
 Backend-Entwicklung
Python-Tutorial
Häufig verwendete Verlustfunktionen und Python-Implementierungsbeispiele
Backend-Entwicklung
Python-Tutorial
Häufig verwendete Verlustfunktionen und Python-Implementierungsbeispiele
Häufig verwendete Verlustfunktionen und Python-Implementierungsbeispiele

Was ist die Verlustfunktion?
Die Verlustfunktion ist ein Algorithmus, der den Grad der Übereinstimmung zwischen dem Modell und den Daten misst. Eine Verlustfunktion ist eine Möglichkeit, die Differenz zwischen tatsächlichen Messungen und vorhergesagten Werten zu messen. Je höher der Wert der Verlustfunktion, desto fehlerhafter ist die Vorhersage, und je niedriger der Wert der Verlustfunktion, desto näher liegt die Vorhersage am wahren Wert. Die Verlustfunktion wird für jede einzelne Beobachtung (Datenpunkt) berechnet. Die Funktion, die die Werte aller Verlustfunktionen mittelt, wird als Kostenfunktion bezeichnet. Ein einfacheres Verständnis besteht darin, dass die Verlustfunktion für eine einzelne Stichprobe gilt, während die Kostenfunktion für alle Stichproben gilt.
Verlustfunktionen und Metriken
Einige Verlustfunktionen können auch als Bewertungsmetriken verwendet werden. Aber Verlustfunktionen und Metriken haben unterschiedliche Zwecke. Während Metriken verwendet werden, um das endgültige Modell zu bewerten und die Leistung verschiedener Modelle zu vergleichen, wird die Verlustfunktion während der Modellerstellungsphase als Optimierer für das zu erstellende Modell verwendet. Die Verlustfunktion leitet das Modell an, wie der Fehler minimiert werden kann.
Das heißt, die Verlustfunktion weiß, wie das Modell trainiert wird, und der Messindex erklärt die Leistung des Modells
Warum die Verlustfunktion verwenden?#🎜🎜 ##🎜🎜 #Da die Verlustfunktion die Differenz zwischen dem vorhergesagten Wert und dem tatsächlichen Wert misst, können sie beim Training des Modells als Leitfaden für die Modellverbesserung (die übliche Gradientenabstiegsmethode) verwendet werden. Wenn sich beim Erstellen des Modells das Gewicht des Merkmals ändert und bessere oder schlechtere Vorhersagen getroffen werden, müssen Sie die Verlustfunktion verwenden, um zu beurteilen, ob das Gewicht des Merkmals im Modell geändert werden muss und in welche Richtung die Änderung geht .
