Kurz gesagt, Ctrip-Back-End-Entwicklungsmanager mit Schwerpunkt auf technischer Architektur, Leistungsoptimierung, Transportplanung und anderen Bereichen.
1. Hintergrundeinführung
Aufgrund der Einschränkungen der Transportplanung und der Transportressourcen gibt es möglicherweise keinen direkten Transport zwischen den beiden vom Benutzer abgefragten Orten oder an wichtigen Feiertagen ist der direkte Transportausverkauft. Benutzer können ihr Ziel jedoch weiterhin durch Hin- und Rücktransfers wie Züge, Flugzeuge, Autos, Schiffe usw. erreichen. Darüber hinaus ist der Transfertransport manchmal preislich und zeitlich vorteilhafter. Beispielsweise kann die Verbindung mit dem Zug von Shanghai nach Yuncheng schneller und günstiger sein als mit einem Direktzug.
Abbildung 1 Liste der Ctrip-Zugtransfertransporte
Bei der Bereitstellung von Transfertransportlösungen besteht eine sehr wichtige Verbindung darin, zwei oder mehr Fahrten mit Zügen, Flugzeugen, Autos, Schiffen usw. zusammenzufügen, um eine zu bilden realisierbarer Transferplan. Die erste Schwierigkeit beim Zusammenführen des Transitverkehrs besteht darin, dass allein in Shanghai als Transitstadt fast 100 Millionen Kombinationen generiert werden können, da sich die Daten der Produktionslinie ständig ändern jederzeit und muss ständig aktualisiert werden. Abfragedaten zu Zügen, Flugzeugen, Autos und Schiffen. Das Spleißen des Transitverkehrs erfordert viel Rechenressourcen und E/A-Overhead, daher ist die Optimierung der Leistung besonders wichtig.
In diesem Artikel werden anhand von Beispielen die Prinzipien, Analyse- und Optimierungsmethoden vorgestellt, die bei der Optimierung der Übertragungsleistung beim Spleißen des Datenverkehrs angewendet werden, um den Lesern wertvolle Referenzen und Inspirationen zu bieten.
2. Optimierungsprinzipien
Leistungsoptimierung erfordert einen Ausgleich und Kompromisse zwischen verschiedenen Ressourcen und Einschränkungen unter der Prämisse, dass die Einhaltung einiger wichtiger Prinzipien dazu beitragen kann, Unsicherheiten zu beseitigen und die optimale Lösung zu finden. Insbesondere werden während des Optimierungsprozesses für das Spleißen des Übertragungsverkehrs hauptsächlich die folgenden drei Prinzipien befolgt:
2.1 Leistungsoptimierung ist eher ein Mittel als ein Zweck. Auch wenn es in diesem Artikel um Leistungsoptimierung geht, muss sie am Anfang dennoch hervorgehoben werden : Tun Sie es nicht zur Optimierung, sondern optimieren Sie es. Es gibt viele Möglichkeiten, Geschäftsanforderungen zu erfüllen, und die Leistungsoptimierung ist nur eine davon. Manchmal ist das Problem sehr komplex und es gibt viele Einschränkungen, ohne die Benutzererfahrung wesentlich zu beeinträchtigen. Eine Reduzierung der Auswirkungen auf Benutzer durch die Lockerung von Einschränkungen oder die Einführung anderer Prozesse ist auch eine gute Möglichkeit, Leistungsprobleme zu lösen. In der Softwareentwicklung gibt es viele Beispiele für erhebliche Kostensenkungen, die durch geringe Leistungseinbußen erreicht werden. Beispielsweise benötigt der HyperLogLog-Algorithmus, der für Kardinalitätsstatistiken (Entfernung von Duplikaten) in Redis verwendet wird, nur 12 KB Speicherplatz, um 264 Daten mit einem Standardfehler von 0,81 % zu zählen.
Zurück zum Problem selbst: Aufgrund der Notwendigkeit, häufig Produktionsliniendaten abzufragen und umfangreiche Verbindungsvorgänge durchzuführen, sind die Kosten sehr hoch, wenn jeder Benutzer bei der Abfrage sofort den aktuellsten Übertragungsplan zurückgeben muss. Um die Kosten zu senken, muss ein Gleichgewicht zwischen Reaktionszeit und Datenaktualität gefunden werden. Nach sorgfältiger Überlegung akzeptieren wir Dateninkonsistenzen auf Minutenebene. Für einige unbeliebte Routen und Daten gibt es bei der ersten Abfrage möglicherweise keinen guten Transferplan. Bitten Sie den Benutzer in diesem Fall einfach, die Seite zu aktualisieren.
