
 Technologie-Peripheriegeräte
KI
Neue Untersuchungen des Teams von Stanford Li Feifei ergaben, dass das Entwerfen, Verbessern und Auswerten von Daten der Schlüssel zum Erreichen einer vertrauenswürdigen künstlichen Intelligenz ist
Technologie-Peripheriegeräte
KI
Neue Untersuchungen des Teams von Stanford Li Feifei ergaben, dass das Entwerfen, Verbessern und Auswerten von Daten der Schlüssel zum Erreichen einer vertrauenswürdigen künstlichen Intelligenz ist
Neue Untersuchungen des Teams von Stanford Li Feifei ergaben, dass das Entwerfen, Verbessern und Auswerten von Daten der Schlüssel zum Erreichen einer vertrauenswürdigen künstlichen Intelligenz ist

Angesichts des aktuellen Trends, dass sich die Entwicklung von KI-Modellen von modellzentriert zu datenzentriert verlagert, ist die Qualität der Daten besonders wichtig geworden.
Im vergangenen KI-Entwicklungsprozess ist der Datensatz normalerweise festgelegt, und die Entwicklungsarbeit konzentriert sich auf die Iteration der Modellarchitektur oder des Trainingsprozesses, um die Basisleistung zu verbessern. Jetzt, da die Dateniteration im Mittelpunkt steht, benötigen wir systematischere Methoden zum Auswerten, Filtern, Bereinigen und Kommentieren der Daten, die zum Trainieren und Testen von KI-Modellen verwendet werden.
Kürzlich veröffentlichten Weixin Liang, Li Feifei und andere vom Department of Computer Science der Stanford University gemeinsam einen Artikel in „Nature-Machine Intelligence“ mit dem Titel „Fortschritte, Herausforderungen und Chancen bei der Datenerstellung für vertrauenswürdige KI“. „Der Artikel diskutiert die Schlüsselfaktoren und Methoden zur Sicherstellung der Datenqualität in jedem Aspekt des gesamten KI-Datenprozesses.

Paper address: https://www.nature.com/articles/s42256-022-00516-1.epdf?sharing_token=VPzI-KWAm8tLG_BiXJnV9tRgN0jAjWel9j nR3ZoTv0MRS1pu9dXg73FQ0NTrwhu7Hi_VBEr6peszIAFc6XO1tdlvV1lLJQtOvUFnSXpvW6_nu0Knc_dRekx6lyZNc6PcM1nslocIcut_qNW9OUg1IsbCfuL058R4MsYFqyzlb2E %3D# 🎜🎜#
Zu den Hauptschritten im KI-Datenprozess gehören: Datendesign (Datenerfassung und -aufzeichnung), Datenverbesserung (Datenfilterung, Bereinigung, Annotation, Verbesserung) sowie Auswertung und Überwachung von KI-Modelle Datenstrategie, jeder Aspekt davon wird die Glaubwürdigkeit des endgültigen KI-Modells beeinflussen.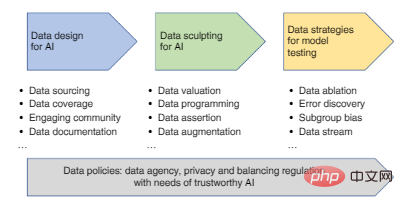
2. Daten verbessern: filtern, bereinigen, kennzeichnen, verbessern
Nachdem der erste Datensatz erfasst wurde, müssen wir die Daten weiter verbessern, um effektivere Daten für die KI-Entwicklung bereitzustellen. Dies ist der Hauptunterschied zwischen modellzentrierten KI-Ansätzen und datenzentrierten Ansätzen, wie in Abbildung 2a dargestellt. Modellzentrierte Forschung basiert normalerweise auf vorgegebenen Daten und konzentriert sich auf die Verbesserung der Modellarchitektur oder die Optimierung dieser Daten. Die datenzentrierte Forschung hingegen konzentriert sich auf skalierbare Methoden zur systematischen Verbesserung von Daten durch Prozesse wie Datenbereinigung, Filterung, Annotation und Verbesserung und kann eine Modellentwicklungsplattform aus einer Hand nutzen.

Abbildung 2a: Vergleich von KI-modellzentrierten und datenzentrierten Ansätzen. MNIST, COCO und ImageNet sind häufig verwendete Datensätze in der KI-Forschung.
