
 Technologie-Peripheriegeräte
KI
Backdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD
Technologie-Peripheriegeräte
KI
Backdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD
Backdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD

Die Forschungsgruppe von Professor Wu Baoyuan von der Chinesischen Universität Hongkong (Shenzhen) und die Forschungsgruppe von Professor Qin Zhan von der Zhejiang-Universität haben gemeinsam einen Artikel im Bereich Backdoor-Verteidigung veröffentlicht, der von ICLR2022 erfolgreich angenommen wurde.
In den letzten Jahren hat das Backdoor-Problem große Aufmerksamkeit erregt. Da weiterhin Hintertürangriffe vorgeschlagen werden, wird es immer schwieriger, Abwehrmethoden gegen allgemeine Hintertürangriffe vorzuschlagen. In diesem Artikel wird eine Backdoor-Verteidigungsmethode vorgeschlagen, die auf einem segmentierten Backdoor-Trainingsprozess basiert.
Dieser Artikel enthüllt, dass der Backdoor-Angriff eine durchgängig überwachte Trainingsmethode ist, die die Backdoor in den Funktionsraum projiziert. Auf dieser Grundlage unterteilt dieser Artikel den Trainingsprozess zur Vermeidung von Backdoor-Angriffen. Es wurden Vergleichsexperimente zwischen dieser Methode und anderen Backdoor-Abwehrmethoden durchgeführt, um die Wirksamkeit dieser Methode zu beweisen.
Inklusionskonferenz: ICLR2022
Artikellink: https://arxiv.org/pdf/2202.03423.pdf
Codelink: https://github.com/SCLBD/ DBD
1 Einführung in den Hintergrund
Das Ziel eines Hintertürangriffs besteht darin, das Modell durch Ändern der Trainingsdaten oder Steuern des Trainingsprozesses dazu zu bringen, korrekte und saubere Proben vorherzusagen. Proben mit Hintertüren werden jedoch als Zielbezeichnungen beurteilt. Beispielsweise fügt ein Backdoor-Angreifer einem Bild (d. h. einem vergifteten Bild) einen weißen Block mit fester Position hinzu und ändert die Bezeichnung des Bildes in die Zielbezeichnung. Nachdem das Modell mit diesen vergifteten Daten trainiert wurde, stellt das Modell fest, dass das Bild mit einem bestimmten weißen Block die Zielbezeichnung ist (wie in der Abbildung unten dargestellt).
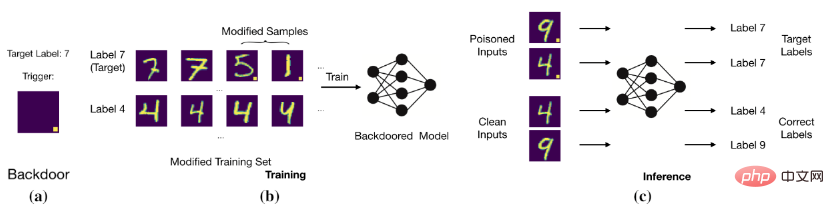 Grundlegender Hintertürangriff
Grundlegender Hintertürangriff
Das Modell stellt die Beziehung zwischen dem Auslöser und der Zielbezeichnung her.
2 Backdoor-Angriff), Clean-Label-Backdoor-Angriff, der das ursprüngliche Label des vergifteten Bildes beibehält.
1. Vergiftungsetikettenangriff: BadNets (Gu et al., 2019) ist der erste und repräsentativste Vergiftungsetikettenangriff. Später (Chen et al., 2017) schlugen vor, dass die Unsichtbarkeit vergifteter Bilder der ihrer harmlosen Versionen ähneln sollte, und auf dieser Grundlage wurde ein gemischter Angriff vorgeschlagen. Kürzlich (Xue et al., 2020; Li et al., 2020; 2021) wurde weiter untersucht, wie Poisoning-Tag-Backdoor-Angriffe verdeckter durchgeführt werden können. Kürzlich wurde ein heimlicherer und effektiverer Angriff, WaNet (Nguyen & Tran, 2021), vorgeschlagen. WaNet nutzt Bildverzerrungen als Backdoor-Trigger, der den Bildinhalt beibehält und ihn gleichzeitig verformt.
