
 Technologie-Peripheriegeräte
KI
Der weltweite Bestand an qualitativ hochwertigen Sprachdaten ist knapp und kann nicht ignoriert werden.
Technologie-Peripheriegeräte
KI
Der weltweite Bestand an qualitativ hochwertigen Sprachdaten ist knapp und kann nicht ignoriert werden.
Der weltweite Bestand an qualitativ hochwertigen Sprachdaten ist knapp und kann nicht ignoriert werden.

Als eines der drei Elemente der künstlichen Intelligenz spielen Daten eine wichtige Rolle.
Aber haben Sie schon einmal darüber nachgedacht: Was wäre, wenn eines Tages alle Daten der Welt zur Neige gehen würden?
Eigentlich hat die Person, die diese Frage gestellt hat, definitiv kein psychisches Problem, denn dieser Tag kommt vielleicht wirklich bald! ! !
Kürzlich veröffentlichten der Forscher Pablo Villalobos und andere einen Artikel mit dem Titel „Werden uns die Daten ausgehen?“ Der Artikel „Analysis of the Limitations of Dataset Scaling in Machine Learning“ wurde auf arXiv veröffentlicht.
Basierend auf früheren Analysen der Datensatzgrößentrends sagten sie das Wachstum der Datensatzgrößen in den Bereichen Sprache und Sehen voraus und schätzten den Entwicklungstrend des Gesamtbestands verfügbarer unbeschrifteter Daten in den nächsten Jahrzehnten.
Ihre Forschung zeigt, dass hochwertige Sprachdaten bereits im Jahr 2026 erschöpft sein werden! Dadurch wird sich auch die Geschwindigkeit der maschinellen Lernentwicklung verlangsamen. Es ist wirklich nicht optimistisch.
Zwei Methoden werden zusammen verwendet, aber die Ergebnisse sind nicht optimistisch
Das Forschungsteam dieses Papiers besteht aus 11 Forschern und 3 Beratern mit Mitgliedern aus der ganzen Welt, die sich dafür einsetzen, die Lücke zwischen der Entwicklung der KI-Technologie und zu schließen KI-Strategie und Beratung wichtiger Entscheidungsträger im Bereich KI-Sicherheit.

Chinchilla ist ein neues Predictive-Computing-Optimierungsmodell, das von Forschern bei DeepMind vorgeschlagen wurde.
Tatsächlich wies ein Forscher bei früheren Experimenten mit Chinchilla einmal darauf hin, dass „Trainingsdaten bald zu einem Engpass bei der Erweiterung großer Sprachmodelle werden.“
Also analysierten sie das Wachstum der Datensatzgrößen für maschinelles Lernen für die Verarbeitung natürlicher Sprache und Computer Vision und verwendeten zwei Methoden zur Extrapolation: die Verwendung historischer Wachstumsraten und die Berechnung optimaler Schätzungen der Rechenbudgets für zukünftige Prognosen. Datensatzgröße.
Zuvor haben sie Daten zu Eingabetrends beim maschinellen Lernen, einschließlich einiger Trainingsdaten, gesammelt und auch das Wachstum der Datennutzung untersucht, indem sie den Gesamtbestand an unbeschrifteten Daten geschätzt haben, die in den nächsten Jahrzehnten im Internet verfügbar sind.
