

Was ist das Implementierungsprinzip der Python-Funktion?

Wedge
Funktion ist ein Grundelement jeder Programmiersprache. Sie kann mehrere auszuführende Operationen kombinieren. Und was wird beim Aufruf der Funktion getan? Ja, für die Ausführung der Funktion muss ein Stack-Frame erstellt werden.
PyFunctionObject
Alles in Python ist ein Objekt und Funktionen sind keine Ausnahme. Die Funktion wird unten durch die PyFunctionObject-Struktur implementiert, die in funcobject.h definiert ist.
typedef struct {
/* 头部信息,无需多说 */
PyObject_HEAD
/* 函数对应的 PyCodeObject 对象
因为函数也是基于 PyCodeObject 对象构建的 */
PyObject *func_code;
/* 函数的 global 名字空间 */
PyObject *func_globals;
/* 函数参数的默认值,一个元组或者空 */
PyObject *func_defaults;
/* 只能通过关键字的方式传递的 "参数" 和 "该参数的默认值" 组成的字典
或者空 */
PyObject *func_kwdefaults;
/* 闭包 */
PyObject *func_closure;
/* 函数的 docstring */
PyObject *func_doc;
/* 函数名 */
PyObject *func_name;
/* 函数的属性字典,一般为空 */
PyObject *func_dict;
/* 弱引用列表,对函数的弱引用都会保存在里面 */
PyObject *func_weakreflist;
/* 函数所在的模块 */
PyObject *func_module;
/* 函数的类型注解 */
PyObject *func_annotations;
/* 函数的全限定名 */
PyObject *func_qualname;
/* Python 函数在底层也是某个类(PyFunction_Type)的实例对象
调用时会执行类型对象的 tp_call,在 Python 里面就是 __call__
但函数比较特殊,它创建出来就是为了调用的,所以不能走通用的 tp_call
为了优化调用效率,引入了 vectorcall */
vectorcallfunc vectorcall;
} PyFunctionObject;Lassen Sie uns diese Mitglieder tatsächlich holen und sehen, wie sie sich in Python verhalten.
func_code: Bytecode der Funktion
def foo(a, b, c):
pass
code = foo.__code__
print(code) # <code object foo at ......>
print(code.co_varnames) # ('a', 'b', 'c')func_globals: globaler Namespace
def foo(a, b, c):
pass
name = "古明地觉"
print(foo.__globals__) # {......, 'name': '古明地觉'}
# 拿到的其实就是外部的 global名字空间
print(foo.__globals__ is globals()) # Truefunc_defaults: Standardwerte der Funktionsparameter
def foo(name="古明地觉", age=16):
pass
# 打印的是默认值
print(foo.__defaults__) # ('古明地觉', 16)
def bar():
pass
# 没有默认值的话,__defaults__ 为 None
print(bar.__defaults__) # Nonefunc_k wdefaults: Nur durch Schlüsselwörter Das Wörterbuch besteht des übergebenen „Parameters“ und „des Standardwerts des Parameters“
def foo(name="古明地觉", age=16):
pass
# 打印为 None,这是因为虽然有默认值
# 但并不要求必须通过关键字参数的方式传递
print(foo.__kwdefaults__) # None
def bar(*, name="古明地觉", age=16):
pass
print(
bar.__kwdefaults__
) # {'name': '古明地觉', 'age': 16}ist ein * vorangestellt, was bedeutet, dass die folgenden Parameter über Schlüsselwörter übergeben werden müssen. Denn wenn sie nicht über Schlüsselwortparameter übergeben werden, können sie, egal wie viele Positionsparameter von * empfangen werden, sowieso nicht an Name oder Alter übergeben werden.
Wir wissen, dass die Funktion bei Definition von *args eine beliebige Anzahl von Positionsparametern empfangen kann und diese Parameter dann in Form von Tupeln in args gespeichert werden. Aber wir brauchen es hier nicht, wir wollen nur, dass die nachfolgenden Parameter durch Schlüsselwortparameter übergeben werden, also schreiben Sie einfach ein * davor. Natürlich ist auch das Schreiben von *args möglich.
func_closure: Verschlussobjekt
def foo():
name = "古明地觉"
age = 16
def bar():
nonlocal name
nonlocal age
return bar
# 查看的是闭包里面使用的外层作用域的变量
# 所以 foo().__closure__ 是一个包含两个元素的元组
print(foo().__closure__)
"""
(<cell at 0x000001FD1D3B02B0: int object at 0x00007FFDE559D660>,
<cell at 0x000001FD1D42E310: str object at 0x000001FD1D3DA090>)
"""
print(foo().__closure__[0].cell_contents) # 16
print(foo().__closure__[1].cell_contents) # 古明地觉Hinweis: Um die Verschlusseigenschaften anzuzeigen, verwenden wir die innere Funktion, nicht das äußere foo.
func_doc: Der Docstring der Funktion
def foo():
"""
hi,欢迎来到我的编程教室
遇见你真好
"""
pass
print(foo.__doc__)
"""
hi,欢迎来到我的编程教室
遇见你真好
"""func_name: Der Name der Funktion
def foo(name, age):
pass
print(foo.__name__) # fooNatürlich haben nicht nur Funktionen, sondern auch Methoden, Klassen und Module ihre eigenen Namen.
import numpy as np print(np.__name__) # numpy print(np.ndarray.__name__) # ndarray print(np.array([1, 2, 3]).transpose.__name__) # transpose
func_dict: Attributwörterbuch der Funktion
Da die Funktion auch von einer Klasse auf der untersten Ebene instanziiert wird, kann sie ein eigenes Attributwörterbuch haben, dieses Wörterbuch ist jedoch normalerweise leer.
def foo(name, age):
pass
print(foo.__dict__) # {}Natürlich können wir auch ein paar Tricks machen:
def foo(name, age):
return f"name: {name}, age: {age}"
code = """
name, age = "古明地觉", 17
def foo():
return "satori"
"""
exec(code, foo.__dict__)
print(foo.name) # 古明地觉
print(foo.age) # 17
print(foo.foo()) # satori
print(foo("古明地觉", 17)) # name: 古明地觉, age: 17Obwohl es also eine Funktion genannt wird, wird es auch von einem bestimmten Objekttyp implementiert.
