
 Technologie-Peripheriegeräte
KI
ChatGPT konzentriert sich auf den Chatbot-Wettbewerb zwischen Google, Meta und OpenAI und stellt die Unzufriedenheit von LeCun in den Mittelpunkt des Themas
Technologie-Peripheriegeräte
KI
ChatGPT konzentriert sich auf den Chatbot-Wettbewerb zwischen Google, Meta und OpenAI und stellt die Unzufriedenheit von LeCun in den Mittelpunkt des Themas
ChatGPT konzentriert sich auf den Chatbot-Wettbewerb zwischen Google, Meta und OpenAI und stellt die Unzufriedenheit von LeCun in den Mittelpunkt des Themas

Vor ein paar Tagen verbreiteten sich die Kommentare von Metas Chefforscher für künstliche Intelligenz, Yann LeCun, zu ChatGPT schnell in der Branche und lösten viele Diskussionen aus.
Bei einem kleinen Treffen von Medien und Führungskräften bei Zoom machte LeCun einen überraschenden Kommentar: „Was die zugrunde liegende Technologie betrifft, ist ChatGPT keine große Innovation.“
„Obwohl es in der Öffentlichkeit revolutionär ist.“ , aber wir wissen, dass es sich um ein gut zusammengesetztes Produkt handelt, mehr nicht.“
ChatGPT ist keine Innovation
ChatGPT war in den letzten Monaten der „erstklassige“ Chatbot. Er wurde überall beliebt Welt und veränderte sogar die Karriere einiger Menschen und die aktuelle Situation der Schulbildung.
Als die ganze Welt davon begeistert war, war LeCuns Rezension von ChatGPT so „Understatement“.

Aber tatsächlich sind seine Bemerkungen nicht unvernünftig.
Datengesteuerte künstliche Intelligenzsysteme wie ChatGPT sind in vielen Unternehmen und Forschungslaboren verfügbar. LeCun sagte, dass OpenAI in diesem Bereich nicht sehr einzigartig sei.
„Neben Google und Meta gibt es sechs Startups, im Grunde alle mit sehr ähnlicher Technologie.“

Dann wurde LeCun etwas sauer -
"ChatGPT verwendet eine Transformer-Architektur, die auf selbstüberwachte Weise vorab trainiert wird, und selbstüberwachtes Lernen ist das, was ich schon seit langem befürworte. Bei Damals war OpenAI noch nicht geboren.“
Unter ihnen ist Transformer die Erfindung von Google. Diese Art von sprachlichem neuronalem Netzwerk ist die Grundlage groß angelegter Sprachmodelle wie GPT-3.
Das erste Sprachmodell für neuronale Netze wurde vor 20 Jahren von Yoshua Bengio vorgeschlagen. Bengios Aufmerksamkeitsmechanismus wurde später von Google in Transformer verwendet und ist seitdem zu einem Schlüsselelement in allen Sprachmodellen geworden.
Darüber hinaus nutzt ChatGPT die Human Feedback Reinforcement Learning (RLHF)-Technologie, die ebenfalls von Google DeepMind Lab entwickelt wurde.
Nach Ansicht von LeCun ist ChatGPT eher ein erfolgreicher technischer Fall als ein wissenschaftlicher Durchbruch.
Die Technologie von OpenAI „ist nichts Innovatives im Hinblick auf die Grundlagenforschung, sie ist einfach nur gut konzipiert.“
 Ich kritisiere die Arbeit von OpenAI nicht Es handelt sich auch nicht um eine Kritik ihrer Ideen.
Ich kritisiere die Arbeit von OpenAI nicht Es handelt sich auch nicht um eine Kritik ihrer Ideen.
Ich möchte die Ansichten der Öffentlichkeit und der Medien korrigieren. Sie glauben im Allgemeinen, dass ChatGPT ein innovativer und einzigartiger technologischer Durchbruch ist, aber das ist nicht der Fall.
Bei einer Podiumsdiskussion mit dem New York Times-Reporter Cade Metz spürte LeCun die Zweifel der Wichtigtuer.
