
 Technologie-Peripheriegeräte
KI
Multimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews
Technologie-Peripheriegeräte
KI
Multimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews
Multimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews

Multimodales Lernen zielt darauf ab, Informationen aus mehreren Modalitäten zu verstehen und zu analysieren. In den letzten Jahren wurden bei den Überwachungsmechanismen erhebliche Fortschritte erzielt.
Allerdings behindert die starke Abhängigkeit von Daten in Verbindung mit kostspieligen manuellen Anmerkungen die Modellskalierung. Gleichzeitig ist selbstüberwachtes Lernen angesichts der Verfügbarkeit umfangreicher, unbeschrifteter Daten in der realen Welt zu einer attraktiven Strategie geworden, um den Etikettierungsengpass zu lindern.
Basierend auf diesen beiden Richtungen bietet selbstüberwachtes multimodales Lernen (SSML) eine Methode, um die Überwachung anhand ursprünglicher multimodaler Daten zu nutzen.

Papieradresse: https://arxiv.org/abs/2304.01008
Projektadresse: https://github. com/ys-zong/awesome-self-supervised-multimodal-learning
In dieser Rezension bieten wir einen umfassenden Überblick über den Stand der Technik in SSML, den wir entlang dreier orthogonaler Achsen klassifizieren: Zielfunktion, Datenausrichtung und Modellarchitektur. Diese Achsen entsprechen den inhärenten Merkmalen selbstüberwachter Lernmethoden und multimodaler Daten.
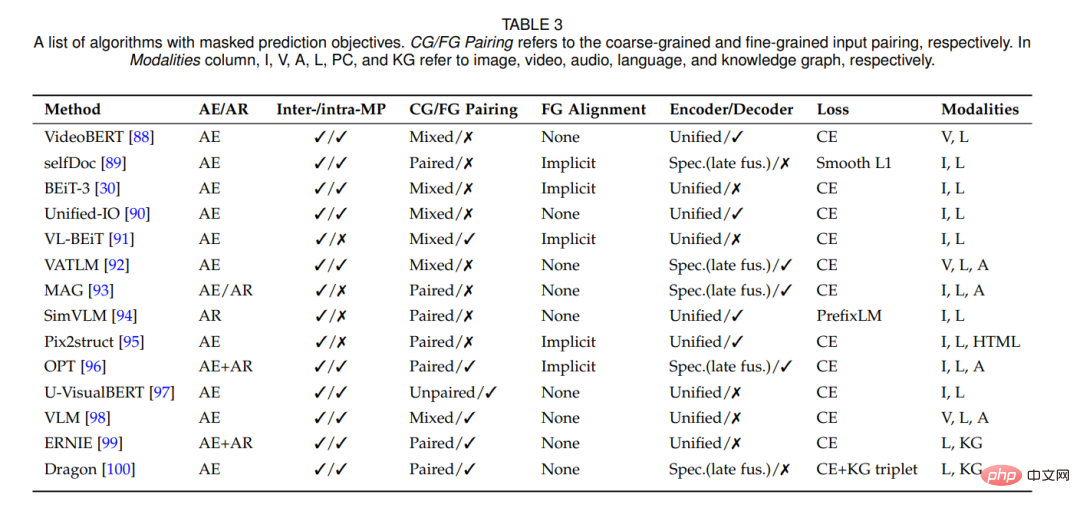
Konkret unterteilen wir die Trainingsziele in die Kategorien Instanzunterscheidung, Clustering und Maskenvorhersage. Wir diskutieren auch multimodale Eingabedatenpaarungs- und Ausrichtungsstrategien während des Trainings. Abschließend wird die Modellarchitektur überprüft, einschließlich des Designs von Encodern, Fusionsmodulen und Decodern, die wichtige Komponenten von SSML-Methoden sind.
