
 Technologie-Peripheriegeräte
KI
„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'
Technologie-Peripheriegeräte
KI
„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'
„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'

Das Folgende ist der Inhalt der Rede von Professor Lu Zhiwu auf der ChatGPT- und Large Model Technology-Konferenz, die von Heart of the Machine abgehalten wurde, ohne die ursprüngliche Bedeutung zu ändern:

Hallo zusammen, ich bin Lu Zhiwu, Renmin University of China. Der Titel meines heutigen Berichts lautet „Wichtige Aufklärungen von ChatGPT zu multimodalen generativen Modellen“ und besteht aus vier Teilen.

Zunächst bringt uns ChatGPT einige Inspirationen zur Innovation von Forschungsparadigmen. Der erste Punkt besteht darin, „Big Model + Big Data“ zu verwenden, ein Forschungsparadigma, das wiederholt verifiziert wurde und auch das grundlegende Forschungsparadigma von ChatGPT darstellt. Es ist besonders wichtig zu betonen, dass ein großes Modell erst dann über neue Fähigkeiten verfügt, wie z. B. kontextbezogenes Lernen, CoT-Argumentation und andere Fähigkeiten. Diese Fähigkeiten sind sehr erstaunlich.
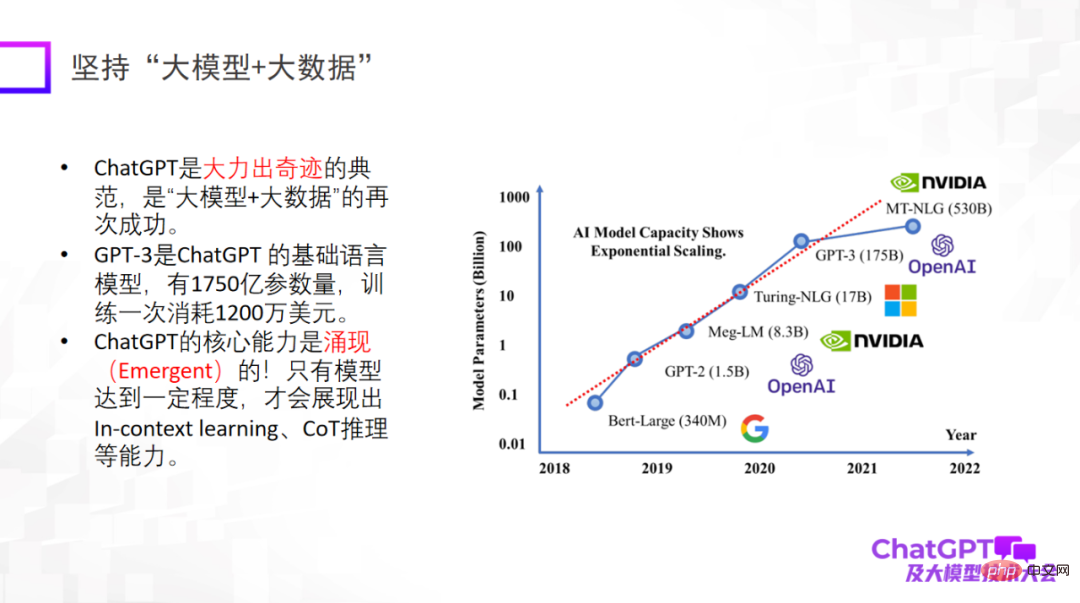
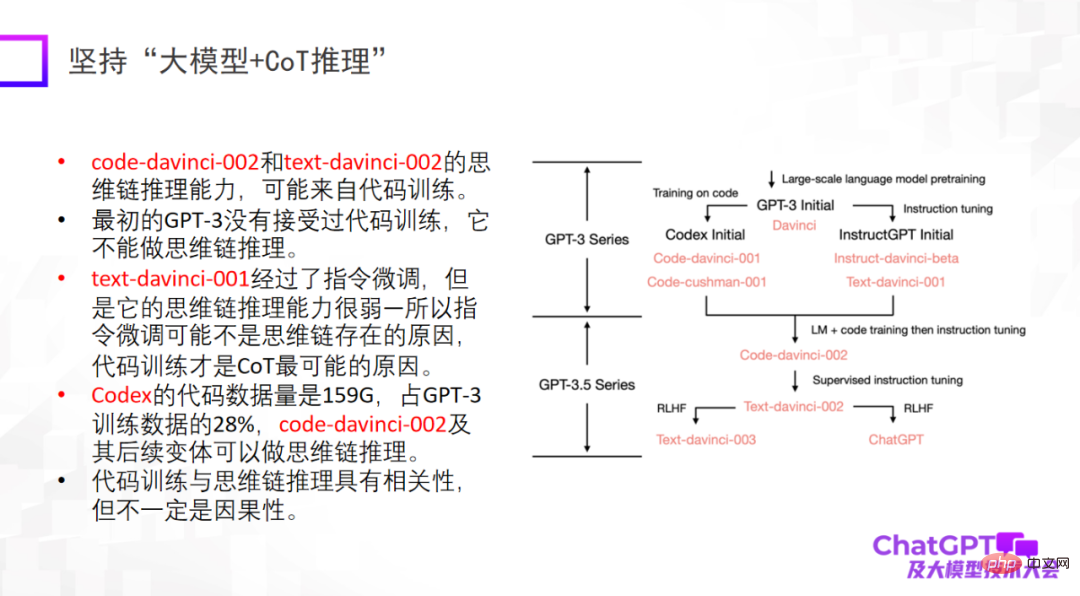
Der zweite Punkt ist, auf „großes Modell + Inferenz“ zu bestehen. Dies ist auch der Punkt, der mich an ChatGPT am meisten beeindruckt hat. Denn im Bereich des maschinellen Lernens oder der künstlichen Intelligenz gilt das Denken als das schwierigste, und auch ChatGPT hat in dieser Hinsicht Durchbrüche erzielt. Natürlich kann die Argumentationsfähigkeit von ChatGPT hauptsächlich aus dem Code-Training stammen, aber ob ein unvermeidlicher Zusammenhang besteht, ist noch nicht sicher. Im Hinblick auf das logische Denken sollten wir uns mehr Mühe geben, herauszufinden, woher es kommt und ob es andere Trainingsmethoden gibt, um das logische Denken weiter zu verbessern.
