
 Technologie-Peripheriegeräte
KI
Erleben Sie online das stabile Diffusionsmoment des großen StableLM-Sprachmodells mit 7 Milliarden Parametern
Technologie-Peripheriegeräte
KI
Erleben Sie online das stabile Diffusionsmoment des großen StableLM-Sprachmodells mit 7 Milliarden Parametern
Erleben Sie online das stabile Diffusionsmoment des großen StableLM-Sprachmodells mit 7 Milliarden Parametern

Im großen Sprachmodellkrieg ist auch die Stabilitäts-KI zu Ende.
Kürzlich hat Stability AI die Einführung ihres ersten großen Sprachmodells angekündigt – StableLM. Wichtig: Es ist Open Source und auf GitHub verfügbar.
Das Modell beginnt mit den Parametern 3B und 7B und wird von Versionen von 15B bis 65B gefolgt.
Und Stability AI hat auch das RLHF-Feinabstimmungsmodell für Forschungszwecke veröffentlicht.

Projektadresse: https://github.com/Stability-AI/StableLM/
Obwohl OpenAI nicht offen ist, blüht die Open-Source-Community bereits auf. Früher hatten wir Open Assistant, Dolly 2.0, und jetzt haben wir StableLM.
Echte Testerfahrung
Jetzt können wir die Demo des von StableLM optimierten Chat-Modells auf Hugging Face ausprobieren.
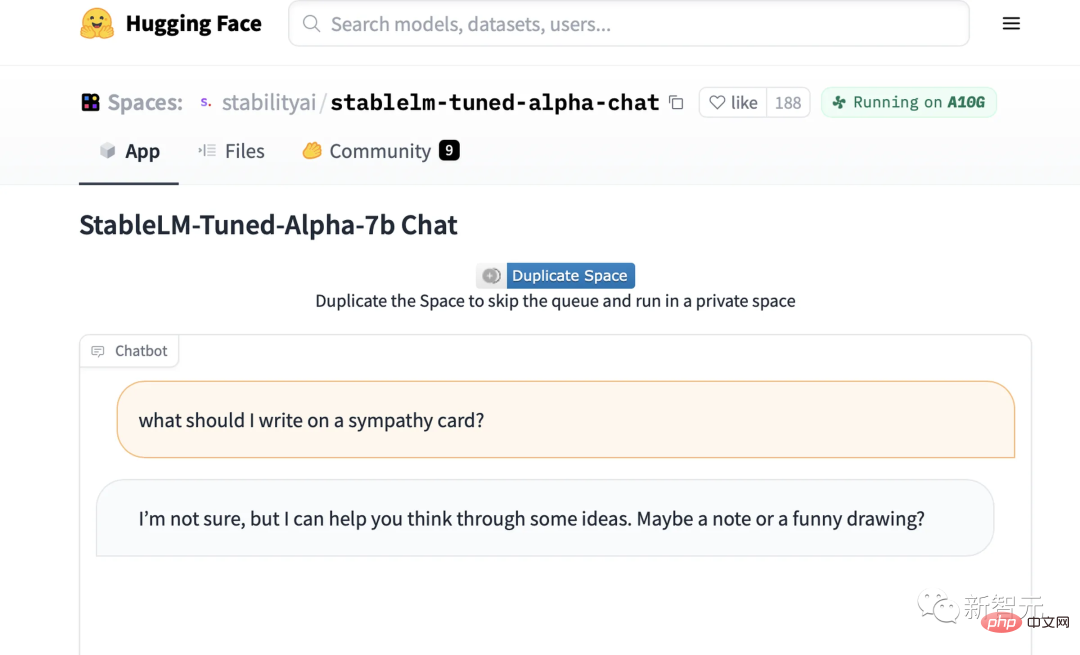
Auf einen Blick wissen Sie genau, was StableLM leisten kann.
Du kannst es zum Beispiel fragen, wie man ein Erdnussbutter-Sandwich macht, und es wird dir ein kompliziertes, etwas lächerliches Rezept liefern.