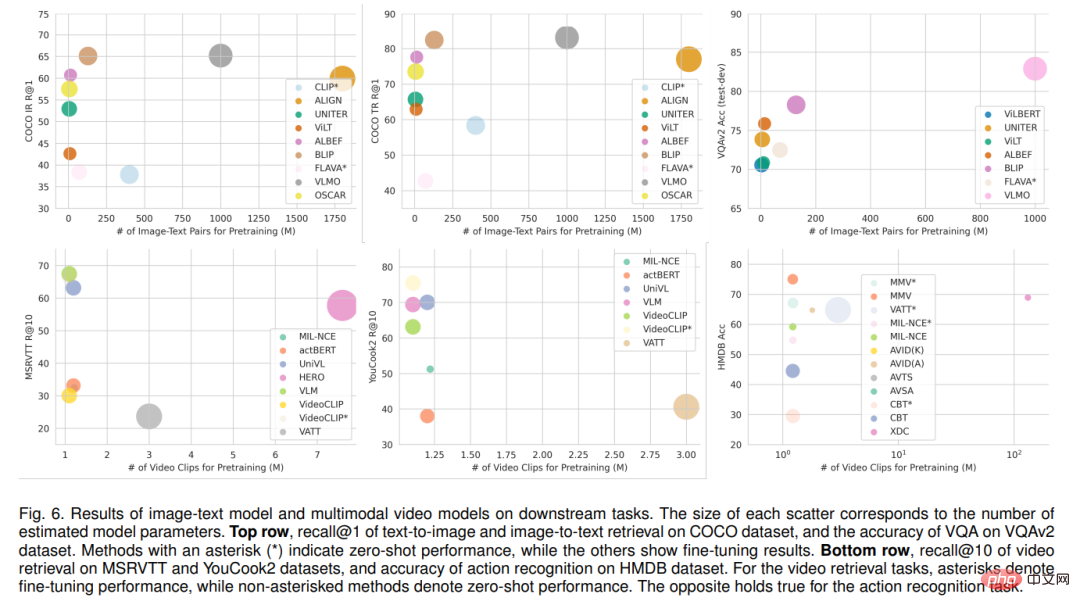
Überprüft nachgelagerte multimodale Anwendungsaufgaben, berichtet über die spezifische Leistung hochmoderner Bild-Text-Modelle und multimodaler Videomodelle und überprüft auch praktische Anwendungen von SSML-Algorithmen in verschiedenen Bereichen, beispielsweise im Gesundheitswesen , Fernerkundung und maschinelle Übersetzung. Abschließend werden Herausforderungen und zukünftige Richtungen für SSML diskutiert.
1. Einführung
Der Mensch nimmt die Welt mit verschiedenen Sinnen wahr, darunter Sehen, Hören, Fühlen und Riechen. Wir gewinnen ein umfassendes Verständnis unserer Umgebung, indem wir ergänzende Informationen aus jeder Modalität nutzen. Die KI-Forschung konzentriert sich auf die Entwicklung intelligenter Agenten, die menschliches Verhalten nachahmen und die Welt auf ähnliche Weise verstehen. Zu diesem Zweck zielt das Gebiet des multimodalen maschinellen Lernens [1], [2] darauf ab, Modelle zu entwickeln, die in der Lage sind, Daten aus mehreren verschiedenen Modalitäten zu verarbeiten und zu integrieren. In den letzten Jahren hat das multimodale Lernen erhebliche Fortschritte gemacht, die zu einer Reihe von Anwendungen im visuellen und sprachlichen Lernen [3], im Videoverständnis [4], [5], in der Biomedizin [6], im autonomen Fahren [7] und in anderen Bereichen geführt haben. Noch grundlegender ist, dass multimodales Lernen seit langem bestehende Grundprobleme der künstlichen Intelligenz vorantreibt [8] und uns einer allgemeineren künstlichen Intelligenz näher bringt.
Allerdings erfordern multimodale Algorithmen für ein effektives Training oft immer noch teure manuelle Annotationen, was ihre Erweiterung behindert. Vor kurzem hat selbstüberwachtes Lernen (SSL) [9], [10] begonnen, dieses Problem zu lindern, indem Supervision aus leicht verfügbaren annotierten Daten generiert wird. Die Selbstüberwachung beim monomodalen Lernen ist ziemlich genau definiert und hängt nur von den Trainingszielen ab und davon, ob menschliche Anmerkungen zur Überwachung verwendet werden. Im Kontext des multimodalen Lernens ist seine Definition jedoch differenzierter. Beim multimodalen Lernen fungiert eine Modalität häufig als Überwachungssignal für eine andere Modalität. Im Hinblick auf das Ziel der Aufwärtsskalierung durch Beseitigung des Engpasses bei der manuellen Annotation besteht eine zentrale Frage bei der Definition des Umfangs der Selbstüberwachung darin, ob modalübergreifende Paarungen frei erfasst werden.
