

Absatzsortierung ist ein sehr wichtiges und herausforderndes Thema im Bereich des Informationsabrufs und hat in Wissenschaft und Industrie große Aufmerksamkeit erhalten. Die Wirksamkeit des Absatz-Ranking-Modells kann die Zufriedenheit der Suchmaschinennutzer verbessern und beim Informationsabruf bezogene Anwendungen wie Frage- und Antwortsysteme, Leseverständnis usw. unterstützen. In diesem Zusammenhang wurden einige Benchmark-Datensätze wie MS-MARCO, DuReader_retrieval usw. erstellt, um entsprechende Forschungsarbeiten zur Absatzsortierung zu unterstützen. Die meisten häufig verwendeten Datensätze konzentrieren sich jedoch auf englische Szenen. Bei chinesischen Szenen weisen die vorhandenen Datensätze Einschränkungen hinsichtlich der Datenskala, der feinkörnigen Benutzeranmerkung und der Lösung des Problems falsch negativer Beispiele auf. In diesem Zusammenhang haben wir einen neuen Benchmark-Datensatz für das chinesische Absatzranking erstellt, der auf echten Suchprotokollen basiert: T2Ranking.
T2Das Ranking setzt sich aus über 300.000 echten Suchanfragen und 2 Millionen Internetabsätzen zusammen. Und Es umfasst eine 4-stufige, feinkörnige Korrelationsannotation, die von professionellen Annotatoren bereitgestellt wird. Die aktuellen Daten und einige Basismodelle wurden auf Github veröffentlicht und die relevanten Forschungsarbeiten wurden von SIGIR 2023 als Ressourcenpapier akzeptiert.
Zur Unterstützung der Absatzsortieraufgabe werden mehrere Datensätze zum Trainieren und Testen von Absatzsortieralgorithmen erstellt. Die meisten der am häufigsten verwendeten Datensätze konzentrieren sich auf englische Szenarien. Der am häufigsten verwendete Datensatz ist beispielsweise der MS-MARCO-Datensatz, der mehr als 500.000 Abfragebegriffe und mehr als 8 Millionen Absätze enthält. Für jeden Abfragebegriff rekrutierte das MS-MARCO-Datenfreigabeteam Annotatoren, die Standardantworten bereitstellen. Basierend darauf, ob ein bestimmter Absatz die manuell bereitgestellten Standardantworten enthält, wird beurteilt, ob dieser Absatz mit dem Abfragebegriff zusammenhängt.
Im chinesischen Szenario gibt es auch einige Datensätze, die zur Unterstützung von Absatzsortierungsaufgaben erstellt wurden. Beispielsweise ist mMarco-Chinesisch die chinesische Übersetzungsversion des MS-MARCO-Datensatzes, und der DuReader_retrieval-Datensatz verwendet dasselbe Paradigma wie MS-MARCO, um Absatzbeschriftungen zu generieren, dh die Korrelation des Abfragewort-Absatz-Paares gegeben aus den von Menschen bereitgestellten Standardantworten. Das Multi-CPR-Modell enthält Absatzabrufdaten aus drei verschiedenen Bereichen (E-Commerce, Unterhaltungsvideos und Medizin). Basierend auf den Protokolldaten der Sogou-Suche wurden auch Datensätze wie Sogou-SRR, Sogou-QCL und Tiangong-PDR vorgeschlagen.