„Sie fragen sich vielleicht, warum Google und Meta keine ähnlichen Systeme haben? Meine Antwort ist, dass die Verluste ziemlich groß sein werden, wenn Google und Meta solche unsinnigen Chatbots starten.“
 Zufälligerweise schrieb Marcus über Nacht auch einen Artikel auf seinem Blog, um OpenAI lächerlich zu machen, als bekannt wurde, dass OpenAI von Microsoft und anderen Investoren bevorzugt wurde und sein Wert auf 29 Milliarden US-Dollar stieg.
Zufälligerweise schrieb Marcus über Nacht auch einen Artikel auf seinem Blog, um OpenAI lächerlich zu machen, als bekannt wurde, dass OpenAI von Microsoft und anderen Investoren bevorzugt wurde und sein Wert auf 29 Milliarden US-Dollar stieg.
In dem Artikel brachte Marcus einen goldenen Satz hervor: Was kann OpenAI, was Google nicht kann, und ist es den horrenden Preis von 29 Milliarden US-Dollar wert?
 Google, Meta, DeepMind, OpenAI PK!
Google, Meta, DeepMind, OpenAI PK!
Lassen Sie uns ohne weitere Umschweife die Chatbots dieser KI-Giganten hervorholen und die Daten für sich sprechen lassen.
LeCun sagte, dass viele Unternehmen und Labore KI-Chatbots ähnlich wie ChatGPT haben, was stimmt.
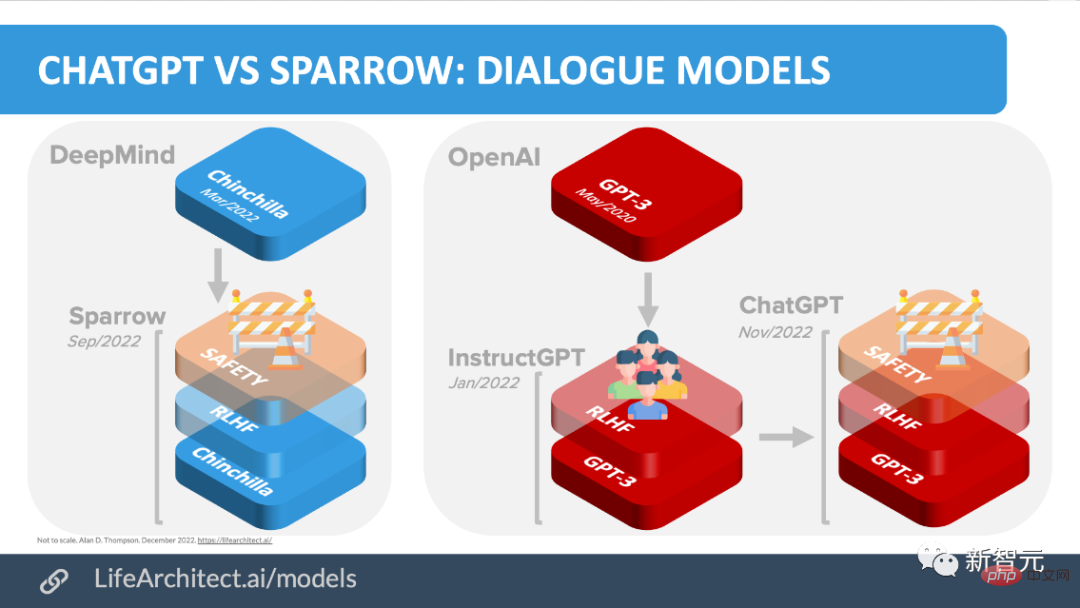
ChatGPT ist nicht der erste KI-Chatbot, der auf einem Sprachmodell basiert, er hat viele „Vorgänger“.
Bevor OpenAI, Meta, Google, DeepMind usw. alle ihre eigenen Chatbots veröffentlichten, wie BlenderBot von Meta, LaMDA von Google und Sparrow von DeepMind.
Einige Teams haben auch ihre eigenen Open-Source-Chatbot-Pläne angekündigt. Zum Beispiel Open-Assistant von LAION.
 In einem Blog von Huggingface haben mehrere Autoren wichtige Beiträge zu den Themen RLHF, SFT, IFT und CoT (allesamt Schlüsselwörter von ChatGPT) untersucht, klassifiziert und zusammengefasst.
In einem Blog von Huggingface haben mehrere Autoren wichtige Beiträge zu den Themen RLHF, SFT, IFT und CoT (allesamt Schlüsselwörter von ChatGPT) untersucht, klassifiziert und zusammengefasst.