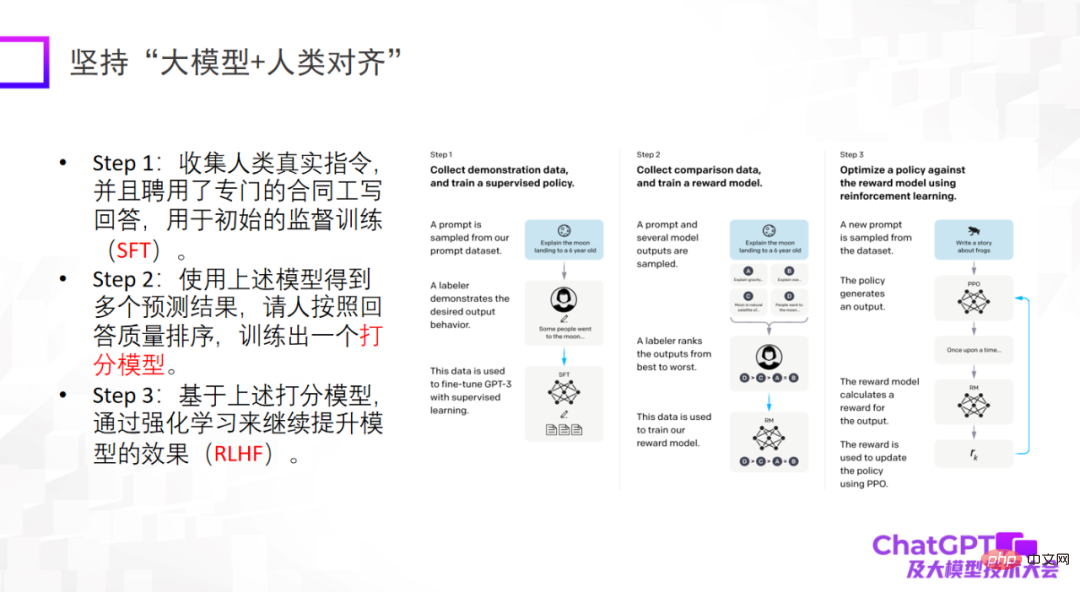
Der dritte Punkt ist, dass große Modelle auf Menschen ausgerichtet sein müssen. Dies ist eine wichtige Offenbarung, die uns ChatGPT aus technischer Sicht oder aus Sicht der Modelllandung gibt. Wenn das Modell nicht auf den Menschen abgestimmt ist, generiert es viele schädliche Informationen, wodurch das Modell unbrauchbar wird. Der dritte Punkt besteht nicht darin, die Obergrenze des Modells anzuheben, aber die Zuverlässigkeit und Sicherheit des Modells sind in der Tat sehr wichtig.
Die Einführung von ChatGPT hatte große Auswirkungen auf viele Bereiche, mich eingeschlossen. Da ich mich seit mehreren Jahren mit Multimodalität beschäftige, werde ich darüber nachdenken, warum wir kein so leistungsstarkes Modell entwickelt haben.
ChatGPT ist eine allgemeine Generierung in Sprache oder Text. Werfen wir einen Blick auf die neuesten Fortschritte im Bereich der multimodalen allgemeinen Generierung. Multimodale Pre-Training-Modelle haben begonnen, sich in multimodale allgemeine generative Modelle umzuwandeln, und es wurden einige vorläufige Untersuchungen durchgeführt. Schauen wir uns zunächst das von Google im Jahr 2019 vorgeschlagene Flamingo-Modell an. Die folgende Abbildung zeigt die Modellstruktur.