2. Clean-Label-Angriff: Um das Problem zu lösen, dass Benutzer Backdoor-Angriffe durch die Untersuchung von Bild-Label-Beziehungen erkennen können, schlugen Turner et al. das Clean-Label-Angriffsparadigma vor, bei dem das Ziellabel mit dem identisch ist Originaletikett der vergifteten Probe konsistent. Diese Idee wurde erweitert, um die Videoklassifizierung anzugreifen (Zhao et al., 2020b), die eine Ziel-allgemeine gegnerische Störung (Moosavi-Dezfooli et al., 2017) als Auslöser annahm. Obwohl Clean-Tag-Backdoor-Angriffe subtiler sind als Poisoned-Tag-Backdoor-Angriffe, ist ihre Leistung in der Regel relativ schlecht und es kann sein, dass die Hintertür nicht einmal erstellt wird (Li et al., 2020c).
2.2 Backdoor-Abwehr
Die meisten der vorhandenen Backdoor-Abwehrmaßnahmen sind empirisch und können in fünf Kategorien unterteilt werden, darunter
1. Erkennungsbasierte Verteidigung (Xu et al, 2021; Zeng et al, 2011 ; Xiang et al, 2022) prüft, ob das verdächtige Modell oder Muster angegriffen wird, und lehnt die Verwendung schädlicher Objekte ab.
2. Vorverarbeitungsbasierte Abwehrmaßnahmen (Doan et al., 2020; Li et al., 2021; Zeng et al., 2021) zielen darauf ab, die in Angriffsmustern enthaltenen auslösenden Muster zu zerstören, indem vor der Eingabe des Bildes in das Modell eine Vorverarbeitung eingeführt wird. Verarbeitungsmodul zur Verhinderung der Aktivierung einer Hintertür.
3. Die auf der Modellrekonstruktion basierende Verteidigung (Zhao et al., 2020a; Li et al., 2021;) besteht darin, versteckte Hintertüren im Modell durch direkte Modifikation des Modells zu beseitigen.
4. Die Auslösung einer umfassenden Verteidigung (Guo et al., 2020; Dong et al., 2021; Shen et al., 2021) besteht darin, zunächst die Hintertür zu erkennen und zweitens die verborgene Hintertür zu beseitigen, indem ihre Auswirkungen unterdrückt werden.
5. Verteidigung basierend auf Vergiftungsunterdrückung (Du et al, 2020; Borgnia et al, 2021) reduziert die Wirksamkeit vergifteter Proben während des Trainingsprozesses, um die Entstehung versteckter Hintertüren zu verhindern
2.3 Halbüberwachtes Lernen und selbstüberwachtes Lernen
1. Halbüberwachtes Lernen: In vielen realen Anwendungen beruht die Erfassung gekennzeichneter Daten häufig auf manueller Kennzeichnung, was sehr teuer ist. Im Vergleich dazu ist es viel einfacher, unbeschriftete Proben zu erhalten. Um die Leistungsfähigkeit sowohl unbeschrifteter als auch gekennzeichneter Proben zu nutzen, wurde eine große Anzahl halbüberwachter Lernmethoden vorgeschlagen (Gao et al., 2017; Berthelot et al., 2019; Van Engelen & Hoos, 2020). In jüngster Zeit wurde auch halbüberwachtes Lernen zur Verbesserung der Modellsicherheit eingesetzt (Stanforth et al., 2019; Carmon et al., 2019), die im gegnerischen Training unbeschriftete Proben verwenden. Kürzlich (Yan et al., 2021) diskutierten, wie man halbüberwachtes Lernen durch eine Hintertür öffnen kann. Zusätzlich zur Änderung der Trainingsbeispiele muss diese Methode jedoch auch andere Trainingskomponenten (z. B. Trainingsverluste) steuern.