Wir können beim maschinellen Lernen verschiedene Verlustfunktionen verwenden, abhängig von der Art des Problems, das wir lösen möchten, der Datenqualität und -verteilung sowie dem von uns verwendeten Algorithmus habe 10 gängige Verlustfunktionen zusammengestellt:
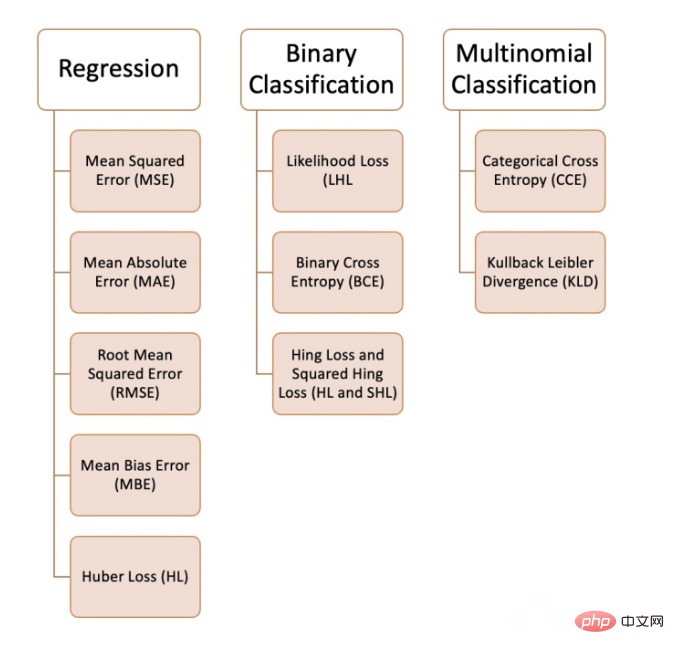 Regressionsproblem
Regressionsproblem
1 Mittlerer quadratischer Fehler (MSE)
# 🎜🎜#Der mittlere quadratische Fehler bezieht sich auf die quadrierte Differenz zwischen allen vorhergesagten Werten und dem wahren Wert und mittelt diese. Wird oft bei Regressionsproblemen verwendet.def MSE (y, y_predicted):
sq_error = (y_predicted - y) ** 2
sum_sq_error = np.sum(sq_error)
mse = sum_sq_error/y.size
return mse
Nach dem Login kopieren
2. Der mittlere absolute Fehler (MAE) wird als Durchschnitt der absoluten Differenzen zwischen dem vorhergesagten Wert und dem wahren Wert berechnet. Dies ist ein besseres Maß als der mittlere quadratische Fehler, wenn die Daten Ausreißer aufweisen. def MSE (y, y_predicted): sq_error = (y_predicted - y) ** 2 sum_sq_error = np.sum(sq_error) mse = sum_sq_error/y.size return mse
def MAE (y, y_predicted):
error = y_predicted - y
absolute_error = np.absolute(error)
total_absolute_error = np.sum(absolute_error)
mae = total_absolute_error/y.size
return mae
Nach dem Login kopieren
3. Root Mean Square Error (RMSE)Diese Verlustfunktion ist die Quadratwurzel des mittleren quadratischen Fehlers. Dies ist ein idealer Ansatz, wenn wir größere Fehler nicht bestrafen wollen. def MAE (y, y_predicted): error = y_predicted - y absolute_error = np.absolute(error) total_absolute_error = np.sum(absolute_error) mae = total_absolute_error/y.size return mae
def RMSE (y, y_predicted):