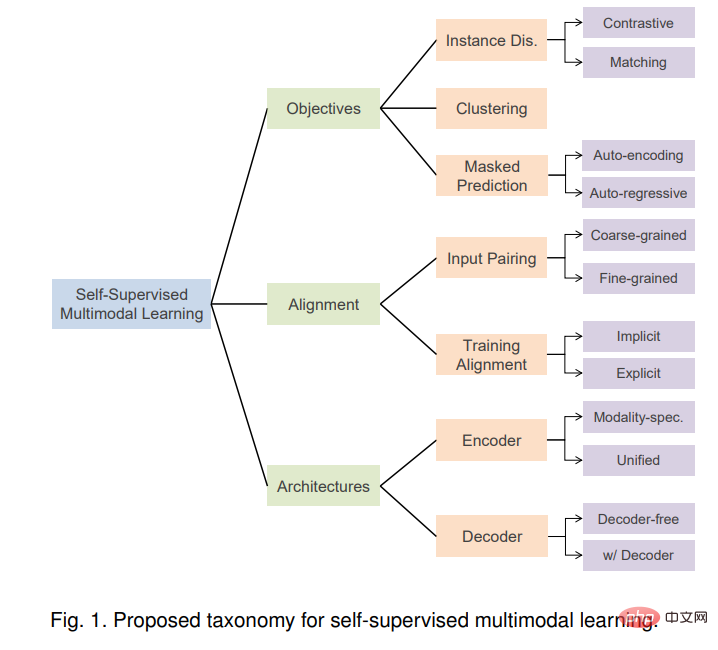
Selbstüberwachtes multimodales Lernen (SSML) verbessert die Fähigkeiten multimodaler Modelle erheblich, indem frei verfügbare multimodale Daten und selbstüberwachte Ziele genutzt werden. In dieser Rezension besprechen wir SSML-Algorithmen und ihre Anwendungen. Wir zerlegen die verschiedenen Methoden entlang dreier orthogonaler Achsen: Zielfunktion, Datenausrichtung und Modellarchitektur. Diese Achsen entsprechen den Merkmalen selbstüberwachter Lernalgorithmen und den spezifischen Überlegungen, die für multimodale Daten erforderlich sind. Abbildung 1 gibt einen Überblick über die vorgeschlagene Taxonomie. Basierend auf der Voraufgabe unterteilen wir die Trainingsziele in die Kategorien Instanzunterscheidung, Clustering und Maskenvorhersage. Es werden auch hybride Ansätze diskutiert, die zwei oder mehr dieser Ansätze kombinieren.
Einzigartig bei der multimodalen Selbstüberwachung ist das Problem der multimodalen Datenpaarung. Paarungen oder allgemeiner Ausrichtungen zwischen Modalitäten können von SSML-Algorithmen als Eingabe (z. B. wenn eine Modalität verwendet wird, um eine andere zu überwachen), aber auch als Ausgabe (z. B. Lernen aus ungepaarten Daten und Induzieren von Paarungen als) genutzt werden ein Nebenprodukt). Wir diskutieren die verschiedenen Rollen der Ausrichtung auf grobkörniger Ebene, von denen oft angenommen wird, dass sie in der multimodalen Selbstüberwachung frei verfügbar sind (z. B. im Internet gecrawlte Bilder und Bildunterschriften [11]), manchmal explizit oder implizit induzierte feinkörnige Ausrichtung (z. B. , Korrespondenz zwischen Titelwörtern und Bildfeldern [12]). Darüber hinaus untersuchen wir die Schnittstelle zwischen Zielfunktionen und Datenausrichtungsannahmen.
analysiert auch das Design zeitgenössischer SSML-Modellarchitektur. Konkret betrachten wir den Designraum von Encoder- und Fusionsmodulen und vergleichen modusspezifische Encoder (ohne Fusion oder mit später Fusion) und einheitliche Encoder mit früher Fusion. Wir untersuchen auch Architekturen mit spezifischen Decoder-Designs und diskutieren die Auswirkungen dieser Design-Entscheidungen.
