
 Technologie-Peripheriegeräte
KI
Das innovative SOTA-Modell von Meta kann auf der Grundlage eines Satzes erstaunliche Videos generieren und so einen Internet-Hype auslösen!
Technologie-Peripheriegeräte
KI
Das innovative SOTA-Modell von Meta kann auf der Grundlage eines Satzes erstaunliche Videos generieren und so einen Internet-Hype auslösen!
Das innovative SOTA-Modell von Meta kann auf der Grundlage eines Satzes erstaunliche Videos generieren und so einen Internet-Hype auslösen!

Ich gebe dir einen Absatz und bitte dich, ein Video zu machen. Kannst du das machen?
Meta sagte, ich kann es schaffen.
Du hast richtig gehört: Mit KI kannst du auch Filmemacher werden!
Vor kurzem hat Meta ein neues KI-Modell auf den Markt gebracht, und der Name ist sehr einfach: Make-A-Video.
Wie leistungsstark ist dieses Modell?
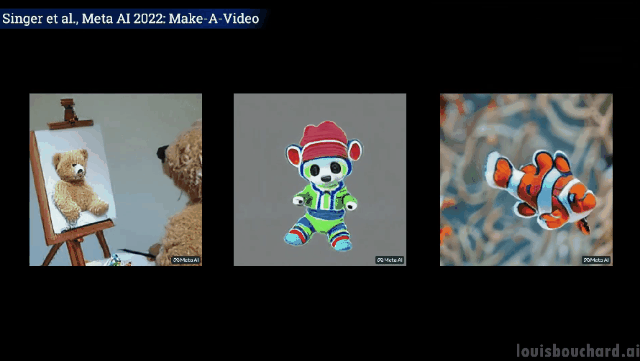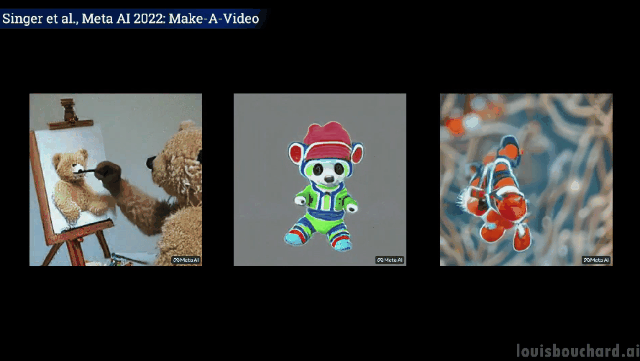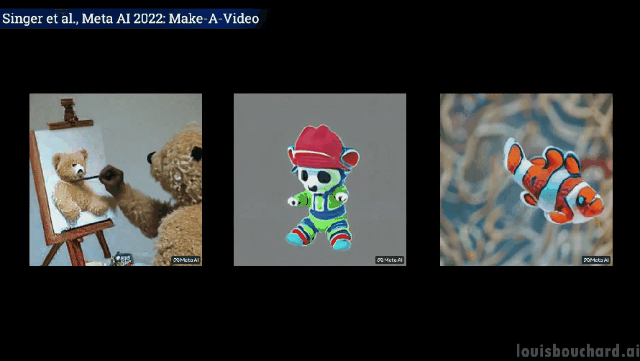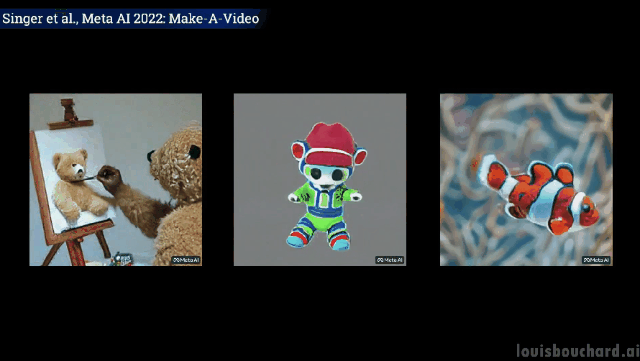
Mit nur einem Satz können Sie die Szene „Drei galoppierende Pferde“ erkennen.