2.2 Falsche Optimierung ist die Wurzel allen Übels
Donald Knuth erwähnte in „Structured Programming With Go To Statements“: „Programmierer verschwenden viel Zeit damit, über die Leistung unkritischer Pfade nachzudenken und sich Sorgen darüber zu machen, und versuchen es.“ Die Optimierung dieses Teils der Leistung wird sehr schwerwiegende negative Auswirkungen auf das Debuggen und die Wartung des gesamten Codes haben, daher sollten wir in 97 % der Fälle kleine Optimierungspunkte vergessen.“ Kurz gesagt, bevor das eigentliche Leistungsproblem entdeckt wird, wird eine übermäßige und auffällige Optimierung auf Codeebene nicht nur die Leistung nicht verbessern, sondern möglicherweise auch zu mehr Fehlern führen. Allerdings betonte der Autor auch: „Für die verbleibenden kritischen 3 % sollten wir uns die Gelegenheit zur Optimierung nicht entgehen lassen.“ Daher müssen Sie immer auf Leistungsprobleme achten, keine Entscheidungen treffen, die sich auf die Leistung auswirken, und bei Bedarf die richtigen Optimierungen vornehmen.
2.3 Analysieren Sie die Leistung quantitativ und klären Sie die Richtung der Optimierung.
Wie im vorherigen Abschnitt erwähnt, müssen Sie vor der Optimierung zunächst die Leistung quantifizieren und Engpässe identifizieren, damit die Optimierung gezielter erfolgen kann. Zur quantitativen Analyse der Leistung können zeitaufwändige Überwachungstools, Profiler-Leistungsanalysetools, Benchmark-Benchmark-Testtools usw. eingesetzt werden, wobei der Schwerpunkt auf Bereichen liegt, die besonders viel Zeit in Anspruch nehmen oder eine besonders hohe Ausführungshäufigkeit aufweisen. In Amdahls Gesetz heißt es: „Der Grad der Verbesserung der Systemleistung, der durch die Verwendung einer schnelleren Ausführungsmethode für eine bestimmte Komponente im System erreicht werden kann, hängt von der Häufigkeit ab, mit der diese Ausführungsmethode verwendet wird, oder vom Anteil der gesamten Ausführungszeit.“ "
Darüber hinaus ist es auch wichtig zu beachten, dass die Leistungsoptimierung ein langwieriger Kampf ist. Da sich das Unternehmen weiterentwickelt, ändern sich Architektur und Code ständig. Daher ist es umso notwendiger, die Leistung kontinuierlich zu quantifizieren, Engpässe kontinuierlich zu analysieren und Optimierungseffekte zu bewerten.
3. Der Weg zur Leistungsanalyse
3.1 Den Geschäftsprozess ordnen
Vor der Leistungsanalyse müssen wir zunächst den Geschäftsprozess ordnen. Das Zusammenfügen von Transfertransportplänen umfasst hauptsächlich die folgenden vier Schritte:
a. Laden Sie die Routenkarte, z. B. den Transfer von Peking nach Shanghai, wobei nur die Informationen der Route selbst berücksichtigt werden und nichts damit zu tun haben spezifischer Zug;
b Überprüfen Sie die Zug-, Produktionsliniendaten von Flugzeugen, Autos und Schiffen, einschließlich Abfahrtszeit, Ankunftszeit, Abfahrtsbahnhof, Preis und verbleibende Ticketinformationen usw.; c. Kombinieren Sie alle möglichen Transfertransportlösungen und berücksichtigen Sie dabei hauptsächlich den Transfer. Die Fahrzeit sollte nicht zu kurz sein, um zu vermeiden, dass der Transfer gleichzeitig abgeschlossen werden kann. Sie sollte nicht zu lang sein, um zu lange Wartezeiten zu vermeiden. Nachdem Sie praktikable Lösungen zusammengestellt haben, müssen Sie noch die Geschäftsfelder verbessern, z. B. Gesamtpreis, Gesamtzeit und Transferinformationen.
d Wählen Sie nach bestimmten Regeln einige Benutzer aus allen möglichen Transferplänen aus Programme, die von Interesse sein könnten.
3.2 Quantitative Analyseleistung
(1) Fügen Sie eine zeitaufwändige Überwachung hinzu
Die zeitaufwändige Überwachung ist die intuitivste Möglichkeit, die zeitaufwändige Situation jeder Phase aus einer Makroperspektive zu beobachten. Es kann nicht nur den zeitaufwändigen Wert und den zeitaufwändigen Anteil in jeder Phase des Geschäftsprozesses anzeigen, sondern auch den zeitaufwändigen Änderungstrend über einen langen Zeitraum hinweg beobachten.
Zeitaufwändige Überwachung kann das unternehmensinterne Indikatorüberwachungs- und Alarmsystem nutzen, um zeitaufwändiges Management zum Hauptprozess der Verbindung von Transportlösungen hinzuzufügen. Zu diesen Prozessen gehören das Laden von Streckenkarten, das Abfragen und Zusammenfügen von Schichtdaten, das Filtern und Speichern von Verbindungsplänen usw. Die zeitaufwändige Situation jeder Phase ist in Abbildung 2 dargestellt. Es ist ersichtlich, dass das Spleißen (einschließlich der Daten der Produktionslinie) den höchsten Zeitaufwand in Anspruch nimmt und daher in Zukunft zu einem wichtigen Optimierungsziel geworden ist. Abbildung 2: Zeitaufwändige Überwachung des Spleißens des Transitverkehrs. Daher sollte es nicht überschritten werden. Mehr, besser geeignet für die Überwachung von Hauptprozessen. Das entsprechende Profiler-Leistungsanalysetool (z. B. Async-Profiler) kann einen spezifischeren Aufrufbaum und das CPU-Auslastungsverhältnis jeder Funktion generieren und so dabei helfen, kritische Pfade und Leistungsengpässe zu analysieren und zu lokalisieren.