func_weakreflist: Schwache Referenzliste
Python kann dieses Attribut nicht erhalten. Wir werden hier nicht ausführlich auf schwache Referenzen eingehen.
func_module: Das Modul, in dem sich die Funktion befindet
def foo(name, age):
pass
print(foo.__module__) # __main__
import pandas as pd
print(
pd.read_csv.__module__
) # pandas.io.parsers.readers
from pandas.io.parsers.readers import read_csv
print(read_csv is pd.read_csv) # TrueKlassen, Methoden und Coroutinen haben auch das Attribut __module__.
func_annotations: Anmerkungen eingeben
def foo(name: str, age: int):
pass
# Python3.5 新增的语法,但只能用于函数参数
# 而在 3.6 的时候,声明变量也可以使用这种方式
# 特别是当 IDE 无法得知返回值类型时,便可通过类型注解的方式告知 IDE
# 这样就又能使用 IDE 的智能提示了
print(foo.__annotations__)
# {'name': <class 'str'>, 'age': <class 'int'>}func_qualname: vollständig qualifizierter Name
def foo():
pass
print(foo.__name__, foo.__qualname__) # foo foo
class A:
def foo(self):
pass
print(A.foo.__name__, A.foo.__qualname__) # foo A.fooDer vollständig qualifizierte Name sollte vollständiger sein.
def foo(name, age):
pass
# <class 'function'> 就是 C 里面的 PyFunction_Type
print(foo.__class__) # <class 'function'>Aber die unterste Ebene dieser Klasse steht uns nicht zur Verfügung und wir können sie nicht direkt verwenden, da die Funktion über def erstellt werden kann und nicht über ein Typobjekt erstellt werden muss.
Wann wurde die Funktion erstellt?
Wir haben bereits erwähnt, dass die Funktion durch die PyFunctionObject-Struktur auf der untersten Ebene implementiert wird. Es gibt ein func_code-Mitglied, das auf ein PyCodeObject-Objekt verweist, und die Funktion wird darauf basierend erstellt.
Da PyCodeObject eine statische Darstellung eines Codeabschnitts ist, generiert der Python-Compiler nach dem Kompilieren des Quellcodes ein und nur ein PyCodeObject-Objekt für jeden darin enthaltenen Codeblock (Codeblock). Dieses Objekt enthält einige statische Informationen zu diesem Codeblock, also Informationen, die aus dem Quellcode ersichtlich sind.
Wenn beispielsweise im Codeblock, der einer Funktion entspricht, ein Ausdruck wie a = 1 vorhanden ist, sind das Symbol a, die Ganzzahl 1 und die Beziehung zwischen ihnen statische Informationen, und diese Informationen werden statisch gespeichert.
Symbol a wird in der Symboltabelle co_varnames gespeichert;
integer 1 wird im Konstantenpool co_consts gespeichert;
ist eine Zuweisungsanweisung zwischen den beiden, daher gibt es zwei Anweisungen: LOAD_CONST und STORE_FAST , sie existieren in der Bytecode-Anweisungssequenz co_code
Die oben genannten Informationen können während der Kompilierung abgerufen werden, sodass das PyCodeObject-Objekt das Ergebnis nach der Kompilierung ist.
Aber wann wurde das PyFunctionObject-Objekt generiert? Offensichtlich wird es vom Python-Code zur Laufzeit dynamisch generiert. Genauer gesagt wird es von der virtuellen Maschine erstellt, wenn sie eine Def-Anweisung ausführt.
Wenn die virtuelle Maschine beim Ausführen des Bytecodes im aktuellen Stapelrahmen die Def-Anweisung findet, bedeutet dies, dass ein neues PyCodeObject-Objekt entdeckt wurde, da diese Schicht für Schicht verschachtelt werden können. Daher erstellt die virtuelle Maschine das entsprechende PyFunctionObject-Objekt basierend auf diesem PyCodeObject-Objekt und platziert dann das Schlüssel-Wert-Paar aus Funktionsnamen und PyFunctionObject-Objekt (Funktionskörper) im aktuellen lokalen Raum.
Im PyFunctionObject-Objekt müssen wir auch relevante statische Informationen abrufen, sodass es ein func_code-Mitglied gibt, das auf PyCodeObject verweist.
