

Die Umweltwahrnehmung ist das erste Glied beim autonomen Fahren und die Verbindung zwischen dem Fahrzeug und der Umwelt. Die Gesamtleistung eines autonomen Fahrsystems hängt maßgeblich von der Qualität des Wahrnehmungssystems ab. Derzeit gibt es zwei gängige technische Wege für die Umweltsensorik:
①Vision-geführte Multisensor-Fusionslösung, der typische Vertreter ist Tesla; Lösung, die von anderen Sensoren dominiert wird und von anderen Sensoren unterstützt wird. Typische Vertreter sind Google, Baidu usw.
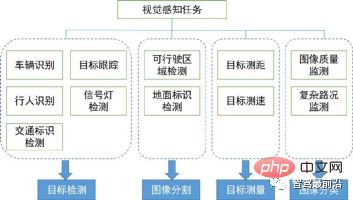
Wir werden die wichtigsten visuellen Wahrnehmungsalgorithmen in der Umgebungswahrnehmung vorstellen. Ihre Aufgabenabdeckung und ihre technischen Bereiche sind in der folgenden Abbildung dargestellt. Im Folgenden betrachten wir den Kontext und die Richtung der visuellen 2D- und 3D-Wahrnehmungsalgorithmen.
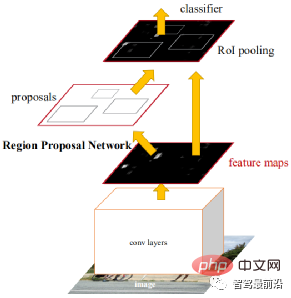
Zwei Stufen Dies bedeutet, dass es zwei Prozesse gibt, um eine Erkennung zu erreichen: Der andere besteht darin, den Objektbereich zu klassifizieren und mit CNN zu identifizieren. Daher wird die „Zweistufe“ auch als Zielerkennung basierend auf der Kandidatenregion bezeichnet (Regionsvorschlag). Repräsentative Algorithmen umfassen die R-CNN-Reihe (R-CNN, Fast R-CNN, Faster R-CNN) usw. Faster R-CNN ist das erste End-to-End-Erkennungsnetzwerk. In der ersten Stufe wird ein Region Proposal Network (RPN) verwendet, um Kandidatenrahmen basierend auf der Feature-Map zu generieren, und ROIPooling wird verwendet, um die Größe der Kandidaten-Features auszurichten. In der zweiten Stufe wird eine vollständig verbundene Ebene zur Verfeinerung verwendet Klassifizierung und Regression.
Die Idee von Anchor wird hier vorgeschlagen, um die Berechnungsschwierigkeit zu verringern und die Geschwindigkeit zu erhöhen. Jede Position der Feature-Map generiert Anker unterschiedlicher Größe und Seitenverhältnisse, die als Referenz für die Objektrahmenregression verwendet werden. Durch die Einführung von Anchor kann die Regressionsaufgabe nur relativ kleine Änderungen verarbeiten, sodass das Lernen im Netzwerk einfacher wird. Die folgende Abbildung ist das Netzwerkstrukturdiagramm von Faster R-CNN.
 Die erste Stufe von CascadeRCNN ist genau die gleiche wie Faster R-CNN, und die zweite Stufe verwendet mehrere RoiHead-Schichten für die Kaskadierung. Die anschließende Arbeit dreht sich größtenteils um einige Verbesserungen des oben genannten Netzwerks oder um eine Ansammlung früherer Arbeiten, mit wenigen bahnbrechenden Verbesserungen.
Die erste Stufe von CascadeRCNN ist genau die gleiche wie Faster R-CNN, und die zweite Stufe verwendet mehrere RoiHead-Schichten für die Kaskadierung. Die anschließende Arbeit dreht sich größtenteils um einige Verbesserungen des oben genannten Netzwerks oder um eine Ansammlung früherer Arbeiten, mit wenigen bahnbrechenden Verbesserungen.