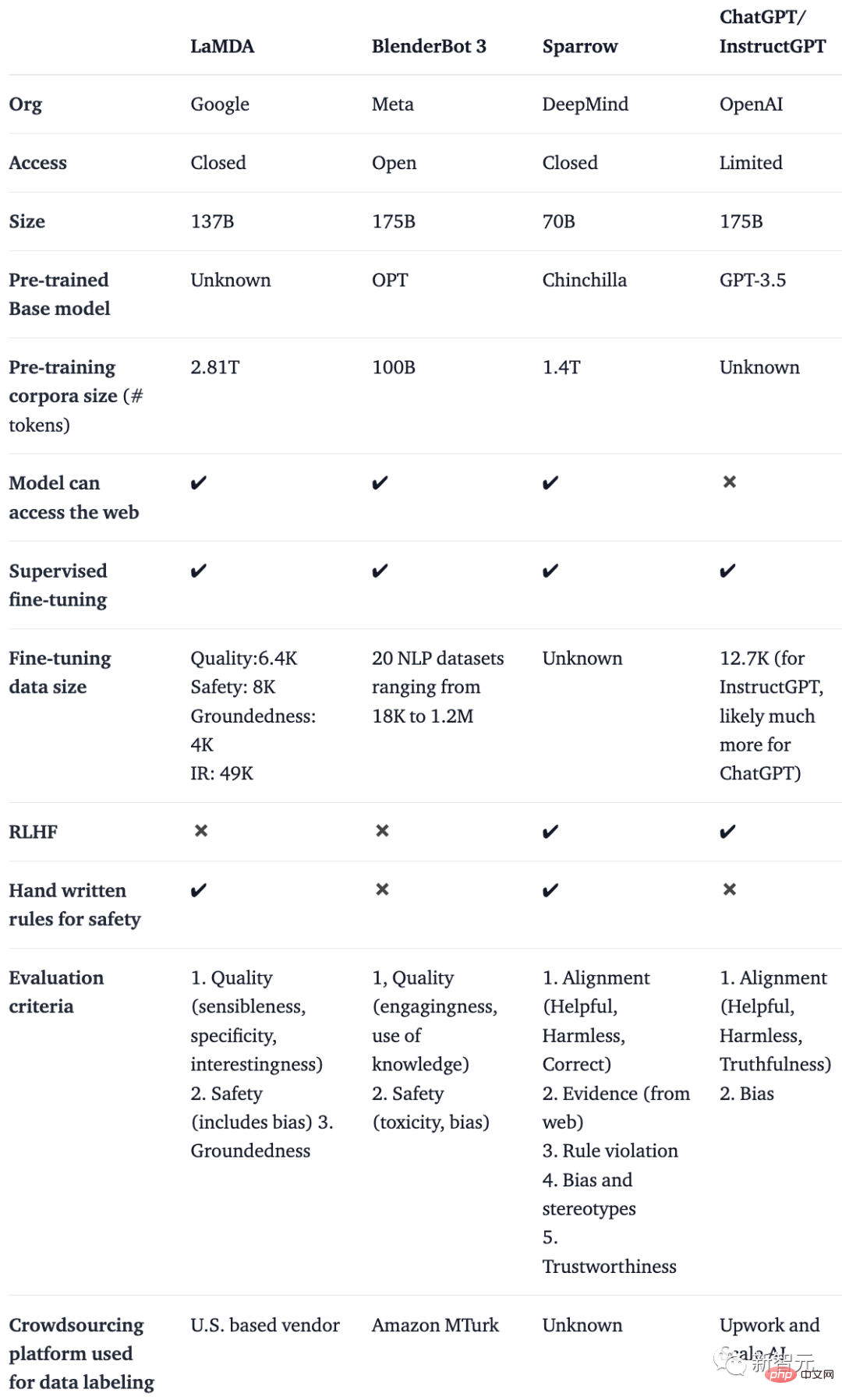
Sie haben eine Tabelle erstellt, in der KI-Chatbots wie BlenderBot, LaMDA, Sparrow und InstructGPT anhand von Details wie öffentlichem Zugriff, Trainingsdaten, Modellarchitektur und Bewertungsrichtung verglichen werden.