除此之外,PyFunctionObject 对象中还包含了一些函数在执行时所必需的动态信息,即上下文信息。比如 func_globals,就是函数在执行时关联的 global 空间,说白了就是在局部变量找不到的时候能够找全局变量,可如果连 global 空间都没有的话,那即便想找也无从下手呀。
而 global 作用域中的符号和值必须在运行时才能确定,所以这部分必须在运行时动态创建,无法静态存储在 PyCodeObject 中,因此要根据 PyCodeObject 对象创建 PyFunctionObject 对象。总之一切的目的,都是为了更好地执行字节码。
我们举个例子:
# 虚拟机从上到下顺序执行字节码
name = "古明地觉"
age = 16
# 啪,很快啊,发现了一个 def 语句
def foo():
pass
# 出现 def,虚拟机就知道源代码进入一个新的作用域了
# 也就是遇到一个新的 PyCodeObject 对象了
# 而通过 def 可以得知这是创建函数的语句
# 所以会基于 PyCodeObject 创建 PyFunctionObject
# 因此当执行完 def 语句之后,一个函数就创建好了
# 创建完之后,会将函数名和函数体组成键值对,存放在当前的 local 空间中
print(locals()["foo"])
"""
<function foo at 0x7fdc280e6280>
"""调用的时候,会从 local 空间中取出符号 foo 对应的 PyFunctionObject 对象。然后根据这个 PyFunctionObject 对象创建 PyFrameObject 对象,也就是为函数创建一个栈帧,随后将执行权交给新创建的栈帧,并在新创建的栈帧中执行字节码。
函数是怎么创建的
通过上面的分析,我们知道了函数是虚拟机在遇到 def 语句的时候创建的,并保存在 local 空间中。当我们通过函数名()的方式调用时,会从 local 空间取出和函数名绑定的函数对象,然后执行。
那么问题来了,函数(对象)是怎么创建的呢?或者说虚拟机是如何完成 PyCodeObject 对象到 PyFunctionObject 对象之间的转变呢?显然想了解这其中的奥秘,就必须从字节码入手。
import dis
s = """
name = "satori"
def foo(a, b):
print(a, b)
return 123
foo(1, 2)
"""
dis.dis(compile(s, "<...>", "exec"))源代码很简单,定义一个变量 name 和函数 foo,然后调用函数。显然源代码在编译之后会产生两个 PyCodeObject,一个是模块的,一个是函数 foo 的,我们来看一下。
# 加载字符串常量 "satori",压入运行时栈
2 0 LOAD_CONST 0 ('satori')
# 将字符串从运行时栈弹出,并使用变量 name 绑定起来
# 也就是将 "name": "satori" 放到 local 名字空间中
2 STORE_NAME 0 (name)
# 注意这一步也是 LOAD_CONST,但它加载的是 PyCodeObject 对象
# 所以 PyCodeObject 对象本质上也是一个常量
3 4 LOAD_CONST 1 (<code object foo at 0x7fb...>)
# 加载符号 "foo"
6 LOAD_CONST 2 ('foo')
# 将符号 "foo" 和 PyCodeObject 对象从运行时栈弹出
# 然后创建 PyFunctionObject 对象,并压入运行时栈
8 MAKE_FUNCTION 0
# 将上一步创建的函数对象从运行时栈弹出,并用变量 foo 与之绑定起来
# 后续通过 foo() 即可发起函数调用
10 STORE_NAME 1 (foo)
# 函数创建完了,我们调用函数
# 通过 LOAD_NAME 将 foo 对应的函数对象(指针)压入运行时栈
6 12 LOAD_NAME 1 (foo)
# 将整数常量(参数)压入运行时栈
14 LOAD_CONST 3 (1)
16 LOAD_CONST 4 (2)
# 将栈里面的参数和函数弹出,发起调用,并将调用的结果(返回值)压入运行时栈
18 CALL_FUNCTION 2
# 从栈顶弹出返回值,然后丢弃,因为我们没有用变量接收返回值
# 如果我们用变量接收了,那么这里的指令就会从 POP_TOP 变成 STORE_NAME
20 POP_TOP
# return None
22 LOAD_CONST 5 (None)
24 RETURN_VALUE
# 以上是模块对应的字节码指令,下面是函数 foo 的字节码指令
Disassembly of <code object foo at 0x7fb......>:
# 从局部作用域中加载内置变量 print
4 0 LOAD_GLOBAL 0 (print)
# 从局部作用域中加载局部变量 a
2 LOAD_FAST 0 (a)
# 从局部作用域中加载局部变量 b
4 LOAD_FAST 1 (b)
# 从运行时栈中将参数和函数依次弹出,发起调用,也就是 print(a, b)
6 CALL_FUNCTION 2
# 从栈顶弹出返回值,然后丢弃,因为我们没有接收 print 的返回值
8 POP_TOP
# return 123
10 LOAD_CONST 1 (123)
12 RETURN_VALUE上面有一个有趣的现象,就是源代码的行号。之前看到源代码的行号都是从上往下、依次增大的,这很好理解,毕竟一条一条解释嘛。但是这里却发生了变化,先执行了第 6 行,之后再执行第 4 行。
如果是从 Python 层面的函数调用来理解的话,很容易一句话就解释了,因为函数只有在调用的时候才会执行,而调用肯定发生在创建之后。但是从字节码的角度来理解的话,我们发现函数的声明和实现是分离的,是在不同的 PyCodeObject 对象中。
确实如此,虽然函数名和函数体是一个整体,但是虚拟机在实现的时候,却在物理上将它们分离开了。
正所谓函数即变量,我们可以把函数当成普通的变量来处理。函数名就是变量名,它位于模块对应的 PyCodeObject 的符号表中;函数体就是变量指向的值,它是基于一个独立的 PyCodeObject 构建的。
换句话说,在编译时,函数体里面的代码会位于一个新的 PyCodeObject 对象当中,所以函数的声明和实现是分离的。
至此,函数的结构就已经非常清晰了。
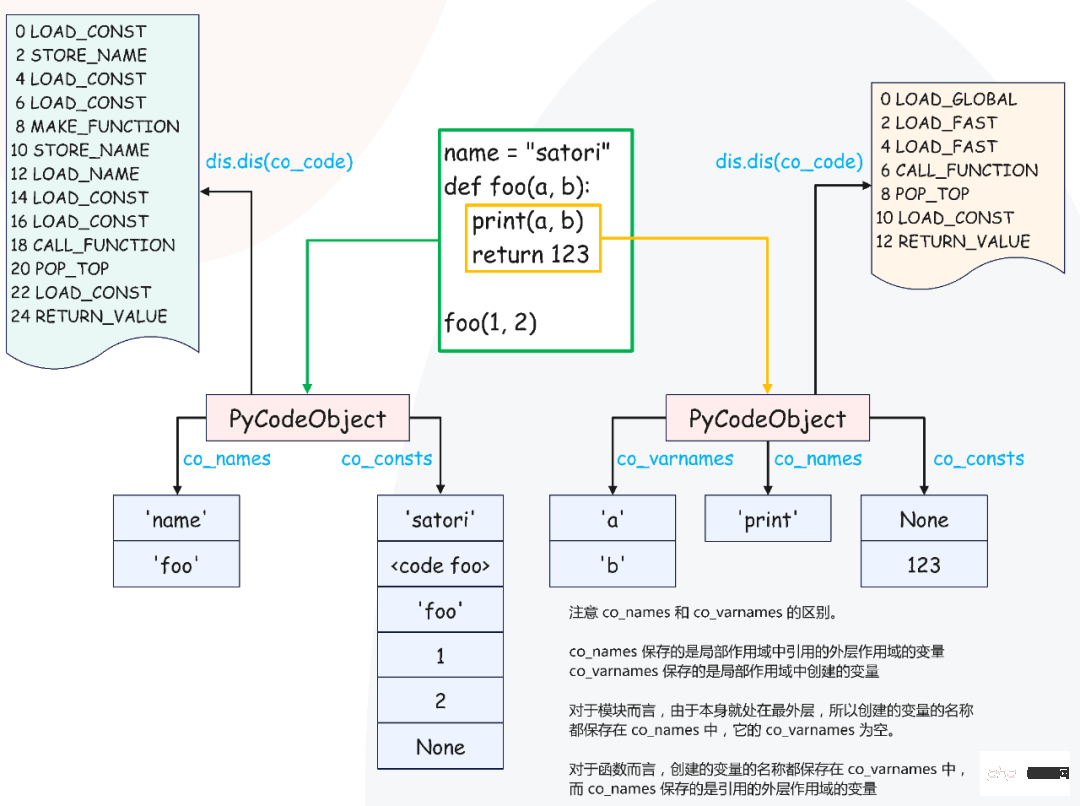
所以函数名和函数体是分离的,它们存储在不同的 PyCodeObject 对象当中。