Sogar LeCun sagte: Was kommen soll, wird immer kommen.

Die visuellen Effekte sind atemberaubend
Ohne weitere Umschweife schauen wir uns einfach die Effekte an.
Zwei Kängurus kochen fleißig in der Küche (ob sie essen können, ist eine andere Frage)

Nahaufnahme: Der Maler malt auf der Leinwand

Die Welt der Zwei Menschen, die im starken Regen spazieren gehen (einheitliche Schritte) Retriever ist Essen an einem wunderschönen tropischen Sommerstrand Eis (Pfoten haben sich weiterentwickelt)

Der Katzenbesitzer schaut mit der Fernbedienung fern (Pfoten haben sich weiterentwickelt)

Ein Teddybär zeichnet ein selbst- Porträt seiner selbst

Natürlich kann Make-A-Video nicht nur Text in Videos umwandeln, sondern auch statische Bilder in Gifs umwandeln.

Eingabe:

Ausgabe:

Eingabe:

Ausgabe: (Das Licht scheint etwas fehl am Platz zu sein)

2 statische Bilder in GIF, geben Sie das Meteoritenbild ein

Ausgabe:

Und das Video in ein Video verwandeln?
Eingabe:

Ausgabe:

Eingabe:

Ausgabe:

Technische Prinzipien
Heute hat Meta sein eigenes Neuestes veröffentlicht Forschung MAKE-A-VIDEO: TEXT-TO-VIDEO-GENERATION OHNE TEXT-VIDEO-DATEN.

Papieradresse: https://makeavideo.studio/Make-A-Video.pdf
Bevor dieses Modell erschien, hatten wir bereits Stable Diffusion.
Kluge Wissenschaftler haben die KI bereits gebeten, Bilder mit nur einem Satz zu erzeugen. Was werden sie als nächstes tun?
Natürlich geht es darum, ein Video zu erstellen.

Ein Superheldenhund mit rotem Umhang fliegt in den Himmel
Ein Video zu erstellen ist viel schwieriger als ein Bild. Wir müssen nicht nur mehrere Bilder desselben Motivs und derselben Szene erstellen, sondern sie auch zeitnah und kohärent gestalten.
Dies erhöht die Komplexität der Bildgenerierungsaufgabe – wir können nicht einfach DALLE verwenden, um 60 Bilder zu generieren und diese dann zu einem Video zusammenzufügen. Der Effekt wird sehr dürftig und unrealistisch sein.
Deshalb brauchen wir ein Modell, das die Welt besser verstehen und es ihr ermöglichen kann, auf dieser Ebene des Verständnisses eine zusammenhängende Reihe von Bildern zu erzeugen. Nur dann können die Bilder nahtlos ineinander übergehen.
Mit anderen Worten: Unser Ziel ist es, eine Welt zu simulieren und dann ihre Aufzeichnungen zu simulieren. Wie geht das?