Datenüberprüfung
Wenn der Datensatz sehr verrauscht ist, müssen wir die Daten vor dem Training sorgfältig überprüfen, was die Zuverlässigkeit und Verallgemeinerung des Modells erheblich verbessern kann. Das Flugzeugbild in Abbildung 2a ist der verrauschte Datenpunkt, der aus dem Vogeldatensatz entfernt werden sollte.
In Abbildung 2b schneiden vier hochmoderne Modelle, die auf zuvor verwendeten großen dermatologischen Daten trainiert wurden, aufgrund von Verzerrungen in den Trainingsdaten alle schlecht ab, wobei die Diagnose bei Bildern mit dunkler Haut besonders schlecht ist, während Modell 1, das auf kleineren, Hochwertige Daten sind sowohl bei dunklen als auch bei hellen Hauttönen relativ zuverlässiger.
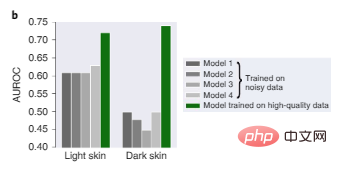
Abbildung 2b: Leistung des Dermatologie-Diagnosetests auf Bildern mit heller Haut und dunkler Haut.
Abbildung 2c zeigt, dass ResNet, DenseNet und VGG, drei beliebte Deep-Learning-Architekturen für die Bildklassifizierung, alle eine schlechte Leistung erbringen, wenn sie auf verrauschten Bilddatensätzen trainiert werden. Nach der Daten-Shapley-Wertfilterung werden Daten schlechter Qualität gelöscht und das auf einer saubereren Datenteilmenge trainierte ResNet-Modell weist eine deutlich bessere Leistung auf.
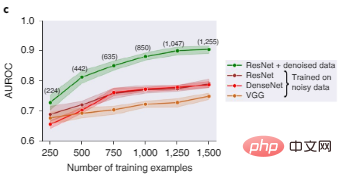
Abbildung 2c: Vergleich der Objekterkennungstestleistung verschiedener Modelle vor und nach der Datenfilterung. Die Zahlen in Klammern stellen die Anzahl der Trainingsdatenpunkte dar, die nach dem Herausfiltern verrauschter Daten verbleiben, wobei die Ergebnisse über fünf zufällige Startwerte aggregiert werden, und der schattierte Bereich stellt das 95 %-Konfidenzintervall dar.
Darum geht es bei der Datenauswertung. Sie zielt darauf ab, die Bedeutung verschiedener Daten zu quantifizieren und Daten herauszufiltern, die aufgrund schlechter Qualität oder Verzerrung die Modellleistung beeinträchtigen könnten.
Datenbereinigung
In diesem Artikel stellt der Autor zwei Datenauswertungsmethoden vor, um die Datenbereinigung zu unterstützen:
Eine Methode besteht darin, die Änderung der KI-Modellleistung zu messen, wenn verschiedene Daten während des Trainingsprozesses gelöscht werden, was Shapley verwenden kann des Datenwerts oder der Einflussnäherung, wie in Abbildung 3a unten dargestellt. Dieser Ansatz ermöglicht eine effiziente rechnerische Auswertung großer KI-Modelle.
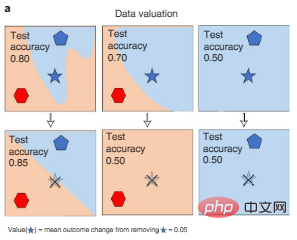
Abbildung 3a: Datenauswertung. Der Shapley-Wert der Daten misst die Leistungsänderung eines Modells, das auf verschiedenen Teilmengen der Daten trainiert wurde, wenn ein bestimmter Punkt aus dem Training entfernt wird (der verblasste fünfzackige Stern, der in der Abbildung durchgestrichen ist), und quantifiziert so jeden Datenpunkt (den fünfzackiges Sternsymbol) Wert. Farben repräsentieren Kategoriebezeichnungen.
Ein anderer Ansatz besteht darin, die Unsicherheit vorherzusagen, um Datenpunkte schlechter Qualität zu erkennen. Menschliche Anmerkungen zu Datenpunkten können systematisch von den Vorhersagen des KI-Modells abweichen, und Algorithmen zum Vertrauenslernen können diese Abweichungen erkennen, wobei sich herausstellte, dass mehr als 3 % der Testdaten bei gängigen Benchmarks wie ImageNet falsch beschriftet waren. Das Herausfiltern dieser Fehler kann die Modellleistung erheblich verbessern.