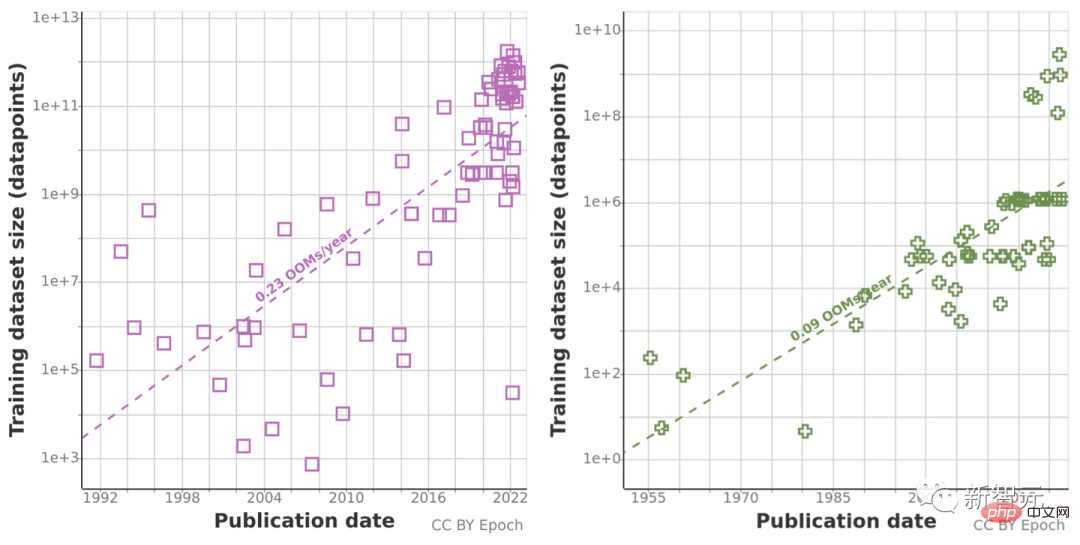
Da historische Vorhersagetrends aufgrund des abnormalen Wachstums des Rechenvolumens im letzten Jahrzehnt möglicherweise „irreführend“ sind, nutzte das Forschungsteam auch das Chinchilla-Skalierungsgesetz, um die Größe des Datensatzes in den nächsten Jahren abzuschätzen Verbessern Sie die Genauigkeit der Berechnungsergebnisse.
Letztendlich verwendeten die Forscher eine Reihe probabilistischer Modelle, um den Gesamtbestand an englischen Sprach- und Bilddaten in den nächsten Jahren abzuschätzen, und verglichen die Vorhersagen zur Trainingsdatensatzgröße und zum Gesamtdatenbestand. Die Ergebnisse sind in der Abbildung dargestellt unten.
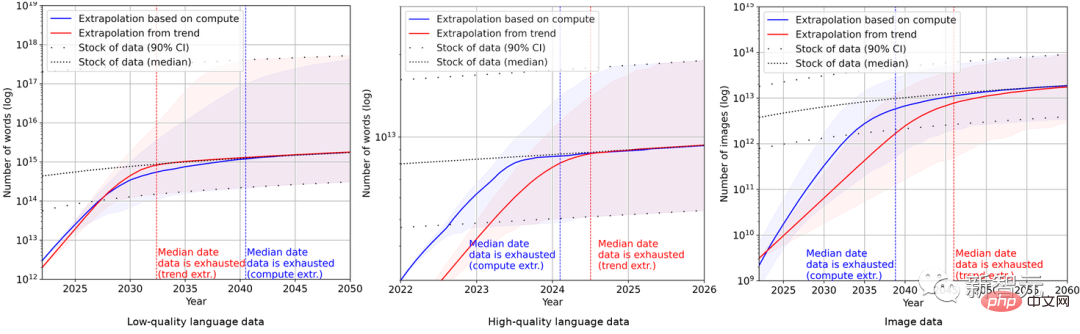
Dies zeigt, dass die Wachstumsrate des Datensatzes viel schneller sein wird als der Datenbestand.
Sollte sich der aktuelle Trend fortsetzen, wird es daher unumgänglich sein, dass der Datenbestand aufgebraucht wird. Die folgende Tabelle zeigt die mittlere Anzahl der Jahre bis zur Erschöpfung an jedem Schnittpunkt der Prognosekurve.
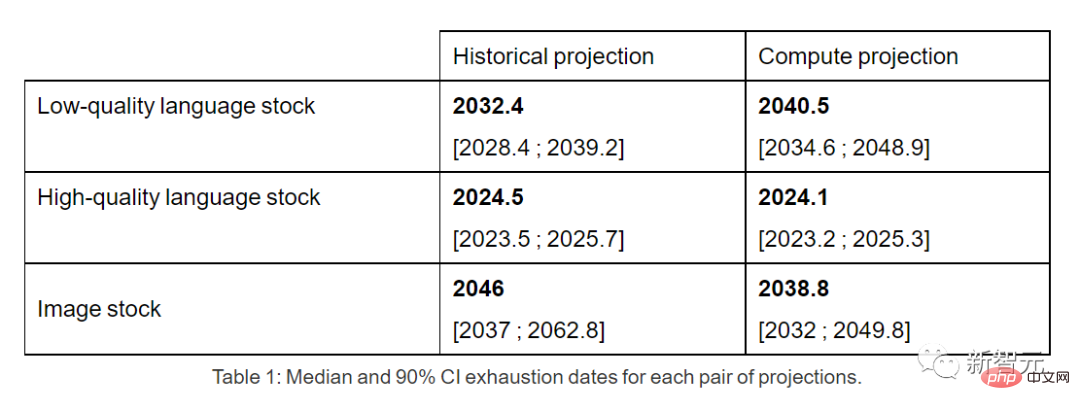
Hochwertige Sprachdatenbestände könnten frühestens 2026 erschöpft sein.