sq_error = (y_predicted - y) ** 2
total_sq_error = np.sum(sq_error)
mse = total_sq_error/y.size
rmse = math.sqrt(mse)
return rmse
Nach dem Login kopieren
4. Der mittlere Bias-Fehler (MBE) ähnelt dem mittleren absoluten Fehler, sucht jedoch nicht nach dem absoluten Wert. Der Nachteil dieser Verlustfunktion besteht darin, dass sich negative und positive Fehler gegenseitig aufheben können. Daher ist es besser, sie anzuwenden, wenn der Forscher weiß, dass der Fehler nur in eine Richtung geht. def RMSE (y, y_predicted): sq_error = (y_predicted - y) ** 2 total_sq_error = np.sum(sq_error) mse = total_sq_error/y.size rmse = math.sqrt(mse) return rmse
def MBE (y, y_predicted):
error = y_predicted -y
total_error = np.sum(error)
mbe = total_error/y.size
return mbe
Nach dem Login kopieren
5. Huber-VerlustDie Huber-Verlustfunktion kombiniert die Vorteile des mittleren absoluten Fehlers (MAE) und des mittleren quadratischen Fehlers (MSE). Dies liegt daran, dass der Hubber-Verlust eine Funktion mit zwei Zweigen ist. Ein Zweig wird auf MAEs angewendet, die den erwarteten Werten entsprechen, und der andere Zweig wird auf Ausreißer angewendet. Die allgemeine Funktion von Hubber Loss ist: def MBE (y, y_predicted): error = y_predicted -y total_error = np.sum(error) mbe = total_error/y.size return mbe
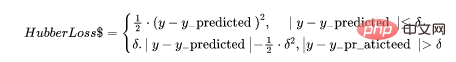
def hubber_loss (y, y_predicted, delta) delta = 1.35 * MAE y_size = y.size total_error = 0 for i in range (y_size): erro = np.absolute(y_predicted[i] - y[i]) if error < delta: hubber_error = (error * error) / 2 else: hubber_error = (delta * error) / (0.5 * (delta * delta)) total_error += hubber_error total_hubber_error = total_error/y.size return total_hubber_error
6. Maximum-Likelihood-Verlust (Likelihood Loss/LHL)