Abbildung 3 Spleiß-Aufrufbaum und CPU-Verhältnis
Wie in Abbildung 3 dargestellt, macht die Spleißlösung (combineTransferLines) 53,80 % aus und die Daten der Abfrageproduktionslinie (querySegmentCacheable, verwendeter Cache). 21,45 %. Im Spleißschema sind die Berechnung des Schema-Scores (computeTripScore, 48,22 % ausmachend), das Erstellen einer Schema-Entität (buildTripBO, 4,61 % ausmachend) und die Überprüfung der Spleißdurchführbarkeit (checkCombineMatchCondition, 0,91 % ausmachend) die drei größten Verknüpfungen.
Abbildung 4 Lösungsbewertungsaufrufbaum und CPU-Verhältnis
Während wir die Berechnungsplanbewertung (computeTripScore) mit dem höchsten Anteil weiter analysierten, stellten wir fest, dass sie hauptsächlich mit der benutzerdefinierten Zeichenfolgenformatierungsfunktion (StringUtils.format) zusammenhängt, einschließlich direkter Aufrufe (die zum Anzeigen von Planbewertungsdetails verwendet werden) und indirekte Aufrufe über getTripId Call (die ID, die zum Generieren des Schemas verwendet wird). Der größte Anteil des angepassten StringUtils.format ist java/lang/String.replace. Der native String-Ersatz von Java 8 wird durch reguläre Ausdrücke implementiert, was relativ ineffizient ist (dieses Problem wurde nach Java 9 behoben).
Mit Hilfe des Benchmark-Benchmark-Tools können Sie die Ausführungszeit Ihres Codes genauer messen. In Tabelle 1 verwenden wir JMH (Java Microbenchmark Harness), um zeitaufwändige Tests für drei String-Formatierungsmethoden und eine String-Spleißmethode durchzuführen. Die Testergebnisse zeigen, dass die String-Formatierung mit der Ersetzungsmethode von Java8 die schlechteste Leistung bringt, während die Verwendung der String-Splicing-Funktion von Apache die beste Leistung bringt.
Tabelle 1 Leistungsvergleich von String-Formatierung und Spleißen
Implementierung
Durchschnittlicher Zeitaufwand (uns) für 1000. Ausführungen
StringUtils .format implementiert mit Java8-Ersatz
1988.982
StringUtils.format implementiert mit Apache-Ersatz
656. 537
Java8 wird mit String geliefert. Format: 1417.474: 1417.474
b. Nehmen Sie das größte Element von der Spitze des großen Root-Heaps und fügen Sie es in die Ergebnismenge ein.
c Wenn sich noch Elemente in der Warteschlange befinden, in der sich das Element befindet, fügen Sie das nächste Element hinzu Heap;
d. Wiederholen Sie die Schritte 2 und 3, bis die Ergebnismenge K Elemente enthält oder alle Warteschlangen leer sind.
Abbildung 7 Multi-Way-Merge-Top-K-Algorithmus
4.2 Aufbau eines mehrstufigen Caches
Cache ist eine typische Raum-für-Zeit-Strategie, mit der Daten und Berechnungsergebnisse zwischengespeichert werden können Verbessern Sie die Zugriffseffizienz und die Cache-Ergebnisse, um wiederholte Berechnungen zu vermeiden. Während Caching Leistungsverbesserungen mit sich bringt, bringt es auch neue Probleme mit sich:
Die Cache-Kapazität ist begrenzt und die Strategien zum Laden, Aktualisieren, Ungültigmachen und Ersetzen von Daten müssen sorgfältig überlegt werden.
Das Design der Cache-Architektur : Normalerweise wird gesagt, dass Speichercaches (wie HashMap, Caffeine usw.) die höchste Leistung haben, gefolgt von verteilten Caches wie RocksDB, und die Obergrenze der Kapazität ist genau das Gegenteil sorgfältig ausgewählt und gemeinsam verwendet werden;
So lösen Sie das Problem der Cache-Inkonsistenz, wie lange können Sie Inkonsistenzen akzeptieren?
Beim Zusammenführen von Transfertransportlösungen müssen eine große Menge an Basisdaten (z. B. Bahnhöfe, Verwaltungsbereiche usw.) und umfangreiche dynamische Daten (z. B. Schichtdaten) verwendet werden. Basierend auf den oben genannten Faktoren und in Kombination mit den Geschäftsmerkmalen des Spleißens von öffentlichen Verkehrsmitteln ist die Cache-Architektur wie folgt konzipiert:
Grundlegende Daten (z. B. Bahnhöfe, Verwaltungsbereiche usw.), da das Datenvolumen gering ist und Die Häufigkeit der Änderungen ist gering, der gesamte Betrag wird in HashMap gespeichert und regelmäßig vollständig aktualisiert.
