

Wir wissen, dass die GPT-Serie von OpenAI durch umfangreiche und vorab trainierte Methoden eine neue Ära der künstlichen Intelligenz eingeläutet hat. Für die meisten Forscher sind jedoch große Sprachmodelle (LLM) aufgrund ihres Volumens und ihrer Anforderungen an die Rechenleistung zu teuer. Unerreichbar. Während sich die Technologie weiterentwickelt, beschäftigen sich die Menschen auch mit dem „einfachsten“ GPT-Modell.
Kürzlich stellte Andrej Karpathy, der ehemalige KI-Direktor von Tesla und gerade zu OpenAI zurückgekehrt, eine einfachste Möglichkeit vor, GPT zu spielen, die möglicherweise mehr Menschen hilft, die Technologie hinter diesem beliebten KI-Modell zu verstehen.
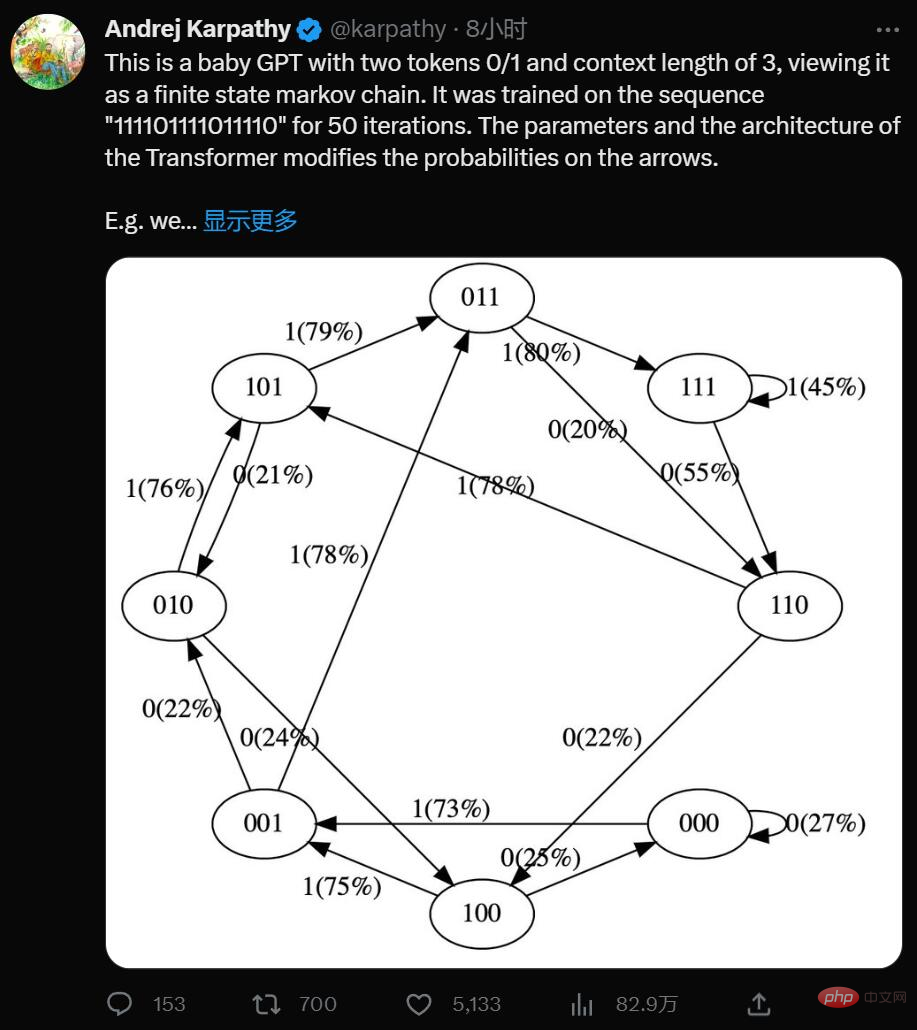
Ja, dies ist ein minimalistischer GPT mit zwei Token 0/1 und einer Kontextlänge von 3. Stellen Sie sich das als eine Markov-Kette mit endlichen Zuständen vor. Es wird auf der Sequenz „111101111011110“ für 50 Iterationen trainiert, und die Parameter und die Architektur des Transformers modifizieren die Wahrscheinlichkeiten auf den Pfeilen.
Zum Beispiel können wir sehen:
Durch Vereinfachung hat Karpathy die Visualisierung von GPT-Modellen vereinfacht, sodass Sie das gesamte System intuitiv verstehen können.
Sie können es hier ausprobieren: https://colab.research.google.com/drive/1SiF0KZJp75rUeetKOWqpsA8clmHP6jMg?usp=sharing
Tatsächlich sogar die erste Version von GPT, das Volumen des Modells Ziemlich beeindruckend: Im Jahr 2018 veröffentlichte OpenAI das GPT-Modell der ersten Generation. Aus dem Artikel „Improving Language Understanding by Generative Pre-Training“ können wir lernen, dass es eine 12-schichtige Transformer-Decoder-Struktur verwendet und etwa 5 GB unüberwachte Textdaten verwendet . Führen Sie Schulungen durch.