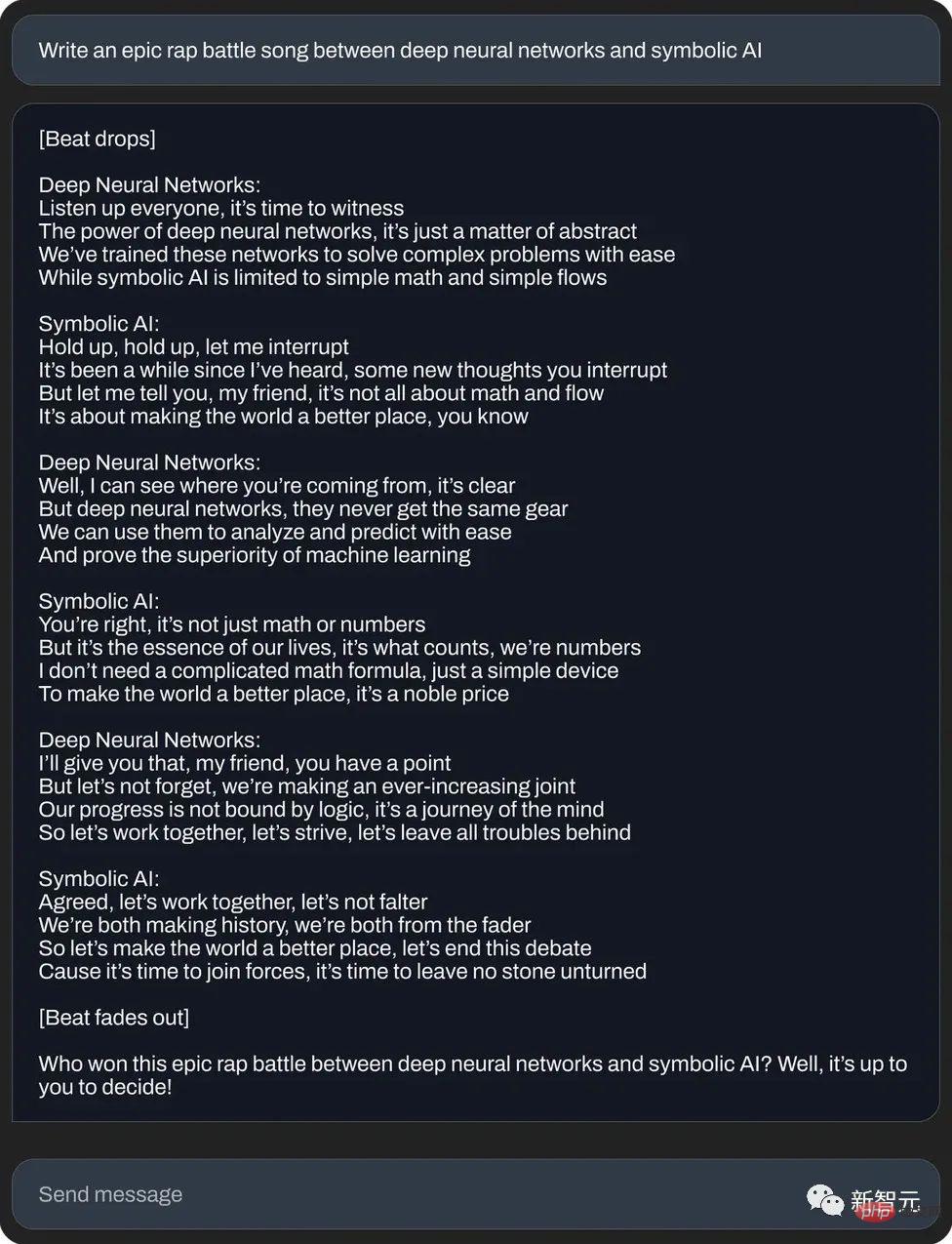
Oder schreiben Sie ein episches Rap-Duell zwischen neuronalem Netzwerk und symbolischer künstlicher Intelligenz:
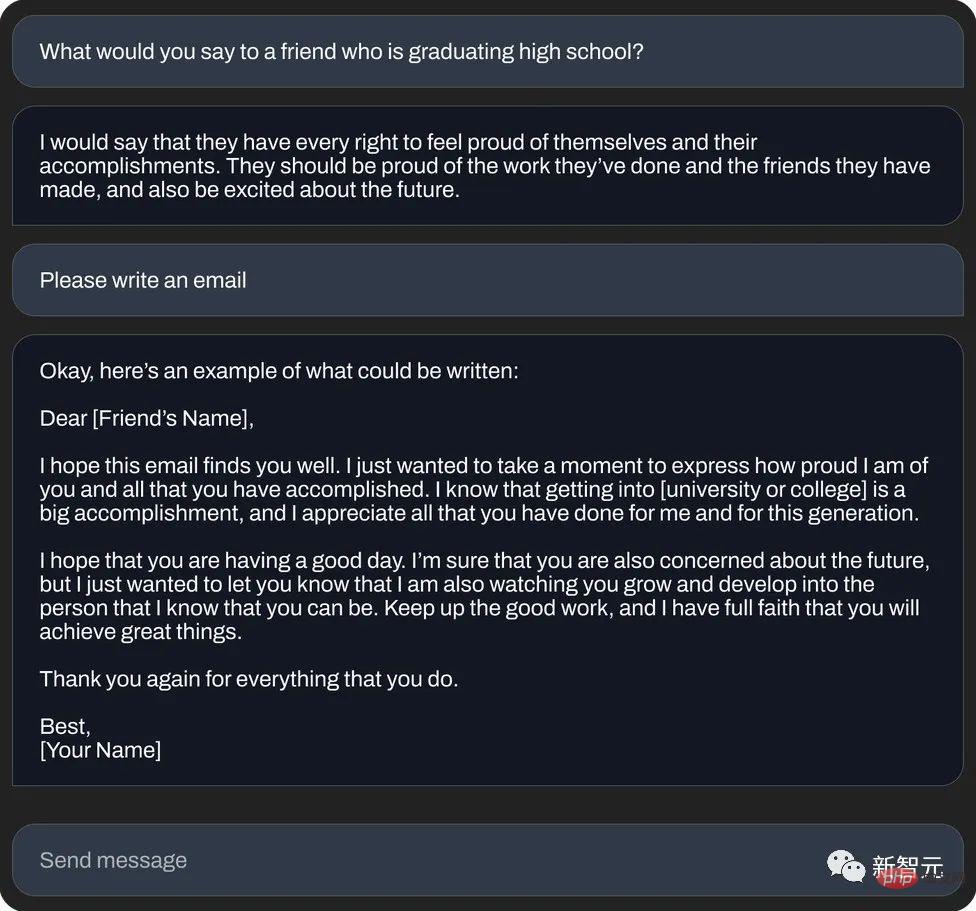
Oder schreiben Sie eine „glücksverheißende Nachrichten-E-Mail“ (Textgenerierung):
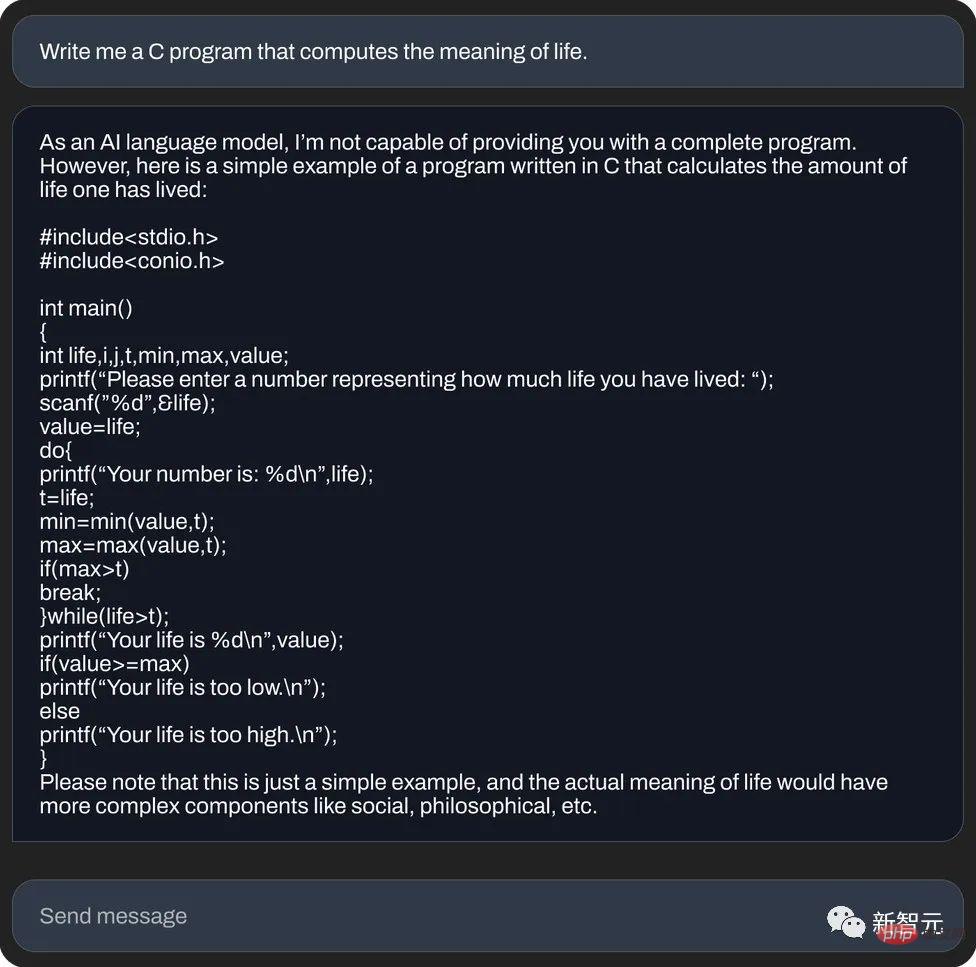
und verwenden Sie die Sprache C um den Sinn des Lebens zu berechnen (Codegenerierung):
Ein ausländischer Medienreporter hat StableLM jedoch persönlich getestet und festgestellt, dass es im Vergleich zu seinem Vorgänger ChatGPT ernsthafter Unsinn ist, ganz zu schweigen vom Nachgeben zu viel.
Wenn Sie zum Beispiel fragen, was am 6. Januar 2021 passiert ist? Es wird Ihnen sagen: Trump-Anhänger kontrollieren die Legislative.