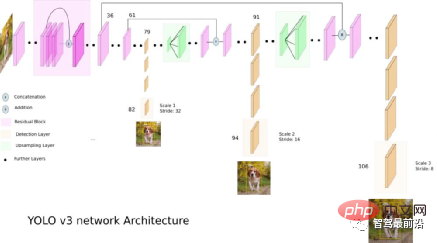
Im Vergleich zum zweistufigen Algorithmus muss der einstufige Algorithmus nur einmal Merkmale extrahieren, um dies zu erreichen Der Geschwindigkeitsalgorithmus ist schneller und weist im Allgemeinen eine etwas geringere Genauigkeit auf. Die Pionierarbeit dieser Art von Algorithmus ist YOLO, das anschließend von SSD und Retinanet verbessert wurde. Das Team, das YOLO vorschlug, integrierte diese Tricks, die zur Verbesserung der Leistung beitragen, in den YOLO-Algorithmus und schlug anschließend vier verbesserte Versionen YOLOv2 bis YOLOv5 vor. Obwohl die Vorhersagegenauigkeit nicht so gut ist wie beim zweistufigen Zielerkennungsalgorithmus, hat sich YOLO aufgrund seiner schnelleren Laufgeschwindigkeit zum Mainstream in der Branche entwickelt. Die folgende Abbildung ist das Netzwerkstrukturdiagramm von YOLO v3.
Diese Art von Methode Im Allgemeinen wird das Objekt als einige Schlüsselpunkte dargestellt, und CNN wird verwendet, um die Positionen dieser Schlüsselpunkte zurückzugeben. Der Schlüsselpunkt kann der Mittelpunkt (CenterNet), Eckpunkt (CornerNet) oder repräsentativer Punkt (RepPoints) des Objektrahmens sein. CenterNet wandelt das Zielerkennungsproblem in ein Mittelpunktvorhersageproblem um, das heißt, es verwendet den Mittelpunkt des Ziels zur Darstellung des Ziels und erhält den rechteckigen Rahmen des Ziels durch Vorhersage des Versatzes, der Breite und der Höhe des Zielmittelpunkts. Heatmap stellt Klassifizierungsinformationen dar und jede Kategorie generiert eine separate Heatmap. Wenn eine bestimmte Koordinate den Mittelpunkt des Ziels enthält, wird für jede Heatmap ein Schlüsselpunkt am Ziel generiert. Wir verwenden einen Gaußschen Kreis, um den gesamten Schlüsselpunkt darzustellen.
 RepPoints schlägt vor, das Objekt als repräsentative Punktmenge darzustellen und sich durch verformbare Faltung an die Formänderungen des Objekts anzupassen. Die Punktmenge wird schließlich in einen Objektrahmen umgewandelt und zur Berechnung der Differenz zur manuellen Annotation verwendet.
RepPoints schlägt vor, das Objekt als repräsentative Punktmenge darzustellen und sich durch verformbare Faltung an die Formänderungen des Objekts anzupassen. Die Punktmenge wird schließlich in einen Objektrahmen umgewandelt und zur Berechnung der Differenz zur manuellen Annotation verwendet.
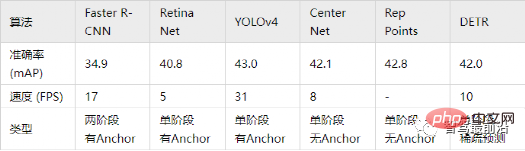
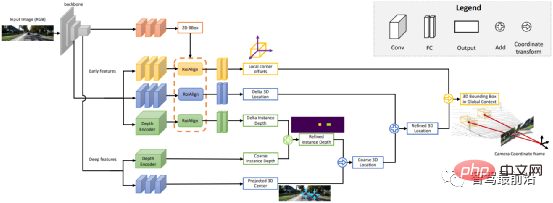
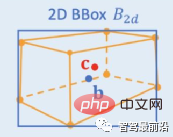
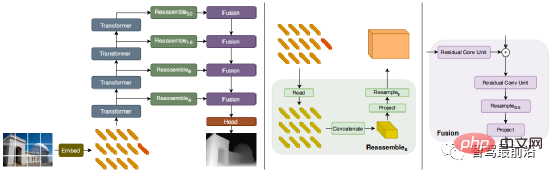
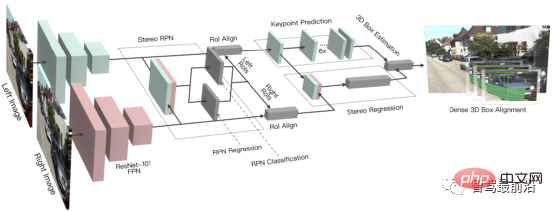
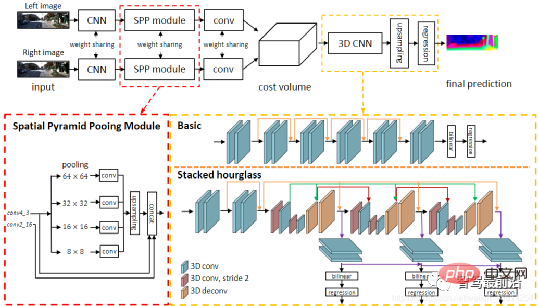
Ob es sich um eine einstufige oder zweistufige Zielerkennung handelt, ob Anker verwendet wird oder nicht, der Aufmerksamkeitsmechanismus wird nicht gut genutzt. Als Reaktion auf diese Situation verwenden Relation Net und DETR Transformer, um den Aufmerksamkeitsmechanismus in den Bereich der Zielerkennung einzuführen. Relation Net verwendet Transformer, um die Beziehung zwischen verschiedenen Zielen zu modellieren, Beziehungsinformationen in Features zu integrieren und eine Funktionsverbesserung zu erreichen. DETR schlägt eine neue Zielerkennungsarchitektur vor, die auf Transformer basiert und eine neue Ära der Zielerkennung einleitet. Die folgende Abbildung zeigt den Algorithmusprozess von DETR. Zuerst wird CNN zum Extrahieren von Bildmerkmalen verwendet, und dann wird Transformer zum Modellieren der globalen räumlichen Beziehung