Einige Zug-, Flugzeug-, Auto- und Schiffsfahrplandaten werden in Redis zwischengespeichert, um die Zugriffseffizienz und Stabilität zu verbessern. Die Caching-Strategien verschiedener Produktionslinien unterscheiden sich geringfügig, aber im Allgemeinen handelt es sich um eine Kombination aus geplanten Aktualisierungen und durch die Suche ausgelösten Aktualisierungen.
Hunderte von Produktionsliniendaten können während eines Spleißvorgangs abgefragt werden, und Redis hat eine Millisekunde -Level-Verzögerung Es summiert sich zu einem sehr großen Betrag. Daher besteht die Hoffnung, eine weitere Schicht Speichercache auf Redis aufzubauen, um die Leistung zu verbessern. Durch die Analyse wurde festgestellt, dass es im Splicing-Prozess sehr offensichtliche Hot-Data gibt. Der Anteil der Abfragen zu beliebten Daten und Routen ist sehr hoch und die Anzahl relativ begrenzt. Daher kann dieser Teil der Hot-Daten im Speichercache gespeichert und durch LFU (Least Frequently Used) ersetzt werden. Die endgültige Trefferquote im Datenspeichercache der Produktionslinie erreicht mehr als 45 %, was einer Reduzierung des E/A-Overheads um fast die Hälfte entspricht .
Da Dateninkonsistenzen auf Minutenebene akzeptiert werden können, werden die Verbindungsergebnisse zwischengespeichert. Wenn der nächste Benutzer während des Gültigkeitszeitraums dieselbe Route am selben Abfahrtsdatum abfragt, können die zwischengespeicherten Daten direkt verwendet werden. Da die Daten des gespleißten Übertragungsschemas relativ groß sind, werden die Spleißergebnisse in RocksDB gespeichert. Obwohl die Leistung nicht so gut ist wie bei Redis, sind die Auswirkungen auf eine einzelne Abfrage akzeptabel.
Abbildung 8 Mehrstufige Cache-Struktur
4.3 Vorverarbeitung
Obwohl theoretisch jede Stadt als Transitpunkt zwischen den beiden Orten ausgewählt werden kann, können die meisten Transitstädte tatsächlich keine qualitativ hochwertige Verbindung herstellen planen. Daher werden einige hochwertige Übertragungspunkte zunächst durch Offline-Vorverarbeitung ausgesiebt, wodurch der Lösungsraum von Tausenden auf Zehner reduziert wird. Im Vergleich zu sich dynamisch ändernden Schichten sind die Liniendaten relativ fest und können einmal täglich berechnet werden. Darüber hinaus kann die Offline-Vorverarbeitung mithilfe der Big-Data-Technologie große Datenmengen verarbeiten und ist relativ unempfindlich gegenüber dem Zeitaufwand.
4.4 Multithreading
In einem Spleißprozess müssen Dutzende Leitungen mit unterschiedlichen Übergabepunkten verarbeitet werden. Das Spleißen jeder Zeile erfolgt unabhängig voneinander, sodass Multithreading verwendet werden kann, was die Verarbeitungszeit minimiert. Aufgrund des Einflusses der Anzahl der Zeilenverschiebungen und der Cache-Trefferrate ist es jedoch schwierig, die Spleißzeit verschiedener Zeilen konsistent zu halten. Wenn zwei Threads die gleiche Anzahl an Aufgaben zugewiesen werden, muss der Thread selbst dann warten, bis die Ausführung des anderen Threads schnell abgeschlossen ist, bevor er mit dem nächsten Schritt fortfahren kann. Um diese Situation zu vermeiden, wird der Work-Stealing-Mechanismus von ForkJoinPool verwendet. Dieser Mechanismus kann sicherstellen, dass jeder Thread, nachdem er seine eigene Aufgabe abgeschlossen hat, auch die unvollendete Arbeit anderer Threads teilt, die Effizienz der Parallelität verbessert und die Leerlaufzeit verkürzt.
Aber Multithreading ist kein Allheilmittel, Sie müssen bei der Verwendung darauf achten:
子Die Ausführung von Aufgaben muss unabhängig voneinander erfolgen und darf sich nicht gegenseitig beeinflussen. Wenn eine Abhängigkeit besteht, müssen Sie auf die Ausführung der vorherigen Aufgabe warten, bevor Sie die nächste Aufgabe starten. Dadurch wird Multithreading bedeutungslos. Die Obergrenze besteht darin, dass zu viele Threads die Leistung aufgrund häufiger Kontextwechsel verringern muss auf Indikatoren wie die Anzahl der Threads, die CPU-Auslastung und die CPU-gedrosselte Zeit geachtet werden.
4.5 Verzögerte Berechnung
Indem die Berechnung auf den erforderlichen Zeitpunkt verschoben wird, kann viel redundanter Overhead vermieden werden. Nach dem Zusammenfügen des Übertragungsplans müssen Sie beispielsweise die Planeinheit aufbauen und die Geschäftsfelder verbessern. Auch dieser Teil verbraucht Ressourcen. Und nicht alle gespleißten Lösungen werden aussortiert, was bedeutet, dass diese nicht aussortierten Lösungen immer noch Rechenressourcen verbrauchen müssen. Daher verzögert sich die Erstellung des vollständigen Lösungsentitätsobjekts. Zehntausende Lösungen werden im Spleißprozess zunächst als leichte Zwischenobjekte gespeichert, und die vollständige Lösungsentität wird erst nach dem Screening für Hunderte von Zwischenobjekten erstellt.