Nach früheren Vorstellungen würden Forscher eine große Anzahl von Text-Video-Paaren verwenden, um das Modell zu trainieren, aber in der aktuellen Situation ist diese Verarbeitungsmethode nicht realistisch. Denn diese Daten sind schwer zu beschaffen und die Schulungskosten sind sehr hoch.
Also öffneten sich die Forscher und wählten einen völlig neuen Ansatz.
Sie entschieden sich dafür, ein Text-zu-Bild-Modell zu entwickeln und es dann auf Videos anzuwenden.
Zufälligerweise hat Meta vor einiger Zeit Make-A-Scene entwickelt, ein Modell vom Text zum Bild.
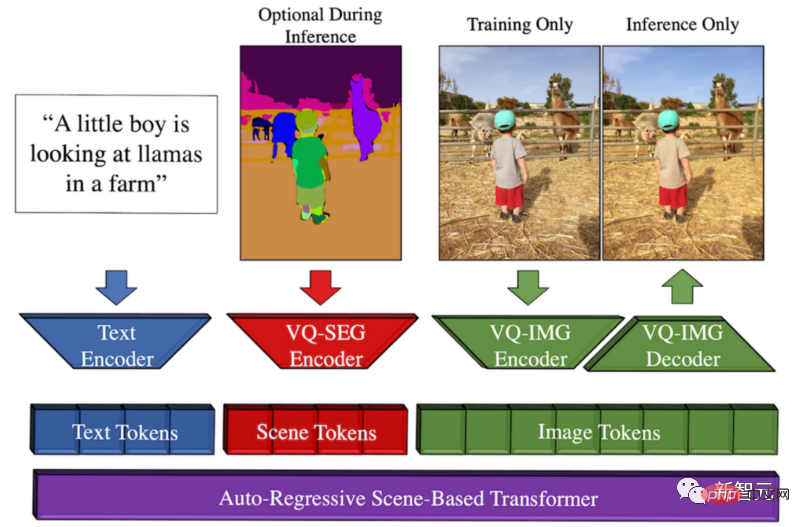
Überblick über die Make-A-Scene-Methode
Die Gelegenheit für dieses Modell besteht darin, dass Meta den kreativen Ausdruck fördern und diesen Text-zu-Bild-Trend mit dem vorherigen Sketch-to vergleichen möchte -Bildmodell kombiniert, was zu einer fantastischen Verschmelzung von Text und skizzenbedingter Bildgenerierung führt.
Das bedeutet, dass wir schnell eine Katze skizzieren und aufschreiben können, welche Art von Bild wir wollen. Unter Anleitung von Skizzen und Text erstellt dieses Modell in Sekundenschnelle die perfekte Illustration, die wir wollen.