Datenanmerkungen
Datenanmerkungen sind ebenfalls eine Hauptquelle für Datenverzerrungen. Obwohl KI-Modelle ein gewisses Maß an zufälligem Label-Rauschen tolerieren können, können voreingenommene Fehler zu voreingenommenen Modellen führen. Derzeit verlassen wir uns hauptsächlich auf die manuelle Annotation, was sehr teuer ist. Da es sich um dreidimensionale Daten handelt, muss der Annotator einen dreidimensionalen Begrenzungsrahmen zeichnen ist anspruchsvoller als allgemeine Anmerkungsaufgaben.
Daher ist der Autor der Ansicht, dass wir Annotationstools auf Crowdsourcing-Plattformen wie MTurk sorgfältig kalibrieren müssen, um konsistente Annotationsregeln bereitzustellen. Im medizinischen Umfeld ist es auch wichtig zu berücksichtigen, dass Annotatoren möglicherweise spezielles Wissen benötigen oder über sensible Daten verfügen, die nicht durch Crowdsourcing gewonnen werden können.
Eine Möglichkeit, die Annotationskosten zu senken, ist die Datenprogrammierung. Bei der Datenprogrammierung müssen KI-Entwickler Datenpunkte nicht mehr manuell kennzeichnen, sondern schreiben stattdessen programmatische Kennzeichnungsfunktionen, um Trainingssätze automatisch zu kennzeichnen. Wie in Abbildung 3b dargestellt, können wir nach der automatischen Generierung mehrerer potenziell verrauschter Beschriftungen für jede Eingabe mithilfe einer benutzerdefinierten Beschriftungsfunktion zusätzliche Algorithmen entwerfen, um mehrere Beschriftungsfunktionen zu aggregieren und so das Rauschen zu reduzieren.
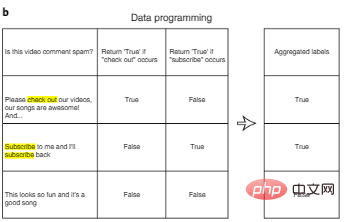
Abbildung 3b: Datenprogrammierung.
Ein weiterer „Human-in-the-Loop“-Ansatz zur Reduzierung der Kennzeichnungskosten besteht darin, die wertvollsten Daten zu priorisieren, damit wir sie durch aktives Lernen kennzeichnen können. Beim aktiven Lernen werden Ideen aus dem optimalen experimentellen Design abgeleitet. Beim aktiven Lernen wählt der Algorithmus die informativsten Punkte aus einer Reihe unbeschrifteter Datenpunkte aus, z. B. Punkte mit hohem Informationsgewinn oder Punkte, bei denen das Modell Unsicherheit aufweist, und führt sie dann manuell aus Anmerkung. Der Vorteil dieses Ansatzes besteht darin, dass die erforderliche Datenmenge viel geringer ist als die, die für standardmäßiges überwachtes Lernen erforderlich ist.
Datenerweiterung
Wenn schließlich die vorhandenen Daten noch sehr begrenzt sind, ist die Datenerweiterung eine wirksame Methode, um den Datensatz zu erweitern und die Zuverlässigkeit des Modells zu verbessern.
Computer-Vision-Daten können durch Bilddrehung, Spiegelung und andere digitale Transformationen verbessert werden, und Textdaten können durch Transformation automatischer Schreibstile verbessert werden. Es gibt auch das neuere Mixup, eine komplexere Erweiterungstechnik, die neue Trainingsdaten durch Interpolation von Trainingsmusterpaaren erstellt, wie in Abbildung 3c dargestellt.
Neben der manuellen Datenanreicherung ist auch der aktuelle automatisierte KI-Datenanreicherungsprozess eine beliebte Lösung. Wenn unbeschriftete Daten verfügbar sind, kann die Beschriftungserweiterung außerdem auch erreicht werden, indem ein anfängliches Modell verwendet wird, um Vorhersagen zu treffen (diese Vorhersagen werden Pseudo-Labels genannt) und dann ein größeres Modell auf den kombinierten Daten mit echten und hochzuverlässigen Pseudo-Labels trainiert wird. Etiketten.