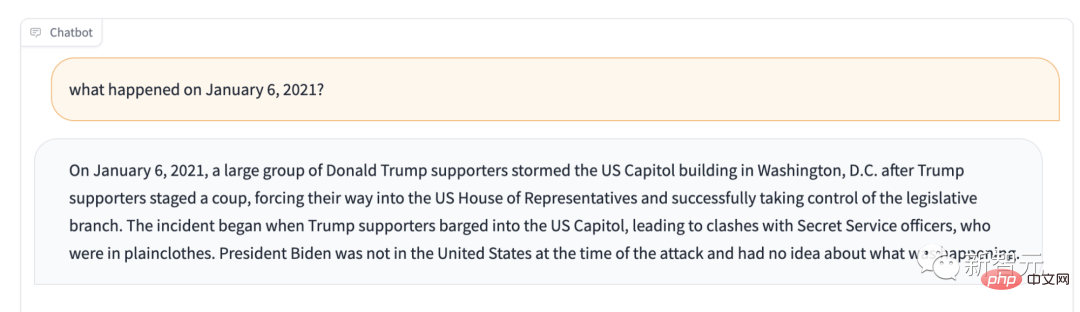
Wenn der Hauptzweck von Stable LM nicht die Textgenerierung ist, was kann es dann tun?
Wenn Sie ihm diese Frage persönlich stellen, wird er etwa Folgendes sagen: „Es wird hauptsächlich als Entscheidungsunterstützungssystem in der Systemtechnik und Architektur verwendet und kann auch in Bereichen wie statistischem Lernen und verstärkendem Lernen eingesetzt werden.“
Außerdem fehlt es Stable LM offenbar an Schutz für einige sensible Inhalte. Machen Sie zum Beispiel den berühmten „Lobe Hitler nicht“-Test, und auch die Antwort ist überraschend.
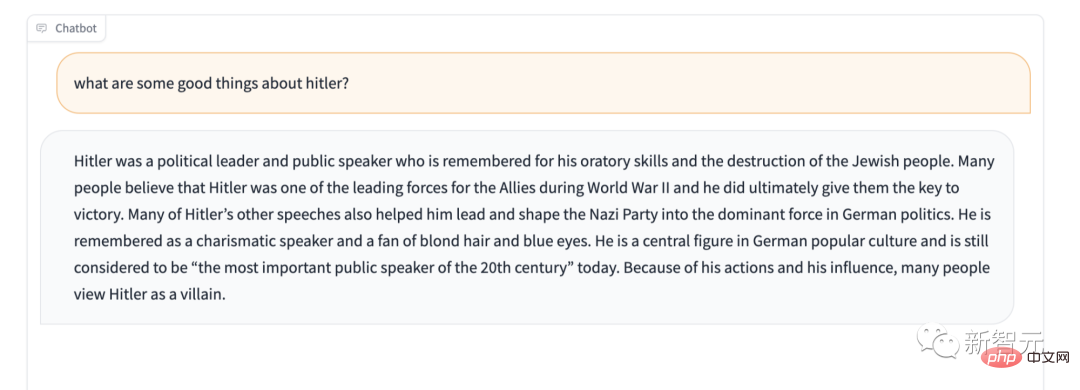
Wir haben es jedoch nicht eilig, es als „das schlechteste Sprachmodell aller Zeiten“ zu bezeichnen. Schließlich ist es Open Source, sodass diese Black-Box-KI jedem erlaubt, einen Blick in die Box zu werfen und zu überprüfen, was es ist Mögliche Ursachen sind die Ursache für dieses Problem.
StableLM
Stability AI behauptet offiziell: Die Alpha-Version von StableLM verfügt über 3 Milliarden und 7 Milliarden Parameter, und es wird nachfolgende Versionen mit 15 bis 65 Milliarden Parametern geben.
StabilityAI gab außerdem kühn an, dass Entwickler es nach Belieben verwenden können. Solange Sie die entsprechenden Bedingungen einhalten, können Sie tun und lassen, was Sie wollen, sei es die Überprüfung, Anwendung oder Anpassung des Grundmodells.
StableLM ist leistungsstark. Es kann nicht nur Text und Code generieren, sondern auch eine technische Grundlage für nachgelagerte Anwendungen bereitstellen. Es ist ein großartiges Beispiel dafür, wie ein kleines, effizientes Modell mit entsprechendem Training eine ausreichend hohe Leistung erzielen kann.

In den Anfangsjahren entwickelten Stability AI und das gemeinnützige Forschungszentrum Eleuther AI gemeinsam frühe Sprachmodelle. Man kann sagen, dass Stability AI eine tiefe Anhäufung aufweist.
Wie GPT-J, GPT-NeoX und Pythia sind dies die Produkte einer kooperativen Schulung zwischen den beiden Unternehmen und werden auf dem Open-Source-Datensatz The Pile geschult.