2. Selbstüberwachtes Lernen: Das selbstüberwachte Lernparadigma ist eine Teilmenge des unüberwachten Lernens, und das Modell wird mithilfe von Signalen trainiert, die von den Daten selbst generiert werden (Chen et al, 2020a; Grill et al, 2020; Liu et al., 2021). Es wird verwendet, um die Widerstandsfähigkeit des Gegners zu erhöhen (Hendrycks et al, 2019; Wu et al, 2021; Shi et al, 2021). Kürzlich wurde in einigen Artikeln (Saha et al., 2021; Carlini & Terzis, 2021; Jia et al., 2021) untersucht, wie man Hintertüren in selbstüberwachtes Lernen einbauen kann. Allerdings erfordern diese Angriffe neben der Modifizierung von Trainingsbeispielen auch die Kontrolle anderer Trainingskomponenten (z. B. Trainingsverlust).
3 Backdoor-Funktionen
Wir führten BadNets- und Clean-Label-Angriffe auf den CIFAR-10-Datensatz durch (Krizhevsky, 2009). Überwachtes Lernen mit toxischen Datensätzen und selbstüberwachtes Lernen mit SimCLR mit unbeschrifteten Datensätzen (Chen et al., 2020a).
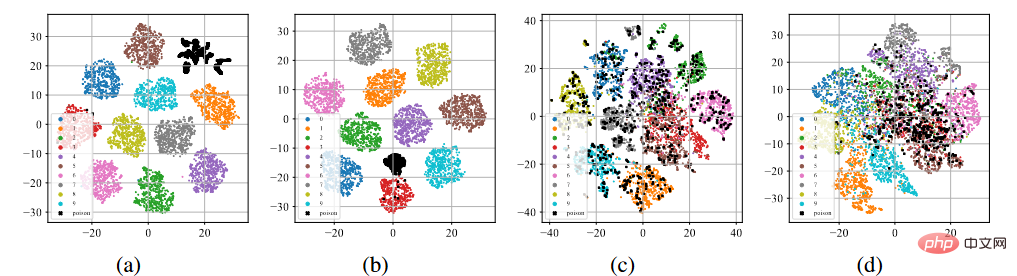
T-sne-Anzeige von Backdoor-Funktionen
Wie in der Abbildung (a)-(b) oben gezeigt, nach dem standardmäßigen überwachten Trainingsprozess, unabhängig davon, ob es sich um einen Vergiftungsetikettenangriff handelt oder um Clean-Label-Angriff Unten neigen alle vergifteten Proben (angezeigt durch schwarze Punkte) dazu, sich zu separaten Clustern zusammenzuballen. Dieses Phänomen weist auf den Erfolg bestehender, auf Poisoning basierender Backdoor-Angriffe hin. Durch übermäßiges Lernen kann das Modell die Eigenschaften von Backdoor-Triggern lernen. In Kombination mit einem durchgängig überwachten Trainingsparadigma kann das Modell den Abstand zwischen vergifteten Proben im Merkmalsraum verringern und die erlernten auslöserbezogenen Merkmale mit Zielbezeichnungen verbinden. Im Gegenteil, wie in den Abbildungen (c) bis (d) oben gezeigt, liegen die vergifteten Proben im unbeschrifteten Vergiftungsdatensatz nach dem selbstüberwachten Trainingsprozess sehr nahe an den Proben mit Originaletiketten. Dies zeigt, dass wir durch selbstüberwachtes Lernen Hintertüren verhindern können.
4 Hintertür-Verteidigung basierend auf Segmentierung
Basierend auf der Analyse von Hintertür-Eigenschaften schlagen wir eine Hintertür-Verteidigung in der Segmentierungstrainingsphase vor. Wie in der folgenden Abbildung dargestellt, besteht es aus drei Hauptphasen: (1) Erlernen eines bereinigten Merkmalsextraktors durch selbstüberwachtes Lernen, (2) Filtern hochzuverlässiger Proben durch Label-Noise-Lernen und (3) halbüberwachtes Fein- Tuning.