verwendet Schließlich erhalten wir die Ausgabe von wird mit manueller Annotation über einen zweiteiligen Graph-Matching-Algorithmus abgeglichen. Die Genauigkeit in der folgenden Tabelle verwendet mAP in der MS COCO-Datenbank als Indikator, während die Geschwindigkeit anhand von FPS gemessen wird AlgorithmenDa es beim strukturellen Design des Netzwerks viele verschiedene Möglichkeiten gibt (z. B. unterschiedliche Eingabegrößen, unterschiedliche Backbone-Netzwerke usw.), sind auch die Implementierungshardwareplattformen jedes Algorithmus unterschiedlich, sodass Genauigkeit und Geschwindigkeit nicht vollständig vergleichbar sind . Hier ist nur eine grobe Liste. Die Ergebnisse dienen Ihrer Information. Bei autonomen Fahranwendungen handelt es sich bei der Eingabe um Videodaten Es gibt viele Ziele, auf die man achten muss, wie zum Beispiel Fahrzeuge, Fußgänger, Fahrräder usw. Daher handelt es sich hierbei um eine typische Multiple-Object-Tracking-Aufgabe (MOT). Für MOT-Aufgaben ist Tracking-by-Detection derzeit das beliebteste Framework. Der Prozess ist wie folgt: ①Der Zieldetektor erhält die Zielbildausgabe auf einem einzelnen Bild; 🎜🎜#②Extrahieren Sie die Merkmale jedes erkannten Ziels, normalerweise einschließlich visueller Merkmale und Bewegungsmerkmale; ③Berechnen Sie die Ähnlichkeit zwischen Zielerkennungen aus benachbarten Bildern basierend auf den Merkmalen, um festzustellen, ob sie aus derselben Quelle stammen. Wahrscheinlichkeit eines Ziels; ④ Zielerkennungen in benachbarten Frames abgleichen und Objekten desselben Ziels dieselbe ID zuweisen. Deep Learning wird in den oben genannten vier Schritten angewendet, aber die ersten beiden Schritte sind die wichtigsten. In Schritt 1 dient die Anwendung von Deep Learning hauptsächlich der Bereitstellung hochwertiger Objektdetektoren, daher werden im Allgemeinen Methoden mit höherer Genauigkeit gewählt. SORT ist eine Zielerkennungsmethode, die auf Faster R-CNN basiert und den Kalman-Filteralgorithmus + den ungarischen Algorithmus verwendet, um die Geschwindigkeit der Verfolgung mehrerer Ziele erheblich zu verbessern und die Genauigkeit von SOTA zu erreichen. Sie wird auch häufig in praktischen Anwendungen verwendet. Algorithmus. In Schritt 2 basiert die Anwendung von Deep Learning hauptsächlich auf der Verwendung von CNN, um die visuellen Merkmale von Objekten zu extrahieren. Die größte Funktion von DeepSORT besteht darin, Darstellungsinformationen hinzuzufügen und das ReID-Modul auszuleihen, um Deep-Learning-Funktionen zu extrahieren und so die Anzahl der ID-Schalter zu reduzieren. Das allgemeine Flussdiagramm sieht wie folgt aus: In diesem Abschnitt stellen wir die 3D-Szenenwahrnehmung vor, die beim autonomen Fahren unerlässlich ist. Da Tiefeninformationen, dreidimensionale Zielgröße usw. nicht in der 2D-Wahrnehmung erfasst werden können, sind diese Informationen der Schlüssel für das autonome Fahrsystem, um korrekte Urteile über die Umgebung zu fällen. Der direkteste Weg, 3D-Informationen zu erhalten, ist die Verwendung von LiDAR. Allerdings hat LiDAR auch seine Nachteile, wie z. B. höhere Kosten, Schwierigkeiten bei der Massenproduktion von Produkten in Automobilqualität, stärkere Witterungseinflüsse usw. Daher ist die ausschließlich auf Kameras basierende 3D-Wahrnehmung immer noch eine sehr bedeutungsvolle und wertvolle Forschungsrichtung. Als nächstes sortieren wir einige 3D-Wahrnehmungsalgorithmen, die auf Monokularen und Ferngläsern basieren. Die Wahrnehmung der 3D-Umgebung anhand einzelner Kamerabilder ist ein schlecht gestelltes Problem, das jedoch durch geometrische Annahmen (z. B. Pixel am Boden), Vorkenntnisse oder einige zusätzliche Informationen gelöst werden kann (z. B. Tiefenschätzung), um zur Lösung des Problems beizutragen. Dieses Mal stellen wir die relevanten Algorithmen vor, ausgehend von den beiden Grundaufgaben zur Realisierung autonomen Fahrens (3D-Zielerkennung und Tiefenschätzung). 