4.6 JVM-Optimierung
Das Transit Traffic Splicing-Projekt basiert auf Java 8 und verwendet den G1 (Garbage-First) Garbage Collector für die Bereitstellung Auf der 8C8G-Maschine. G1 erreicht einen hohen Durchsatz und erfüllt gleichzeitig die Anforderungen an die Pausenzeit weitestgehend. Die von der Systemarchitekturabteilung festgelegten Standardparameter sind bereits für die meisten Szenarien geeignet und erfordern normalerweise keine besondere Optimierung.
Es gibt jedoch zu viele Leitungsübertragungslösungen, was zu zu großen Paketen führt, die die Hälfte der Regionsgröße überschreiten (die Standardregionsgröße für 8G beträgt 2 MB). , was dazu führt, dass viele in die junge Generation eintreten sollten. Das große Objekt gelangt direkt in die alte Generation. Um diese Situation zu vermeiden, wird die Regionsgröße auf 16 MB geändert.
5. Zusammenfassung
Durch die obige Analyse und Optimierung werden die Änderungen im Spleißzeitverbrauch in Abbildung 9 dargestellt:
#🎜 ## Obwohl jedes Unternehmen und jedes Szenario seine eigenen Merkmale hat, erfordert die Leistungsoptimierung auch eine spezifische Analyse. Die Prinzipien sind jedoch dieselben und Sie können weiterhin auf die in diesem Artikel beschriebenen Analyse- und Optimierungsmethoden zurückgreifen. Eine Zusammenfassung aller Analyse- und Optimierungsmethoden in diesem Artikel ist in Abbildung 10 dargestellt.
Abbildung 10 Zusammenfassung der Spleißoptimierung des Transfertransportplans
Das obige ist der detaillierte Inhalt vonOptimieren Sie die Verbindungsleistung des Transfertransportplans von Ctrip. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Erklärung dieser Website
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Wie können wir die Leistung nach Erhalt eines neuen Computers einrichten und optimieren? Benutzer können direkt auf „Datenschutz und Sicherheit“ klicken und dann auf „Allgemein“ (Werbe-ID, lokaler Inhalt, Anwendungsstart, Einstellungsempfehlungen, Produktivitätstools) klicken oder die lokale Gruppenrichtlinie direkt öffnen Lassen Sie mich den Benutzern im Detail vorstellen, wie sie die Einstellungen optimieren und die Leistung des neuen Win11-Computers nach Erhalt verbessern können: 1. Drücken Sie die Tastenkombination [Win+i], um Einstellungen zu öffnen, und klicken Sie dann Klicken Sie links auf [Datenschutz und Sicherheit] und rechts unter „Windows-Berechtigungen“ auf „Allgemein (Werbe-ID, lokaler Inhalt, App-Start, Einstellungsvorschläge, Tools)“.
Laravel ist ein beliebtes PHP-Entwicklungsframework, wird jedoch manchmal dafür kritisiert, dass es so langsam wie eine Schnecke ist. Was genau verursacht die unbefriedigende Geschwindigkeit von Laravel? In diesem Artikel werden die Gründe, warum Laravel in vielerlei Hinsicht so langsam wie eine Schnecke ist, ausführlich erläutert und mit spezifischen Codebeispielen kombiniert, um den Lesern zu einem tieferen Verständnis dieses Problems zu verhelfen. 1. Probleme mit der ORM-Abfrageleistung In Laravel ist ORM (Object Relational Mapping) eine sehr leistungsstarke Funktion, die dies ermöglicht
Die Garbage Collection (GC) von Golang war schon immer ein heißes Thema unter Entwicklern. Als schnelle Programmiersprache kann der integrierte Garbage Collector von Golang den Speicher sehr gut verwalten, mit zunehmender Programmgröße treten jedoch manchmal Leistungsprobleme auf. In diesem Artikel werden die GC-Optimierungsstrategien von Golang untersucht und einige spezifische Codebeispiele bereitgestellt. Die Garbage Collection im Garbage Collector von Golang Golang basiert auf gleichzeitigem Mark-Sweep (concurrentmark-s
Entschlüsselung von Laravel-Leistungsengpässen: Optimierungstechniken vollständig enthüllt! Als beliebtes PHP-Framework bietet Laravel Entwicklern umfangreiche Funktionen und ein komfortables Entwicklungserlebnis. Mit zunehmender Größe des Projekts und steigender Anzahl an Besuchen kann es jedoch zu Leistungsengpässen kommen. Dieser Artikel befasst sich mit den Techniken zur Leistungsoptimierung von Laravel, um Entwicklern dabei zu helfen, potenzielle Leistungsprobleme zu erkennen und zu lösen. 1. Optimierung der Datenbankabfrage mithilfe von Eloquent. Vermeiden Sie verzögertes Laden, wenn Sie Eloquent zum Abfragen der Datenbank verwenden
Die Zeitkomplexität misst die Ausführungszeit eines Algorithmus im Verhältnis zur Größe der Eingabe. Zu den Tipps zur Reduzierung der Zeitkomplexität von C++-Programmen gehören: Auswahl geeigneter Container (z. B. Vektor, Liste) zur Optimierung der Datenspeicherung und -verwaltung. Nutzen Sie effiziente Algorithmen wie die schnelle Sortierung, um die Rechenzeit zu verkürzen. Eliminieren Sie mehrere Vorgänge, um Doppelzählungen zu reduzieren. Verwenden Sie bedingte Verzweigungen, um unnötige Berechnungen zu vermeiden. Optimieren Sie die lineare Suche, indem Sie schnellere Algorithmen wie die binäre Suche verwenden.