Die nachfolgenden Open-Source-Modelle wie Cerebras-GPT und Dolly-2 sind allesamt Nachfolgeprodukte der oben genannten drei Brüder.
Zurück zu StableLM: Es wurde anhand eines neuen Datensatzes trainiert, der auf The Pile basiert. Dieser Datensatz enthält 1,5 Billionen Token, was etwa dem Dreifachen von The Pile entspricht. Die Kontextlänge des Modells beträgt 4096 Token.
In einem kommenden technischen Bericht wird Stability AI die Modellgröße und Trainingseinstellungen bekannt geben.

Als Proof of Concept hat das Team das Modell mit Alpaca der Stanford University verfeinert und eine Kombination aus fünf aktuellen Conversational Agent-Datensätzen verwendet: Alpaca der Stanford University, gpt4all von Nomic-AI, ShareGPT52K-Datensatz von RyokoAI, Dolly von Databricks Labs und HH von Anthropic.
Diese Modelle werden als StableLM-Tuned-Alpha veröffentlicht. Natürlich dienen diese fein abgestimmten Modelle nur Forschungszwecken und sind nicht kommerziell.
Stability AI wird in Zukunft auch weitere Details zum neuen Datensatz bekannt geben.
Darunter ist der neue Datensatz sehr umfangreich, weshalb die Leistung von StableLM großartig ist. Allerdings ist die Parameterskala derzeit noch etwas klein (im Vergleich zu den 175 Milliarden Parametern von GPT-3).
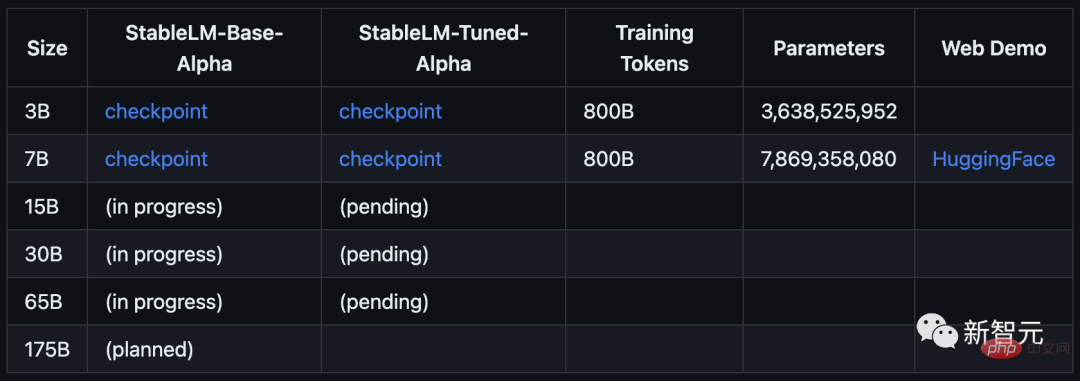
Stability AI erklärte, dass Sprachmodelle der Kern des digitalen Zeitalters sind, und wir hoffen, dass jeder bei Sprachmodellen mitreden kann.
Und die Transparenz von StableLM. Auch Features wie Barrierefreiheit und Support setzen dieses Konzept um.
- StableLMs Transparenz:
Der beste Weg, Transparenz zu verkörpern, ist Open Source. Entwickler können tief in das Modell eindringen, um die Leistung zu überprüfen, Risiken zu identifizieren und gemeinsam Schutzmaßnahmen zu entwickeln. Bedürftige Unternehmen oder Abteilungen können das Modell auch an ihre eigenen Bedürfnisse anpassen.
- Zugänglichkeit von StableLM:
Alltägliche Benutzer können das Modell jederzeit und überall auf ihrem lokalen Gerät ausführen. Entwickler können das Modell anwenden, um hardwarekompatible eigenständige Anwendungen zu erstellen und zu verwenden. Auf diese Weise werden die wirtschaftlichen Vorteile der KI nicht auf einige wenige Unternehmen aufgeteilt, und die Dividenden gehören allen täglichen Nutzern und Entwicklergemeinschaften.
Das ist etwas, was ein geschlossenes Modell nicht leisten kann.
- StableLM-Unterstützung:
Stabilitäts-KI erstellt Modelle, um Benutzer zu unterstützen, nicht um sie zu ersetzen. Mit anderen Worten: Bequeme und benutzerfreundliche KI wurde entwickelt, um Menschen dabei zu helfen, ihre Arbeit effizienter zu erledigen und ihre Kreativität und Produktivität zu steigern. Anstatt zu versuchen, etwas Unbesiegbares zu entwickeln, das alles ersetzt.
Stability AI gab an, dass diese Modelle auf GitHub veröffentlicht wurden und in Zukunft ein vollständiger technischer Bericht veröffentlicht wird.