1.1 3D-Zielerkennung Darstellungsumwandlung (Pseudo-Lidar): Die Erkennung anderer umliegender Fahrzeuge durch visuelle Sensoren stößt normalerweise auf Probleme wie Verdeckung und Unfähigkeit, Entfernungen zu messen Express aus der Vogelperspektive. Hier werden zwei Transformationsmethoden vorgestellt. Die erste ist die inverse Perspektivkartierung (IPM), bei der davon ausgegangen wird, dass sich alle Pixel auf dem Boden befinden und die externen Parameter der Kamera korrekt sind. Zu diesem Zeitpunkt kann die Homographietransformation verwendet werden, um das Bild in BEV umzuwandeln, und dann eine darauf basierende Methode Das YOLO-Netzwerk wird verwendet, um den Bodenrahmen des Ziels zu erkennen. Die zweite ist Orthogonal Feature Transform (OFT), die ResNet-18 verwendet, um perspektivische Bildmerkmale zu extrahieren. Voxelbasierte Merkmale werden dann durch die Akkumulation bildbasierter Merkmale über die projizierten Voxelregionen generiert. Die Voxelmerkmale werden dann vertikal gefaltet, um orthogonale Grundebenenmerkmale zu erzeugen. Schließlich wird ein weiteres Top-Down-Netzwerk ähnlich wie ResNet für die 3D-Objekterkennung verwendet. Diese Methoden eignen sich nur für Fahrzeuge und Fußgänger, die sich in Bodennähe befinden. Für Nicht-Bodenziele wie Verkehrsschilder und Ampeln können durch Tiefenschätzung Pseudopunktwolken zur 3D-Erkennung generiert werden. Pseudo-LiDAR verwendet zunächst die Ergebnisse der Tiefenschätzung, um Punktwolken zu generieren, und wendet dann direkt den Lidar-basierten 3D-Zieldetektor an, um einen 3D-Zielrahmen zu generieren. Der Algorithmusablauf ist in der folgenden Abbildung dargestellt: Schlüsselpunkte und 3D-Modelle: zu erkennen. Die Größe und Form von Zielen wie Fahrzeugen und Fußgängern sind relativ fest und bekannt und können als Vorwissen zur Schätzung der 3D-Informationen des Ziels verwendet werden. DeepMANTA ist eines der Pionierwerke in dieser Richtung. Zunächst werden einige Zielerkennungsalgorithmen wie Faster RNN verwendet, um den 2D-Zielrahmen zu erhalten und auch die Schlüsselpunkte des Ziels zu erkennen. Anschließend werden diese 2D-Zielrahmen und Schlüsselpunkte mit verschiedenen 3D-Fahrzeug-CAD-Modellen in der Datenbank abgeglichen und das Modell mit der höchsten Ähnlichkeit als Ausgabe der 3D-Zielerkennung ausgewählt. MonoGRNet schlägt vor, die monokulare 3D-Zielerkennung in vier Schritte zu unterteilen: 2D-Zielerkennung, Tiefenschätzung auf Instanzebene, projizierte 3D-Mittelpunktschätzung und lokale Eckenregression. Der Algorithmusablauf ist in der folgenden Abbildung dargestellt. Diese Art von Methode geht davon aus, dass das Ziel ein relativ festes Formmodell hat, was für Fahrzeuge im Allgemeinen zufriedenstellend ist, für Fußgänger jedoch relativ schwierig. 