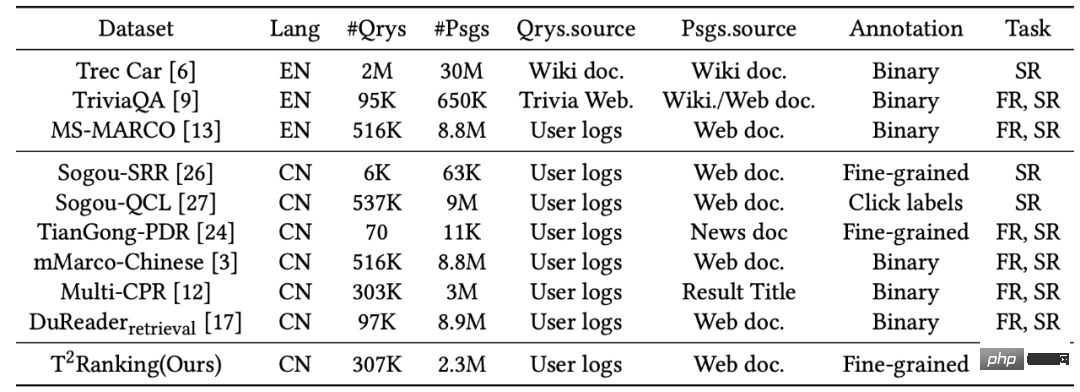
Abbildung 1: Statistik häufig verwendeter Datensätze in Absatzsortieraufgaben# 🎜 🎜#Obwohl vorhandene Datensätze die Entwicklung von Anwendungen zum Sortieren von Absätzen gefördert haben, müssen wir auch einige Einschränkungen beachten: # 🎜🎜#
1) Diese Datensätze sind nicht umfangreich oder die Relevanzbezeichnungen werden nicht manuell mit Anmerkungen versehen, insbesondere im chinesischen Szenario. Sogou-SRR und Tiangong-PDR enthalten nur eine kleine Menge an Abfragedaten. Obwohl mMarco-Chinesisch und Sogou-QCL einen größeren Umfang haben, basiert ersteres auf maschineller Übersetzung und letzteres verwendet Relevanzbezeichnungen als Benutzerklickdaten. Kürzlich wurden zwei relativ große Datensätze, Multi-CPR und DuReader_retrieval, erstellt und veröffentlicht.
2) Vorhandene Datensätze verfügen nicht über feinkörnige Korrelationsannotationsinformationen. Die meisten Datensätze verwenden binäre Korrelationsannotationen (grobkörnig), dh relevant oder irrelevant. Bestehende Arbeiten haben gezeigt, dass feinkörnige Korrelationsannotationsinformationen dabei helfen können, die Beziehungen zwischen verschiedenen Entitäten zu ermitteln und genauere Ranking-Algorithmen zu erstellen. Dann gibt es vorhandene Datensätze, die keine oder nur eine geringe Menge an feinkörnigen Anmerkungen auf mehreren Ebenen bereitstellen. Beispielsweise bieten Sogou-SRR oder Tiangong-PDR nur feinkörnige Anmerkungen mit maximal 100.000.
3) Das Problem falsch negativer Beispiele beeinträchtigt die Genauigkeit der Bewertung. Bestehende Datensätze sind vom Problem falsch negativer Beispiele betroffen, bei dem eine große Anzahl relevanter Dokumente als irrelevant markiert wird. Dieses Problem wird durch die geringe Anzahl manueller Anmerkungen in großen Datenmengen verursacht, die die Genauigkeit der Auswertung erheblich beeinträchtigen. Beispielsweise wird in Multi-CPR für jeden Suchbegriff nur ein Absatz als relevant markiert, während die anderen als irrelevant markiert werden. DuReader_retrieval versucht, das Problem falsch-negativer Ergebnisse zu lindern, indem der Annotator den ersten Satz von Absätzen manuell prüfen und erneut kommentieren lässt.
Um Absatzsortierungsmodelle für qualitativ hochwertige Schulung und Bewertung besser zu unterstützen, haben wir einen neuen Benchmark-Datensatz zum Abrufen chinesischer Absätze erstellt und veröffentlicht – T# 🎜🎜# 2Ranking.
DatensatzkonstruktionsprozessDer Datensatzkonstruktionsprozess umfasst Abfragewort-Sampling, Dokumentenabruf, Absatzextraktion und feinkörnige Relevanzanmerkung. Gleichzeitig haben wir auch mehrere Methoden entwickelt, um die Qualität des Datensatzes zu verbessern, einschließlich der Verwendung modellbasierter Absatzsegmentierungsmethoden und Clustering-basierter Absatzdeduplizierungsmethoden, um die semantische Integrität und Vielfalt der Absätze sicherzustellen, sowie die Verwendung aktiver Lernmethoden. basierte Annotationsmethoden zur Verbesserung der Effizienz und Qualität der Annotation usw.
1) Gesamtprozess
Abbildung 2: Beispiel einer Wikipedia-Seite. Das vorgelegte Dokument enthält klar definierte Absätze.