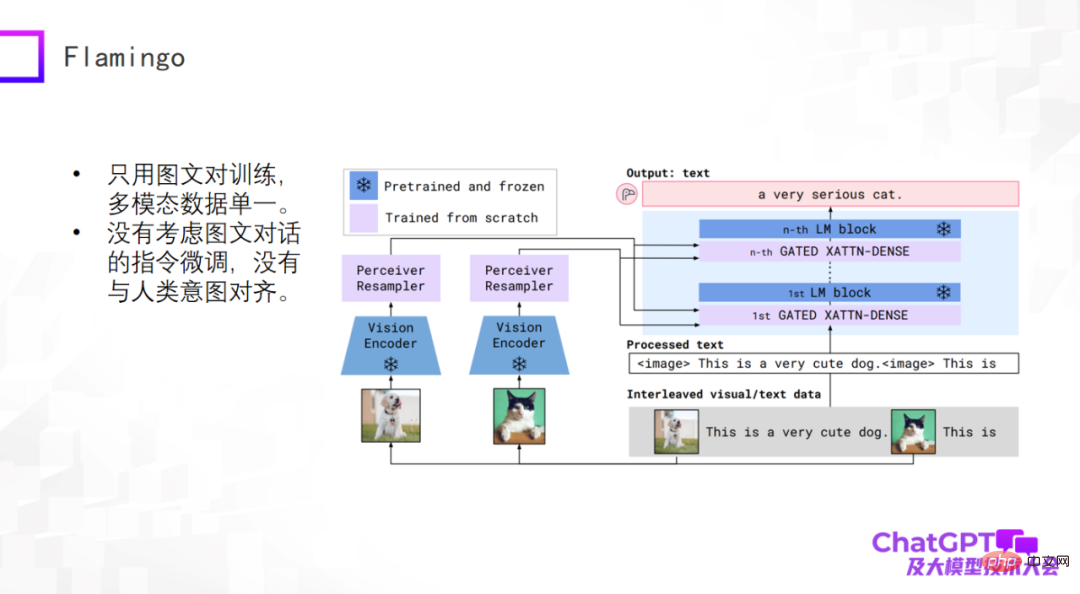
Der Hauptteil der Flamingo-Modellarchitektur ist der Decoder (Decoder) des großen Sprachmodells, bei dem es sich um das blaue Modul auf der rechten Seite des Bildes oben handelt. Zwischen jedem blauen Modul werden einige Adapterschichten hinzugefügt . Der visuelle Teil davon ist die Hinzufügung eines Vision Encoders und eines Perceiver Resamplers. Der Entwurf des gesamten Modells besteht darin, visuelle Dinge zu kodieren und zu konvertieren, den Adapter zu durchlaufen und sie an der Sprache auszurichten, sodass das Modell automatisch Textbeschreibungen für Bilder generieren kann.
Was sind die Vorteile eines architektonischen Entwurfs wie Flamingo? Erstens ist das blaue Modul im obigen Bild fest (eingefroren), einschließlich des Sprachmodell-Decoders, während die Parametermenge des rosa Moduls selbst steuerbar ist, sodass die Anzahl der tatsächlich vom Flamingo-Modell trainierten Parameter sehr gering ist. Denken Sie also nicht, dass multimodale universelle generative Modelle schwierig zu erstellen sind. Tatsächlich ist das nicht so pessimistisch. Das trainierte Flamingo-Modell kann viele allgemeine Aufgaben basierend auf der Textgenerierung erledigen. Natürlich ist die Eingabe multimodal, wie z. B. Videobeschreibung, visuelle Frage und Antwort, multimodaler Dialog usw. Aus dieser Perspektive kann Flamingo als allgemeines generatives Modell betrachtet werden.
Das zweite Beispiel ist das vor einiger Zeit neu veröffentlichte BLIP-2-Modell. Es basiert auf einer verbesserten Modellarchitektur und ist der von Flamingo sehr ähnlich Modell, diese beiden Teile werden fixiert, und dann wird in der Mitte ein Q-Former mit einer Konverterfunktion hinzugefügt – von der visuellen zur Sprachkonvertierung. Der Teil von BLIP-2, der wirklich trainiert werden muss, ist der Q-Former.
Wie in der Abbildung unten gezeigt, geben Sie zunächst ein Bild (das Bild rechts) in den Image Encoder ein. Der Text in der Mitte ist die vom Benutzer gestellte Frage oder Anweisung Eingabe in das große Sprachmodell. Schließlich wird die Antwort generiert, wahrscheinlich durch einen solchen Generierungsprozess.