2D/3D-Geometriebeschränkungen: Regressieren Sie die Projektion des 3D-Zentrums und der groben Instanztiefe und verwenden Sie beide, um eine grobe 3D-Position abzuschätzen. Die Pionierarbeit ist Deep3DBox, das zunächst Bildmerkmale innerhalb einer 2D-Zielbox verwendet, um die Größe und Ausrichtung des Ziels abzuschätzen. Anschließend wird die 3D-Position des Mittelpunkts durch eine geometrische 2D/3D-Beschränkung gelöst. Diese Einschränkung besteht darin, dass die Projektion des 3D-Zielrahmens auf dem Bild eng vom 2D-Zielrahmen umgeben ist, d. h., dass auf jeder Seite des 2D-Zielrahmens mindestens ein Eckpunkt des 3D-Zielrahmens gefunden werden kann. Durch die zuvor vorhergesagte Größe und Ausrichtung, kombiniert mit den Kalibrierungsparametern der Kamera, kann die 3D-Position des Mittelpunkts berechnet werden. Die geometrischen Einschränkungen zwischen den 2D- und 3D-Zielfeldern sind in der folgenden Abbildung dargestellt. Shift R-CNN kombiniert die zuvor erhaltenen 2D-Zielboxen, 3D-Zielboxen und Kameraparameter als Eingaben basierend auf Deep3DBox und verwendet ein vollständig verbundenes Netzwerk, um eine genauere 3D-Position vorherzusagen. 3DBox direkt generieren: Diese Methode beginnt mit dichten 3D-Zielkandidatenboxen und bewertet alle Kandidatenboxen basierend auf den Merkmalen im 2D-Bild. Die Kandidatenbox mit der höchsten Bewertung ist die endgültige Ausgabe. Etwas ähnlich der herkömmlichen Schiebefenstermethode bei der Zielerkennung. Der repräsentative Mono3D-Algorithmus generiert zunächst dichte 3D-Kandidatenfelder basierend auf der vorherigen Position des Ziels (Z-Koordinate ist auf dem Boden) und Größe. Nachdem diese 3D-Kandidatenbilder auf Bildkoordinaten projiziert wurden, werden sie durch Integration der Merkmale im 2D-Bild bewertet. Anschließend wird eine zweite Bewertungsrunde über CNN durchgeführt, um das endgültige 3D-Zielbild zu erhalten. M3D-RPN ist eine ankerbasierte Methode, die 2D- und 3D-Anker definiert. Der 2D-Anker wird durch dichtes Abtasten des Bildes erhalten, und der 3D-Anker wird durch Vorkenntnisse der Trainingssatzdaten (z. B. den Mittelwert der tatsächlichen Größe des Ziels) bestimmt. M3D-RPN verwendet außerdem sowohl die Standardfaltung als auch die tiefenbasierte Faltung. Ersteres weist räumliche Invarianz auf und letzteres unterteilt die Zeilen (Y-Koordinaten) des Bildes in mehrere Gruppen. Jede Gruppe entspricht einer anderen Szenentiefe und wird von verschiedenen Faltungskernen verarbeitet. Die oben genannten Methoden zur dichten Stichprobe sind sehr rechenintensiv. SS3D verwendet eine effizientere einstufige Erkennung, einschließlich eines CNN zur Ausgabe redundanter Darstellungen jedes relevanten Objekts im Bild und entsprechender Unsicherheitsschätzungen sowie eines 3D-Bounding-Box-Optimierers. FCOS3D ist ebenfalls eine einstufige Erkennungsmethode. Das Regressionsziel fügt ein zusätzliches 2,5D-Zentrum (X, Y, Tiefe) hinzu, das durch Projizieren des Zentrums des 3D-Zielrahmens auf das 2D-Bild erhalten wird. 1.2 Tiefenschätzung Ob es sich um die oben erwähnte 3D-Zielerkennung oder eine andere wichtige Aufgabe der wahrnehmungssemantischen Segmentierung des autonomen Fahrens handelt, von Wenn 2D auf 3D erweitert wird, werden mehr oder weniger spärliche oder dichte Tiefeninformationen angewendet. Die Bedeutung der monokularen Tiefenschätzung liegt auf der Hand. Ihre Eingabe ist ein Bild, und die Ausgabe ist ein Bild derselben Größe, das aus dem jedem Pixel entsprechenden Szenentiefenwert besteht. Die Eingabe kann auch eine Videosequenz sein, die zusätzliche Informationen von der Kamera oder der Objektbewegung