Hinweis: Da ChatGPT nicht dokumentiert ist, verwenden sie die Details von InstructGPT, einem Modell zur Feinabstimmung von Anweisungen von OpenAI, das als Grundlage von ChatGPT angesehen werden kann.
LaMDA |
BlenderBot 3 | Sparrow |
ChatGPT/ InstructGPT |
||
Organisation | |
Meta |
DeepMind |
OpenAI |
|
Zugriff |
Geschlossen |
Öffentlich |
Geschlossen |
Begrenzt |
|
Parameterskala |
137 Milliarden |
175 Milliarden |
70 Milliarden |
175 Milliarden |
|
Basismodell |
Unbekannt |
OPT |
Chinchilla |
GPT-3,5 |
|
Körpergröße |
2,81 Billionen |
100 Milliarden |
1,4 Billionen |
Unbekannt |
|
Zugriff auf Web |
✔️ |
✔️ |
✔️ |
✖️ |
|
Überwachung und Feinabstimmung |
✔️ |
✔️ |
✔️ |
✔️ |
|
Feinabstimmung der Datengröße: Hohe Qualität: 6,4 K Unbekannt |
12,7K (ChatGPT könnte mehr sein) RLHF |
✖️ |
✖️ |
✔️ |
|
|
Manuelle Sicherheitsregeln |
✔ |
✖️ |
✔ |
✖️ |
Es ist leicht zu erkennen, dass diese Chatbots trotz vieler Unterschiede in den Trainingsdaten, Basismodellen und Feinabstimmungen eines gemeinsam haben: Sie befolgen Anweisungen.
Zum Beispiel können Sie ChatGPT befehlen, ein Gedicht über Feinabstimmung zu schreiben.
Man sieht, dass ChatGPT sehr „kognitiv“ ist und nie vergisst, LeCun und Hinton beim Schreiben von Gedichten zu schmeicheln.
Dann lobte er leidenschaftlich: „Nudge, Nudge, du bist ein wunderschöner Tanz.“

Von der Textvorhersage bis zur Befolgung von Anweisungen
Normalerweise reicht die Sprachmodellierung des Grundmodells nicht aus um zu lernen, wie man Benutzeranweisungen befolgt.

Beim Training des Modells werden Forscher neben der Verwendung klassischer NLP-Aufgaben (wie Emotionen, Textklassifizierung, Zusammenfassung usw.) auch die Instruktionsfeinabstimmung (IFT) verwenden, die weitergegeben werden soll Sehr unterschiedliche Aufgaben dienen der Feinabstimmung des Basismodells.
Unter diesen bestehen diese Anleitungsbeispiele aus drei Hauptteilen: Anweisungen, Eingabe und Ausgabe.
Die Eingabe ist optional, einige Aufgaben erfordern nur Anweisungen, wie der offene Build im ChatGPT-Beispiel oben.
Wenn eine Ein- und Ausgabe auftritt, wird ein Beispiel gebildet. Für eine bestimmte Anweisung kann es mehrere Eingabe- und Ausgabebeispiele geben. Zum Beispiel das folgende Beispiel:

IFT-Daten sind normalerweise eine Sammlung von Anweisungen, die von Menschen geschrieben wurden, und Anleitungsbeispielen, die von Sprachmodellen geleitet werden.
Während des Bootvorgangs wird LM in einer Einstellung mit wenigen Schüssen aufgefordert (siehe Abbildung oben) und angewiesen, neue Anweisungen, Ein- und Ausgänge zu generieren.
In jeder Runde wird das Modell aufgefordert, aus von Menschen geschriebenen und vom Modell generierten Beispielen auszuwählen.
Der Umfang des menschlichen und modellhaften Beitrags zur Erstellung eines Datensatzes ist wie ein Spektrum (siehe Abbildung unten).