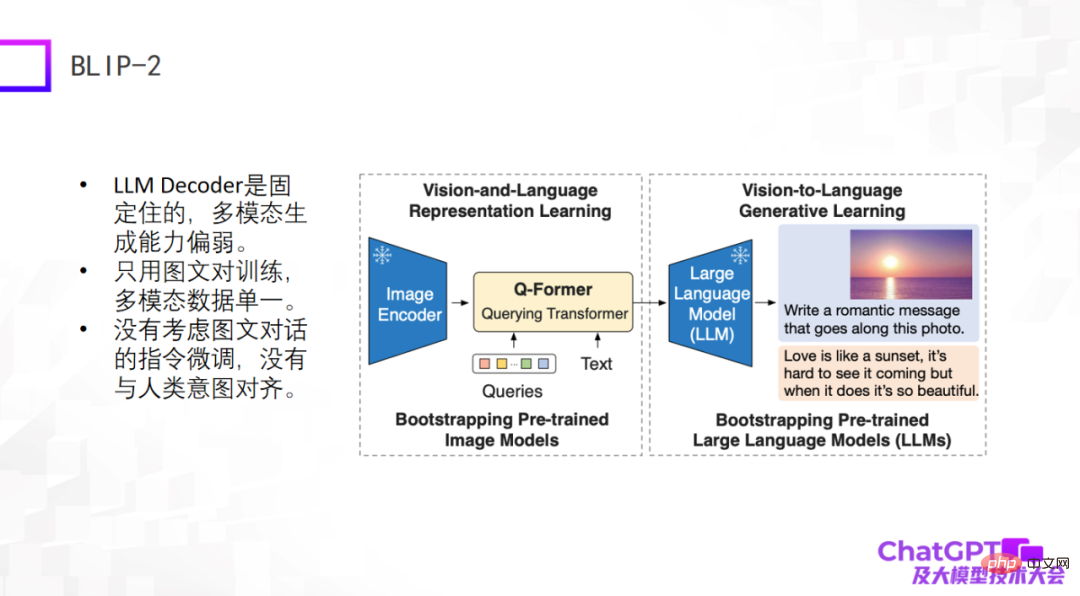
Die Mängel dieser beiden Modelle liegen auf der Hand, da sie relativ früh oder gerade erst erschienen sind und die von ChatGPT verwendeten technischen Methoden nicht berücksichtigt wurden. Zumindest gibt es keine Anweisungen für grafische Dialoge oder Multimodalität Die Feinabstimmung des Dialogs ist daher insgesamt nicht zufriedenstellend.
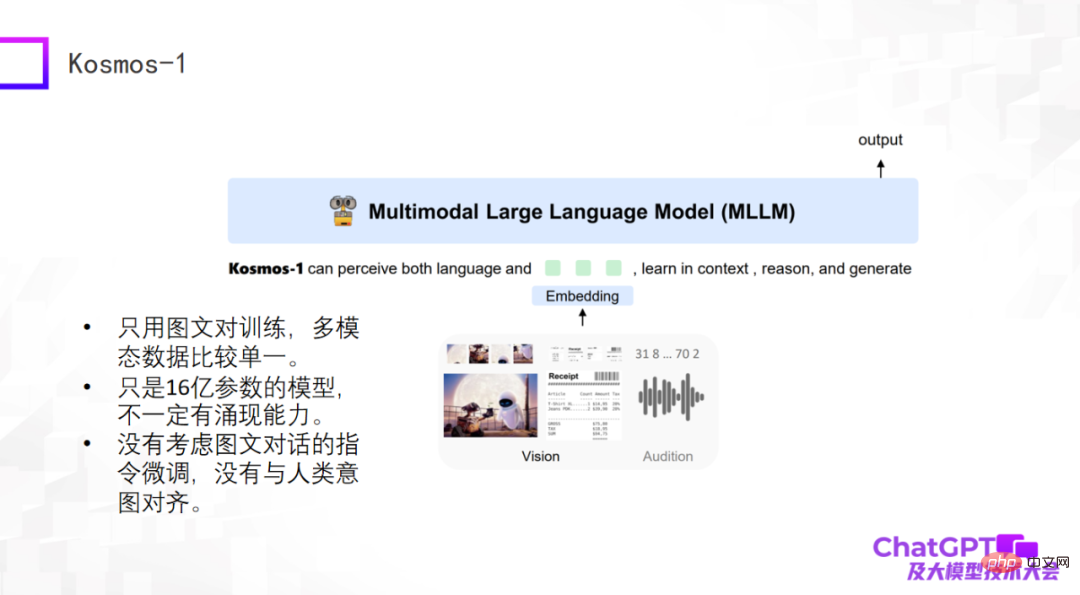
Der dritte ist Kosmos-1, der kürzlich von Microsoft veröffentlicht wurde. Er hat eine sehr einfache Struktur und verwendet nur Bild- und Textpaare für das Training. Die multimodalen Daten sind relativ einfach. Der größte Unterschied zwischen Kosmos-1 und den beiden oben genannten Modellen besteht darin, dass das große Sprachmodell selbst in den beiden oben genannten Modellen festgelegt ist, während das große Sprachmodell selbst in Kosmos-1 trainiert werden muss, also das Kosmos-1-Modell Die Nummer Die Anzahl der Parameter beträgt nur 1,6 Milliarden, und ein Modell mit 1,6 Milliarden Parametern kann möglicherweise nicht entstehen. Natürlich hat Kosmos-1 die Feinabstimmung der Befehle im grafischen Dialog nicht berücksichtigt, was dazu führte, dass manchmal Unsinn gesprochen wurde.
