
 Technologie-Peripheriegeräte
KI
Die Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit
Technologie-Peripheriegeräte
KI
Die Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit
Die Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit

Wie leistungsstark ist eine Codezeile? Die Kernl-Bibliothek, die wir heute vorstellen werden, ermöglicht es Benutzern, das Pytorch-Transformator-Modell mit nur einer Codezeile um ein Vielfaches schneller auf der GPU auszuführen, wodurch die Inferenzgeschwindigkeit des Modells erheblich beschleunigt wird.
Insbesondere ist Berts Inferenzgeschwindigkeit mit dem Segen von Kernl 12-mal schneller als die Basislinie von Hugging Face. Dieser Erfolg ist hauptsächlich darauf zurückzuführen, dass Kernl benutzerdefinierte GPU-Kernel in den neuen OpenAI-Programmiersprachen Triton und TorchDynamo schreibt. Der Projektautor stammt aus Lefebvre Sarrut.
GitHub-Adresse: https://github.com/ELS-RD/kernl/
Das Folgende ist ein Vergleich zwischen Kernl und anderen Inferenz-Engines. Die Zahlen in Klammern Die Abszisse gibt jeweils die Stapelgröße und die Sequenzlänge an, und die Ordinate ist die Inferenzbeschleunigung.
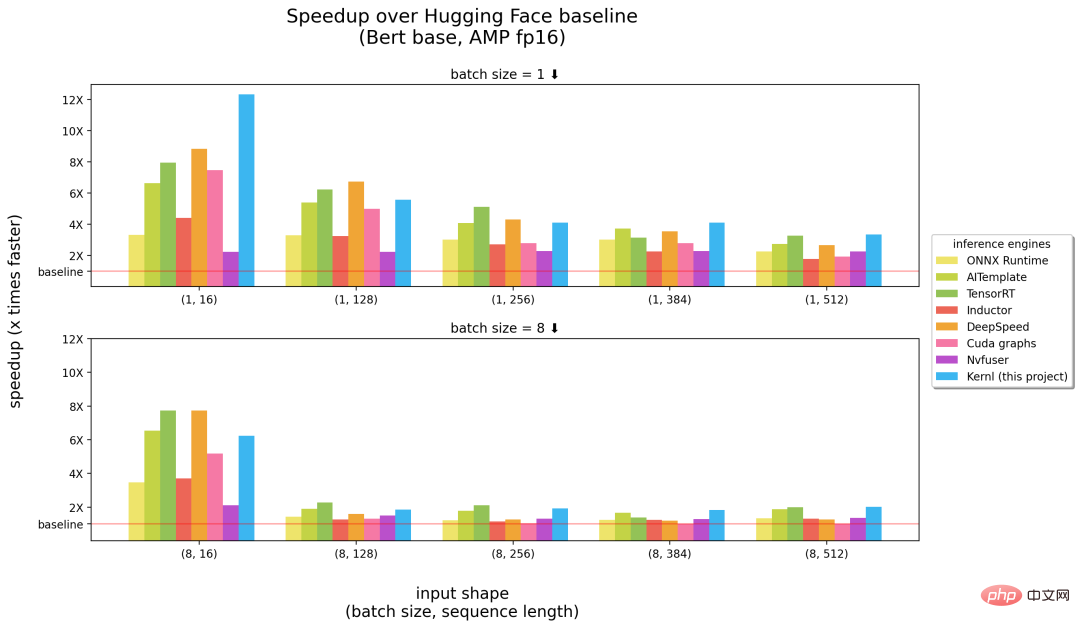
Benchmarks laufen auf einer 3090 RTX-GPU und einer 12-Core-Intel-CPU.
Aus den obigen Ergebnissen ist ersichtlich, dass Kernl bei der Eingabe langer Sequenzen als die schnellste Inferenz-Engine (rechte Hälfte des Bildes oben) gilt und nahe an NVIDIAs TensorRT liegt kurze Eingabesequenzen ( (linke Bildhälfte oben). Ansonsten ist der Kernl-Kernelcode sehr kurz und leicht zu verstehen und zu ändern. Das Projekt fügt sogar einen Triton-Debugger und Tools (basierend auf Fx) hinzu, um den Kernel-Austausch zu vereinfachen, sodass keine Änderungen am Quellcode des PyTorch-Modells erforderlich sind.
Projektautor Michaël Benesty hat diese Forschung zusammengefasst. Sie haben Kernl veröffentlicht, eine Bibliothek zur Beschleunigung der Transformatorinferenz. Sie ist sehr schnell, erreicht manchmal die SOTA-Leistung und kann so geknackt werden, dass sie mit den meisten Transformatorarchitekturen übereinstimmt.
Sie haben es auch auf T5 getestet und es war sechsmal schneller. Benesty sagte, das sei erst der Anfang.
Warum wurde Kernl erstellt?
Bei Lefebvre Sarrut betreibt der Projektautor mehrere Transformer-Modelle in der Produktion, von denen einige latenzempfindlich sind, hauptsächlich Suche und Recsys. Sie verwenden auch OnnxRuntime und TensorRT und haben sogar die Transformer-Deploy-OSS-Bibliothek erstellt, um ihr Wissen mit der Community zu teilen.