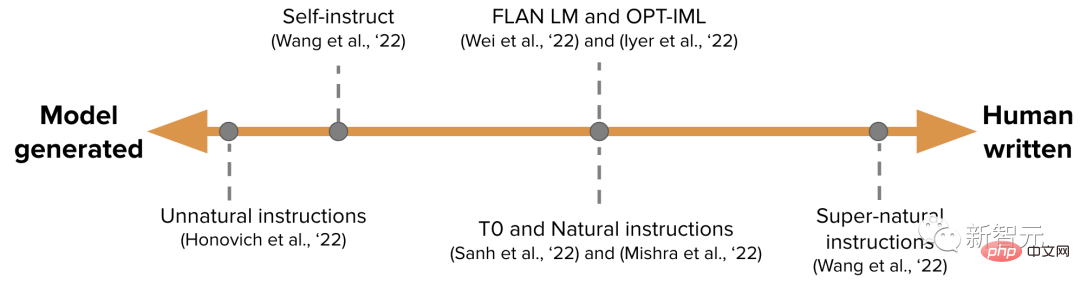
An einem Ende befindet sich ein rein modellgenerierter IFT-Datensatz, wie z. B. Unnatürliche Anweisungen, und am anderen Ende befindet sich eine große Anzahl künstlich generierter Anweisungen, wie z. B. übernatürliche Anweisungen.
Irgendwo dazwischen liegt die Verwendung eines kleineren, aber qualitativ hochwertigeren Seed-Datensatzes und die anschließende Durchführung geführter Arbeiten, z. B. Selbstanweisung.
Eine weitere Möglichkeit, Datensätze für IFT zu organisieren, besteht darin, vorhandene hochwertige Crowdsourcing-NLP-Datensätze für eine Vielzahl von Aufgaben (einschließlich Eingabeaufforderungen) zu nutzen und diese Datensätze mithilfe eines einheitlichen Schemas oder verschiedener Vorlagenanweisungen umzuwandeln.
Die Arbeit in diesem Bereich umfasst T0, Natural-Instructions-Dataset, FLAN LM und OPT-IML.
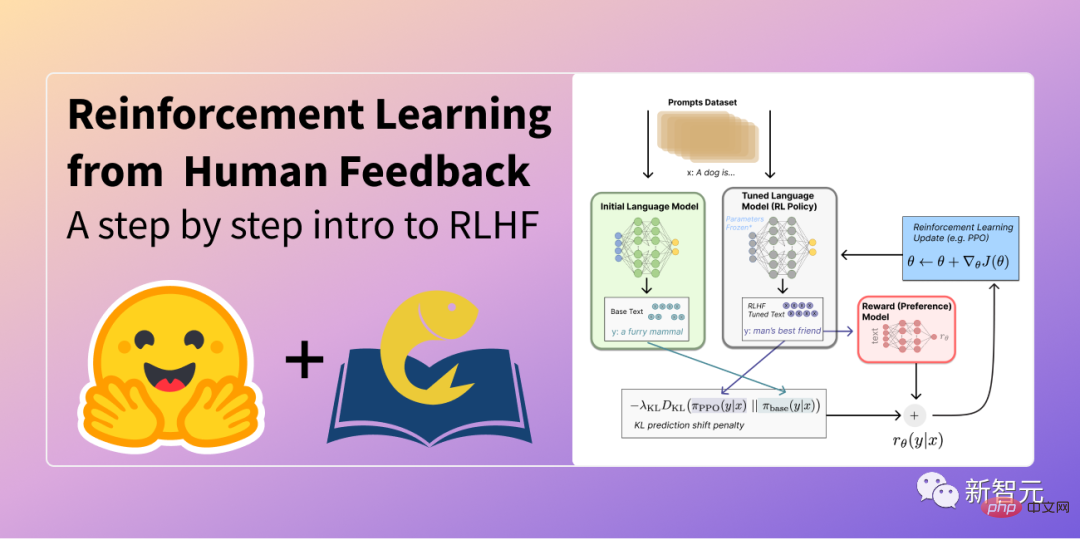
... Zum Einsatz kommt Reinforcement Learning basierend auf menschlichem Feedback (RLHF), also der Annotation menschlicher Präferenzen. 
In RLHF wird eine Reihe von Modellantworten basierend auf menschlichem Feedback (z. B. Auswahl einer populäreren Texteinleitung) eingestuft.
Zuletzt trainieren Sie den Chatbot durch verstärkendes Lernen, um dieses Präferenzmodell zu simulieren.
Chain of Thought (CoT)-Eingabeaufforderungen sind ein Sonderfall von Befehlsbeispielen, die den Chatbot dazu veranlassen, Schritt für Schritt zu argumentieren, um eine Ausgabe zu erzeugen.