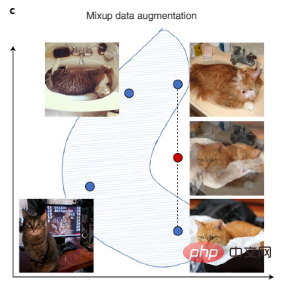
Abbildung 3c: Mixup erweitert den Datensatz durch die Erstellung synthetischer Daten, die vorhandene Daten interpolieren. Blaue Punkte stellen vorhandene Datenpunkte im Trainingssatz dar und rote Punkte stellen synthetische Datenpunkte dar, die durch Interpolation zweier vorhandener Datenpunkte erstellt wurden.
3. Daten zur Bewertung und Überwachung von KI-Modellen
Nachdem das Modell trainiert wurde, ist das Ziel der KI-Bewertung die Generalisierbarkeit und Glaubwürdigkeit des Modells.
Um dieses Ziel zu erreichen, sollten wir die Bewertungsdaten sorgfältig entwerfen, um die realen Einstellungen des Modells zu ermitteln, und die Bewertungsdaten müssen sich außerdem ausreichend von den Trainingsdaten des Modells unterscheiden.
In der medizinischen Forschung beispielsweise werden KI-Modelle meist auf der Grundlage von Daten einer kleinen Anzahl von Krankenhäusern trainiert. Wenn ein solches Modell in einem neuen Krankenhaus eingesetzt wird, nimmt seine Genauigkeit aufgrund von Unterschieden bei der Datenerfassung und -verarbeitung ab. Um die Verallgemeinerung des Modells zu bewerten, ist es notwendig, Bewertungsdaten aus verschiedenen Krankenhäusern und verschiedenen Datenverarbeitungspipelines zu sammeln. In anderen Anwendungen sollten Bewertungsdaten aus verschiedenen Quellen gesammelt und vorzugsweise von verschiedenen Annotatoren als Trainingsdaten gekennzeichnet werden. Gleichzeitig bleiben qualitativ hochwertige menschliche Etiketten die wichtigste Bewertung.
Eine wichtige Rolle der KI-Bewertung besteht darin, festzustellen, ob das KI-Modell falsche Korrelationen als „Abkürzungen“ in Trainingsdaten verwendet, die Konzepte nicht gut bilden können. Beispielsweise kann in der medizinischen Bildgebung die Art und Weise der Datenverarbeitung (z. B. Zuschneiden oder Bildkomprimierung) zu falschen Korrelationen (d. h. Verknüpfungen) führen, die vom Modell erfasst werden. Diese Verknüpfungen können auf den ersten Blick hilfreich sein, können jedoch katastrophal fehlschlagen, wenn das Modell in einer etwas anderen Umgebung bereitgestellt wird.
Die systematische Datenablation ist eine großartige Möglichkeit, mögliche Modell-„Abkürzungen“ zu untersuchen. Bei der Datenablation werden KI-Modelle anhand abgetragener Eingaben falsch korrelierter Oberflächensignale trainiert und getestet.
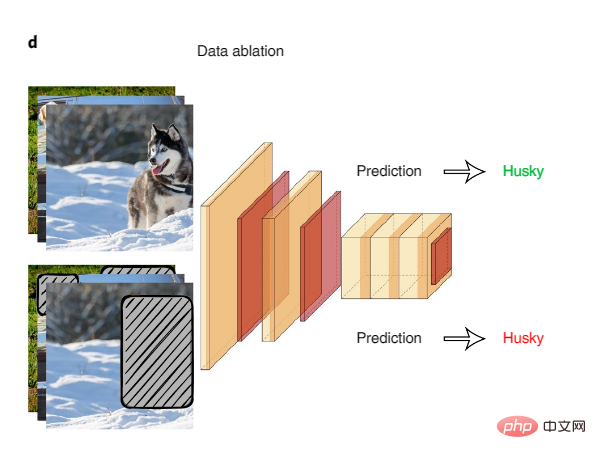
Abbildung 4: Datenablation
Ein Beispiel für die Verwendung der Datenablation zur Erkennung von Modellverknüpfungen ist, dass eine Studie an einem gängigen Inferenzdatensatz in natürlicher Sprache ergab, dass KI-Modelle, die nur auf der ersten Hälfte der Texteingabe trainierten, eine hohe Genauigkeit erreichten beim Ableiten logischer Beziehungen zwischen der ersten und zweiten Texthälfte, wohingegen Menschen bei derselben Eingabe ungefähr das gleiche Niveau erreichen würden wie zufälliges Raten. Dies deutet darauf hin, dass KI-Modelle falsche Korrelationen als Abkürzung nutzen, um diese Aufgabe zu erfüllen. Das Forschungsteam stellte fest, dass bestimmte sprachliche Phänomene von KI-Modellen ausgenutzt werden, beispielsweise die Verneinung in Texten, die stark mit Tags korreliert.