Im Gegensatz dazu schneiden minderwertige Sprachdaten und Bilddaten etwas besser ab: Erstere werden zwischen 2030 und 2050 aufgebraucht sein, letztere zwischen 2030 und 2060.
Am Ende des Papiers kam das Forschungsteam zu dem Schluss, dass sich der Wachstumstrend von Modellen für maschinelles Lernen, die derzeit auf den ständig wachsenden riesigen Datensätzen basieren, wahrscheinlich verlangsamen wird, wenn die Dateneffizienz nicht wesentlich verbessert wird oder neue Datenquellen verfügbar sind runter.
Netizen: Es ist unbegründet, sich Sorgen zu machen. Lassen Sie uns mehr über Efficient Zero herausfinden.
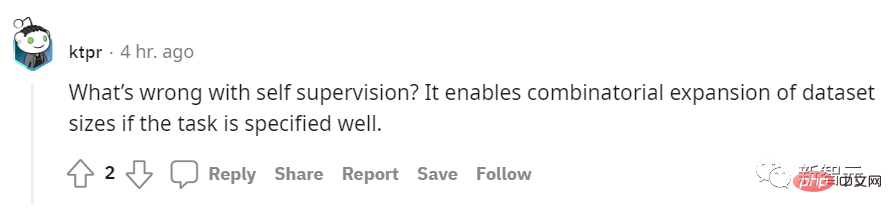
Auf Reddit sagte ein Internetnutzer namens ktpr:
„Was ist falsch an selbstüberwachtem Lernen? Wenn die Aufgabe gut spezifiziert ist, kann sie sogar kombiniert werden, um die Datensatzgröße zu erweitern.“
Ein Internetnutzer namens lostmsn war noch unhöflicher. Er sagte unverblümt:
 „Sie wissen nicht einmal etwas über Efficient Zero? Ich denke, der Autor ist ernsthaft am Puls der Zeit.“ Probe, entwickelt von Gao Yang von der Tsinghua-Universität Dr. vorgeschlagen.
„Sie wissen nicht einmal etwas über Efficient Zero? Ich denke, der Autor ist ernsthaft am Puls der Zeit.“ Probe, entwickelt von Gao Yang von der Tsinghua-Universität Dr. vorgeschlagen.
Bei begrenztem Datenvolumen löste Efficient Zero das Leistungsproblem des Reinforcement Learning bis zu einem gewissen Grad und wurde am Atari Game, einem universellen Testbenchmark für Algorithmen, verifiziert.
 Auf dem Blog des Autorenteams dieses Papiers gaben sogar sie selbst zu:
Auf dem Blog des Autorenteams dieses Papiers gaben sogar sie selbst zu:
„Alle unsere Schlussfolgerungen basieren auf unrealistischen Annahmen über die aktuelle Nutzung und Produktion von maschinellen Lerndaten. Der Trend.“ wird ohne wesentliche Verbesserungen der Dateneffizienz fortgesetzt. „
“Ein zuverlässigeres Modell sollte die Verbesserung der Dateneffizienz des maschinellen Lernens, die Verwendung synthetischer Daten und andere algorithmische und wirtschaftliche Faktoren berücksichtigen.“ In praktischer Hinsicht weist diese Analyse also erhebliche Einschränkungen auf dass sich der Ausbau maschineller Lernmodelle deutlich verlangsamen wird.“
Das obige ist der detaillierte Inhalt vonDer weltweite Bestand an qualitativ hochwertigen Sprachdaten ist knapp und kann nicht ignoriert werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wenn Sie Hadoop-Protokolle auf Debian verwalten, können Sie die folgenden Schritte und Best Practices befolgen: Protokollaggregation Aktivieren Sie die Protokollaggregation: Set Garn.log-Aggregation-Enable in true in der Datei marn-site.xml, um die Protokollaggregation zu aktivieren. Konfigurieren von Protokoll-Retentionsrichtlinien: Setzen Sie Garn.log-Aggregation.Retain-Sekunden, um die Retentionszeit des Protokolls zu definieren, z. B. 172800 Sekunden (2 Tage). Log Speicherpfad angeben: über Garn.n
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