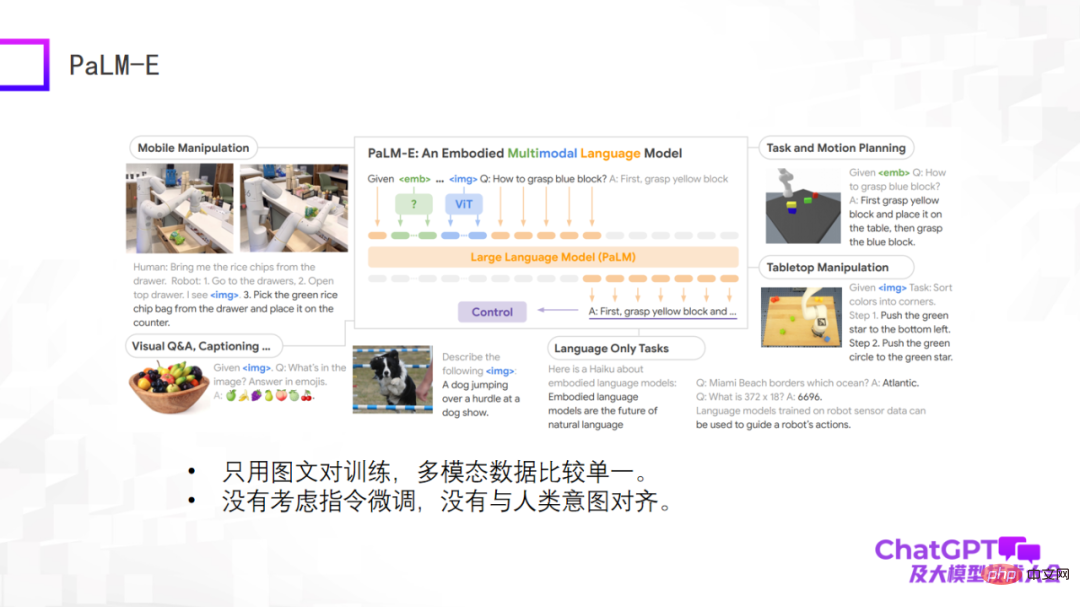
Das nächste Beispiel ist Googles multimodales verkörpertes visuelles Sprachmodell PaLM-E. Das PaLM-E-Modell ähnelt den ersten drei Beispielen und verwendet auch das große Sprachmodell ViT +. Der größte Durchbruch von PaLM-E besteht darin, dass es endlich die Möglichkeit untersucht, multimodale große Sprachmodelle im Bereich der Robotik zu implementieren. PaLM-E versucht den ersten Schritt der Erforschung, aber die Arten von Roboteraufgaben, die es berücksichtigt, sind sehr begrenzt und können nicht wirklich universell sein.
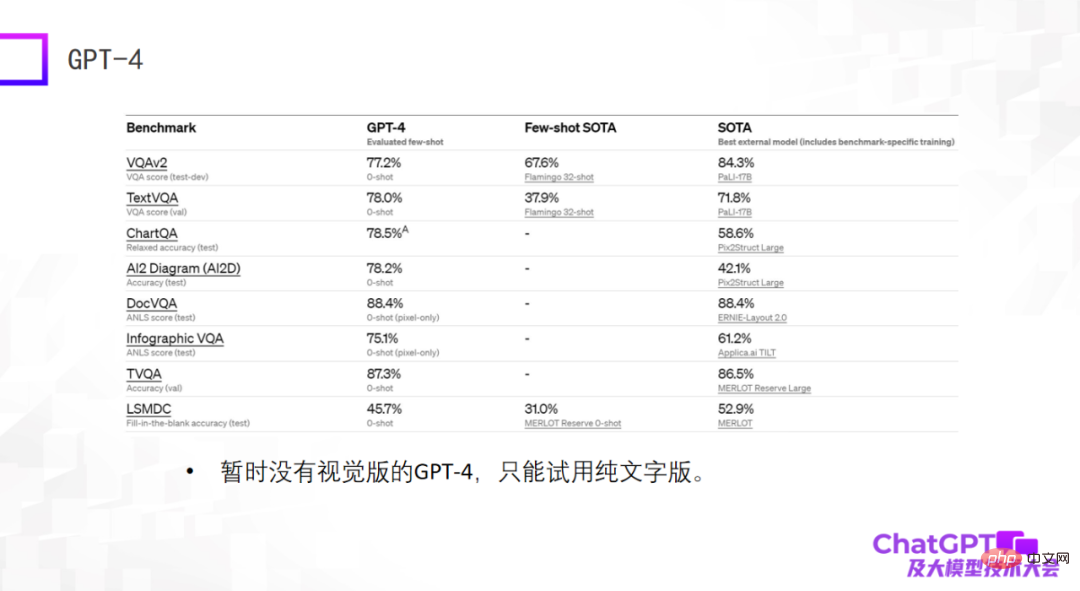
Das letzte Beispiel ist GPT-4 – das besonders erstaunliche Ergebnisse bei Standarddatensätzen liefert, oft sogar besser als die fein abgestimmten SOTA-Modelle, die derzeit auf dem Datensatz trainiert werden. Das mag ein Schock sein, hat aber eigentlich keine Bedeutung. Als wir vor zwei Jahren multimodale große Modelle erstellten, stellten wir fest, dass die Fähigkeiten großer Modelle nicht anhand von Standarddatensätzen bewertet werden können. Es gibt viele Unterschiede zwischen ihnen zwei. Große Lücke. Aus diesem Grund bin ich vom aktuellen GPT-4 etwas enttäuscht, da es nur Ergebnisse für Standarddatensätze liefert. Darüber hinaus handelt es sich bei dem derzeit verfügbaren GPT-4 nicht um eine visuelle Version, sondern um eine reine Textversion.
Im Allgemeinen werden die oben genannten Modelle für die allgemeine Sprachgenerierung verwendet, und die Eingabe ist eine multimodale Eingabe. Die folgenden beiden Modelle unterscheiden sich – nicht nur für die allgemeine Sprachgenerierung, sondern auch für die Generierung von Visionen sowohl Sprache als auch Bilder generieren.