Sie können sich diesen multimodalen generativen KI-Ansatz als Dall-E-Modell mit mehr Kontrolle über die Generierung vorstellen, da auch schnelle Skizzen als Eingabe verwendet werden können.
Der Grund, warum es multimodal genannt wird, liegt darin, dass es mehrere Modalitäten als Eingabe annehmen kann, wie zum Beispiel Text und Bilder. Im Gegensatz dazu kann Dall-E nur Bilder aus Text generieren.
Um ein Video zu generieren, muss die Dimension Zeit hinzugefügt werden, daher fügten die Forscher dem Make-A-Scene-Modell eine räumlich-zeitliche Pipeline hinzu.
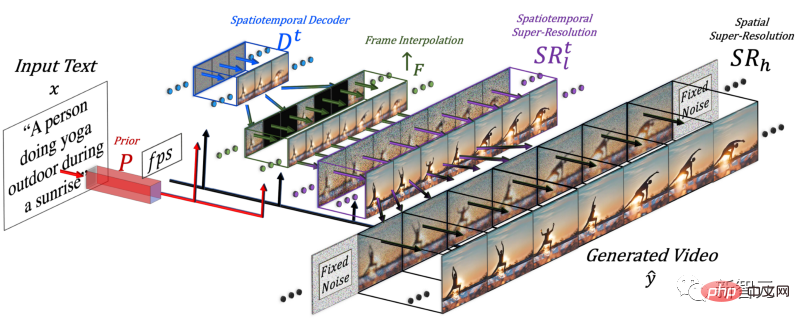
Nach dem Hinzufügen der Zeitdimension generiert dieses Modell nicht nur ein Bild, sondern 16 Bilder mit niedriger Auflösung, um ein zusammenhängendes Kurzvideo zu erstellen.
Diese Methode ähnelt tatsächlich dem Text-zu-Bild-Modell, der Unterschied besteht jedoch darin, dass basierend auf der herkömmlichen zweidimensionalen Faltung eine eindimensionale Faltung hinzugefügt wird.
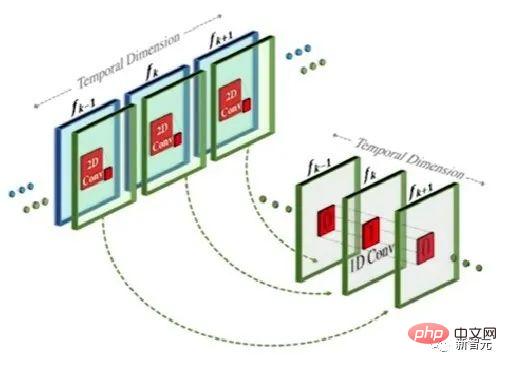
Durch einfaches Hinzufügen einer eindimensionalen Faltung konnten die Forscher die vorab trainierte zweidimensionale Faltung unverändert lassen und gleichzeitig eine zeitliche Dimension hinzufügen. Forscher können dann von Grund auf trainieren und dabei einen Großteil des Codes und der Parameter des Make-A-Scene-Bildmodells wiederverwenden.
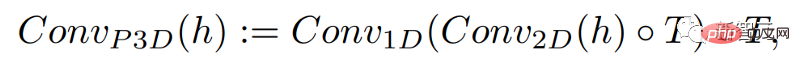
Gleichzeitig möchten die Forscher auch Texteingaben zur Steuerung dieses Modells verwenden, das dem Bildmodell mit CLIP-Einbettung sehr ähnlich sein wird.
In diesem Fall erhöhten die Forscher die räumliche Dimension, indem sie Textmerkmale mit Bildmerkmalen vermischten. Die Methode ist die gleiche wie oben: Beibehaltung des Aufmerksamkeitsmoduls im Make-A-Scene-Modell und Hinzufügen einer eindimensionalen Dimension Achtung: Kopieren Sie das Bildgeneratormodell, fügen Sie es ein und wiederholen Sie das Generierungsmodul für eine weitere Dimension, um 16 Anfangsbilder zu erhalten.
Aber wenn man sich nur auf diese 16 Anfangsbilder verlässt, kann das Video nicht generiert werden.
Forscher müssen aus diesen 16 Hauptbildern ein hochauflösendes Video erstellen. Ihr Ansatz besteht darin, auf frühere und zukünftige Frames zuzugreifen und diese gleichzeitig sowohl in der zeitlichen als auch in der räumlichen Dimension iterativ zu interpolieren.
Auf diese Weise wurden zwischen diesen 16 Anfangsbildern neue, größere Bilder basierend auf den Bildern davor und danach generiert, sodass die Bewegung kohärent und das Gesamtvideo flüssig wurde.
Dies geschieht über ein Frame-Interpolationsnetzwerk, das vorhandene Bilder nutzen kann, um die Lücken zu füllen und Zwischeninformationen zu generieren. In der räumlichen Dimension bewirkt es das Gleiche: Es vergrößert das Bild, füllt die Lücken in Pixeln und macht das Bild hochauflösender.