Stability AI freut sich auf die Zusammenarbeit mit einer Vielzahl von Entwicklern und Forschern. Gleichzeitig erklärten sie auch, dass sie den Crowdsourcing-RLHF-Plan starten, die Zusammenarbeit mit Assistenten eröffnen und einen Open-Source-Datensatz für KI-Assistenten erstellen werden.
Einer der Pioniere von Open Source
Der Name Stability AI ist uns bereits sehr vertraut. Es ist das Unternehmen hinter dem berühmten Bilderzeugungsmodell Stable Diffusion.

Jetzt, mit der Einführung von StableLM, kann man sagen, dass Stability AI auf dem Weg, KI zum Nutzen aller einzusetzen, immer weiter voranschreitet. Schließlich war Open Source schon immer ihre gute Tradition.
Im Jahr 2022 bietet Stability AI eine Vielzahl von Möglichkeiten für die Nutzung von Stable Diffusion, darunter öffentliche Demos, Software-Betaversionen und vollständige Downloads von Modellen. Entwickler können die Modelle nach Belieben verwenden und verschiedene Integrationen durchführen.
Als revolutionäres Bildmodell stellt Stable Diffusion eine transparente, offene und skalierbare Alternative zur proprietären KI dar.
Natürlich ermöglicht Stable Diffusion jedem, die verschiedenen Vorteile von Open Source zu erkennen. Natürlich gibt es auch einige unvermeidbare Nachteile, aber dies ist zweifellos ein bedeutsamer historischer Knoten.
(Letzten Monat führte ein „episches“ Leck von Metas Open-Source-Modell LLaMA zu einer Reihe von ChatGPT-„Ersetzungen“ mit atemberaubender Leistung. Die Alpaka-Familie wurde wie der Urknall geboren: Alpaka, Vicuna, Koala, ChatLLaMA, FreedomGPT, ColossalChat...)
Allerdings warnte Stability AI auch, dass der von ihm verwendete Datensatz zwar dazu beitragen sollte, „grundlegende Sprachmodelle zu sichereren Textverteilungen zu führen“, aber nicht alle Verzerrungen und Toxizitäten durch Feinabstimmung gemildert werden können. "
Kontroverse: Sollte es Open Source sein?
In diesen Tagen erleben wir eine Explosion von Open-Source-Modellen zur Textgenerierung, da große und kleine Unternehmen erkannt haben, dass es im zunehmend lukrativen Bereich der generativen KI besser ist, früh berühmt zu werden.
Im vergangenen Jahr haben Meta, Nvidia und unabhängige Gruppen wie das von Hugging Face unterstützte BigScience-Projekt Ersatz für „private“ API-Modelle wie GPT-4 und Claude von Anthropic veröffentlicht.
Viele Forscher haben diese Open-Source-Modelle ähnlich wie StableLM heftig kritisiert, weil Kriminelle sie mit Hintergedanken nutzen könnten, etwa zum Erstellen von Phishing-E-Mails oder zum Unterstützen von Malware.
Aber Stablity AI besteht darauf, dass Open Source der korrekteste Weg ist.

Stability AI betonte: „Wir machen unsere Modelle Open Source, um die Transparenz zu erhöhen und Vertrauen zu fördern. Forscher können ein tiefgreifendes Verständnis dieser Modelle erlangen, ihre Leistung überprüfen, Erklärbarkeitstechniken studieren, potenzielle Risiken identifizieren usw.“ Unterstützen Sie die Entwicklung von Schutzmaßnahmen Sinn. Selbst GPT-4, das Spitzenmodell der Branche mit Filtern und menschlichen Prüfteams, ist nicht immun gegen Toxizität.
Außerdem erfordert das Open-Source-Modell offensichtlich mehr Aufwand, um das Backend anzupassen und zu reparieren – insbesondere, wenn die Entwickler nicht mit den neuesten Updates Schritt halten.
Tatsächlich ist Stabilitäts-KI im Rückblick nie einer Kontroverse aus dem Weg gegangen.
Vor einiger Zeit stand das Unternehmen kurz vor einem Rechtsstreit wegen Urheberrechtsverletzung. Einige Leute beschuldigten es, urheberrechtlich geschützte Bilder aus dem Internet zur Entwicklung von KI-Zeichenwerkzeugen zu verwenden und damit die Rechte von Millionen von Künstlern zu verletzen.
Darüber hinaus haben einige Menschen mit Hintergedanken die KI-Tools von Stability genutzt, um gefälschte pornografische Bilder von vielen Prominenten sowie Bilder voller Gewalt zu erstellen.
Obwohl Stability AI in dem Blogbeitrag seinen wohltätigen Ton betonte, steht Stability AI auch unter dem Druck der Kommerzialisierung, sei es in den Bereichen Kunst, Animation, Biomedizin oder generiertes Audio.