Laravel-Leistungsengpass aufgedeckt: Optimierungslösung aufgedeckt! Mit der Entwicklung der Internettechnologie ist die Leistungsoptimierung von Websites und Anwendungen immer wichtiger geworden. Als beliebtes PHP-Framework kann es bei Laravel während des Entwicklungsprozesses zu Leistungsengpässen kommen. In diesem Artikel werden die Leistungsprobleme untersucht, auf die Laravel-Anwendungen stoßen können, und einige Optimierungslösungen und spezifische Codebeispiele bereitgestellt, damit Entwickler diese Probleme besser lösen können. 1. Optimierung von Datenbankabfragen Datenbankabfragen sind einer der häufigsten Leistungsengpässe in Webanwendungen. existieren
1. Drücken Sie die Tastenkombination (Win-Taste + R) auf dem Desktop, um das Ausführungsfenster zu öffnen, geben Sie dann [regedit] ein und drücken Sie zur Bestätigung die Eingabetaste. 2. Nachdem wir den Registrierungseditor geöffnet haben, klicken wir zum Erweitern auf [HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionExplorer] und prüfen dann, ob sich im Verzeichnis ein Serialize-Element befindet. Wenn nicht, können wir mit der rechten Maustaste auf Explorer klicken, ein neues Element erstellen und es Serialize nennen. 3. Klicken Sie dann auf „Serialisieren“, klicken Sie dann mit der rechten Maustaste auf die leere Stelle im rechten Bereich, erstellen Sie einen neuen DWORD-Wert (32) und nennen Sie ihn „Star“.
Die Parameterkonfiguration des Vivox100 wurde enthüllt: Wie kann die Prozessorleistung optimiert werden? In der heutigen Zeit der rasanten technologischen Entwicklung sind Smartphones zu einem unverzichtbaren Bestandteil unseres täglichen Lebens geworden. Als wichtiger Bestandteil eines Smartphones