Das erste ist Microsofts Visual ChatGPT, lassen Sie mich es kurz bewerten. Die Idee dieses Modells ist sehr einfach und es handelt sich eher um eine Überlegung beim Produktdesign. Es gibt viele Arten der visuellen Generierung sowie einige visuelle Erkennungsmodelle. Die Eingaben und Anweisungen für diese verschiedenen Aufgaben sind sehr unterschiedlich. Das Problem besteht darin, wie ein Modell alle diese Aufgaben umfassen kann. Daher hat Microsoft den Prompt-Manager entwickelt. Das im Kernteil von OpenAI verwendete ChatGPT entspricht der Übersetzung von Anweisungen für verschiedene visuelle Generierungsaufgaben durch ChatGPT. Bei den Fragen des Benutzers handelt es sich um in natürlicher Sprache beschriebene Anweisungen, die über ChatGPT in Anweisungen übersetzt werden, die die Maschine verstehen kann.
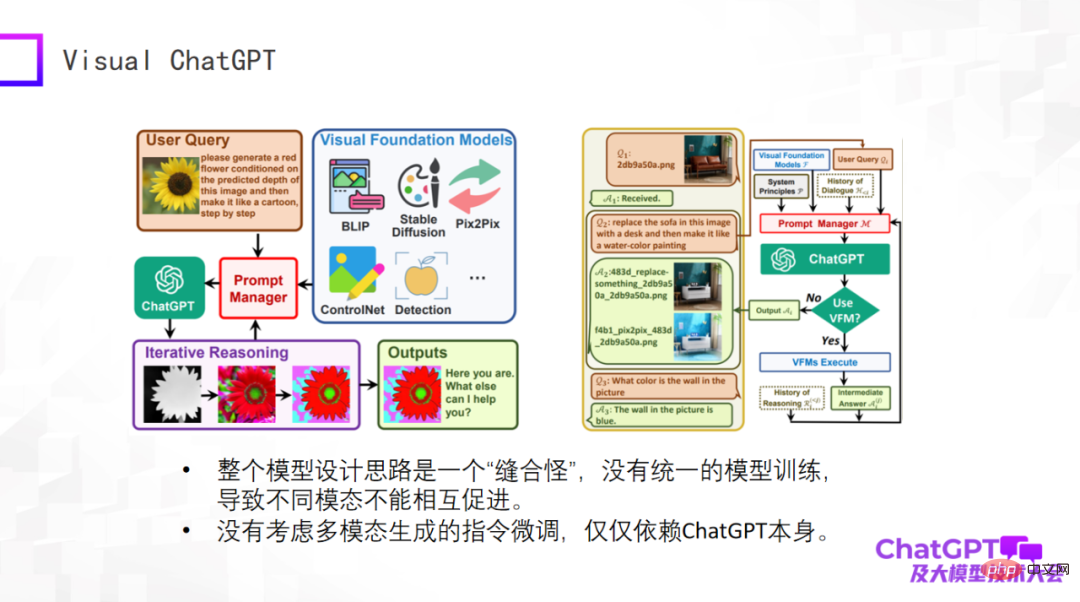
Visual ChatGPT macht genau so etwas. Aus Produktsicht ist es also wirklich gut, aus Sicht des Modelldesigns jedoch nichts Neues. Daher ist das Gesamtmodell aus Sicht des Modells ein „Stichmonster“. Es gibt kein einheitliches Modelltraining, was zu keiner gegenseitigen Förderung zwischen verschiedenen Modi führt. Wir betreiben Multimodalität, weil wir glauben, dass Daten aus verschiedenen Modalitäten einander helfen müssen. Und Visual ChatGPT berücksichtigt nicht die Feinabstimmung der Anweisungen zur multimodalen Generierung. Die Feinabstimmung der Anweisungen basiert nur auf ChatGPT selbst.