Mit CoT verfeinerte Modelle verwenden einen Datensatz mit Anweisungen für die schrittweise Schlussfolgerung mit menschlichen Anmerkungen.
Dies ist der Ursprung der berühmten Aufforderung „Lass uns Schritt für Schritt denken“.
Das folgende Beispiel stammt aus „Scaling Instruction-Finetuned Language Models“. Darunter hebt Orange die Anweisungen hervor, Rosa zeigt die Ein- und Ausgabe und Blau ist die CoT-Schlussfolgerung.

Das Papier weist darauf hin, dass Modelle, die CoT-Feinabstimmung verwenden, bei Aufgaben, die gesunden Menschenverstand, Arithmetik und symbolisches Denken erfordern, eine bessere Leistung erbringen.
Darüber hinaus ist die CoT-Feinabstimmung auch bei sensiblen Themen sehr effektiv (manchmal besser als RLHF), insbesondere um Modellkorruption zu vermeiden – „Leider kann ich nicht antworten“.

Anweisungen sicher befolgen
Wie gerade erwähnt, können auf Anweisungen abgestimmte Sprachmodelle nicht immer nützliche und sichere Antworten liefern.
Zum Beispiel wird es ausgeweicht, indem es nutzlose Antworten wie „Entschuldigung, ich verstehe nicht“ gibt oder unsichere Antworten an Benutzer ausgibt, die sensible Themen ansprechen.
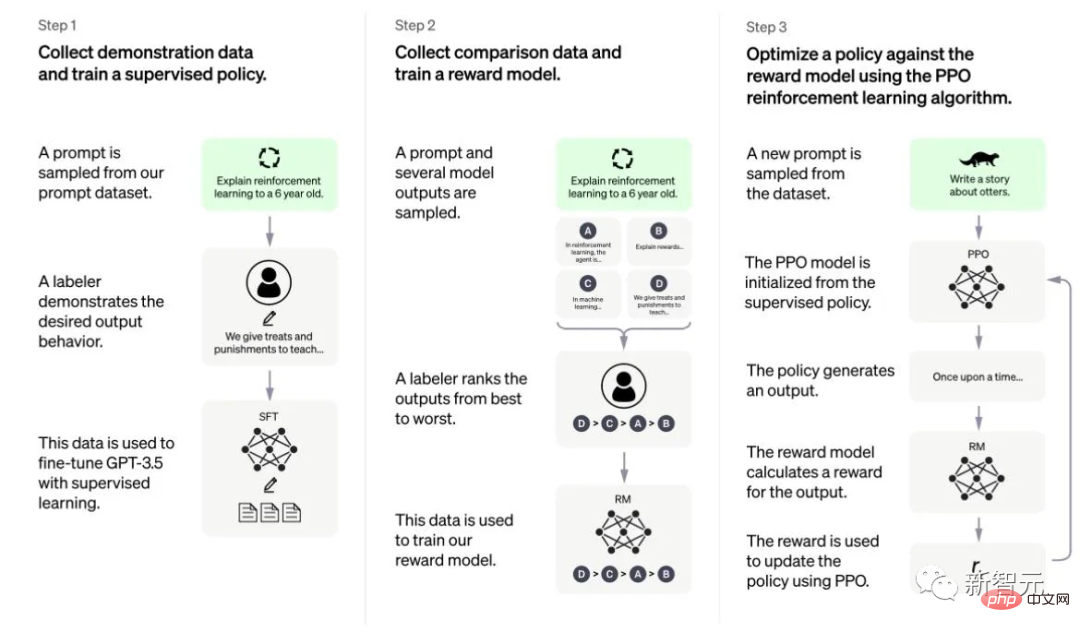
Um dieses Verhalten zu verbessern, verfeinern Forscher das grundlegende Sprachmodell anhand hochwertiger, von Menschen annotierter Daten in Form einer überwachten Feinabstimmung (Supervised Fine-Tuning, SFT) und verbessern so den Nutzen und die Unbedenklichkeit des Modells.

Die Verbindung zwischen SFT und IFT ist sehr eng. IFT kann als Teilmenge von SFT angesehen werden. In der neueren Literatur wird die SFT-Phase häufig für Sicherheitsthemen und nicht für spezifische Unterrichtsthemen verwendet, die nach dem IFT abgeschlossen werden.
