durch Standarddesigns wie Transformatoren ersetzt werden kann.
Diese Erkenntnis zeigt, dass Diffusionsmodelle von Trends zur Architekturvereinheitlichung profitieren können. Beispielsweise können Diffusionsmodelle Best Practices und Trainingsmethoden aus anderen Bereichen übernehmen und dabei die Skalierbarkeit, Robustheit und Effizienz dieser Modelle beibehalten. Eine standardisierte Architektur wird auch neue Möglichkeiten für die domänenübergreifende Forschung eröffnen.

- Papieradresse: https://arxiv.org/pdf/2212.09748.pdf
- Projektadresse: https://github.com/facebookresearch/DiT
- Paper-Homepage: https://www.wpeebles.com/DiT
Diese Forschung konzentriert sich auf eine neue Art transformatorbasierter Diffusionsmodelle: Diffusion Transformers (kurz: DiTs). DiTs folgen den Best Practices von Vision Transformers (ViTs), mit einigen kleinen, aber wichtigen Anpassungen. Es hat sich gezeigt, dass DiT effizienter skaliert als herkömmliche Faltungsnetzwerke wie ResNet.
In diesem Artikel wird insbesondere das Skalierungsverhalten von Transformer im Hinblick auf Netzwerkkomplexität und Probenqualität untersucht. Die Studie zeigt, dass es durch die Konstruktion und das Benchmarking des DiT-Designraums im Rahmen des Latent Diffusion Model (LDM)-Frameworks, bei dem das Diffusionsmodell innerhalb des Latentraums von VAE trainiert wird, möglich ist, das U-Net-Backbone erfolgreich durch einen Transformator zu ersetzen. Dieses Papier zeigt außerdem, dass DiT eine skalierbare Architektur für Diffusionsmodelle ist: Es besteht eine starke Korrelation zwischen der Netzwerkkomplexität (gemessen durch Gflops) und der Probenqualität (gemessen durch FID). Durch einfaches Erweitern von DiT und Trainieren eines LDM mit einem Backbone mit hoher Kapazität (118,6 Gflops) werden hochmoderne Ergebnisse von 2,27 FID auf dem klassenbedingten 256 × 256 ImageNet-Generierungsbenchmark erzielt.
Diffusion Transformers
DiTs ist eine neue Architektur für Diffusionsmodelle, die darauf abzielt, der Standardtransformatorarchitektur so treu wie möglich zu bleiben, um deren Skalierbarkeit beizubehalten. DiT behält viele der Best Practices von ViT bei und Abbildung 3 zeigt die vollständige DiT-Architektur. Die Eingabe für