Zusammenfassend lässt sich sagen, dass die Forscher zur Generierung von Videos ein Text-zu-Bild-Modell verfeinert haben. Sie nahmen ein leistungsstarkes Modell, das bereits trainiert war, optimierten und trainierten es, um es an das Video anzupassen.
Durch die Hinzufügung räumlicher und zeitlicher Module können Sie das Modell einfach an diese neuen Daten anpassen, ohne es neu trainieren zu müssen, was eine Menge Kosten spart.
Diese Art der Umschulung verwendet unbeschriftete Videos und muss dem Modell nur beibringen, die Konsistenz des Videos und der Videobilder zu verstehen, was die Erstellung des Datensatzes erleichtert.
Schließlich nutzten die Forscher erneut das Bildoptimierungsmodell, um die räumliche Auflösung zu verbessern, und nutzten die Frame-Interpolationskomponente, um weitere Frames hinzuzufügen, um das Video flüssiger zu machen.
Natürlich weisen die aktuellen Ergebnisse von Make-A-Video immer noch Mängel auf, genau wie das Text-zu-Bild-Modell. Aber wir alle wissen, wie schnell der Fortschritt im Bereich der KI ist.
Wenn Sie mehr wissen möchten, können Sie sich das Meta AI-Papier im Link ansehen. Die Community entwickelt außerdem eine PyTorch-Implementierung. Bleiben Sie also auf dem Laufenden, wenn Sie diese selbst implementieren möchten.
Vorstellung des Autors
Eine Reihe chinesischer Forscher waren an diesem Artikel beteiligt: Yin Xi, An Jie, Zhang Songyang, Qiyuan Hu.
Yin Xi, FAIR-Forscher. Zuvor arbeitete er für Microsoft als leitender Anwendungswissenschaftler für Microsoft Cloud und AI. Er erhielt seinen Doktortitel vom Department of Computer Science and Engineering der Michigan State University und seinen Bachelor-Abschluss in Elektrotechnik von der Wuhan University im Jahr 2013. Die Hauptforschungsbereiche sind multimodales Verständnis, groß angelegte Zielerkennung, Gesichtsbegründung usw.
Anjie ist Doktorandin am Fachbereich Informatik der University of Rochester. Studieren Sie bei Professor Roger Bo. Zuvor erhielt er 2016 und 2019 Bachelor- und Masterabschlüsse von der Peking-Universität. Zu den Forschungsinteressen gehören Computer Vision, tiefe generative Modelle und KI+Kunst. Teilnahme an der Make-A-Video-Forschung als Praktikant.
Zhang Songyang ist Doktorand am Fachbereich Informatik der Universität Rochester und studiert bei Professor Roger Bo. Er erhielt seinen Bachelor-Abschluss von der Southeast University und seinen Master-Abschluss von der Zhejiang-Universität. Zu den Forschungsinteressen gehören Momentlokalisierung in natürlicher Sprache, unbeaufsichtigte Grammatikinduktion, skelettbasierte Aktionserkennung usw. Teilnahme an der Make-A-Video-Forschung als Praktikant.
Qiyuan Hu, damals KI-Resident bei FAIR, beschäftigte sich mit der Erforschung multimodaler generativer Modelle, die die menschliche Kreativität verbessern. Sie promovierte in medizinischer Physik an der University of Chicago und arbeitete an der KI-gestützten medizinischen Bildanalyse. Arbeitet jetzt bei Tempus Labs als Wissenschaftler für maschinelles Lernen.
Die Internetnutzer waren schockiert
Vor einiger Zeit haben große Unternehmen wie Google ihre eigenen Text-zu-Bild-Modelle wie Parti usw. veröffentlicht.
Manche denken sogar, dass generative Text-zu-Video-Modelle noch eine Weile auf sich warten lassen.
Unerwartet ließ Meta dieses Mal eine Bombe platzen.
Tatsächlich gibt es heute auch ein Text-zu-Video-Generierungsmodell Phenaki, das bei ICLR 2023 eingereicht wurde. Da es sich noch in der Blind-Review-Phase befindet, ist die Institution des Autors noch unbekannt.

Netizens sagten, dass von DALLE über Stable Diffuson bis hin zu Make-A-Video alles zu schnell ging.

Das obige ist der detaillierte Inhalt vonDas innovative SOTA-Modell von Meta kann auf der Grundlage eines Satzes erstaunliche Videos generieren und so einen Internet-Hype auslösen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laraveleloquent-Modellab Abruf: Das Erhalten von Datenbankdaten Eloquentorm bietet eine prägnante und leicht verständliche Möglichkeit, die Datenbank zu bedienen. In diesem Artikel werden verschiedene eloquente Modellsuchtechniken im Detail eingeführt, um Daten aus der Datenbank effizient zu erhalten. 1. Holen Sie sich alle Aufzeichnungen. Verwenden Sie die Methode All (), um alle Datensätze in der Datenbanktabelle zu erhalten: UseApp \ Models \ post; $ posts = post :: all (); Dies wird eine Sammlung zurückgeben. Sie können mit der Foreach-Schleife oder anderen Sammelmethoden auf Daten zugreifen: foreach ($ postas $ post) {echo $ post->