分析完结构之后,重点就要落在 MAKE_FUNCTION 指令上了,我们说当遇到 def foo(a, b) 的时候,就知道要创建函数了。在语法上这是函数的声明语句,但从虚拟机的角度来看这其实是函数对象的创建语句。
所以下面我们就要分析一下这个指令,看看它到底是怎么将一个 PyCodeObject 对象变成一个 PyFunctionObject 对象的。
case TARGET(MAKE_FUNCTION): {
// 弹出压入运行时栈的函数名
PyObject *qualname = POP();
// 弹出对应的 PyCodeObject 对象
PyObject *codeobj = POP();
// 创建 PyFunctionObject 对象,需要三个参数
// 分别是 PyCodeObject 对象、global 名字空间、函数的全限定名
// 我们看到创建函数的时候将 global 名字空间传递了进去
// 所以现在我们应该明白为什么函数可以调用 __globals__ 了
// 当然也明白为什么函数在局部变量找不到的时候可以去找全局变量了
PyFunctionObject *func = (PyFunctionObject *)
PyFunction_NewWithQualName(codeobj, f->f_globals, qualname);
// 减少引用计数
// 如果函数创建失败会返回 NULL,跳转至 error
Py_DECREF(codeobj);
Py_DECREF(qualname);
if (func == NULL) {
goto error;
}
// 编译时能够静态检测出函数有没有设置闭包、类型注解等属性
// 比如设置了闭包,那么 oparg & 0x08 为真
// 设置了类型注解,那么 oparg & 0x04 为真
// 如果条件为真,那么进行相关属性设置
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
func ->func_closure = POP();
}
if (oparg & 0x04) {
assert(PyDict_CheckExact(TOP()));
func->func_annotations = POP();
}
if (oparg & 0x02) {
assert(PyDict_CheckExact(TOP()));
func->func_kwdefaults = POP();
}
if (oparg & 0x01) {
assert(PyTuple_CheckExact(TOP()));
func->func_defaults = POP();
}
// 将创建好的函数对象的指针压入运行时栈
// 下一个指令 STORE_NAME 会将它从运行时栈弹出
// 并用变量 foo 和它绑定起来,放入 local 空间中
PUSH((PyObject *)func);
DISPATCH();
}整个步骤很好理解,先通过 LOAD_CONST 将 PyCodeObject 对象和符号 foo 压入栈中。然后执行 MAKE_FUNCTION 的时候,将两者从栈中弹出,再加上当前栈帧对象中维护的 global 名字空间,三者作为参数传入 PyFunction_NewWithQualName 函数中,从而构建出相应的函数对象。
上面的函数比较简单,如果再加上类型注解、以及默认值,会有什么效果呢?
s = """
name = "satori"
def foo(a: int = 1, b: int = 2):
print(a, b)
foo(1, 2)
"""
import dis
dis.dis(compile(s, "func", "exec"))这里我们加上了类型注解和默认值,看看它的字节码指令会有什么变化?
0 LOAD_CONST 0 ('satori')
2 STORE_NAME 0 (name)
4 LOAD_CONST 7 ((1, 2))
6 LOAD_NAME 1 (int)
8 LOAD_NAME 1 (int)
10 LOAD_CONST 3 (('a', 'b'))
12 BUILD_CONST_KEY_MAP 2
14 LOAD_CONST 4 ()
16 LOAD_CONST 5 ('foo')
18 MAKE_FUNCTION 5 (defaults, annotations)
......
......
不难发现,在构建函数时会先将默认值以元组的形式压入运行时栈;然后再根据使用了类型注解的参数和类型构建一个字典,并将这个字典压入运行时栈。
后续创建函数的时候,会将默认值保存在 func_defaults 成员中,类型注解对应的字典会保存在 func_annotations 成员中。
def foo(a: int = 1, b: int = 2):
print(a, b)
print(foo.__defaults__)
print(foo.__annotations__)
# (1, 2)
# {'a': <class 'int'>, 'b': <class 'int'>}基于类型注解和描述符,我们便可以像静态语言一样,实现函数参数的类型约束。介绍完描述符之后,我们会举例说明。
函数的一些骚操作
我们通过一些骚操作,来更好地理解一下函数。
之前说
def f():
pass
print(type(f)) # <class 'function'>
# lambda匿名函数的类型也是 function
print(type(lambda: None)) # <class 'function'>那么下面就来创建函数:
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
# 得到PyCodeObject对象
code = f.__code__
# 根据类function创建函数对象
# 接收三个参数: PyCodeObject对象、名字空间、函数名
new_f = type(f)(code, globals(), "根据 f 创建的 new_f")
# 打印函数名
print(new_f.__name__) # 根据 f 创建的 new_f
# 调用函数
print(
new_f("古明地觉", 16)
) # name: 古明地觉, age: 16, gender: female是不是很神奇呢?另外我们说函数在访问变量时,显然先从自身的符号表中查找,如果没有再去找全局变量。这是因为,我们在创建函数的时候将 global 名字空间传进去了,如果我们不传递呢?