nutzt, um die Genauigkeit der Tiefenschätzung zu verbessern. Im Vergleich zum überwachten Lernen erfordert die unbeaufsichtigte Methode der monokularen Tiefenschätzung nicht die Erstellung eines anspruchsvollen Ground-Truth-Datensatzes und ist weniger schwierig zu implementieren. Unüberwachte Methoden zur monokularen Tiefenschätzung können in zwei Typen unterteilt werden: basierend auf monokularen Videosequenzen und basierend auf synchronisierten Stereobildpaaren. Ersteres basiert auf der Annahme bewegter Kameras und statischer Szenen. Bei der letztgenannten Methode versuchten Garg et al. zunächst, stereokorrigierte binokulare Bildpaare gleichzeitig für die Bildrekonstruktion zu verwenden. Durch binokulare Bestimmung wurde ein relativ idealer Effekt erzielt. Auf dieser Grundlage verwendeten Godard et al. Einschränkungen für die linke und rechte Konsistenz, um die Genauigkeit weiter zu verbessern. Während jedoch erweiterte Merkmale durch schichtweises Downsampling extrahiert wurden, um das Empfangsfeld zu erhöhen, nimmt auch die Merkmalsauflösung ständig ab geht ständig verloren, was die Verarbeitung tiefer Details und die Klarheit der Kanten beeinträchtigt. Um dieses Problem zu lindern, haben Godard et al. einen Multiskalenverlust mit voller Auflösung eingeführt, der schwarze Löcher und Texturreplikationsartefakte in Bereichen mit geringer Textur effektiv reduziert. Diese Verbesserung der Genauigkeit ist jedoch noch begrenzt. In jüngster Zeit sind in einem endlosen Strom einige Transformer-basierte Modelle aufgetaucht, die darauf abzielen, in allen Phasen ein globales Empfangsfeld zu erhalten, das sich auch sehr gut für intensive Tiefenschätzungsaufgaben eignet. Bei der überwachten DPT wird vorgeschlagen, Transformer und Multiskalenstrukturen zu verwenden, um gleichzeitig die lokale Genauigkeit und die globale Konsistenz der Vorhersage sicherzustellen. Die folgende Abbildung zeigt das Netzwerkstrukturdiagramm. Binokulares Sehen kann die Mehrdeutigkeit der perspektivischen Transformationszone lösen Daher kann es theoretisch die Genauigkeit der 3D-Wahrnehmung verbessern. Allerdings stellt das Binokularsystem relativ hohe Anforderungen an Hardware und Software. Hardwareseitig sind zwei genau registrierte Kameras erforderlich, wobei die Korrektheit der Registrierung im Fahrzeugbetrieb gewährleistet sein muss. In Bezug auf die Software muss der Algorithmus Daten von zwei Kameras gleichzeitig verarbeiten. Die Berechnungskomplexität ist hoch und die Echtzeitleistung des Algorithmus kann nur schwer garantiert werden. Im Vergleich zum Monokular ist die binokulare Arbeit relativ geringer. Als nächstes geben wir auch eine kurze Einführung in die beiden Aspekte der 3D-Zielerkennung und Tiefenschätzung. 2.1 3D-Zielerkennung 3DOP ist eine zweistufige Erkennungsmethode, die eine Erweiterung der Fast R-CNN-Methode im 3D-Bereich darstellt. Zunächst werden binokulare Bilder verwendet, um eine Tiefenkarte zu erstellen. Die Tiefenkarte wird in eine Punktwolke umgewandelt und dann in eine Gitterdatenstruktur quantifiziert. Diese wird dann als Eingabe verwendet, um einen Kandidatenrahmen für das 3D-Ziel zu generieren. Ähnlich wie beim zuvor eingeführten Pseudo-LiDAR werden dichte Tiefenkarten (von monokularem, binokularem oder sogar LiDAR mit geringer Linienzahl) in Punktwolken umgewandelt und anschließend Algorithmen im Bereich der Punktwolken-Zielerkennung angewendet. DSGN nutzt