Zukünftig soll ihre Klassifizierung und Beschreibung klarere Anwendungsfälle haben.
Darüber hinaus ist Googles LaMDA auch auf einen sicher annotierten Konversationsdatensatz abgestimmt, der Sicherheitsanmerkungen enthält, die auf einer Reihe von Regeln basieren.
Diese Regeln werden oft von Forschern vordefiniert und entwickelt und decken ein breites Themenspektrum ab, darunter Schaden, Diskriminierung, Fehlinformationen und mehr.
Der nächste Schritt für KI-Chatbots
Es gibt noch viele offene Fragen zu KI-Chatbots, wie zum Beispiel:
1 Wie wichtig ist RL beim Lernen aus menschlichem Feedback? Können wir die Leistung von RLHF in IFT oder SFT mit einem qualitativ hochwertigeren Datentraining erreichen?
2. Wie ist die Sicherheit von SFT+RLHF in Sparrow im Vergleich zu nur SFT in LaMDA?
3. Da wir bereits über IFT, SFT, CoT und RLHF verfügen, wie viel weitere Vorschulung ist erforderlich? Welche Kompromisse gibt es? Welches ist das beste Basismodell (sowohl öffentlich als auch privat)?
4. Diese Modelle werden nun sorgfältig entwickelt, wobei Forscher gezielt nach Fehlermöglichkeiten suchen und auf der Grundlage der aufgedeckten Probleme Einfluss auf zukünftige Schulungen (einschließlich Tipps und Methoden) nehmen. Wie können wir die Wirkung dieser Methoden systematisch dokumentieren und reproduzieren?
Zusammenfassend
1 Im Vergleich zu den Trainingsdaten ist nur ein sehr kleiner Teil für die Feinabstimmung des Unterrichts erforderlich (Hunderte Größenordnungen).
2. Bei der überwachten Feinabstimmung werden menschliche Anmerkungen verwendet, um die Ausgabe des Modells sicherer und nützlicher zu machen.
3. Die CoT-Feinabstimmung verbessert die Leistung des Modells bei Schritt-für-Schritt-Denkaufgaben und verhindert, dass das Modell immer sensiblen Problemen entgeht.
Referenz:
https://huggingface.co/blog/dialog-agents
Das obige ist der detaillierte Inhalt vonChatGPT konzentriert sich auf den Chatbot-Wettbewerb zwischen Google, Meta und OpenAI und stellt die Unzufriedenheit von LeCun in den Mittelpunkt des Themas. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Das neue erschwingliche Meta Quest 3S VR-Headset erscheint bei FCC, was auf eine baldige Markteinführung hindeutet
Sep 04, 2024 am 06:51 AM
Das neue erschwingliche Meta Quest 3S VR-Headset erscheint bei FCC, was auf eine baldige Markteinführung hindeutet
Sep 04, 2024 am 06:51 AM
Die Meta Connect 2024-Veranstaltung findet vom 25. bis 26. September statt. Bei dieser Veranstaltung wird das Unternehmen voraussichtlich ein neues erschwingliches Virtual-Reality-Headset vorstellen. Gerüchten zufolge handelt es sich bei dem VR-Headset um das Meta Quest 3S, das offenbar auf der FCC-Liste aufgetaucht ist. Dieser Vorschlag
 Das erste Open-Source-Modell, das das GPT4o-Niveau übertrifft! Llama 3.1 durchgesickert: 405 Milliarden Parameter, Download-Links und Modellkarten sind verfügbar
Jul 23, 2024 pm 08:51 PM
Das erste Open-Source-Modell, das das GPT4o-Niveau übertrifft! Llama 3.1 durchgesickert: 405 Milliarden Parameter, Download-Links und Modellkarten sind verfügbar
Jul 23, 2024 pm 08:51 PM
Machen Sie Ihre GPU bereit! Llama3.1 ist endlich erschienen, aber die Quelle ist nicht offiziell von Meta. Heute gingen die durchgesickerten Nachrichten über das neue Llama-Großmodell auf Reddit viral. Zusätzlich zum Basismodell enthält es auch Benchmark-Ergebnisse von 8B, 70B und den maximalen Parameter von 405B. Die folgende Abbildung zeigt die Vergleichsergebnisse jeder Version von Llama3.1 mit OpenAIGPT-4o und Llama38B/70B. Es ist ersichtlich, dass selbst die 70B-Version in mehreren Benchmarks GPT-4o übertrifft. Bildquelle: https://x.com/mattshumer_/status/1815444612414087294 Offensichtlich Version 3.1 von 8B und 70
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Ollama ist ein superpraktisches Tool, mit dem Sie Open-Source-Modelle wie Llama2, Mistral und Gemma problemlos lokal ausführen können. In diesem Artikel werde ich vorstellen, wie man Ollama zum Vektorisieren von Text verwendet. Wenn Sie Ollama nicht lokal installiert haben, können Sie diesen Artikel lesen. In diesem Artikel verwenden wir das Modell nomic-embed-text[2]. Es handelt sich um einen Text-Encoder, der OpenAI text-embedding-ada-002 und text-embedding-3-small bei kurzen und langen Kontextaufgaben übertrifft. Starten Sie den nomic-embed-text-Dienst, wenn Sie o erfolgreich installiert haben
 Sechs schnelle Möglichkeiten, das neu veröffentlichte Llama 3 zu erleben!