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
code = f.__code__
try:
new_f = type(f)(code, None, "根据 f 创建的 new_f")
except TypeError as e:
print(e)
"""
function() argument 'globals' must be dict, not None
"""
# 这里告诉我们 function 的第二个参数 globals 必须是一个字典
# 我们传递一个空字典
new_f1 = type(f)(code, {}, "根据 f 创建的 new_f1")
# 打印函数名
print(new_f1.__name__) # 根据 f 创建的 new_f1
# 调用函数
try:
print(new_f1("古明地觉", 16))
except NameError as e:
print(e)
"""
name 'gender' is not defined
"""
# 我们看到提示 gender 没有定义因此现在我们又从 Python 的角度理解了一遍,为什么函数能够在局部变量找不到的时候,去找全局变量。原因就在于构建函数的时候,将 global 名字空间交给了函数,使得函数可以在 global 空间进行变量查找,所以它才能够找到全局变量。而我们这里给了一个空字典,那么显然就找不到 gender 这个变量了。
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
code = f.__code__
new_f = type(f)(code, {"gender": "少女觉"}, "根据 f 创建的 new_f")
# 我们可以手动传递一个字典进去
# 此时我们传递的字典对于函数来说就是 global 名字空间
# 所以在函数内部找不到某个变量的时候, 就会去我们指定的名字空间中查找
print(new_f("古明地觉", 16))
"""
name: 古明地觉, age: 16, gender: 少女觉
"""
# 所以此时的 gender 不再是外部的 "female"
# 而是我们指定的 "少女觉"此外我们还可以为函数指定默认值:
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
# 必须接收一个PyTupleObject对象
f.__defaults__ = ("古明地觉", 16, "female")
print(f())
"""
name: 古明地觉, age: 16, gender: female
"""我们看到函数 f 明明接收三个参数,但是调用时不传递居然也不会报错,原因就在于我们指定了默认值。而默认值可以在定义函数的时候指定,也可以通过 __defaults__ 指定,但很明显我们应该通过前者来指定。
如果你用的是 pycharm,那么会在 f() 这个位置给你飘黄,提示你参数没有传递。但我们知道,由于使用 __defaults__ 已经设置了默认值,所以这里是不会报错的。只不过 pycharm 没有检测到,当然基本上所有的 IDE 都无法做到这一点,毕竟动态语言。
另外 __defaults__ 接收的元组里面的元素个数和参数个数不匹配怎么办?
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
f.__defaults__ = (15, "female")
print(f("古明地恋"))
"""
name: 古明地恋, age: 15, gender: female
"""由于元组里面只有两个元素,意味着我们在调用时需要至少传递一个参数,而这个参数会赋值给 name。原因就是在设置默认值的时候是从后往前设置的,也就是 "female" 会给赋值给 gender,15 会赋值给 age。而 name 没有得到默认值,那么它就需要调用者显式传递了。
为啥 Python 在设置默认值是从后往前设置呢?如果从前往后设置的话,会出现什么后果呢?显然此时 15 会赋值给 name,"female" 会赋值给 age,那么函数就等价于如下:
def f(name=15, age="female", gender):
return f"name: {name}, age: {age}, gender: {gender}"这样的函数能够通过编译吗?显然是不行的,因为默认参数必须在非默认参数的后面。所以 Python 的这个做法是完全正确的,必须要从后往前进行设置。
另外我们知道默认值的个数是小于等于参数个数的,如果大于会怎么样呢?
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
f.__defaults__ = ("古明地觉", "古明地恋", 15, "female")
print(f())
"""
name: 古明地恋, age: 15, gender: female
"""依旧从后往前进行设置,当所有参数都有默认值了,那么就结束了。当然,如果不使用 __defaults__,是不可能出现默认值个数大于参数个数的。
可要是 __defaults__ 指向的元组先结束,那么没有得到默认值的参数就必须由我们来传递了。
最后再来说一下如何深拷贝一个函数。首先如果是你的话,你会怎么拷贝一个函数呢?不出意外的话,你应该会使用 copy 模块。
import copy
def f(a, b):
return [a, b]
# 但是问题来了,这样能否实现深度拷贝呢?
new_f = copy.deepcopy(f)
f.__defaults__ = (2, 3)
print(new_f()) # [2, 3]修改 f 的 __defaults__,会对 new_f 产生影响,因此我们并没有实现函数的深度拷贝。事实上,copy 模块无法对函数、方法、回溯栈、栈帧、模块、文件、套接字等类型的实例实现深度拷贝。
那我们应该怎么做呢?