Schließlich die Anwendungen dieser Algorithmen in mehreren realen Bereichen, einschließlich Gesundheitswesen, Fernerkundung, maschinelle Übersetzung usw., sowie die technischen Herausforderungen und sozialen Auswirkungen davon SSML werden diskutiert. Es wird eine ausführliche Diskussion geführt und mögliche zukünftige Forschungsrichtungen aufgezeigt. Wir fassen die jüngsten Fortschritte bei Methoden, Datensätzen und Implementierungen zusammen, um Forschern und Praktikern auf diesem Gebiet einen Ausgangspunkt zu bieten.
Vorhandene Übersichtsarbeiten konzentrieren sich entweder nur auf überwachtes multimodales Lernen [1], [2], [13], [14] oder auf einzelnes -modales selbstüberwachtes Lernen [9], [10], [15] oder ein bestimmter Teilbereich von SSML, wie beispielsweise das visuelle Sprach-Vortraining [16]. Die relevanteste Rezension ist [17], aber sie konzentriert sich mehr auf zeitliche Daten und ignoriert die wichtigsten Überlegungen der multimodalen Selbstüberwachung von Ausrichtung und Architektur. Im Gegensatz dazu bieten wir einen umfassenden und aktuellen Überblick über SSML-Algorithmen und eine neue Taxonomie, die Algorithmen, Daten und Architektur abdeckt.
2. Hintergrundwissen
Im multimodalen Lernen Selbst -supervised
Wir beschreiben zunächst den in dieser Umfrage berücksichtigten Umfang von SSML, da dieser Begriff in der bisherigen Literatur uneinheitlich verwendet wurde. Die Definition von Selbstüberwachung in einem einmodalen Kontext ist einfacher, wenn man sich auf die etikettenfreie Natur verschiedener Vorwandaufgaben beruft, z. B. die bekannte Instanzunterscheidung [20] oder das maskierte Vorhersageziel [21], die Selbstüberwachung implementieren. Im Gegensatz dazu ist die Situation beim multimodalen Lernen komplizierter, da die Rollen von Modalität und Bezeichnung verschwimmen. Beispielsweise wird Text bei der überwachten Bildunterschrift [22] normalerweise als Beschriftung behandelt, beim selbstüberwachten multimodalen Lernen visueller und sprachlicher Darstellungen [11] wird Text jedoch als Eingabemodalität behandelt.
Im multimodalen Kontext wird der Begriff Selbstüberwachung verwendet, um sich auf mindestens vier Situationen zu beziehen: (1) aus automatisch gepaarten multimodalen Daten Etikettenfreies Lernen – z.B. Filme mit Video- und Audiospuren [23] oder Bild- und Tiefendaten von RGBD-Kameras [24]. (2) Lernen aus multimodalen Daten, bei denen eine Modalität manuell annotiert wurde oder zwei Modalitäten manuell gepaart wurden, diese Annotation jedoch für einen anderen Zweck erstellt wurde und daher für das SSML-Vortraining als kostenlos betrachtet werden kann. Beispielsweise sind passende Bild-Untertitel-Paare aus dem Internet, wie sie im bahnbrechenden CLIP [11] verwendet werden, tatsächlich ein Beispiel für überwachtes metrisches Lernen [25], [26], bei dem die Paarung überwacht wird. Da jedoch sowohl Muster als auch Paarungen im großen Maßstab frei verfügbar sind, wird es oft als selbstüberwacht bezeichnet. Diese nicht kuratierten, zufällig erstellten Daten sind häufig von geringerer Qualität und verrauschter als speziell kuratierte Datensätze wie COCO [22] und Visual Genome [27]. (3) Lernen Sie aus hochwertigen, zweckannotierten multimodalen Daten (z. B. manuell beschriftete Bilder in COCO [22]), jedoch mit einem selbstüberwachten Stilziel wie Pixel-BERT [28]. (4) Schließlich gibt es „selbstüberwachte“ Methoden, die eine Mischung aus freien und manuell gekennzeichneten multimodalen Daten verwenden [29], [30]. Für den Zweck dieser Untersuchung folgen wir der Idee der Selbstüberwachung und streben eine Skalierung an, indem wir den Engpass der manuellen Annotation überwinden. Daher schließen wir die ersten beiden Kategorien und die vierte Kategorie von Methoden ein, um auf frei verfügbaren Daten trainieren zu können. Wir schließen Methoden aus, die nur für manuell kuratierte Datensätze gezeigt werden, da sie typische „Selbstüberwachungs“-Ziele auf kuratierte Datensätze anwenden (z. B. maskierte Vorhersage).