Stereo-Matching, um planare Scan-Volumina zu erstellen und diese in 3D-Geometrie umzuwandeln, um 3D-Geometrie und semantische Informationen zu kodieren. Es handelt sich um ein End-to-End-Framework, das Features auf Pixelebene für Stereo-Matching und erweiterte Objekterkennung extrahieren kann und kann gleichzeitig die Szenentiefe schätzen und 3D-Objekte erkennen. Stereo R-CNN erweitert Faster R-CNN für Stereoeingänge, um Objekte in der linken und rechten Ansicht gleichzeitig zu erkennen und zu korrelieren. Nach RPN wird ein zusätzlicher Zweig hinzugefügt, um spärliche Schlüsselpunkte, Ansichtspunkte und Objektgrößen vorherzusagen, und kombiniert die 2D-Begrenzungsrahmen in der linken und rechten Ansicht, um einen groben 3D-Objektbegrenzungsrahmen zu berechnen. Anschließend werden mithilfe der bereichsbasierten photometrischen Ausrichtung der linken und rechten interessierenden Bereiche genaue 3D-Begrenzungsrahmen wiederhergestellt. Die folgende Abbildung zeigt die Netzwerkstruktur. 2.2 Tiefenschätzung Das Prinzip der binokularen Tiefenschätzung ist sehr einfach und basiert auf dem Pixelabstand d zwischen demselben 3D-Punkt in der linken und rechten Ansicht (vorausgesetzt, dass die beiden Kameras den gleichen Wert beibehalten). Höhe, daher wird nur die horizontale Richtung berücksichtigt, dh die Parallaxe, die Brennweite f der Kamera und der Abstand B (Basislinienlänge) zwischen den beiden Kameras, um die Tiefe des 3D-Punkts abzuschätzen ist wie folgt. Die Tiefe kann durch Schätzung der Parallaxe berechnet werden. Dann müssen Sie nur noch für jedes Pixel einen passenden Punkt auf dem anderen Bild finden. Für jedes mögliche d kann der Übereinstimmungsfehler an jedem Pixel berechnet werden, sodass ein dreidimensionales Fehlerdaten-Kostenvolumen erhalten wird. Durch das Kostenvolumen können wir leicht die Disparität an jedem Pixel ermitteln (d entspricht dem minimalen Übereinstimmungsfehler) und so den Tiefenwert erhalten. MC-CNN verwendet ein Faltungs-Neuronales Netzwerk, um den Übereinstimmungsgrad zweier Bildfelder vorherzusagen, und berechnet daraus die Kosten für die Stereoanpassung. Die Kosten werden durch schnittpunktbasierte Kostenaggregation und halbglobales Matching verfeinert, gefolgt von Links-Rechts-Konsistenzprüfungen, um Fehler in verdeckten Bereichen zu beseitigen. PSMNet schlägt ein End-to-End-Lernframework für Stereo-Matching vor, das keine Nachbearbeitung erfordert, führt ein Pyramiden-Pooling-Modul ein, um globale Kontextinformationen in Bildfunktionen zu integrieren, und stellt ein gestapeltes Sanduhr-3D-CNN bereit, um globale Informationen weiter zu verbessern. Die folgende Abbildung zeigt die Netzwerkstruktur. 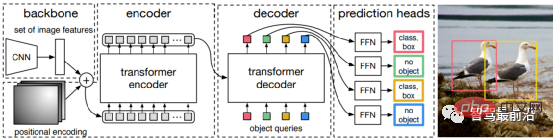
2. Zielverfolgung
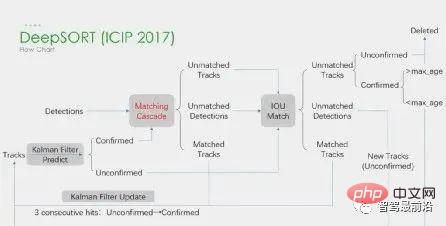 Darüber hinaus gibt es ein Framework zur gleichzeitigen Erkennung und Verfolgung. Wie zum Beispiel der repräsentative CenterTrack, der aus dem zuvor eingeführten einstufigen ankerlosen Erkennungsalgorithmus CenterNet hervorgegangen ist. Im Vergleich zu CenterNet fügt CenterTrack das RGB-Bild des vorherigen Frames und die Heatmap des Objektzentrums als zusätzliche Eingaben hinzu und fügt einen Offset-Zweig für die Zuordnung zwischen dem vorherigen und dem nächsten Frame hinzu. Im Vergleich zum mehrstufigen Tracking-by-Detection nutzt CenterTrack ein Netzwerk zur Implementierung der Erkennungs- und Matching-Stufen und verbessert so die Geschwindigkeit der MOT.