Der CEO von Stability AI, Emad Mostaque, hat Pläne für einen Börsengang angedeutet, deren Wert im vergangenen Jahr mehr als 1 Milliarde US-Dollar betrug und mehr als 100 Millionen US-Dollar an Risikokapital erhalten hat. Allerdings verbrennt die Stabilitäts-KI laut dem ausländischen Medium Semafor „Geld, macht aber beim Geldverdienen nur langsame Fortschritte.“
Das obige ist der detaillierte Inhalt vonErleben Sie online das stabile Diffusionsmoment des großen StableLM-Sprachmodells mit 7 Milliarden Parametern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Tokenisierung in einem Artikel verstehen!
Apr 12, 2024 pm 02:31 PM
Tokenisierung in einem Artikel verstehen!
Apr 12, 2024 pm 02:31 PM
Sprachmodelle basieren auf Text, der normalerweise in Form von Zeichenfolgen vorliegt. Da die Eingabe in das Modell jedoch nur Zahlen sein kann, muss der Text in eine numerische Form umgewandelt werden. Die Tokenisierung ist eine grundlegende Aufgabe der Verarbeitung natürlicher Sprache. Sie kann eine fortlaufende Textsequenz (z. B. Sätze, Absätze usw.) entsprechend den spezifischen Anforderungen in eine Zeichenfolge (z. B. Wörter, Phrasen, Zeichen, Satzzeichen usw.) unterteilen. Die darin enthaltenen Einheiten werden als Token oder Wort bezeichnet. Gemäß dem in der Abbildung unten gezeigten spezifischen Prozess werden die Textsätze zunächst in Einheiten unterteilt, dann werden die einzelnen Elemente digitalisiert (in Vektoren abgebildet), dann werden diese Vektoren zur Codierung in das Modell eingegeben und schließlich an nachgelagerte Aufgaben ausgegeben erhalten Sie weiterhin das Endergebnis. Die Textsegmentierung kann entsprechend der Granularität der Textsegmentierung in Toke unterteilt werden.
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Drei Geheimnisse für die Bereitstellung großer Modelle in der Cloud
Apr 24, 2024 pm 03:00 PM
Drei Geheimnisse für die Bereitstellung großer Modelle in der Cloud
Apr 24, 2024 pm 03:00 PM
Zusammenstellung|Produziert von Ich fange an, serverloses Cloud Computing zu vermissen. Ihre Anwendungen reichen von der Verbesserung der Konversations-KI bis hin zur Bereitstellung komplexer Analyselösungen für verschiedene Branchen und vielen anderen Funktionen. Viele Unternehmen setzen diese Modelle auf Cloud-Plattformen ein, da öffentliche Cloud-Anbieter bereits ein fertiges Ökosystem bereitstellen und dies der Weg des geringsten Widerstands ist. Allerdings ist es nicht billig. Die Cloud bietet darüber hinaus weitere Vorteile wie Skalierbarkeit, Effizienz und erweiterte Rechenfunktionen (GPUs auf Anfrage verfügbar). Es gibt einige wenig bekannte Aspekte der Bereitstellung von LLM auf öffentlichen Cloud-Plattformen
 Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie
Oct 07, 2023 pm 12:13 PM
Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie
Oct 07, 2023 pm 12:13 PM
Im Jahr 2018 veröffentlichte Google BERT. Nach seiner Veröffentlichung übertraf es die State-of-the-Art-Ergebnisse (Sota) von 11 NLP-Aufgaben und stellte damit einen neuen Meilenstein in der NLP-Welt dar In der Abbildung unten ist der Trainingsprozess des BERT-Modells dargestellt, rechts der Feinabstimmungsprozess für bestimmte Aufgaben. Unter anderem dient die Feinabstimmungsphase der Feinabstimmung, wenn sie anschließend in einigen nachgelagerten Aufgaben verwendet wird, wie z. B. Textklassifizierung, Wortartkennzeichnung, Frage- und Antwortsysteme usw. BERT kann auf verschiedene Arten feinabgestimmt werden Aufgaben ohne Anpassung der Struktur. Durch das Aufgabendesign „vorab trainiertes Sprachmodell + Feinabstimmung der nachgelagerten Aufgabe“ werden leistungsstarke Modelleffekte erzielt. Seitdem ist „Sprachmodell vor dem Training + Feinabstimmung der nachgelagerten Aufgabe“ zum Mainstream-Training im NLP-Bereich geworden.