steht die Leistungsoptimierung des Prozessors in direktem Zusammenhang mit der Benutzererfahrung des Mobiltelefons. Als hochkarätiges Smartphone hat die Parameterkonfiguration des Vivox100 große Aufmerksamkeit erregt, insbesondere die Optimierung der Prozessorleistung hat bei den Benutzern große Aufmerksamkeit erregt. Als „Gehirn“ des Mobiltelefons beeinflusst der Prozessor direkt die Laufgeschwindigkeit des Mobiltelefons.

 Technologie-Peripheriegeräte
Technologie-Peripheriegeräte

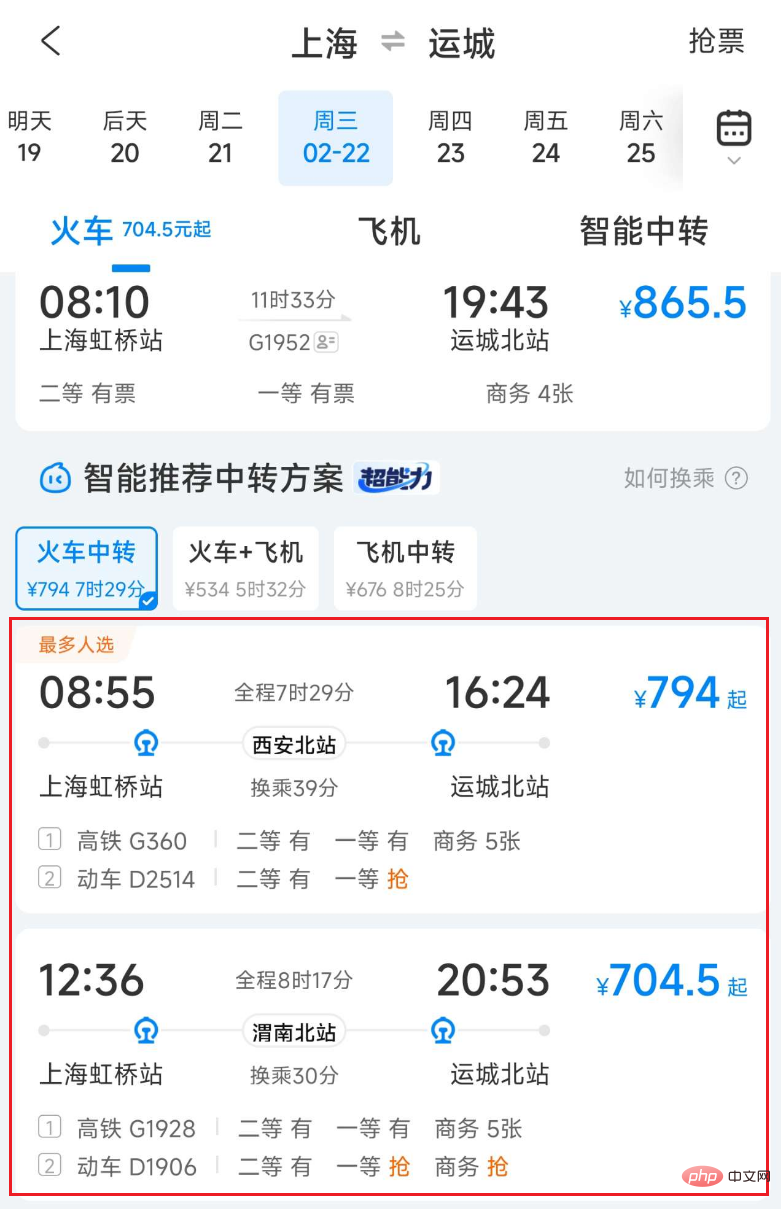
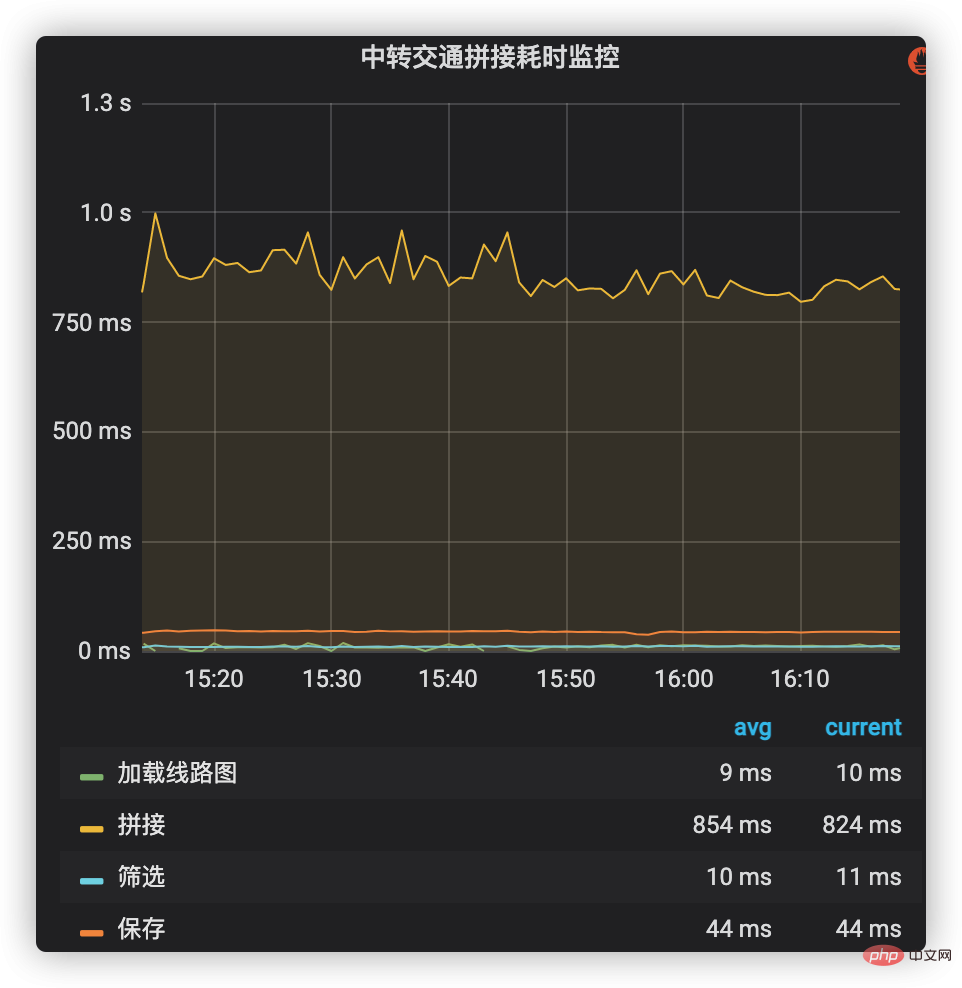


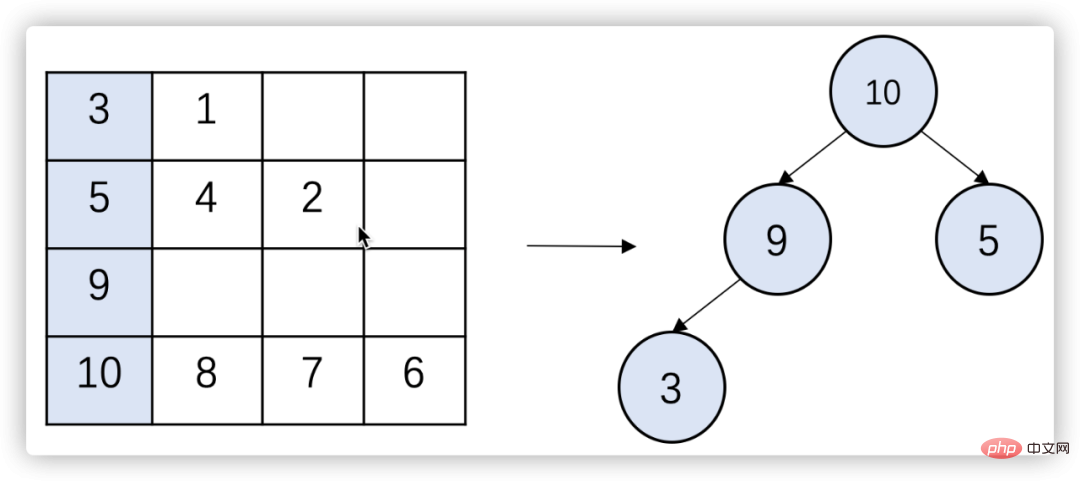
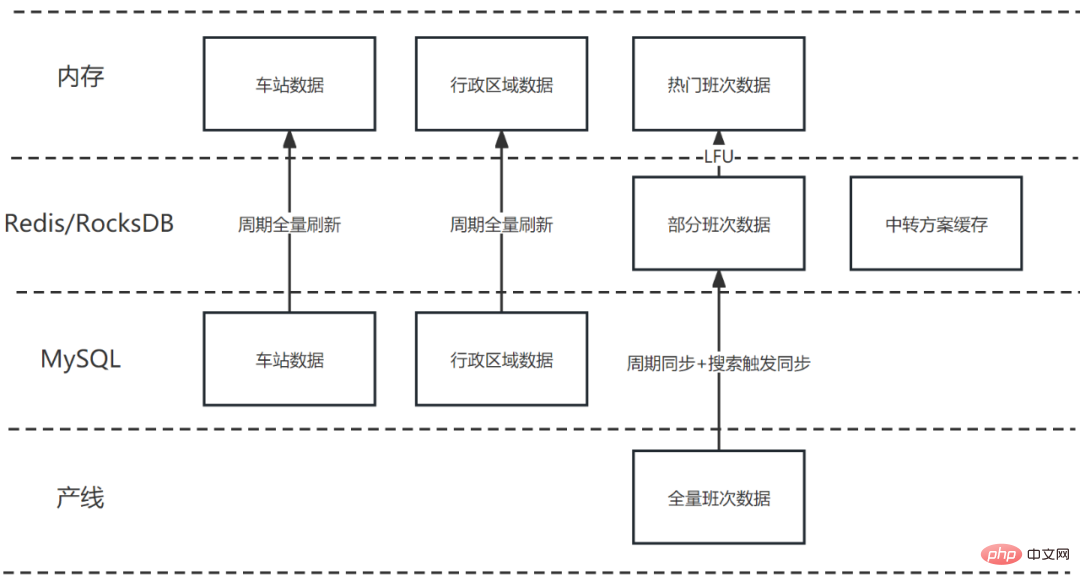
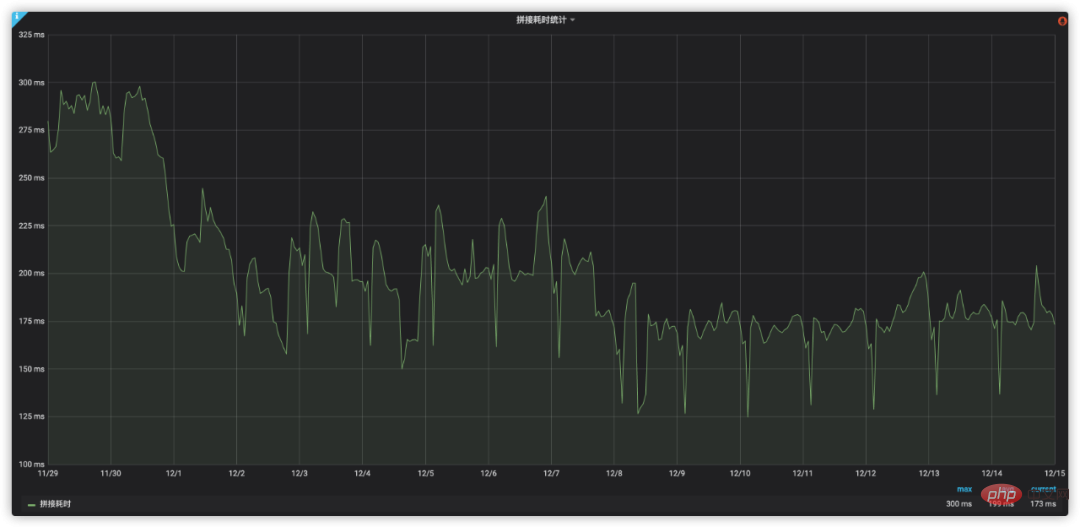 Abbildung 10 Zusammenfassung der Spleißoptimierung des Transfertransportplans
Abbildung 10 Zusammenfassung der Spleißoptimierung des Transfertransportplans