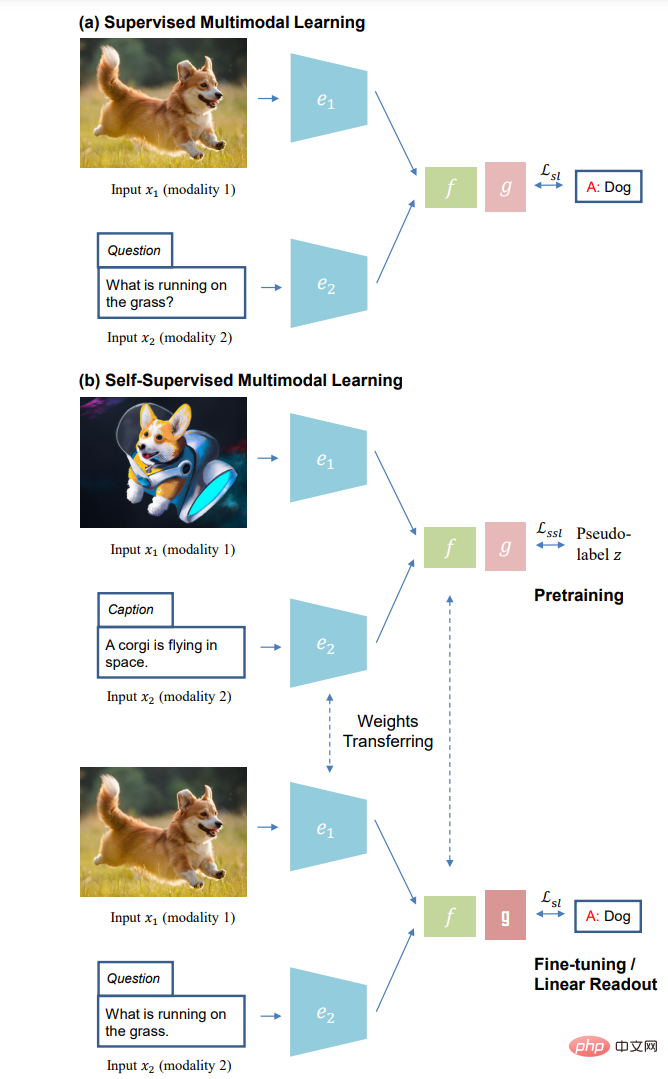
(a) Überwachtes multimodales Lernen und (b) selbstüberwachtes Lernparadigma des multimodalen Lernens: selbstüberwachtes Vortraining ohne manuelle Annotation (oben); unten) ).
3. Zielfunktion
In diesem Abschnitt stellen wir die Zielfunktion vor, die zum Trainieren von drei Kategorien selbstüberwachter multimodaler Algorithmen verwendet wird: Instanzunterscheidung, Clustering und Maskenvorhersage. Schließlich haben wir auch Hybridziele diskutiert.
3.1 Instanzunterscheidung
Beim Single-Mode-Lernen behandelt die Instanzunterscheidung (ID) jede Instanz in den Originaldaten als separate Klasse und trainiert das Modell, um verschiedene Instanzen zu unterscheiden. Im Kontext des multimodalen Lernens zielt die Instanzunterscheidung normalerweise darauf ab, festzustellen, ob Stichproben aus zwei Eingabemodalitäten von derselben Instanz stammen, also gepaart sind. Auf diese Weise wird versucht, den Darstellungsraum von Musterpaaren auszurichten und gleichzeitig den Darstellungsraum verschiedener Instanzpaare weiter auseinanderzuschieben. Es gibt zwei Arten von Instanzerkennungszielen: kontrastive Vorhersage und Matching-Vorhersage, je nachdem, wie die Eingabe abgetastet wird.