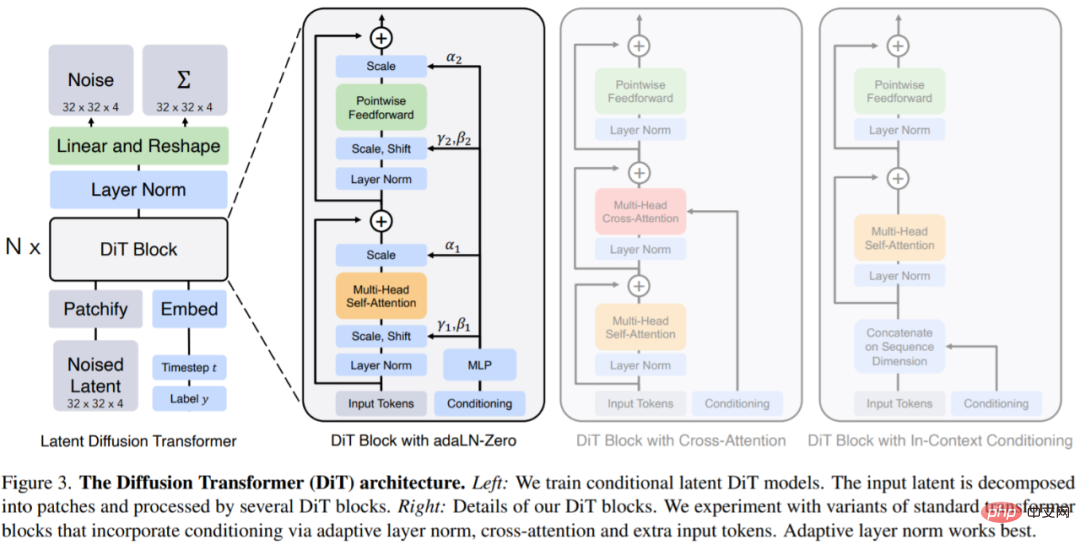
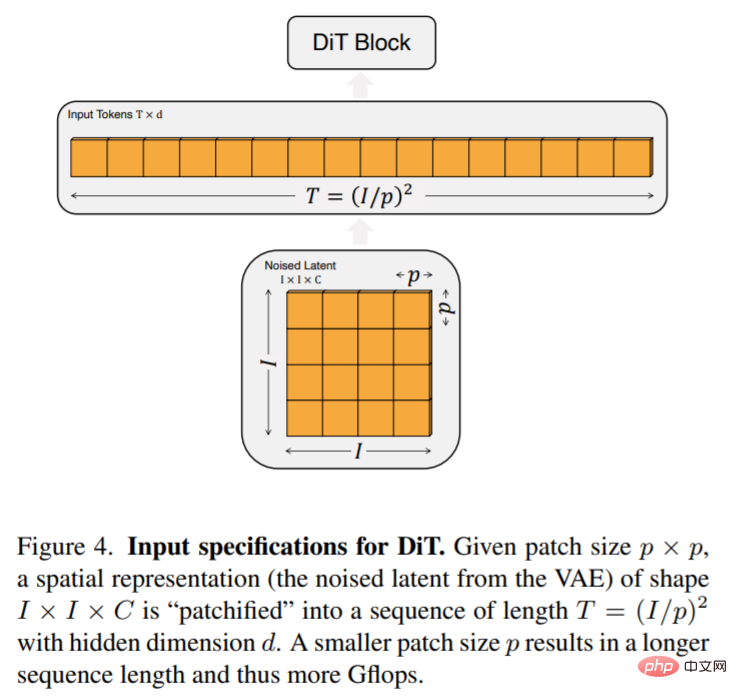
DiT ist die räumliche Darstellung z (für ein 256 × 256 × 3-Bild beträgt die Form von z 32 × 32 × 4). Die erste Ebene von DiT ist Patchify, das die räumliche Eingabe in eine Folge von T-Tokens umwandelt, indem jedes Patch linear in die Eingabe eingebettet wird. Nach dem Patchify wenden wir standardmäßige frequenzbasierte Positionseinbettungen von ViT auf alle Eingabe-Tokens an.
Die Anzahl der von Patchify erstellten Token T wird durch den Patch-Size-Hyperparameter p bestimmt. Wie in Abbildung 4 dargestellt, vervierfacht die Halbierung von p T und vervierfacht daher mindestens die Gflops des Transformators. Dieser Artikel fügt p = 2,4,8 zum DiT-Designraum hinzu.
DiT-Blockdesign: Nach dem Patchify wird das Eingabetoken von einer Reihe von Transformatorblöcken verarbeitet. Zusätzlich zur verrauschten Bildeingabe verarbeiten Diffusionsmodelle manchmal zusätzliche bedingte Informationen, wie z. B. Rauschzeitschritt t, Klassenbezeichnung c, natürliche Sprache usw. In diesem Artikel werden vier Transformatorblockvarianten untersucht, die bedingte Eingaben auf unterschiedliche Weise verarbeiten. Diese Designs weisen geringfügige, aber wesentliche Änderungen am Standard-ViT-Blockdesign auf. Der Aufbau aller Module ist in Abbildung 3 dargestellt.
In diesem Artikel wurden vier Konfigurationen ausprobiert, die je nach Modelltiefe und -breite variieren: DiT-S, DiT-B, DiT-L und DiT-XL. Diese Modellkonfigurationen reichen von 33M bis 675M Parametern und Gflops von 0,4 bis 119.
Experiment
Die Forscher trainierten vier DiT-XL/2-Modelle mit den höchsten Gflops, wobei jedes ein anderes Blockdesign verwendete – In-Context (119,4 Gflops), Cross-Attention (137,6 Gflops), adaptive Layer-Norm (adaLN). , 118,6Gflops) oder adaLN-null (118,6Gflops). Anschließend wurde der FID während des Trainings gemessen und Abbildung 5 zeigt die Ergebnisse.