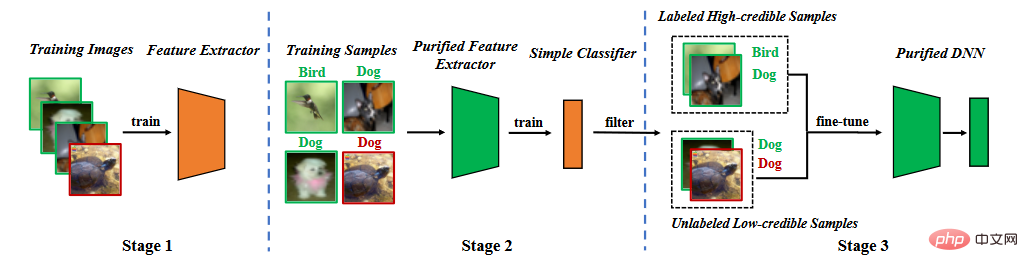 Methodenflussdiagramm
Methodenflussdiagramm
4.1 Lernmerkmalsextraktor
Wir verwenden den Trainingsdatensatz, um das Modell zu lernen. Die Parameter des Modells bestehen aus zwei Teilen, einem sind die Parameter des Backbone-Modells und der andere sind die Parameter der vollständig verbundenen Schicht. Wir nutzen selbstüberwachtes Lernen, um die Parameter des Backbone-Modells zu optimieren.
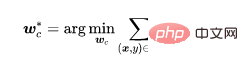
Wo ist der selbstüberwachte Verlust (zum Beispiel NT-Xent in SimCLR (Chen et al., 2020))? Backdoor-Funktionen.
4.2 Label-Noise-Lernen zum Filtern von Proben
Sobald der Feature-Extraktor trainiert ist, legen wir die Parameter des Feature-Extraktors fest und verwenden den Trainingsdatensatz, um die Parameter der vollständig verbundenen Schicht weiter zu lernen,
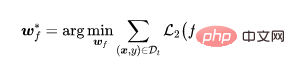
Wo ist der überwachte Lernverlust (z. B. Kreuzentropieverlust)?
Obwohl dieser Segmentierungsprozess es dem Modell erschwert, Hintertüren zu lernen, gibt es zwei Probleme. Erstens kommt es im Vergleich zu Methoden, die durch überwachtes Lernen trainiert werden, zu einem gewissen Rückgang der Genauigkeit der Vorhersage sauberer Proben, da der erlernte Merkmalsextraktor in der zweiten Stufe eingefroren wird. Zweitens dienen bei Angriffen mit vergifteten Etiketten vergiftete Proben als „Ausreißer“, was die zweite Lernstufe weiter behindert. Diese beiden Probleme weisen darauf hin, dass wir vergiftete Proben entfernen und das gesamte Modell neu trainieren oder optimieren müssen.
Wir müssen feststellen, ob die Probe eine Hintertür hat. Wir glauben, dass es für das Modell schwierig ist, aus Backdoor-Proben zu lernen, daher verwenden wir Vertrauen als Unterscheidungsindikator. Proben mit hohem Vertrauen sind saubere Proben, während Proben mit niedrigem Vertrauen vergiftete Proben sind. Durch Experimente wurde festgestellt, dass das mit symmetrischem Kreuzentropieverlust trainierte Modell eine große Verlustlücke zwischen den beiden Proben aufweist, sodass der Grad der Diskriminierung hoch ist, wie in der folgenden Abbildung dargestellt.
