

Was ist die Implementierungsmethode des KMP-Algorithmus in Java?

Abbildung
Der kmp-Algorithmus weist eine gewisse Ähnlichkeit mit der zuvor erwähnten Idee des bm-Algorithmus auf. Wie bereits erwähnt, gibt es das Konzept eines guten Suffixes im bm-Algorithmus und es gibt ein Konzept eines guten Präfixes in kmp. Schauen wir uns zunächst das folgende Beispiel an.
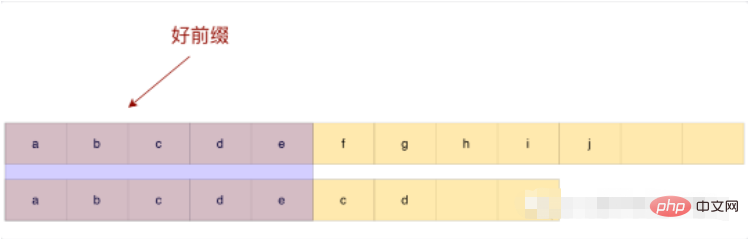
Beobachten Sie das obige Beispiel: Das bereits übereinstimmende abcde wird als gutes Präfix bezeichnet, a stimmt nicht mit dem folgenden bcde überein, sodass kein erneuter Vergleich erforderlich ist. Schieben Sie es einfach direkt nach e.
Was ist, wenn das gute Präfix übereinstimmende Zeichen enthält?
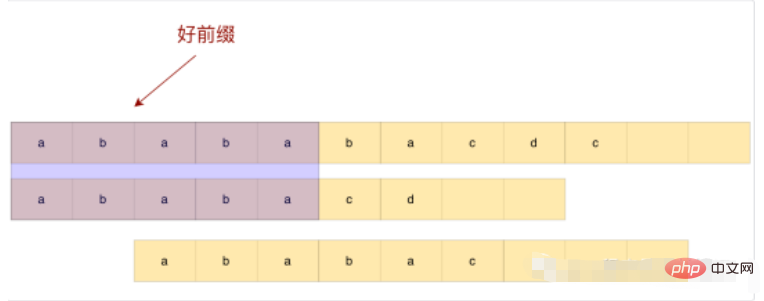
Beobachten Sie das obige Beispiel. Wenn wir zu diesem Zeitpunkt direkt nach dem guten Präfix schieben, schieben wir zu viel und verpassen den passenden Teilstring. Wie führen wir also ein vernünftiges Gleiten basierend auf guten Präfixen durch?
Tatsächlich wird überprüft, ob das Präfix und das Suffix des aktuellen guten Präfixes übereinstimmen, die längste passende Länge gefunden und direkt verschoben. Um die längste passende Länge mehr als einmal zu finden, können wir zuerst ein Array initialisieren und die längste passende Länge unter dem aktuellen guten Präfix speichern. Zu diesem Zeitpunkt wird unser nächstes Array ausgegeben.
Wir definieren ein nächstes Array, das die längste übereinstimmende Teilzeichenfolgenlänge des Präfixes und Suffixes des guten Präfixes unter dem aktuellen guten Präfix darstellt. Diese längste übereinstimmende Länge bedeutet, dass diese Teilzeichenfolge bereits zuvor abgeglichen wurde und nicht erneut abgeglichen werden muss . Der Abgleich beginnt direkt mit dem nächsten Zeichen der Teilzeichenfolge.

Müssen wir bei jeder Berechnung von next[i] jedes Zeichen abgleichen? Können wir aus next[i - 1] schließen, um unnötige Vergleiche zu vermeiden?
Mit dieser Idee werfen wir einen Blick auf die folgenden Schritte:
Angenommen, next[i - 1] = k - 1;
Wenn modelStr[k] = modelStr[i], dann next[i]=k

Wenn modelStr[k] != modelStr[i], können wir dann direkt next[i] = next[i - 1] bestimmen?