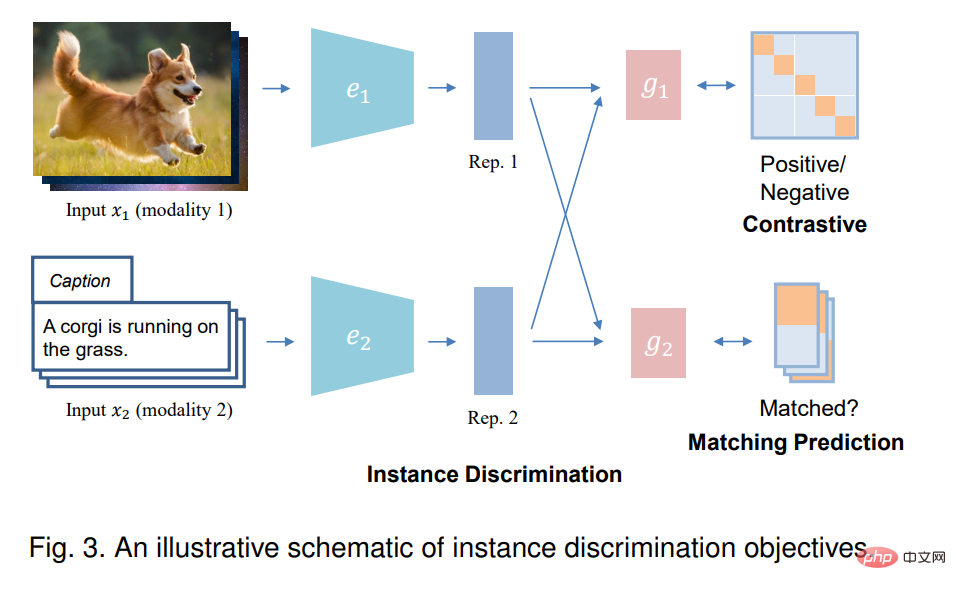
3.2 Clustering
Clustering-Methoden gehen davon aus, dass die Anwendung von trainiertem End-to-End-Clustering zu einer Gruppierung der Daten basierend auf semantisch hervorstechenden Merkmalen führt. In der Praxis sagen diese Methoden iterativ Clusterzuordnungen codierter Darstellungen voraus und verwenden diese Vorhersagen (auch Pseudo-Labels genannt) als Überwachungssignale zur Aktualisierung von Merkmalsdarstellungen. Multimodales Clustering bietet die Möglichkeit, multimodale Darstellungen zu erlernen und auch das traditionelle Clustering zu verbessern, indem andere Modalitäten mithilfe von Pseudobezeichnungen für jede Modalität überwacht werden.
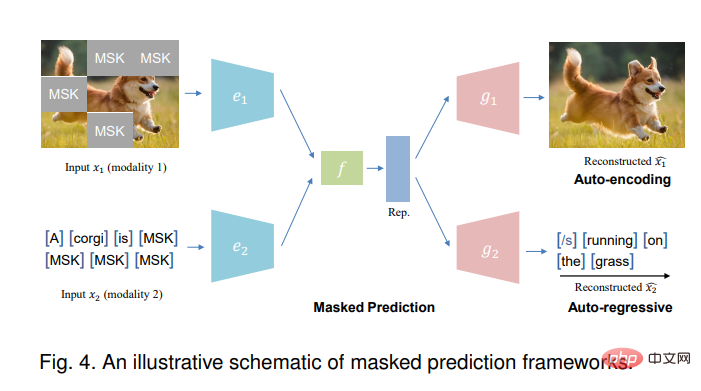
3.3 Maskenvorhersage
Die Maskenvorhersageaufgabe kann mithilfe automatischer Codierung (ähnlich BERT [101]) oder automatischer Regressionsmethoden (ähnlich GPT [102]) durchgeführt werden.
Das obige ist der detaillierte Inhalt vonMultimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Mar 18, 2024 am 09:20 AM
Mar 18, 2024 am 09:20 AM
Heute möchte ich eine aktuelle Forschungsarbeit der University of Connecticut vorstellen, die eine Methode zum Abgleichen von Zeitreihendaten mit großen NLP-Modellen (Natural Language Processing) im latenten Raum vorschlägt, um die Leistung von Zeitreihenprognosen zu verbessern. Der Schlüssel zu dieser Methode besteht darin, latente räumliche Hinweise (Eingabeaufforderungen) zu verwenden, um die Genauigkeit von Zeitreihenvorhersagen zu verbessern. Titel des Papiers: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Download-Adresse: https://arxiv.org/pdf/2403.05798v1.pdf 1. Hintergrundmodell für große Probleme
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