Datenablation wird in verschiedenen Bereichen häufig eingesetzt. Beispielsweise können im medizinischen Bereich biologisch relevante Teile eines Bildes ausgeblendet werden, um zu beurteilen, ob die KI aus einem falschen Hintergrund oder einem Artefakt der Bildqualität lernt.
Die KI-Bewertung beschränkt sich oft auf den Vergleich der Gesamtleistungsmetriken über einen gesamten Testdatensatz hinweg. Aber selbst wenn ein KI-Modell auf der Gesamtdatenebene gut funktioniert, kann es dennoch systematische Fehler in bestimmten Untergruppen der Daten aufweisen, und die Charakterisierung von Clustern dieser Fehler kann zu einem besseren Verständnis der Einschränkungen des Modells führen.
Wenn Metadaten verfügbar sind, sollten feinkörnige Bewertungsmethoden die Bewertungsdaten wann immer möglich nach Geschlecht, Geschlecht, Rasse und geografischem Standort der Teilnehmer im Datensatz aufteilen – zum Beispiel „älterer asiatischer Mann“ oder „weibliche amerikanische Ureinwohner“ – und quantifizieren Sie die Leistung des Modells für jede Untergruppe von Daten. Multi-Accuracy-Auditing ist ein Algorithmus, der automatisch nach Untergruppen von Daten sucht, bei denen KI-Modelle eine schlechte Leistung erbringen. Hier werden Prüfalgorithmen darauf trainiert, mithilfe von Metadaten die Fehler des Originalmodells vorherzusagen und zu gruppieren und dann erklärbare Antworten auf Fragen zu liefern, etwa welche Fehler das KI-Modell gemacht hat und warum.
Wenn keine Metadaten verfügbar sind, identifizieren Methoden wie Domino automatisch Datencluster, in denen Bewertungsmodelle fehleranfällig sind, und nutzen die Textgenerierung, um Erklärungen dieser Modellfehler in natürlicher Sprache zu erstellen.
4. Die Zukunft der Daten
Derzeit entwickeln die meisten KI-Forschungsprojekte Datensätze nur einmal, aber reale KI-Benutzer müssen Datensätze und Modelle oft kontinuierlich aktualisieren. Die kontinuierliche Datenentwicklung bringt folgende Herausforderungen mit sich:
Erstens können sich sowohl die Daten als auch die KI-Aufgaben im Laufe der Zeit ändern: Beispielsweise erscheint möglicherweise ein neues Fahrzeugmodell auf der Straße (d. h. Domänenverschiebung) oder möglicherweise die KI A Der Entwickler möchte eine neue Klasse von Objekten erkennen (z. B. einen Schulbustyp, der sich von einem regulären Bus unterscheidet), wodurch sich die Klassifizierung des Labels ändert. Es wäre verschwenderisch, Millionen Stunden alter Tag-Daten wegzuwerfen, daher sind Aktualisierungen unerlässlich. Darüber hinaus sollten Trainings- und Bewertungsmetriken sorgfältig entworfen werden, um neue Daten abzuwägen und geeignete Daten für jede Teilaufgabe zu verwenden.
Zweitens müssen Benutzer die meisten datenzentrierten KI-Prozesse automatisieren, um kontinuierlich Daten zu erfassen und zu nutzen. Diese Automatisierung beinhaltet die Verwendung von Algorithmen, um auszuwählen, welche Daten an den Annotator gesendet werden sollen und wie sie zum erneuten Trainieren des Modells verwendet werden sollen. Der Modellentwickler wird nur dann benachrichtigt, wenn dabei etwas schief geht (z. B. wenn die Genauigkeitsmetriken sinken). Im Rahmen des Trends „MLOps (Machine Learning Operations)“ beginnen Industrieunternehmen, Tools zur Automatisierung des maschinellen Lernlebenszyklus einzusetzen.
Das obige ist der detaillierte Inhalt vonNeue Untersuchungen des Teams von Stanford Li Feifei ergaben, dass das Entwerfen, Verbessern und Auswerten von Daten der Schlüssel zum Erreichen einer vertrauenswürdigen künstlichen Intelligenz ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