Diese Verlustfunktion wird hauptsächlich für binäre Klassifizierungsprobleme verwendet. Die Wahrscheinlichkeit jedes vorhergesagten Werts wird multipliziert, um einen Verlustwert zu erhalten, und die zugehörige Kostenfunktion ist der Durchschnitt aller beobachteten Werte. Nehmen wir das folgende Beispiel einer binären Klassifizierung, bei der die Klasse [0] oder [1] ist. Wenn die Ausgabewahrscheinlichkeit gleich oder größer als 0,5 ist, ist die vorhergesagte Klasse [1], andernfalls ist sie [0]. Ein Beispiel für die Ausgabewahrscheinlichkeit lautet wie folgt:
[0.3 , 0.7 , 0.8 , 0.5 , 0.6 , 0.4]
Die entsprechende vorhergesagte Klasse ist:
[0 , 1 , 1 , 1 , 1 , 0]
Und die tatsächliche Klasse ist:
[0 , 1 , 1 , 0 , 1 , 0]
Jetzt Zur Berechnung des Verlusts werden die realen Klassen- und Ausgabewahrscheinlichkeiten verwendet. Wenn die wahre Klasse [1] ist, verwenden wir die Ausgabewahrscheinlichkeit, wenn die wahre Klasse [0] ist, verwenden wir die 1-Wahrscheinlichkeit:
((1–0.3)+0.7+0.8+(1–0.5)+0.6+(1–0.4)) / 6 = 0.65
Der Python-Code lautet wie folgt: #🎜🎜 #
def LHL (y, y_predicted): likelihood_loss = (y * y_predicted) + ((1-y) * (y_predicted)) total_likelihood_loss = np.sum(likelihood_loss) lhl = - total_likelihood_loss / y.size return lhl
Lassen Sie uns weiterhin die Werte aus verwenden obiges Beispiel: #🎜 🎜#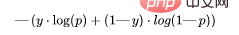
- (0 . log (0,3) + (1–0) . log (1–0,3)) = 0,155 #🎜 🎜#(1 . log(0,7) + (1–1) . log (0,3)) = 0,155(1 . log(0,8) + (1–1) . log (0,2)) = 0,097#🎜 🎜#
- (1 . log(0,6) + ( 1–1). ##🎜🎜 #Dann ist das Ergebnis der Kostenfunktion:
- Der Python-Code lautet wie folgt:
- 8, Hinge Loss und Squared Hinge Loss (HL und SHL) #🎜 🎜#Hinge Loss wird als Scharnierverlust oder Scharnierverlust übersetzt. Hier ist die englische Version maßgebend.
Hinge Loss主要用于支持向量机模型的评估。错误的预测和不太自信的正确预测都会受到惩罚。所以一般损失函数是:

这里的t是真实结果用[1]或[-1]表示。
使用Hinge Loss的类应该是[1]或-1。为了在Hinge loss函数中不被惩罚,一个观测不仅需要正确分类而且到超平面的距离应该大于margin(一个自信的正确预测)。如果我们想进一步惩罚更高的误差,我们可以用与MSE类似的方法平方Hinge损失,也就是Squared Hinge Loss。
如果你对SVM比较熟悉,应该还记得在SVM中,超平面的边缘(margin)越高,则某一预测就越有信心。如果这块不熟悉,则看看这个可视化的例子:
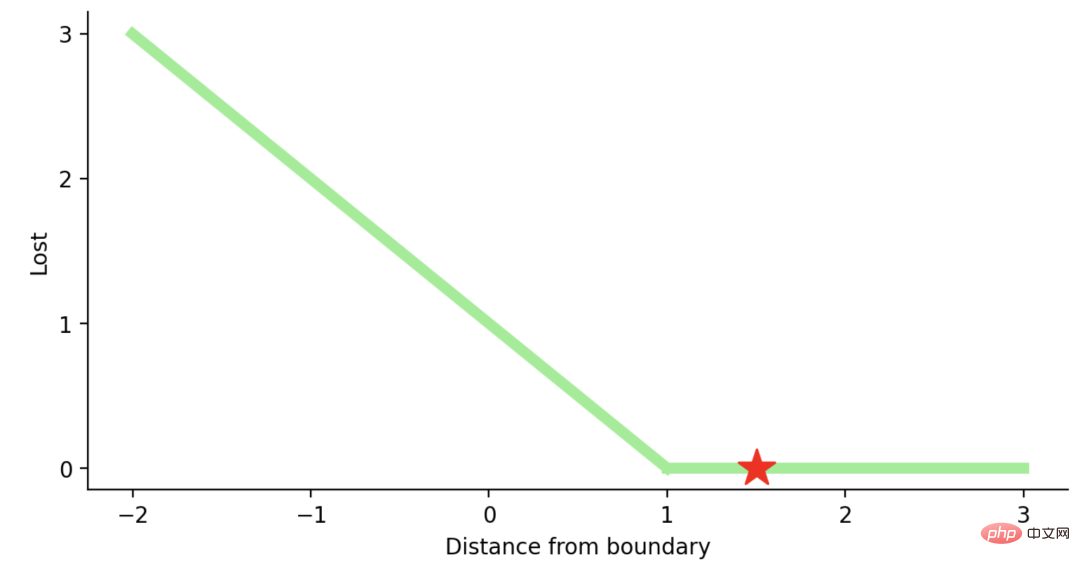
如果一个预测的结果是1.5,并且真正的类是[1],损失将是0(零),因为模型是高度自信的。
loss= Max (0,1 - 1* 1.5) = Max (0, -0.5) = 0