Darüber hinaus gibt es ein Framework zur gleichzeitigen Erkennung und Verfolgung. Wie zum Beispiel der repräsentative CenterTrack, der aus dem zuvor eingeführten einstufigen ankerlosen Erkennungsalgorithmus CenterNet hervorgegangen ist. Im Vergleich zu CenterNet fügt CenterTrack das RGB-Bild des vorherigen Frames und die Heatmap des Objektzentrums als zusätzliche Eingaben hinzu und fügt einen Offset-Zweig für die Zuordnung zwischen dem vorherigen und dem nächsten Frame hinzu. Im Vergleich zum mehrstufigen Tracking-by-Detection nutzt CenterTrack ein Netzwerk zur Implementierung der Erkennungs- und Matching-Stufen und verbessert so die Geschwindigkeit der MOT.
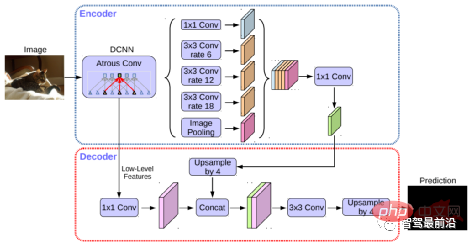
Semantische Segmentierung wird sowohl bei der Spurlinienerkennung als auch bei der Erkennung befahrbarer Bereiche beim autonomen Fahren verwendet. Repräsentative Algorithmen umfassen FCN, U-Net, DeepLab-Serie usw. DeepLab verwendet erweiterte Faltung und ASPP-Struktur (Atrous Spatial Pyramid Pooling), um eine mehrskalige Verarbeitung des Eingabebilds durchzuführen. Schließlich wird das bedingte Zufallsfeld (Conditional Random Field, CRF), das üblicherweise in herkömmlichen semantischen Segmentierungsmethoden verwendet wird, zur Optimierung der Segmentierungsergebnisse verwendet. Die folgende Abbildung zeigt die Netzwerkstruktur von DeepLab v3+.
 Der STDC-Algorithmus hat in den letzten Jahren eine Struktur ähnlich dem FCN-Algorithmus angenommen und die komplexe Decoderstruktur des U-Net-Algorithmus entfernt. Gleichzeitig wird das ARM-Modul beim Netzwerk-Downsampling verwendet, um kontinuierlich Informationen aus Feature-Maps verschiedener Ebenen zusammenzuführen und so die Mängel des FCN-Algorithmus zu vermeiden, der nur Einzelpixelbeziehungen berücksichtigt. Man kann sagen, dass der STDC-Algorithmus ein gutes Gleichgewicht zwischen Geschwindigkeit und Genauigkeit erreicht und die Echtzeitanforderungen des autonomen Fahrsystems erfüllen kann. Der Algorithmusablauf ist in der folgenden Abbildung dargestellt.
Der STDC-Algorithmus hat in den letzten Jahren eine Struktur ähnlich dem FCN-Algorithmus angenommen und die komplexe Decoderstruktur des U-Net-Algorithmus entfernt. Gleichzeitig wird das ARM-Modul beim Netzwerk-Downsampling verwendet, um kontinuierlich Informationen aus Feature-Maps verschiedener Ebenen zusammenzuführen und so die Mängel des FCN-Algorithmus zu vermeiden, der nur Einzelpixelbeziehungen berücksichtigt. Man kann sagen, dass der STDC-Algorithmus ein gutes Gleichgewicht zwischen Geschwindigkeit und Genauigkeit erreicht und die Echtzeitanforderungen des autonomen Fahrsystems erfüllen kann. Der Algorithmusablauf ist in der folgenden Abbildung dargestellt. Visuelle 3D-Wahrnehmung
1. Monokulare 3D-Wahrnehmung

2. Binokulare 3D-Wahrnehmung

Das obige ist der detaillierte Inhalt vonEine ausführliche Diskussion der visuellen 2D- und 3D-Wahrnehmungsalgorithmen beim autonomen Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Algorithmus zum Ersetzen von Seiten
Algorithmus zum Ersetzen von Seiten
 Der Unterschied zwischen Get-Request und Post-Request
Der Unterschied zwischen Get-Request und Post-Request
 drücke irgendeine Taste zum Neustart
drücke irgendeine Taste zum Neustart
 Welche Software ist Unity?
Welche Software ist Unity?
 Python-Tutorial
Python-Tutorial
 So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
 Methoden zur Reparatur von Datenbankschwachstellen
Methoden zur Reparatur von Datenbankschwachstellen
 Wie viel entspricht Dimensity 6020 Snapdragon?
Wie viel entspricht Dimensity 6020 Snapdragon?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