from types import FunctionType
def f(a, b):
return "result"
# FunctionType 就是函数的类型对象
# 它也是通过 type 得到的
new_f = FunctionType(f.__code__,
f.__globals__,
f.__name__,
f.__defaults__,
f.__closure__)
# 显然 function 还可以接收第四个参数和第五个参数
# 分别是函数的默认值和闭包
# 然后别忘记将属性字典也拷贝一份
# 由于函数的属性字典几乎用不上,这里就浅拷贝了
new_f.__dict__.update(f.__dict__)
f.__defaults__ = (2, 3)
print(f.__defaults__) # (2, 3)
print(new_f.__defaults__) # None此时修改 f 不会影响 new_f,当然在拷贝的时候也可以自定义属性。
其实上面实现的深拷贝,本质上就是定义了一个新的函数。由于是两个不同的函数,那么自然就没有联系了。
判断函数都有哪些参数
再来看看如何检测一个函数有哪些参数,首先函数的局部变量(包括参数)在编译时就已经确定,会存在符号表 co_varnames 中。
def f(a, b, /, c, d, *args, e, f, **kwargs):
g = 1
h = 2
varnames = f.__code__.co_varnames
print(varnames)
"""
('a', 'b', 'c', 'd', 'e', 'f', 'args', 'kwargs', 'g', 'h')
"""注意:在定义函数的时候,* 和 ** 最多只能出现一次。
显然 a 和 b 必须通过位置参数传递,c 和 d 可以通过位置参数和关键字参数传递,e 和 f 必须通过关键字参数传递。
而从打印的符号表来看,里面的符号是有顺序的。参数永远处于函数内部定义的局部变量的前面,比如 g 和 h 就是函数内部定义的局部变量,所以它在所有参数的后面。
而对于参数,* 和 ** 会位于最后面,其它参数位置不变。所以除了 g 和 h,最后面的就是 args 和 kwargs。
那么接下来我们就可以进行检测了。
def f(a, b, /, c, d, *args, e, f, **kwargs):
g = 1
h = 2
varnames = f.__code__.co_varnames
# 1. 寻找必须通过位置参数传递的参数
posonlyargcount = f.__code__.co_posonlyargcount
print(posonlyargcount) # 2
print(varnames[: posonlyargcount]) # ('a', 'b')
# 2. 寻找既可以通过位置参数传递、又可以通过关键字参数传递的参数
argcount = f.__code__.co_argcount
print(argcount) # 4
print(varnames[: 4]) # ('a', 'b', 'c', 'd')
print(varnames[posonlyargcount: 4]) # ('c', 'd')
# 3. 寻找必须通过关键字参数传递的参数
kwonlyargcount = f.__code__.co_kwonlyargcount
print(kwonlyargcount) # 2
print(varnames[argcount: argcount + kwonlyargcount]) # ('e', 'f')
# 4. 寻找 *args 和 **kwargs
flags = f.__code__.co_flags
# 在介绍 PyCodeObject 的时候,我们说里面有一个 co_flags 成员
# 它是函数的标识,可以对函数类型和参数进行检测
# 如果co_flags和 4 进行按位与之后为真,那么就代表有* args, 否则没有
# 如果co_flags和 8 进行按位与之后为真,那么就代表有 **kwargs, 否则没有
step = argcount + kwonlyargcount
if flags & 0x04:
print(varnames[step]) # args
step += 1
if flags & 0x08:
print(varnames[step]) # kwargs以上我们检测出了函数都有哪些参数,你也可以将其封装成一个函数,实现代码的复用。
然后需要注意一下 args 和 kwargs,打印的内容主要取决定义时使用的名字。如果定义的时候是 *ARGS 和 **KWARGS,那么这里就会打印 ARGS 和 KWARGS,只不过一般我们都叫做 *args 和 **kwargs。
但如果我们定义的时候不是 *args,只是一个 *,那么它就不是参数了。
def f(a, b, *, c):
pass
# 我们看到此时只有a、b、c
print(f.__code__.co_varnames) # ('a', 'b', 'c')
print(f.__code__.co_flags & 0x04) # 0
print(f.__code__.co_flags & 0x08) # 0
# 显然此时也都为假单独的一个 * 只是为了强制要求后面的参数必须通过关键字参数的方式传递。
函数是怎么调用的
到目前为止,我们聊了聊 Python 函数的底层实现,并且还演示了如何通过函数的类型对象自定义一个函数,以及如何获取函数的参数。虽然这在工作中没有太大意义,但是可以让我们深刻理解函数的行为。
下面我来探讨一下函数在底层是怎么调用的,但是在介绍调用之前,我们需要补充一个知识点。
def foo():
pass
print(type(foo))
print(type(sum))
"""
<class 'function'>
<class 'builtin_function_or_method'>
"""函数实际上分为两种:
如果是 Python 实现的函数,底层会对应 PyFunctionObject。其类型在 Python 里面是
,在底层是 PyFunction_Type; 如果是 C 实现的函数,底层会对应 PyCFunctionObject。其类型在 Python 里面是
,在底层是 PyCFunction_Type;
像内置函数、使用 C 扩展编写的函数,它们都是 PyCFunctionObject。
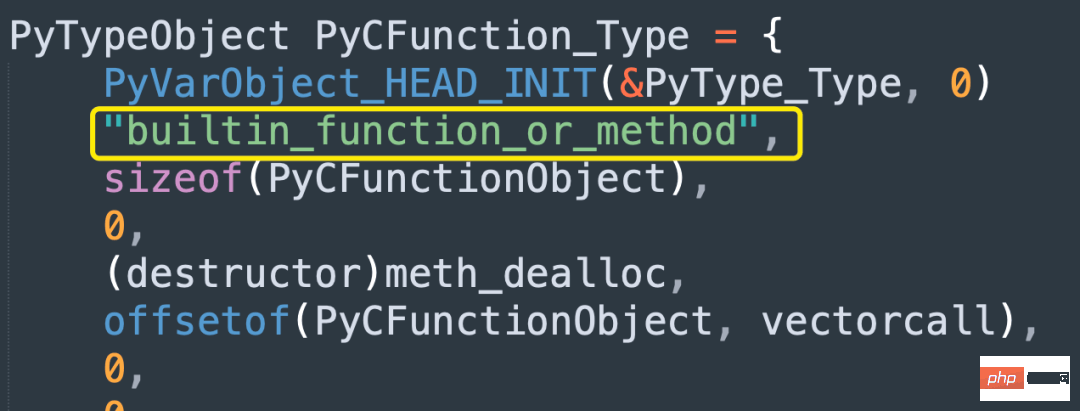
另外从名字上可以看出 PyCFunctionObject 不仅用于 C 实现的函数,还用于方法。关于方法,我们后续在介绍类的时候细说,这里暂时不做深入讨论。
总之对于 Python 函数和 C 函数,底层在实现的时候将两者分开了,因为 C 函数可以有更快的执行方式。
注意这里说的 C 函数,指的是 C 实现的 Python 函数。像内置函数就是 C 实现的,比如 sum、getattr 等等。
好了,下面来看函数调用的具体细节。
s = """
def foo():
a, b = 1, 2
return a + b
foo()
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "<...>", "exec"))还是以一个简单的函数为例,看看它的字节码:
# 遇见 def 表示构建函数 # 于是加载 PyCodeObject 对象和函数名 "foo" 0 LOAD_CONST 0 (<code object foo at 0x7f...>) 2 LOAD_CONST 1 ('foo') # 构建函数对象,压入运行时栈 4 MAKE_FUNCTION 0 # 从栈中弹出函数对象,用变量 foo 保存 6 STORE_NAME 0 (foo) # 将变量 foo 压入运行时栈 8 LOAD_NAME 0 (foo) # 从栈中弹出 foo,执行 foo(),也就是函数调用,这一会要剖析的重点 10 CALL_FUNCTION 0 # 从栈顶弹出返回值 12 POP_TOP # return None 14 LOAD_CONST 2 (None) 16 RETURN_VALUE Disassembly of <code object foo at 0x7...>: # 函数的字节码,因为模块和函数都会对应 PyCodeObject # 只不过后者在前者的常量池中 # 加载元组常量 (1, 2) 0 LOAD_CONST 1 ((1, 2)) # 解包,将常量压入运行时栈 2 UNPACK_SEQUENCE 2 # 再从栈中弹出,分别赋值给 a 和 b 4 STORE_FAST 0 (a) 6 STORE_FAST 1 (b) # 加载 a 和 b 8 LOAD_FAST 0 (a) 10 LOAD_FAST 1 (b) # 执行加法运算 12 BINARY_ADD # 将相加之和的值返回 14 RETURN_VALUE
相信现在看字节码已经不是什么问题了,然后我们看到调用函数用的是 CALL_FUNCTION 指令,那么这个指令都做了哪些事情呢?