Apr 19, 2024 pm 12:16 PM
Sechs schnelle Möglichkeiten, das neu veröffentlichte Llama 3 zu erleben!
Apr 19, 2024 pm 12:16 PM
Gestern Abend hat Meta die Modelle Llama38B und 70B veröffentlicht. Das anweisungsoptimierte Modell Llama3 ist für Dialog-/Chat-Anwendungsfälle optimiert und übertrifft viele bestehende Open-Source-Chat-Modelle in gängigen Benchmarks. Zum Beispiel Gemma7B und Mistral7B. Das Llama+3-Modell verbessert Daten und Skalierung und erreicht neue Höhen. Es wurde mit mehr als 15T Datentokens auf zwei benutzerdefinierten 24K-GPU-Clustern trainiert, die kürzlich von Meta veröffentlicht wurden. Dieser Trainingsdatensatz ist siebenmal größer als Llama2 und enthält viermal mehr Code. Dies bringt die Leistungsfähigkeit des Llama-Modells auf das derzeit höchste Niveau, das Textlängen von mehr als 8 KB unterstützt, doppelt so viel wie Llama2. unter
 ChatGPT ist jetzt mit der Veröffentlichung einer speziellen App für macOS verfügbar
Jun 27, 2024 am 10:05 AM
ChatGPT ist jetzt mit der Veröffentlichung einer speziellen App für macOS verfügbar
Jun 27, 2024 am 10:05 AM
Die ChatGPT-Mac-Anwendung von Open AI ist jetzt für alle verfügbar, während sie in den letzten Monaten nur denjenigen mit einem ChatGPT Plus-Abonnement vorbehalten war. Die App lässt sich wie jede andere native Mac-App installieren, sofern Sie über ein aktuelles Apple S verfügen
 Das stärkste Modell Llama 3.1 405B wird offiziell veröffentlicht, Zuckerberg: Open Source leitet eine neue Ära ein
Jul 24, 2024 pm 08:23 PM
Das stärkste Modell Llama 3.1 405B wird offiziell veröffentlicht, Zuckerberg: Open Source leitet eine neue Ära ein
Jul 24, 2024 pm 08:23 PM
Gerade jetzt wurde das lang erwartete Llama 3.1 offiziell veröffentlicht! Meta gab offiziell bekannt, dass „Open Source eine neue Ära einläutet“. Im offiziellen Blog sagte Meta: „Bis heute sind große Open-Source-Sprachmodelle hinsichtlich Funktionalität und Leistung meist hinter geschlossenen Modellen zurückgeblieben. Jetzt läuten wir eine neue Ära ein, die von Open Source angeführt wird. Wir haben MetaLlama3.1405B öffentlich veröffentlicht.“ , von dem wir glauben, dass es sich um das größte und leistungsfähigste Open-Source-Basismodell der Welt handelt, die Gesamtzahl der Downloads aller Llama-Versionen hat gerade 300 Millionen Mal überschritten, und wir haben gerade erst damit begonnen, eine zu schreiben Artikel. Langer Artikel „OpenSourceAIIsthePathForward“,
