

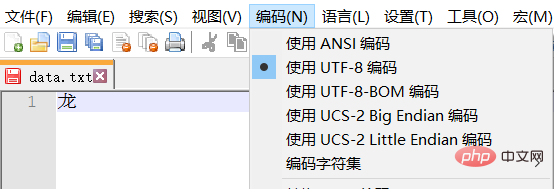
Hinweis: Der Testtext ist in UTF-8 codiert, normalerweise chinesische Zeichen Es belegt drei Bytes. Chinesische Zeichen in GBK belegen normalerweise 2 Bytes.
import os
# 对于单个文件进行操作的函数,如果需要对文件夹进行操作,可以使用一个函数包装它,这样不用修改本函数,即达到扩展的目的了。
def transfer_encode(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='r', errors='ignore', encoding=source_encode) as source_file: # 读取文件时,如果直接忽略报错,则程序正常执行,但是文件已经损坏了。
with open(target_path, mode='w', encoding=target_encode) as target_file: # 所以,应该捕获异常,停止程序执行。
line = source_file.readline()
while line != '':
target_file.write(line)
line = source_file.readline()
print("Execute End!")
# 这个函数的功能和上面是一样的,区别在于它是以二进制读取的,然后解码、转码再写入的
def transfer_encode2(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='rb') as source_file:
with open(target_path, mode="wb") as target_file:
bs = source_file.read(1024)
while len(bs) != 0:
target_file.write(bs.decode(source_encode).encode(target_encode))
bs = source_file.read(1024)
print("Execute End!")
source_path = r'C:\Users\Alfred\Desktop\test_data\test\data.txt'
target_path = r'C:\Users\Alfred\Desktop\test_data\test\data1.txt'
transfer_encode(source_path=source_path, target_path=target_path, source_encode="UTF-8", target_encode="GBK")
# transfer_encode2(source_path=source_path, target_path=target_path)
# 在cmd中使用 type命令,可以查看文件的内容,并且使用cmd默认的编码。
# 使用 chcp 命令可以查看当前使用的编码的数字编号KonsolenausgabeDie Ausgabe dieser Funktionsausführung hat keine Bedeutung. Ich möchte nur wissen, ob es ausgeführt wurde, also drucke ich es aus.

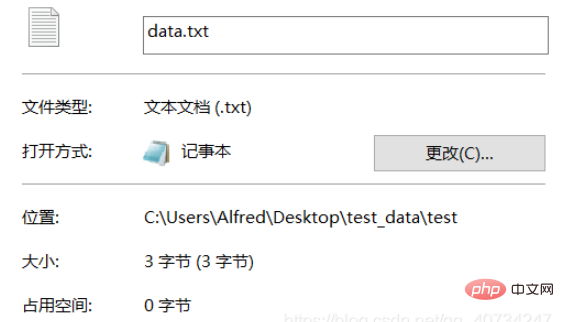
Testordner data1.txt ist der konvertierte und codierte Text.
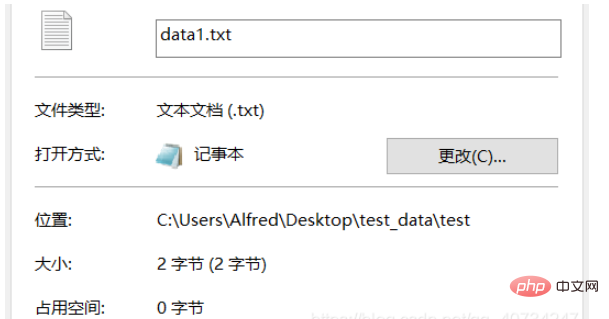
Da die generierte Datei nur ein Wort enthält, vergleichen wir nur die Größe . Erfahren Sie, ob die Konvertierung erfolgreich war. Natürlich ist es auch möglich, es direkt zur Ansicht zu öffnen, aber wenn Sie es direkt zur Ansicht öffnen, hat dies keine Auswirkung und es wird ein chinesisches Schriftzeichen 龙 angezeigt. Hier verfolgen wir also einen anderen Ansatz und verwenden eine andere Betrachtungsmethode!
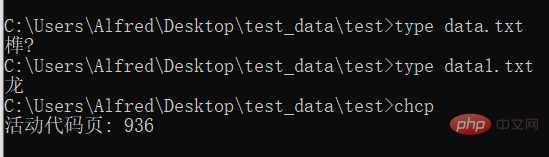
Hinweis: data.txt ist in UTF-8 codiert, während data1.txt in GBK codiert ist. Da das in China verwendete Windows standardmäßig die chinesische Kodierungsmethode übernimmt, kann es keinen UTF-8-kodierten Text anzeigen. Die dritte Ausgabe dient zur Anzeige der aktuell verwendeten Kodierung. Einzelheiten finden Sie in der Abbildung unten:
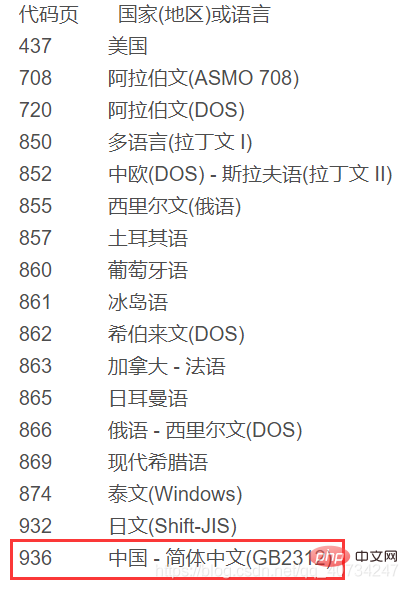
-Zeichen der Funktion einer Übergabestation. Wenn Sie einen Zeichensatz direkt verwenden, um den Inhalt eines anderen Zeichensatzes zu lesen, werden die im obigen Cmd angezeigten verstümmelten Zeichen angezeigt.

Das obige ist der detaillierte Inhalt vonWie kann das Problem der Konvertierung von Textdateien in Python gelöst werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