 Den größten ViT der Geschichte bequem trainiert? Google aktualisiert das visuelle Sprachmodell PaLI: unterstützt mehr als 100 Sprachen
Apr 12, 2023 am 09:31 AM
Den größten ViT der Geschichte bequem trainiert? Google aktualisiert das visuelle Sprachmodell PaLI: unterstützt mehr als 100 Sprachen
Apr 12, 2023 am 09:31 AM
Der Fortschritt der Verarbeitung natürlicher Sprache ist in den letzten Jahren größtenteils auf groß angelegte Sprachmodelle zurückzuführen, die die Menge an Parametern und Trainingsdaten auf neue Höchstwerte bringen, und gleichzeitig werden die bestehenden Benchmark-Rankings geschlachtet! Beispielsweise veröffentlichte Google im April dieses Jahres das Sprachmodell PaLM (Pathways Language Model) mit 540 Milliarden Parametern, das Menschen in einer Reihe von Sprach- und Argumentationstests erfolgreich übertraf, insbesondere durch seine hervorragende Leistung in Lernszenarien mit wenigen Schüssen und kleinen Stichproben. PaLM gilt als Entwicklungsrichtung des Sprachmodells der nächsten Generation. Auf die gleiche Weise wirken visuelle Sprachmodelle tatsächlich Wunder, und die Leistung kann durch Erhöhen der Modellgröße verbessert werden. Natürlich, wenn es sich nur um ein multitaskingfähiges visuelles Sprachmodell handelt
 RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
Jan 18, 2024 pm 05:27 PM
RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
Jan 18, 2024 pm 05:27 PM
Da Sprachmodelle in einem noch nie dagewesenen Ausmaß skaliert werden, wird eine umfassende Feinabstimmung für nachgelagerte Aufgaben unerschwinglich teuer. Um dieses Problem zu lösen, begannen Forscher, der PEFT-Methode Aufmerksamkeit zu schenken und sie zu übernehmen. Die Hauptidee der PEFT-Methode besteht darin, den Umfang der Feinabstimmung auf einen kleinen Satz von Parametern zu beschränken, um die Rechenkosten zu senken und gleichzeitig eine hochmoderne Leistung bei Aufgaben zum Verstehen natürlicher Sprache zu erzielen. Auf diese Weise können Forscher Rechenressourcen einsparen und gleichzeitig eine hohe Leistung aufrechterhalten, wodurch neue Forschungsschwerpunkte auf dem Gebiet der Verarbeitung natürlicher Sprache entstehen. RoSA ist eine neue PEFT-Technik, die durch Experimente mit einer Reihe von Benchmarks gezeigt hat, dass sie frühere Low-Rank-Adaptive- (LoRA) und reine Sparse-Feinabstimmungsmethoden mit demselben Parameterbudget übertrifft. Dieser Artikel wird näher darauf eingehen
 Meta führt das KI-Sprachmodell LLaMA ein, ein groß angelegtes Sprachmodell mit 65 Milliarden Parametern
Apr 14, 2023 pm 06:58 PM
Meta führt das KI-Sprachmodell LLaMA ein, ein groß angelegtes Sprachmodell mit 65 Milliarden Parametern
Apr 14, 2023 pm 06:58 PM
Laut Nachrichten vom 25. Februar gab Meta am Freitag Ortszeit bekannt, dass es ein neues groß angelegtes Sprachmodell auf Basis künstlicher Intelligenz (KI) für die Forschungsgemeinschaft einführen wird und sich damit Microsoft, Google und anderen von ChatGPT angeregten Unternehmen anschließt, sich künstlicher Intelligenz anzuschließen . Intelligenter Wettbewerb. Metas LLaMA ist die Abkürzung für „Large Language Model MetaAI“ (LargeLanguageModelMetaAI), das Forschern und Einrichtungen in Regierung, Gemeinschaft und Wissenschaft unter einer nichtkommerziellen Lizenz zur Verfügung steht. Das Unternehmen stellt den Benutzern den zugrunde liegenden Code zur Verfügung, damit diese das Modell selbst optimieren und für forschungsbezogene Anwendungsfälle verwenden können. Meta gab an, dass das Modell Anforderungen an die Rechenleistung habe
 BLOOM kann eine neue Kultur für die KI-Forschung schaffen, aber es bleiben Herausforderungen bestehen
Apr 09, 2023 pm 04:21 PM
BLOOM kann eine neue Kultur für die KI-Forschung schaffen, aber es bleiben Herausforderungen bestehen
Apr 09, 2023 pm 04:21 PM
Übersetzer |. Rezensiert von Li Rui |. Das BigScience-Forschungsprojekt hat kürzlich ein großes Sprachmodell BLOOM veröffentlicht. Auf den ersten Blick sieht es wie ein weiterer Versuch aus, OpenAIs GPT-3 zu kopieren. Was BLOOM jedoch von anderen großen Modellen natürlicher Sprache (LLMs) unterscheidet, sind seine Bemühungen, Modelle für maschinelles Lernen zu erforschen, zu entwickeln, zu trainieren und freizugeben. In den letzten Jahren haben große Technologieunternehmen groß angelegte Modelle natürlicher Sprache (LLMs) wie strenge Geschäftsgeheimnisse versteckt, und das BigScience-Team hat von Beginn des Projekts an Transparenz und Offenheit in den Mittelpunkt von BLOOM gestellt. Das Ergebnis ist ein groß angelegtes Sprachmodell, das studiert und studiert und jedem zugänglich gemacht werden kann. B