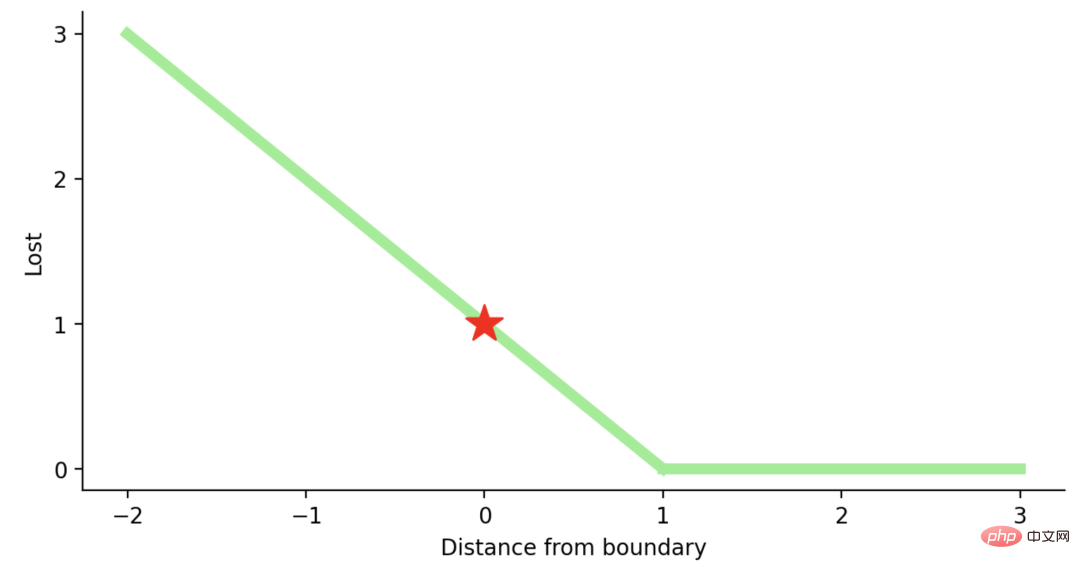
如果一个观测结果为0(0),则表示该观测处于边界(超平面),真实的类为[-1]。损失为1,模型既不正确也不错误,可信度很低。
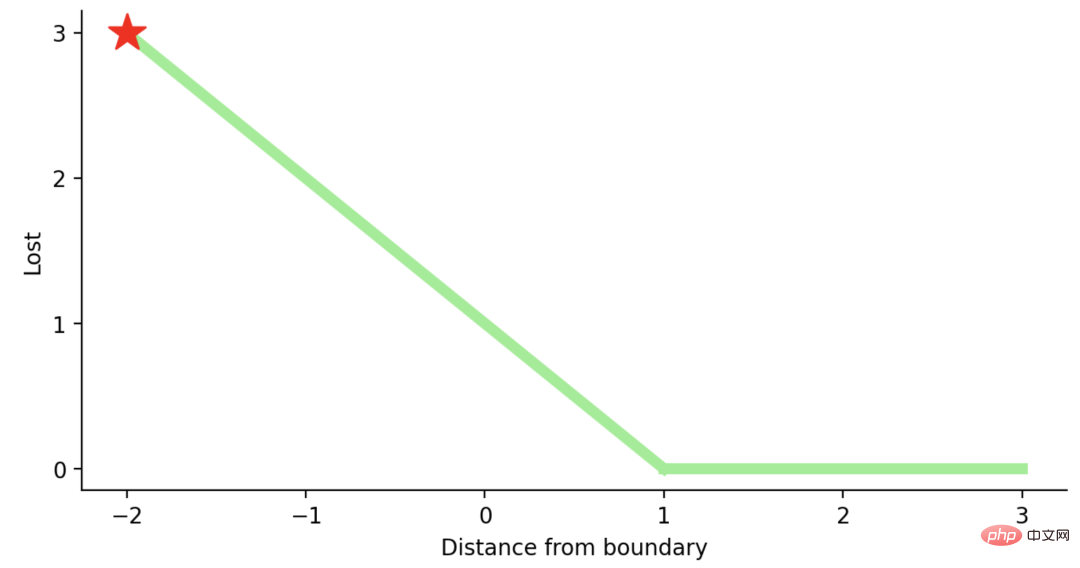
如果一次观测结果为2,但分类错误(乘以[-1]),则距离为-2。损失是3(非常高),因为我们的模型对错误的决策非常有信心(这个是绝不能容忍的)。
python代码如下:
#Hinge Loss def Hinge (y, y_predicted): hinge_loss = np.sum(max(0 , 1 - (y_predicted * y))) return hinge_loss #Squared Hinge Loss def SqHinge (y, y_predicted): sq_hinge_loss = max (0 , 1 - (y_predicted * y)) ** 2 total_sq_hinge_loss = np.sum(sq_hinge_loss) return total_sq_hinge_loss
Nach dem Login kopieren多分类
9、交叉熵(CE)
在多分类中,我们使用与二元交叉熵类似的公式,但有一个额外的步骤。首先需要计算每一对[y, y_predicted]的损失,一般公式为:
如果我们有三个类,其中单个[y, y_predicted]对的输出是:
这里实际的类3(也就是值=1的部分),我们的模型对真正的类是3的信任度是0.7。计算这损失如下:
为了得到代价函数的值,我们需要计算所有单个配对的损失,然后将它们相加最后乘以[-1/样本数量]。代价函数由下式给出:
使用上面的例子,如果我们的第二对:
那么成本函数计算如下:
使用Python的代码示例可以更容易理解;
def CCE (y, y_predicted): cce_class = y * (np.log(y_predicted)) sum_totalpair_cce = np.sum(cce_class) cce = - sum_totalpair_cce / y.size return cce
Nach dem Login kopieren10、Kullback-Leibler 散度 (KLD)
又被简化称为KL散度,它类似于分类交叉熵,但考虑了观测值发生的概率。如果我们的类不平衡,它特别有用。
def KL (y, y_predicted): kl = y * (np.log(y / y_predicted)) total_kl = np.sum(kl) return total_kl
Nach dem Login kopieren以上就是常见的10个损失函数,希望对你有所帮助。
Das obige ist der detaillierte Inhalt vonHäufig verwendete Verlustfunktionen und Python-Implementierungsbeispiele. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
(0.155 + 0.155 + 0.097 + 0.301 + 0.222 + 0.222) / 6 = 0.192
def BCE (y, y_predicted): ce_loss = y*(np.log(y_predicted))+(1-y)*(np.log(1-y_predicted)) total_ce = np.sum(ce_loss) bce = - total_ce/y.size return bce
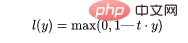
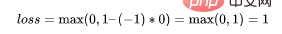
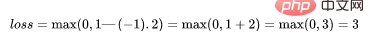
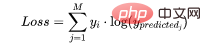

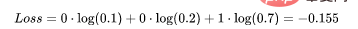
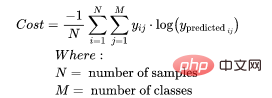

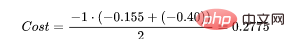
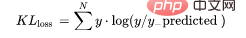

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