case TARGET(CALL_FUNCTION): {
PREDICTED(CALL_FUNCTION);
PyObject **sp, *res;
// 指向运行时栈的栈顶
sp = stack_pointer;
// 调用函数,将返回值赋值给 res
// tstate 表示线程状态对象
// &sp 是一个三级指针,oparg 表示指令的操作数
res = call_function(tstate, &sp, oparg, NULL);
// 函数执行完毕之后,sp 会指向运行时栈的栈顶
// 所以再将修改之后的 sp 赋值给 stack_pointer
stack_pointer = sp;
// 将 res 压入栈中:*stack_pointer++ = res
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}CALL_FUNCTION 这个指令之前提到过,但是函数的核心执行流程是在 call_function 里面,它位于 ceval.c 中,我们来看一下。


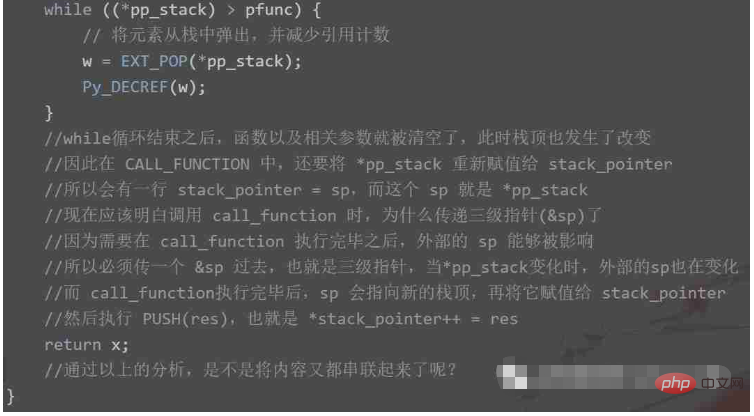
因此接下来重点就在 _PyObject_Vectorcall 函数上面,在该函数内部又会调用其它函数,最终会走到 _PyFunction_FastCallDict 这里。
//Objects/call.c
PyObject *
_PyFunction_FastCallDict(PyObject *func, PyObject *const *args, Py_ssize_t nargs,
PyObject *kwargs)
{
//获取PyCodeObject对象
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
//获取global名字空间
PyObject *globals = PyFunction_GET_GLOBALS(func);
//获取默认值
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
//....
//我们观察一下下面的return
//一个是function_code_fastcall,一个是最后的_PyEval_EvalCodeWithName
//从名字上能看出来function_code_fastcall是一个快分支
//但是这个快分支要求函数调用时不能传递关键字参数
if (co->co_kwonlyargcount == 0 &&
(kwargs == NULL || PyDict_GET_SIZE(kwargs) == 0) &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
/* Fast paths */
if (argdefs == NULL && co->co_argcount == nargs) {
//function_code_fastcall里面逻辑很简单
//直接抽走当前PyFunctionObject里面PyCodeObject和global名字空间
//根据PyCodeObject对象直接为其创建一个PyFrameObject对象
//然后PyEval_EvalFrameEx执行栈帧
//也就是真正的进入了函数调用,执行函数里面的代码
return function_code_fastcall(co, args, nargs, globals);
}
else if (nargs == 0 && argdefs != NULL
&& co->co_argcount == PyTuple_GET_SIZE(argdefs)) {
/* function called with no arguments, but all parameters have
a default value: use default values as arguments .*/
args = _PyTuple_ITEMS(argdefs);
return function_code_fastcall(co, args, PyTuple_GET_SIZE(argdefs),
globals);
}
}
//适用于有关键字参数的情况
nk = (kwargs != NULL) ? PyDict_GET_SIZE(kwargs) : 0;
//.....