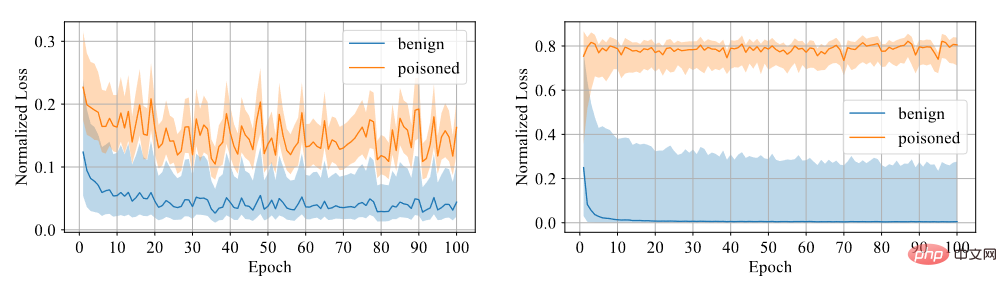
Vergleich zwischen symmetrischem Kreuzentropieverlust und Kreuzentropieverlust
Daher haben wir den Feature-Extraktor korrigiert, um die vollständig verbundene Schicht mithilfe des symmetrischen Kreuzentropieverlusts zu trainieren, und den Datensatz so gefiltert, dass er hoch ist nach der Größe des Konfidenzniveaus. Konfidenzdaten und Daten mit niedrigem Konfidenzniveau.
4.3 Halbüberwachte Feinabstimmung
Zuerst entfernen wir Etiketten von Daten mit geringem Vertrauen. Wir verwenden halbüberwachtes Lernen, um das gesamte Modell zu verfeinern.

Wo ist der halbüberwachte Verlust (z. B. die Verlustfunktion in MixMatch (Berthelot et al, 2019)).
Halbüberwachte Feinabstimmung kann nicht nur verhindern, dass das Modell Backdoor-Trigger lernt, sondern auch dafür sorgen, dass das Modell bei sauberen Datensätzen gut funktioniert.
5 (eine Teilmenge). Der Artikel verwendet das ResNet18-Modell (He et al., 2016). Der Artikel untersucht alle Verteidigungsmethoden zur Abwehr von vier typischen Angriffen, nämlich Badnets (Gu et al., 2019), Backdoor-Angriffe mit gemischten Strategien (Chen et al.). . al, 2017), WaNet (Nguyen & Tran, 2021) und Clean-Label-konsistente Angriffe mit gegnerischen Störungen (Turner et al, 2019).
Beispielbild für einen Backdoor-Angriff
5.2 Experimentelle Ergebnisse
 Die Beurteilungskriterien des Experiments sind die Beurteilungsgenauigkeit von BA als saubere Probe und die Beurteilungsgenauigkeit von ASR als vergifteter Probe .
Die Beurteilungskriterien des Experiments sind die Beurteilungsgenauigkeit von BA als saubere Probe und die Beurteilungsgenauigkeit von ASR als vergifteter Probe .
Ergebnisse des Backdoor-Verteidigungsvergleichs
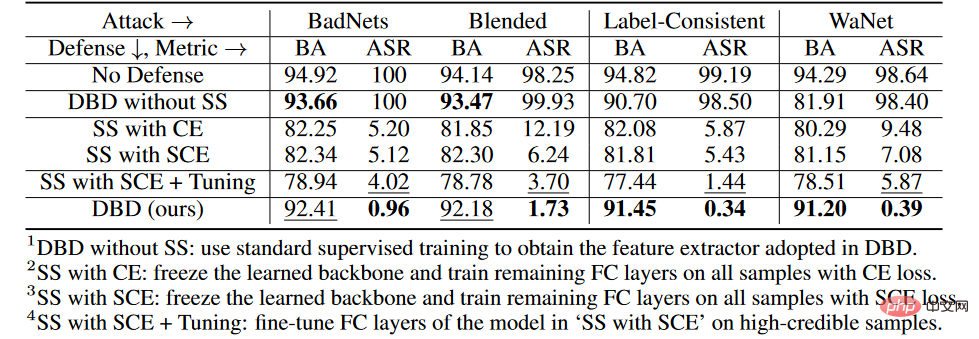
Wie in der Tabelle oben gezeigt, ist DBD bei der Abwehr aller Angriffe deutlich besser als Verteidigungen mit den gleichen Anforderungen (d. h. DPSGD und ShrinkPad). In allen Fällen hat DBD mehr als 20 % BA und 5 % niedrigere ASR als DPSGD. Der ASR des DBD-Modells beträgt in allen Fällen weniger als 2 % (in den meisten Fällen weniger als 0,5 %), was bestätigt, dass DBD die Erstellung versteckter Hintertüren erfolgreich verhindern kann. DBD wird mit zwei anderen Methoden verglichen, nämlich NC und NAD, die beide erfordern, dass der Verteidiger über einen sauberen lokalen Datensatz verfügt.