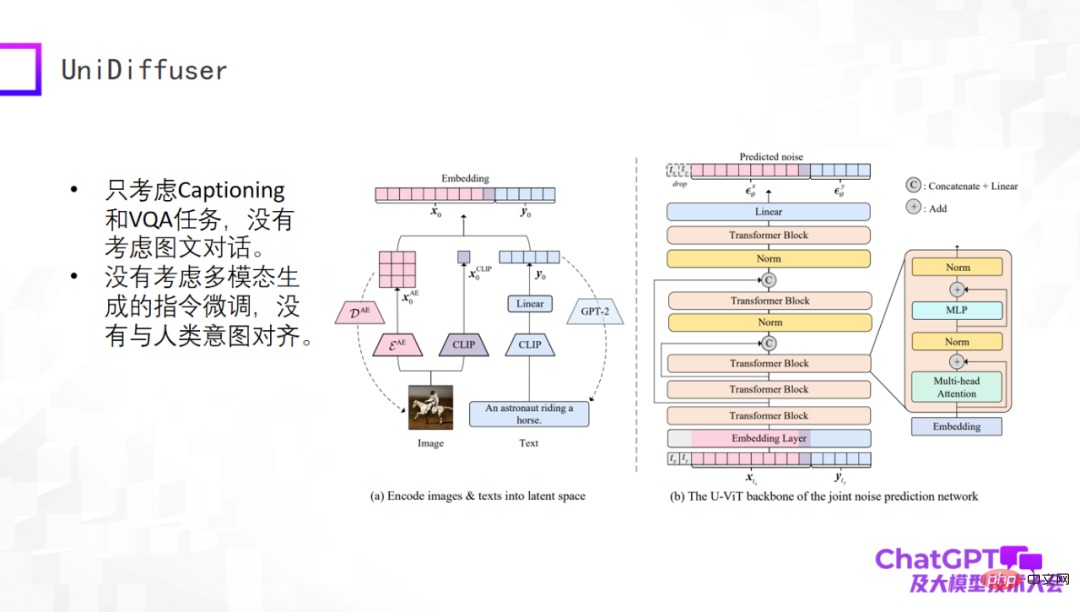
Das nächste Beispiel ist das UniDiffuser-Modell, das vom Team von Professor Zhu Jun von der Tsinghua-Universität veröffentlicht wurde. Aus akademischer Sicht kann dieses Modell tatsächlich Text und visuelle Inhalte aus multimodalen Eingaben generieren. Dies ist auf die transformatorbasierte Netzwerkarchitektur U-ViT zurückzuführen, die U-Net, der Kernkomponente von Stable Diffusion, ähnelt Dann werden Bilder und Textgenerierung in einem Framework vereint. Diese Arbeit selbst ist sehr aussagekräftig, aber sie ist noch relativ früh. Sie berücksichtigt beispielsweise nur Untertitel- und VQA-Aufgaben, berücksichtigt nicht mehrere Dialogrunden und optimiert die Anweisungen für die multimodale Generierung nicht.
Es gab schon so viele Rezensionen, dass wir auch ein Produkt namens ChatImg entwickelt haben, wie im Bild unten gezeigt. Im Allgemeinen enthält ChatImg einen Bild-Encoder, einen multimodalen Bild- und Text-Encoder und einen Text-Decoder. Es ähnelt Flamingo und BLIP-2, wir berücksichtigen jedoch mehr und es gibt detaillierte Unterschiede in der spezifischen Implementierung.
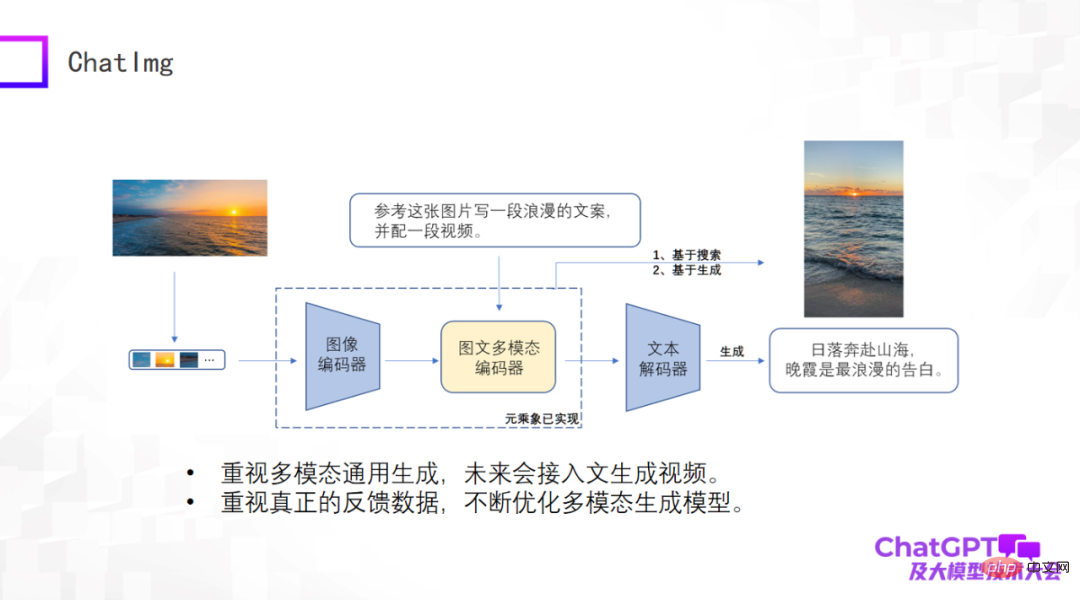
Einer der größten Vorteile von ChatImg ist, dass es Videoeingaben akzeptieren kann. Besonderes Augenmerk legen wir auf die multimodale allgemeine Generierung, einschließlich Textgenerierung, Bildgenerierung und Videogenerierung. Wir hoffen, in diesem Rahmen verschiedene Generierungsaufgaben implementieren zu können und letztendlich auf Text zugreifen zu können, um Videos zu generieren.
Zweitens legen wir besonderen Wert auf echte Benutzerdaten. Wir hoffen, das Generierungsmodell selbst kontinuierlich zu optimieren und seine Fähigkeiten nach Erhalt echter Benutzerdaten zu verbessern, deshalb haben wir die ChatImg-Anwendung veröffentlicht.