2) Modellbasierte Methode zur Absatzsegmentierung
In vorhandenen Datensätzen werden Absätze in der Regel anhand natürlicher Absätze (Zeilenumbrüche) oder durch Schiebefenster mit fester Länge aus Dokumenten segmentiert. Beide Methoden können jedoch dazu führen, dass Absätze semantisch unvollständig oder zu lang sind und mehrere unterschiedliche Themen enthalten. In dieser Arbeit haben wir eine modellbasierte Methode zur Absatzsegmentierung übernommen. Als Trainingsdaten haben wir insbesondere die Sogou-Enzyklopädie, die Baidu-Enzyklopädie und die chinesische Wikipedia verwendet, da die Struktur dieses Teils des Dokuments relativ klar ist und auch die natürlichen Absätze erhalten werden eine bessere Definition. Wir haben ein Segmentierungsmodell trainiert, um zu bestimmen, ob ein bestimmtes Wort ein Segmentierungspunkt sein muss. Wir haben die Idee von Sequenzmarkierungsaufgaben genutzt und das letzte Wort jedes natürlichen Segments als positives Beispiel zum Trainieren des Modells verwendet. 3) Auf Clustering basierende Methode zur Deduplizierung von Absätzen Basierend auf der Methode zur Deduplizierung von Absätzen, um die Effizienz der Anmerkung zu verbessern. Insbesondere verwenden wir Ward, einen hierarchischen Clustering-Algorithmus, um ein unbeaufsichtigtes Clustering ähnlicher Dokumente durchzuführen. Absätze in derselben Klasse gelten als sehr ähnlich, und wir stichprobenartig einen Absatz aus jeder Klasse zur Relevanzanmerkung. Es ist zu beachten, dass wir diesen Vorgang nur am Trainingssatz durchführen. Für den Testsatz werden wir alle extrahierten Absätze vollständig mit Anmerkungen versehen, um die Auswirkungen falsch negativer Beispiele zu verringern. Abbildung 3: Sampling-Annotation-Prozess basierend auf aktivem Lernen Alle Trainingsbeispiele können die Leistung des Ranking-Modells weiter verbessern. Für Trainingsbeispiele, die das Modell genau vorhersagen kann, ist die Trainingshilfe für nachfolgende Modelle begrenzt. Daher haben wir die Idee des aktiven Lernens übernommen, um dem Modell die Auswahl informativerer Trainingsbeispiele für die weitere Annotation zu ermöglichen. Konkret haben wir zunächst ein auf dem Cross-Encoder-Framework basierendes Neuordnungsmodell für Abfragen trainiert. Anschließend haben wir dieses Modell verwendet, um andere Daten vorherzusagen und übermäßige Konfidenzwerte (Informationsgehalt (niedrig)) zu entfernen Ermitteln Sie einen niedrigen Konfidenzwert (verrauschte Daten), kommentieren Sie die beibehaltenen Absätze weiter und wiederholen Sie diesen Prozess.
DatensatzstatistikT2
Das Ranking besteht aus über 300.000 echten Suchanfragen und 2 Millionen Internetabsätzen. Darunter enthält der Trainingssatz etwa 250.000 Abfragewörter und der Testsatz etwa 50.000 Abfragewörter. Suchbegriffe können bis zu 40 Zeichen lang sein, wobei die durchschnittliche Länge etwa 11 Zeichen beträgt. Gleichzeitig decken die Abfragewörter im Datensatz mehrere Bereiche ab, darunter Medizin, Bildung, E-Commerce usw. Wir haben auch den Diversity Score (ILS) der Abfragewörter berechnet und unsere Abfragevielfalt mit vorhandenen Datensätzen verglichen ist höher. Aus 1,75 Millionen Dokumenten wurden mehr als 2,3 Millionen Absätze ausgewählt, und jedes Dokument war im Durchschnitt in 1,3 Absätze unterteilt. Im Trainingssatz wurden durchschnittlich 6,25 Absätze pro Abfragebegriff manuell mit Anmerkungen versehen, während im Testsatz durchschnittlich 15,75 Absätze pro Abfragebegriff manuell mit Anmerkungen versehen wurden.
Abbildung 4: Domänenverteilung von Abfragewörtern im Datensatz
Abbildung 5: Relevanzannotationsverteilung
Wir haben die Leistung einiger häufig verwendeter Absatzsortierungsmodelle anhand des erhaltenen Datensatzes getestet. Wir haben auch die Leistung vorhandener Absätze in zwei Stufen bewertet des Abrufs und der Neuordnung von Absätzen.