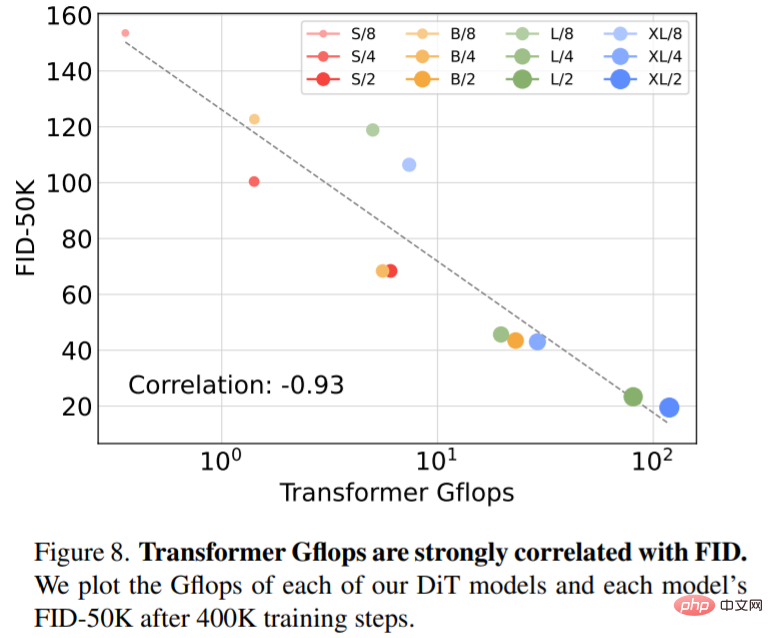
Erweiterte Modellgröße und Patchgröße. Abbildung 2 (links) gibt einen Überblick über die Gflops für jedes Modell und ihren FID bei 400.000 Trainingsiterationen. Es ist ersichtlich, dass eine Vergrößerung der Modellgröße und eine Verringerung der Patchgröße erhebliche Verbesserungen im Diffusionsmodell bewirken.
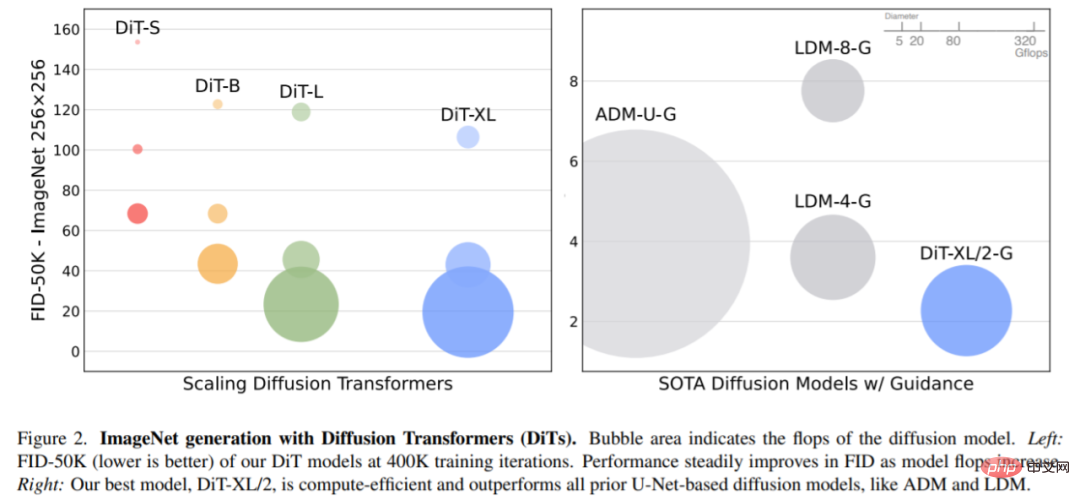
Abbildung 6 (oben) zeigt, wie sich FID ändert, wenn die Modellgröße zunimmt und die Patchgröße konstant gehalten wird. Über alle vier Einstellungen hinweg werden in allen Trainingsphasen erhebliche Verbesserungen der FID erzielt, indem der Transformer tiefer und breiter gemacht wird. In ähnlicher Weise zeigt Abbildung 6 (unten) den FID, wenn die Patchgröße reduziert wird und die Modellgröße konstant bleibt. Die Forscher stellten erneut fest, dass sich FID erheblich verbesserte, indem einfach die Anzahl der von DiT verarbeiteten Token erhöht und die Parameter während des gesamten Trainingsprozesses grob beibehalten wurden.