//调用_PyEval_EvalCodeWithName
result = _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
args, nargs,
k, k != NULL ? k + 1 : NULL, nk, 2,
d, nd, kwdefs,
closure, name, qualname);
Py_XDECREF(kwtuple);
return result;
}所以函数调用时会有两种方式:
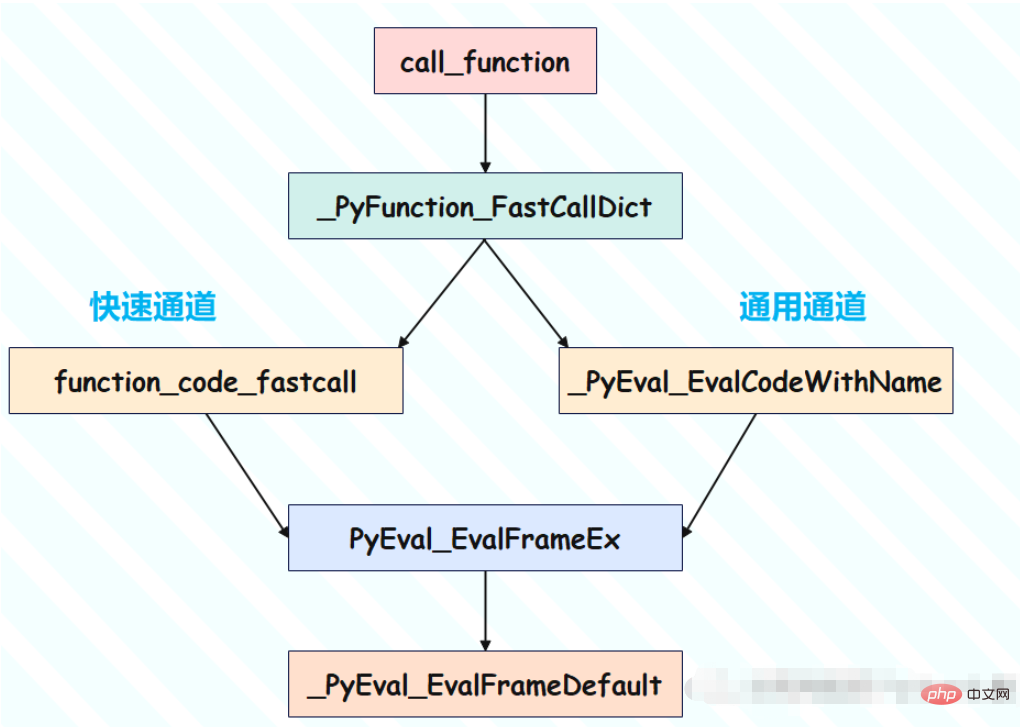
因此我们看到,总共有两条途径,分别针对有无关键字参数。但是最终殊途同归,都会走到 PyEval_EvalFrameEx 那里,然后虚拟机在新的栈帧中执行新的 PyCodeObject。
不过可能有人会好奇,我们之前说过:
PyFrameObject 是根据 PyCodeObject 创建的
PyFunctionObject 也是根据 PyCodeObject 创建的
那么 PyFrameObject 和 PyFunctionObject 之间有啥关系呢?
如果把 PyCodeObject 比喻成妹子,那么 PyFunctionObject 就是妹子的备胎,PyFrameObject 就是妹子的心上人。
其实在栈帧中执行指令时候,PyFunctionObject 的影响就已经消失了,真正对栈帧产生影响的是PyFunctionObject 里面的 PyCodeObject 对象和 global 名字空间。
也就是说,最终是 PyFrameObject 和 PyCodeObject 两者如胶似漆,跟 PyFunctionObject 之间没有关系,所以 PyFunctionObject 辛苦一场,实际上是为别人做了嫁衣。PyFunctionObject 主要是对 PyCodeObject 和 global 名字空间的一种打包和运输方式。
Das obige ist der detaillierte Inhalt vonWas ist das Implementierungsprinzip der Python-Funktion?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Der Schlüssel zur Federkontrolle liegt darin, seine allmähliche Natur zu verstehen. PS selbst bietet nicht die Möglichkeit, die Gradientenkurve direkt zu steuern, aber Sie können den Radius und die Gradientenweichheit flexius durch mehrere Federn, Matching -Masken und feine Selektionen anpassen, um einen natürlichen Übergangseffekt zu erzielen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie richte ich PS -Federn ein?
Apr 06, 2025 pm 07:36 PM
Wie richte ich PS -Federn ein?
Apr 06, 2025 pm 07:36 PM
PS Federn ist ein Bildkantenschwärcheneffekt, der durch den gewichteten Durchschnitt der Pixel im Randbereich erreicht wird. Das Einstellen des Federradius kann den Grad der Unschärfe steuern und je größer der Wert ist, desto unscharfer ist er. Eine flexible Einstellung des Radius kann den Effekt entsprechend den Bildern und Bedürfnissen optimieren. Verwenden Sie beispielsweise einen kleineren Radius, um Details bei der Verarbeitung von Charakterfotos zu erhalten und einen größeren Radius zu verwenden, um ein dunstiges Gefühl bei der Verarbeitung von Kunst zu erzeugen. Es ist jedoch zu beachten, dass zu groß der Radius leicht an Kantendetails verlieren kann, und zu klein ist der Effekt nicht offensichtlich. Der Federneffekt wird von der Bildauflösung beeinflusst und muss anhand des Bildverständnisses und des Griffs von Effekten angepasst werden.
 Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt. Was soll ich tun? Wenn Sie MySQL herunterladen, können Sie die Korruption der Datei begegnen. Es ist heutzutage wirklich nicht einfach! In diesem Artikel wird darüber gesprochen, wie dieses Problem gelöst werden kann, damit jeder Umwege vermeiden kann. Nach dem Lesen können Sie nicht nur das beschädigte MySQL -Installationspaket reparieren, sondern auch ein tieferes Verständnis des Download- und Installationsprozesses haben, um zu vermeiden, dass Sie in Zukunft stecken bleiben. Lassen Sie uns zunächst darüber sprechen, warum das Herunterladen von Dateien beschädigt wird. Dafür gibt es viele Gründe. Netzwerkprobleme sind der Schuldige. Unterbrechung des Download -Prozesses und der Instabilität im Netzwerk kann zu einer Korruption von Dateien führen. Es gibt auch das Problem mit der Download -Quelle selbst. Die Serverdatei selbst ist gebrochen und natürlich auch unterbrochen, wenn Sie sie herunterladen. Darüber hinaus kann das übermäßige "leidenschaftliche" Scannen einer Antiviren -Software auch zu einer Beschädigung von Dateien führen. Diagnoseproblem: Stellen Sie fest, ob die Datei wirklich beschädigt ist
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