Die folgenden Bilder sind einige Beispiele, die wir als frühes Modell getestet haben. Obwohl es immer noch einige Dinge gibt, die nicht gut gemacht sind, kann ChatImg die Bilder im Allgemeinen immer noch verstehen. ChatImg kann beispielsweise Beschreibungen von Gemälden in Gesprächen generieren und auch kontextbezogenes Lernen durchführen.
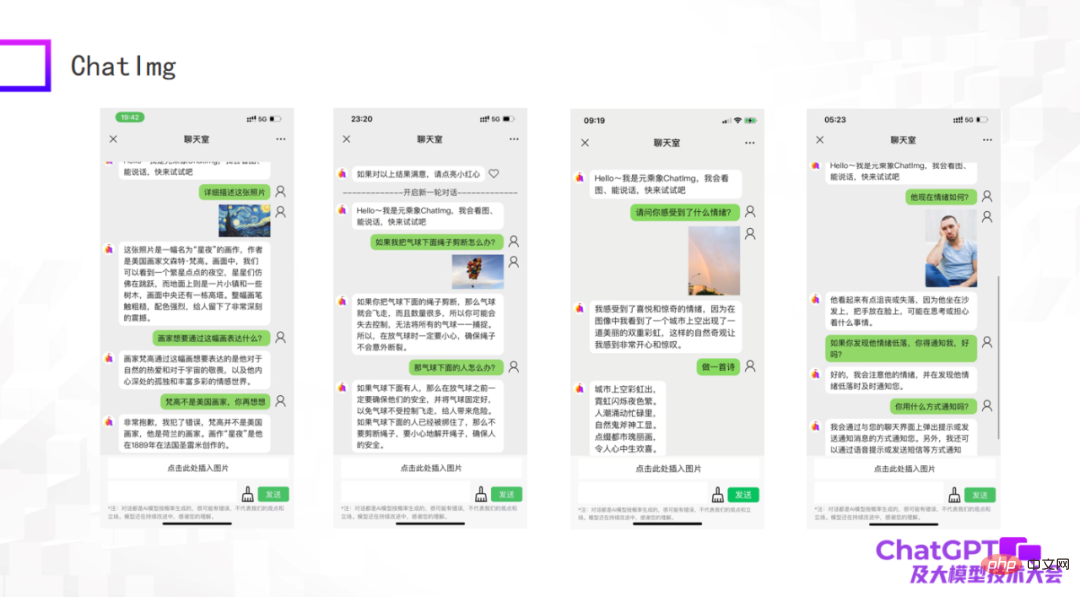
Das erste Beispiel im Bild oben beschreibt das Gemälde „Sternennacht“. In der Beschreibung nennt ChatImg es einen amerikanischen Maler Beispiel: ChatImg hat physikalische Rückschlüsse auf die Objekte im Bild gezogen; das dritte Beispiel ist ein Foto, das ich selbst aufgenommen habe und das zwei Regenbögen enthielt, und es wurde genau erkannt.
Uns ist aufgefallen, dass es beim dritten und vierten Beispiel im obigen Bild um emotionale Probleme geht. Dies hängt tatsächlich mit der Arbeit zusammen, die wir als Nächstes erledigen werden. Wir möchten ChatImg mit dem Roboter verbinden. Heutige Roboter sind meist passiv und alle Anweisungen sind voreingestellt, was sie sehr starr erscheinen lässt. Wir hoffen, dass mit ChatImg verbundene Roboter aktiv mit Menschen kommunizieren können. Wie geht das? Zuallererst muss der Roboter in der Lage sein, Menschen zu fühlen, um den Zustand der Welt und die Emotionen der Menschen objektiv zu sehen, oder um ein Spiegelbild zu erhalten. Anhand dieser beiden Beispiele glaube ich, dass dieses Ziel erreichbar ist.
Lassen Sie mich abschließend den heutigen Bericht zusammenfassen. Erstens haben ChatGPT und GPT-4 Innovationen in das Forschungsparadigma gebracht. Wir können uns nicht darüber beschweren, dass wir keine Ressourcen haben, es gibt immer Möglichkeiten Schwierigkeiten zu überwinden. Für die multimodale Forschung sind nicht einmal Maschinen mit Hunderten von Karten erforderlich. Solange entsprechende Strategien angewendet werden, kann eine kleine Anzahl von Maschinen gute Arbeit leisten. Zweitens haben alle bestehenden multimodalen generativen Modelle ihre eigenen Probleme. GPT-4 verfügt noch nicht über eine offene visuelle Version, und es gibt immer noch eine Chance für uns alle. Darüber hinaus denke ich, dass GPT-4 immer noch ein Problem hat, wie das multimodale generative Modell letztendlich aussehen sollte. Es gibt keine perfekte Antwort (tatsächlich enthüllt es keine Details von GPT-4). Das ist eigentlich eine gute Sache. Menschen auf der ganzen Welt sind sehr schlau und jeder hat seine eigenen Ideen. Dadurch kann eine neue Forschungssituation entstehen, in der hundert Blumen blühen. Das war’s für meine Rede, vielen Dank an alle.

Das obige ist der detaillierte Inhalt von„Lu Zhiwu, ein Forscher an der Renmin-Universität von China, schlug die wichtige Auswirkung von ChatGPT auf multimodale generative Modelle vor.'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