Wie in der Tabelle oben gezeigt, übertreffen NC und NAD DPSGD und ShrinkPad, weil sie zusätzliche Informationen aus lokalen sauberen Datensätzen nutzen. Obwohl NAD und NC zusätzliche Informationen verwenden, ist DBD insbesondere besser als diese. Insbesondere im ImageNet-Datensatz hat NC nur begrenzte Auswirkungen auf die Reduzierung der ASR. Im Vergleich dazu erreicht DBD den kleinsten ASR, während DBDs BA in fast allen Fällen am höchsten oder zweithöchsten ist. Darüber hinaus sank der BA im Vergleich zum Modell ohne jegliches Verteidigungstraining bei der Abwehr von Poisoning-Tag-Angriffen um weniger als 2 %. Bei relativ größeren Datensätzen ist DBD sogar noch besser, da alle Basismethoden weniger effektiv sind. Diese Ergebnisse bestätigen die Wirksamkeit von DBD.
5.3 Ablationsexperimente
ablierungsexperimente in jeder Stufe
on im CIFAR-10-Datensatz verglichen wir die vorgeschlagene DBD und seine vier Varianten, einschließlich
1 , ersetzt das durch selbstüberwachtes Lernen erzeugte Rückgrat durch das auf überwachte Weise trainierte Rückgrat und behält andere Teile unverändert
2 mit SS, friert das durch selbstüberwachtes Lernen erlernte Rückgrat ein und Kreuzentropieverlust Die verbleibenden vollständig verbundenen Schichten wurden auf allen Trainingsmustern trainiert
3.SS mit SCE, ähnlich der zweiten Variante, jedoch unter Verwendung eines symmetrischen Kreuzentropieverlusts trainiert.
4.SS mit SCE + Tuning, weitere Feinabstimmung der vollständig verbundenen Schicht auf Proben mit hoher Zuverlässigkeit, gefiltert durch die dritte Variante.
Wie in der Tabelle oben gezeigt, ist die Entkopplung des ursprünglichen End-to-End-überwachten Trainingsprozesses wirksam, um die Entstehung versteckter Hintertüren zu verhindern. Darüber hinaus werden die zweite und dritte DBD-Variante verglichen, um die Wirksamkeit des SCE-Verlusts bei der Abwehr von Poison-Tag-Backdoor-Angriffen zu überprüfen. Darüber hinaus sind ASR und BA der vierten DBD-Mutation niedriger als die der dritten DBD-Mutation. Dieses Phänomen ist auf die Entfernung von Stichproben mit geringer Konfidenz zurückzuführen. Dies legt nahe, dass es für die Verteidigung wichtig ist, nützliche Informationen aus Stichproben mit geringem Vertrauen zu nutzen und gleichzeitig deren Nebenwirkungen zu reduzieren.