1) Absatz-Recall-Experiment
Vorhandene Absätze Recall-Modelle kann grob in Sparse-Recall-Modelle und Dense-Recall-Modelle unterteilt werden.
BM25: Ein häufig verwendetes Sparse-Recall-Benchmark-Modell.
2) Experiment zur Neuordnung von Absätzen
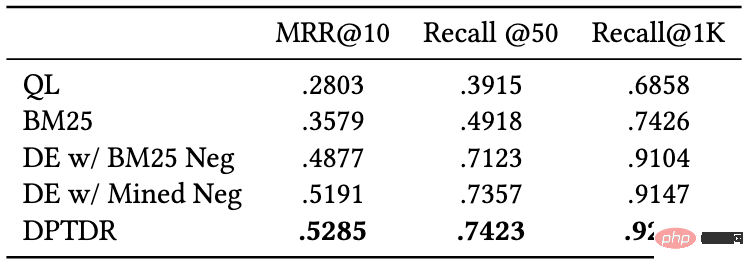
Abbildung 7: Leistung des interaktiven Encoders bei der Aufgabe zur Neuordnung von Absätzen
Die experimentellen Ergebnisse zeigen, dass bei der Twin-Tower-Kodierung eine Neuanordnung auf der Grundlage der von Dual-Encoder abgerufenen Absätze bessere Ergebnisse erzielen kann als eine Neuanordnung auf der Grundlage der von BM25 abgerufenen Absätze steht im Einklang mit den experimentellen Schlussfolgerungen bestehender Arbeiten. Ähnlich wie beim Recall-Experiment ist die Leistung des Reranking-Modells in unserem Datensatz schlechter als in anderen Datensätzen, was möglicherweise an der feinkörnigeren Annotation und der höheren Abfragewortvielfalt unseres Datensatzes liegt ist anspruchsvoll und kann die Modellleistung genauer widerspiegeln.
Der Datensatz wurde gemeinsam von der Information Retrieval Research Group (THUIR) der Fakultät für Informatik der Tsinghua-Universität und dem Team des QQ Browser Search Technology Center von Tencent veröffentlicht und von unterstützt das Tiangong Intelligent Computing Research Institute der Tsinghua-Universität. Die THUIR-Forschungsgruppe konzentriert sich auf die Forschung zu Such- und Empfehlungsmethoden und hat typische Ergebnisse bei der Modellierung des Benutzerverhaltens und erklärbaren Lernmethoden erzielt. Zu den Erfolgen der Forschungsgruppe gehören der WSDM2022 Best Paper Award, der SIGIR2020 Best Paper Nomination Award und der CIKM2018 Best Paper eine Reihe akademischer Auszeichnungen, darunter der erste Preis der Chinesischen Informationsgesellschaft „Qian Weichang Chinese Information Processing Science and Technology Award“ 2020. Das Team des QQ Browser Search Technology Center ist für die Suchtechnologieforschung und -entwicklung der Tencent PCG Information Platform und Service Line verantwortlich. Es stützt sich auf das Content-Ökosystem von Tencent und treibt Produktinnovationen durch Benutzerforschung voran, um Benutzern Grafiken, Informationen, Romane usw. zur Verfügung zu stellen und kurze Videos, Dienstleistungen usw. Der Orientierungsinformationsbedarf wird gedeckt.
Das obige ist der detaillierte Inhalt vonVeröffentlichter Benchmark-Datensatz für die Sortierung chinesischer Absätze: basierend auf 300.000 echten Abfragen und 2 Millionen Internetabsätzen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Verbunden, aber kein Zugriff auf das Internet möglich
Verbunden, aber kein Zugriff auf das Internet möglich
 Erstellen Sie einen Internetserver
Erstellen Sie einen Internetserver
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Der Unterschied zwischen Ankern und Zielen
Der Unterschied zwischen Ankern und Zielen
 Wie viel entspricht Dimensity 6020 Snapdragon?
Wie viel entspricht Dimensity 6020 Snapdragon?
 Was ist der Unterschied zwischen Hardware-Firewall und Software-Firewall?
Was ist der Unterschied zwischen Hardware-Firewall und Software-Firewall?
 0x80070002 Lösung
0x80070002 Lösung
 window.setinterval
window.setinterval
 Was ist USDT?
Was ist USDT?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