Kürzlich hat der Autor generative Sprachen getestet und hart daran gearbeitet, sie zu beschleunigen. Allerdings hat es sich als sehr schwierig erwiesen, dies mit herkömmlichen Werkzeugen zu bewerkstelligen. Ihrer Ansicht nach ist Onnx ein weiteres interessantes Format, das für maschinelles Lernen entwickelt wurde und zum Speichern trainierter Modelle verwendet wird.
Allerdings weist das Onnx-Ökosystem (hauptsächlich die Inferenz-Engine) die folgenden Einschränkungen auf, wenn es mit der neuen LLM-Architektur umgeht:
- Der Export von Modellen ohne Kontrollfluss nach Onnx ist einfach, denn darauf können Sie sich verlassen Verfolgung. Aber dynamisches Verhalten ist schwieriger zu erreichen;
- Im Gegensatz zu PyTorch bietet ONNX Runtime/TensorRT noch keine native Unterstützung für Multi-GPU-Aufgaben, die Tensor-Parallelität implementieren;
- TensorRT kann nicht zwei Dynamiken für Transformatormodelle mit derselben verwalten Konfigurationsdatei axis. Da Sie jedoch normalerweise Eingaben unterschiedlicher Länge bereitstellen möchten, müssen Sie 1 Modell pro Stapelgröße erstellen.
- Sehr große Modelle sind üblich, aber Onnx (als Protobuff-Datei) weist einige Einschränkungen hinsichtlich der Datei auf Größe und Gewichte müssen außerhalb des Modells gespeichert werden, um das Problem zu lösen.
Eine sehr ärgerliche Tatsache ist, dass neue Modelle niemals beschleunigt werden. Sie müssen warten, bis jemand anderes einen benutzerdefinierten CUDA-Kernel dafür schreibt. Es ist nicht so, dass die vorhandenen Lösungen schlecht wären. Eines der großartigen Dinge an OnnxRuntime ist die Multi-Hardware-Unterstützung, und TensorRT ist dafür bekannt, sehr schnell zu sein.
Also wollten die Projektautoren einen Optimierer haben, der so schnell ist wie TensorRT auf Python/PyTorch, weshalb sie Kernl erstellt haben.
Wie geht das?
Speicherbandbreite ist normalerweise der Engpass beim Deep Learning. Um die Schlussfolgerung zu beschleunigen, ist die Reduzierung des Speicherzugriffs oft eine gute Strategie. Bei kurzen Eingabesequenzen hängt der Engpass normalerweise mit dem CPU-Overhead zusammen, der beseitigt werden muss. Die Projektautoren nutzen hauptsächlich die folgenden drei Technologien:
Die erste ist OpenAI Triton, eine Sprache zum Schreiben von GPU-Kerneln wie CUDA. Verwechseln Sie sie nicht mit dem Nvidia Triton-Inferenzserver, der effizienter ist . Verbesserungen wurden durch die Fusion mehrerer Operationen erzielt, sodass Berechnungen verkettet werden, ohne Zwischenergebnisse im GPU-Speicher zu behalten. Der Autor verwendet es, um Aufmerksamkeit (ersetzt durch Flash Attention), lineare Ebenen und Aktivierungen sowie Layernorm/Rmsnorm neu zu schreiben.
Das zweite ist das CUDA-Diagramm. Während des Aufwärmschritts speichert es jeden gestarteten Kern und seine Parameter. Anschließend rekonstruierten die Projektautoren den gesamten Argumentationsprozess.
Schließlich gibt es noch TorchDynamo, einen von Meta vorgeschlagenen Prototyp, der Projektautoren beim Umgang mit dynamischem Verhalten helfen soll. Während des Aufwärmschritts verfolgt es das Modell und stellt ein Fx-Diagramm (statisches Berechnungsdiagramm) bereit. Sie ersetzten einige Operationen des Fx-Graphen durch ihren eigenen Kernel, der in Python neu kompiliert wurde.
Zukünftig wird die Projekt-Roadmap schnelleres Aufwärmen, unregelmäßige Inferenz (keine Verlustberechnung beim Padding), Trainingsunterstützung (Unterstützung langer Sequenzen), Multi-GPU-Unterstützung (mehrere Parallelisierungsmodi) und Quantisierung (PTQ) umfassen. , Cutlass-Kernel-Tests neuer Chargen und verbesserte Hardware-Unterstützung usw.
Weitere Einzelheiten finden Sie im Originalprojekt.
Das obige ist der detaillierte Inhalt vonDie Programmiersprache OpenAI beschleunigt Berts Denken um das Zwölffache und die Engine erregt Aufmerksamkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wenn Sie Hadoop-Protokolle auf Debian verwalten, können Sie die folgenden Schritte und Best Practices befolgen: Protokollaggregation Aktivieren Sie die Protokollaggregation: Set Garn.log-Aggregation-Enable in true in der Datei marn-site.xml, um die Protokollaggregation zu aktivieren. Konfigurieren von Protokoll-Retentionsrichtlinien: Setzen Sie Garn.log-Aggregation.Retain-Sekunden, um die Retentionszeit des Protokolls zu definieren, z. B. 172800 Sekunden (2 Tage). Log Speicherpfad angeben: über Garn.n
 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