5.4 Widerstand gegen potenzielle adaptive Angriffe
Wenn Angreifer die Existenz von DBD kennen, können sie adaptive Angriffe entwerfen. Wenn der Angreifer die vom Verteidiger verwendete Modellstruktur kennt, kann er einen adaptiven Angriff entwerfen, indem er das Auslösemuster so optimiert, dass die vergiftete Probe nach dem selbstüberwachten Lernen in einem neuen Cluster verbleibt, wie unten gezeigt:
Angriffseinstellungen
Lassen Sie bei einem Klassifizierungsproblem die sauberen Proben darstellen, die vergiftet werden müssen, stellen Sie die Proben mit dem Originaletikett dar und seien Sie ein geschultes Rückgrat. Angesichts des vom Angreifer vorgegebenen vergifteten Bildgenerators zielt der adaptive Angriff darauf ab, das Auslösemuster zu optimieren, indem der Abstand zwischen vergifteten Bildern minimiert und gleichzeitig der Abstand zwischen der Mitte des vergifteten Bildes und der Mitte der Gruppe harmloser Bilder mit unterschiedlichen Etikettenabständen maximiert wird. das heißt.
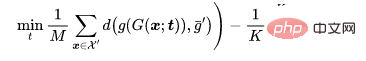
wobei 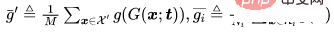 eine Entfernungsbestimmung ist.
eine Entfernungsbestimmung ist.
Experimentelle Ergebnisse
Der BA des adaptiven Angriffs ohne Verteidigung beträgt 94,96 % und der ASR beträgt 99,70 %. Die Verteidigungsergebnisse von DBD lagen jedoch bei BA93,21 % und ASR1,02 %. Mit anderen Worten: DBD ist gegen solche adaptiven Angriffe resistent.
6 Zusammenfassung
Der Mechanismus des auf Poisoning basierenden Backdoor-Angriffs besteht darin, während des Angriffs eine Beziehung zwischen dem Auslösermuster und der Zielbezeichnung herzustellen Ausbildungsprozess mögliche Zusammenhänge. Dieser Artikel zeigt, dass dieser Zusammenhang in erster Linie auf das durchgängig überwachte Trainingsparadigmenlernen zurückzuführen ist. Basierend auf diesem Verständnis schlägt dieser Artikel eine auf Entkopplung basierende Backdoor-Verteidigungsmethode vor. Eine große Anzahl von Experimenten hat bestätigt, dass die DBD-Verteidigung Backdoor-Bedrohungen reduzieren und gleichzeitig eine hohe Genauigkeit bei der Vorhersage harmloser Proben gewährleisten kann.
Das obige ist der detaillierte Inhalt vonBackdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Das Modell wird sich nach der Fusion weiterentwickeln und SOTA direkt gewinnen! Die neuen unternehmerischen Errungenschaften des Transformer-Autors sind beliebt
Mar 26, 2024 am 11:30 AM
Das Modell wird sich nach der Fusion weiterentwickeln und SOTA direkt gewinnen! Die neuen unternehmerischen Errungenschaften des Transformer-Autors sind beliebt
Mar 26, 2024 am 11:30 AM
Nutzen Sie die vorgefertigten Modelle auf Huggingface zum „Sparen“ – können Sie diese direkt kombinieren, um neue leistungsstarke Modelle zu erstellen? ! Die große japanische Modellfirma sakana.ai war sehr kreativ (es war das Unternehmen, das von einem der „8 Transformers“ gegründet wurde) und hat sich eine so clevere Möglichkeit ausgedacht, Modelle weiterzuentwickeln und zusammenzuführen. Die Methode generiert nicht nur automatisch neue Basismodelle, auch ihre Leistung ist alles andere als schlecht: Sie erzielte hochmoderne Ergebnisse bei relevanten Benchmarks unter Verwendung eines großen Modells japanischer Mathematik mit 7 Milliarden Parametern und übertraf damit das 70 Milliarden Parameter umfassende Llama - 2 und andere Vorgängermodelle. Am wichtigsten ist, dass die Ableitung eines solchen Modells kein Gradiententraining erfordert und daher deutlich weniger Rechenressourcen erfordert. Der NVIDIA-Wissenschaftler JimFan lobte es, nachdem er es gelesen hatte