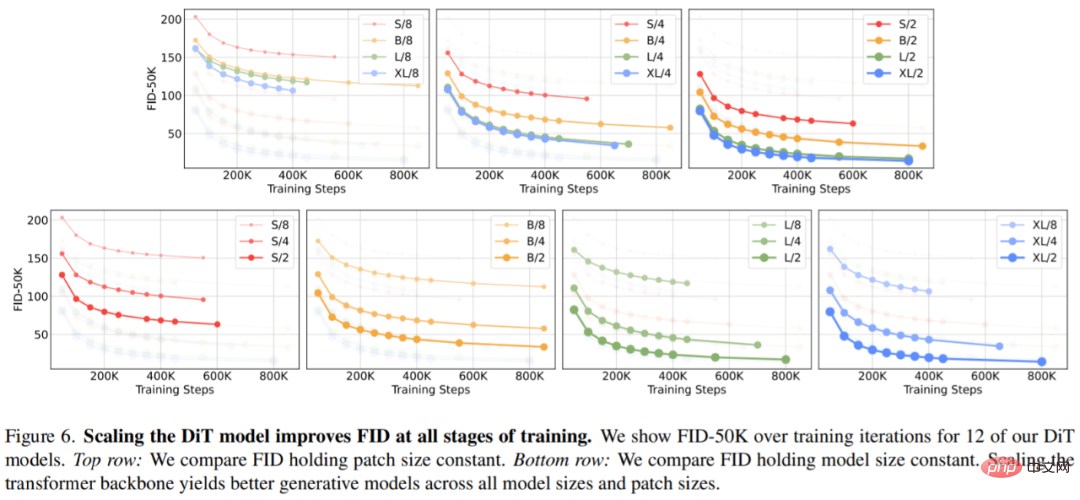
Abbildung 8 zeigt den Vergleich von FID-50K mit Modell-Gflops bei 400.000 Trainingsschritten:
SOTA-Diffusionsmodell 256×256 ImageNet. Nach der erweiterten Analyse trainierten die Forscher weiterhin das Modell mit dem höchsten Gflop, DiT-XL/2, mit einer Schrittzahl von 7 Millionen. Abbildung 1 zeigt ein Beispiel dieses Modells und vergleicht es mit dem SOTA-Modell zur kategoriebedingten Generierung. Die Ergebnisse sind in Tabelle 2 aufgeführt.

Bei Verwendung einer klassifikatorfreien Führung übertrifft DiT-XL/2 alle vorherigen Diffusionsmodelle und reduziert den bisher besten FID-50K von 3,60, der von LDM erreicht wurde, auf 2,27. Wie in Abbildung 2 (rechts) dargestellt, ist DiT-XL/2 (118,6 Gflops) im Vergleich zu U-Net-Modellen mit latentem Raum wie LDM-4 (118,6 Gflops) viel recheneffizienter als ADM (1120 Gflops). ADM-U (742 Gflops), Pixelraum-U-Net-Modelle sind viel effizienter.
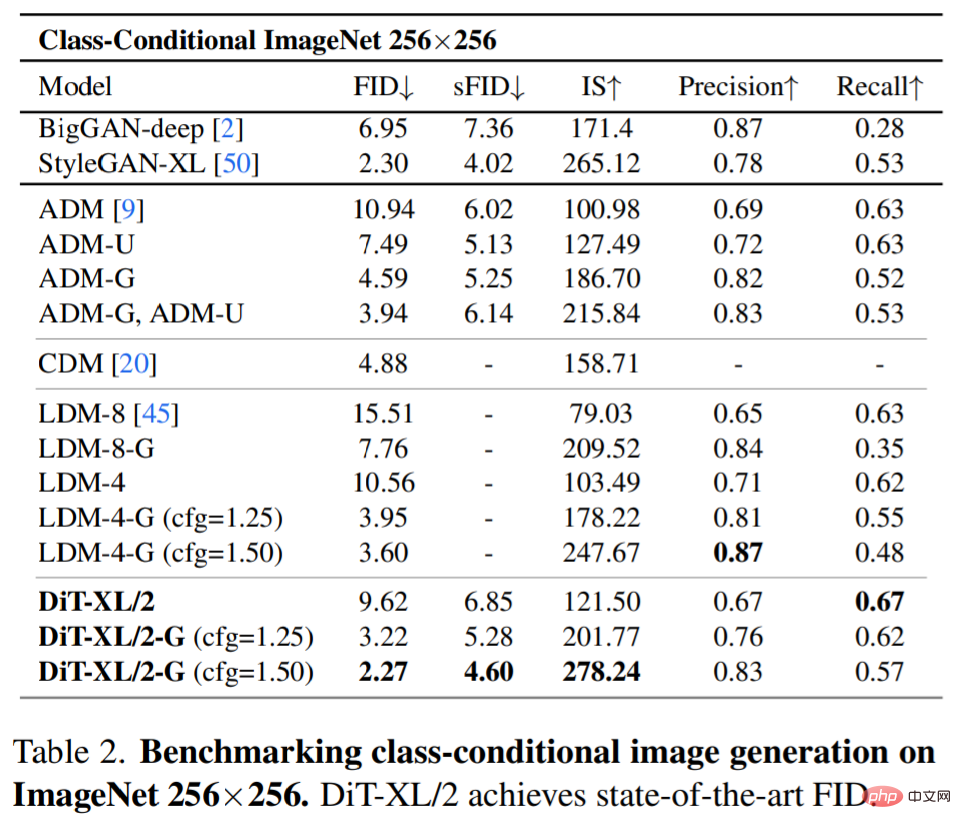
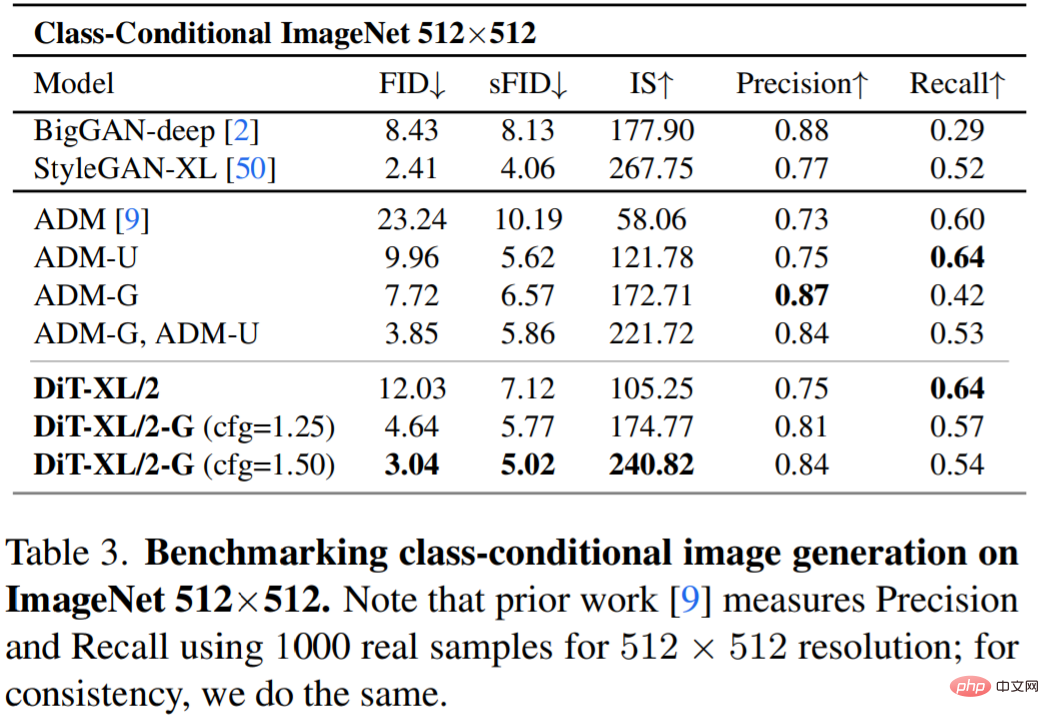
Tabelle 3 zeigt den Vergleich mit SOTA-Methoden. XL/2 übertrifft bei dieser Auflösung erneut alle bisherigen Diffusionsmodelle und verbessert den bisher besten FID von ADM von 3,85 auf 3,04.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonVon U-Net zu DiT: Anwendung der Transformatortechnologie im Dominanzdiffusionsmodell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
Eine vollständige Anleitung zum Anzeigen von GitLab -Protokollen unter CentOS -System In diesem Artikel wird in diesem Artikel verschiedene GitLab -Protokolle im CentOS -System angezeigt, einschließlich Hauptprotokolle, Ausnahmebodi und anderen zugehörigen Protokollen. Bitte beachten Sie, dass der Log -Dateipfad je nach GitLab -Version und Installationsmethode variieren kann. Wenn der folgende Pfad nicht vorhanden ist, überprüfen Sie bitte das GitLab -Installationsverzeichnis und die Konfigurationsdateien. 1. Zeigen Sie das Hauptprotokoll an. Verwenden Sie den folgenden Befehl, um die Hauptprotokolldatei der GitLabRails-Anwendung anzuzeigen: Befehl: Sudocat/var/log/gitlab/gitlab-rails/production.log Dieser Befehl zeigt das Produkt an
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