Anhand des obigen Beispiels können wir deutlich erkennen, dass next[i]!=next[i-1] dann, wenn modelStr[k]!=modelStr[i], bereits next[ 0],next kennt [1]…next[i-1], wie kann man next[i] herausschieben?
Angenommen, modelStr[x…i] ist die längste Suffix-Teilzeichenfolge, mit der das Präfix und das Suffix übereinstimmen können, dann ist die längste passende Präfix-Teilzeichenfolge modelStr[0…i-x]

Wenn wir die längste passende Zeichenfolge finden, ist sie die vorherige Die zweitlängste übereinstimmende Zeichenfolge (mit Ausnahme des aktuellen i), d ist modelStr[0…i-x-1], die Suffix-Teilzeichenfolge ist modelStr[x…i-1] und modelStr[i-x] == modelStr[i], diese Präfix-Suffix-Teilzeichenfolge ist die sekundäre Präfix-Teilzeichenfolge plus das aktuelle Zeichen ist die längste passende Präfix- und Suffix-Teilzeichenfolge.
Code-Implementierung
Zunächst das wichtigste nächste Array im kmp-Algorithmus. Dieses Array markiert die Anzahl der längsten Präfix- und Suffixzeichen, die im kmp-Algorithmus übereinstimmen ein gutes Präfix, das heißt: Durch Anpassen des Musterzeichenfolgenpräfixes können wir bestimmte Techniken verwenden, um mehr als ein Zeichen nach vorne zu schieben. Weitere Informationen finden Sie in der vorherigen Erklärung. Wir wissen nicht im Voraus, welche Präfixe gut sind, und der Abgleichvorgang erfolgt mehr als einmal. Daher rufen wir zu Beginn eine Initialisierungsmethode auf, um das nächste Array zu initialisieren.
1. Wenn das nächste Zeichen der längsten Präfix-Teilzeichenfolge des vorherigen Zeichens == das aktuelle Zeichen ist, kann die längste Präfix-Teilzeichenfolge des vorherigen Zeichens direkt zum aktuellen Zeichen hinzugefügt werden
2 Wenn es nicht gleich ist Sie müssen das vorherige Zeichen finden. Das nächste Zeichen der längsten vorhandenen Präfix-Teilzeichenfolge ist gleich der aktuellen Teilzeichenfolge und legt dann die längste Präfix-Suffix-Teilzeichenfolge der aktuellen Zeichen-Teilzeichenfolge fest
int[] next ;
/**
* 初始化next数组
* @param modelStr
*/
public void init(char[] modelStr) {
//首先计算next数组
//遍历modelStr,遍历到的字符与之前字符组成一个串
next = new int[modelStr.length];
int start = 0;
while (start < modelStr.length) {
next[start] = this.recursion(start, modelStr);
++ start;
}
}
/**
*
* @param i 当前遍历到的字符
* @return
*/
private int recursion(int i, char[] modelStr) {
//next记录的是个数,不是下标
if (0 == i) {
return 0;
}
int last = next[i -1];
//没有匹配的,直接判断第一个是否匹配
if (0 == last) {
if (modelStr[last] == modelStr[i]) {
return 1;
}
return 0;
}
//如果last不为0,有值,可以作为最长匹配的前缀
if (modelStr[last] == modelStr[i]) {
return next[i - 1] + 1;
}
//当next[i-1]对应的子串的下一个值与modelStr不匹配时,需要找到当前要找的最长匹配子串的次长子串
//依据就是次长子串对应的子串的下一个字符==modelStr[i];
int tempIndex = i;
while (tempIndex > 0) {
last = next[tempIndex - 1];
//找到第一个下一个字符是当前字符的匹配子串
if (modelStr[last] == modelStr[i]) {
return last + 1;
}
-- tempIndex;
}
return 0;
}Beginnen Sie dann mit der Verwendung des nächsten übereinstimmenden Arrays, beginnend mit Finden Sie das erste nicht übereinstimmende Zeichen. Beurteilen Sie zunächst, ob es sich um eine vollständige Übereinstimmung handelt, und geben Sie es direkt zurück. und dann passt es direkt zur Rückseite. Wenn ein gutes Präfix vorhanden ist, wird zu diesem Zeitpunkt das nächste Array verwendet. Durch das nächste Array wissen wir, wo der aktuelle Abgleich beginnen kann, und es besteht keine Notwendigkeit, die vorherigen abzugleichen.
public int kmp(char[] mainStr, char[] modelStr) {
//开始进行匹配
int i = 0, j = 0;
while (i + modelStr.length <= mainStr.length) {
while (j < modelStr.length) {
//找到第一个不匹配的位置
if (modelStr[j] != mainStr[i]) {
break;
}
++ i;
++ j;
}
if (j == modelStr.length) {
//证明完全匹配
return i - j;
}
//走到这里找到的是第一个不匹配的位置
if (j == 0) {
++ i;
continue;
}
//从好前缀后一个匹配
j = next[j - 1];
}
return -1;
}Das obige ist der detaillierte Inhalt vonWas ist die Implementierungsmethode des KMP-Algorithmus in Java?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