Aber wenn man das Konzept vereinfacht, ist GPT ein neuronales Netzwerk, das einige diskrete Token-Sequenzen verwendet und die Wahrscheinlichkeit des nächsten Tokens in der Sequenz vorhersagt. Wenn es zum Beispiel nur zwei Marker 0 und 1 gibt, dann kann uns ein kleiner binärer GPT zum Beispiel sagen:
1 |
|
Hier nimmt der GPT die Bitfolge [0,1,0] und basiert auf dem aktuellen Parameter Einstellungen: Die Wahrscheinlichkeit, dass die nächste Vorhersage 1 ist, beträgt 80 %. Wichtig ist, dass die Kontextlänge von GPT standardmäßig begrenzt ist. Wenn die Kontextlänge 3 beträgt, können bei der Eingabe nur bis zu 3 Token verwendet werden. Wenn wir im obigen Beispiel eine voreingenommene Münze werfen und 1 abtasten, was eigentlich der nächste sein sollte, wechseln wir vom ursprünglichen Zustand [0,1,0] zum neuen Zustand [1,0,1]. Wir fügen rechts ein neues Bit hinzu (1) und kürzen die Sequenz auf Kontextlänge 3, indem wir das Bit ganz links (0) verwerfen. Dieser Vorgang kann für den Übergang zwischen Zuständen immer wieder wiederholt werden.
Offensichtlich ist GPT eine Markov-Kette mit endlichen Zuständen: Es gibt eine endliche Menge von Zuständen und probabilistische Übergangspfeile zwischen ihnen. Jeder Zustand wird durch eine bestimmte Einstellung von Tokens am GPT-Eingang definiert (z. B. [0,1,0]). Wir können es mit einer bestimmten Wahrscheinlichkeit in einen neuen Zustand überführen, beispielsweise [1,0,1]. Sehen wir uns an, wie es im Detail funktioniert:
1 2 3 4 5 |
|
Die Eingabe in das neuronale GPT-Netzwerk ist eine Folge von Tokens der Länge context_length. Diese Token sind diskret, daher ist der Zustandsraum einfach:
1 2 |
|
Details: Um genau zu sein, kann GPT eine beliebige Anzahl von Tokens von 1 bis context_length annehmen. Wenn die Kontextlänge also 3 beträgt, können wir im Prinzip 1, 2 oder 3 Token eingeben, während wir versuchen, das nächste Token vorherzusagen. Wir ignorieren dies hier und gehen davon aus, dass die Kontextlänge „maximiert“ wird, nur um einen Teil des folgenden Codes zu vereinfachen, aber es lohnt sich, dies im Hinterkopf zu behalten.
1 2 |
|
我们现在要在 PyTorch 中定义一个 GPT。出于本笔记本的目的,你无需理解任何此代码。
现在让我们构建 GPT 吧:
1 2 3 4 5 6 7 8 9 |
|
对于这个笔记本你不必担心 n_layer、n_head、n_embd、bias,这些只是实现 GPT 的 Transformer 神经网络的一些超参数。
GPT 的参数(12656 个)是随机初始化的,它们参数化了状态之间的转移概率。如果你平滑地更改这些参数,就会平滑地影响状态之间的转换概率。
现在让我们试一试随机初始化的 GPT。让我们获取上下文长度为 3 的小型二进制 GPT 的所有可能输入:
1 2 3 4 5 6 7 8 9 |
|
1 2 3 4 5 6 7 8 |
|
这是 GPT 可能处于的 8 种可能状态。让我们对这些可能的标记序列中的每一个运行 GPT,并获取序列中下一个标记的概率,并绘制为可视化程度比较高的图形:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
1 2 3 4 5 6 7 8 |
|
我们看到了 8 个状态,以及连接它们的概率箭头。因为有 2 个可能的标记,所以每个节点有 2 个可能的箭头。请注意,在初始化时,这些概率中的大多数都是统一的(在本例中为 50%),这很好而且很理想,因为我们甚至根本没有训练模型。
下面开始训练:
1 2 3 |
|
1 |
|
1 2 3 4 5 6 7 8 9 10 11 |
|
我们可以看到在那个序列中有 12 个示例。现在让我们训练它:
1 2 3 4 |
|
1 2 3 4 5 6 7 8 |
|
1 2 |
|
我们没有得到这些箭头的准确 100% 或 50% 的概率,因为网络没有经过充分训练,但如果继续训练,你会期望接近。
请注意一些其他有趣的事情:一些从未出现在训练数据中的状态(例如 000 或 100)对于接下来应该出现的 token 有很大的概率。如果在训练期间从未遇到过这些状态,它们的出站箭头不应该是 50% 左右吗?这看起来是个错误,但实际上是可取的,因为在部署期间的真实应用场景中,几乎每个 GPT 的测试输入都是训练期间从未见过的输入。我们依靠 GPT 的内部结构(及其「归纳偏差」)来适当地执行泛化。
大小比较:
Andrej Karpathy 是 OpenAI 的创始成员和研究科学家。但在 OpenAI 成立一年多后,Karpathy 便接受了马斯克的邀请,加入了特斯拉。在特斯拉工作的五年里,他一手促成了 Autopilot 的开发。这项技术对于特斯拉的完全自动驾驶系统 FSD 至关重要,也是马斯克针对 Model S、Cybertruck 等车型的卖点之一。
今年 2 月,在 ChatGPT 火热的背景下,Karpathy 回归 OpenAI,立志构建现实世界的 JARVIS 系统。

最近一段时间,Karpathy 给大家贡献了很多学习材料,包括详解反向传播的课程 、重写的 minGPT 库、从零开始构建 GPT 模型的完整教程等。
Das obige ist der detaillierte Inhalt vonEs ist nicht nötig, Code zu schreiben, das einfachste BabyGPT-Modell kann von Hand erstellt werden: die neue Arbeit des ehemaligen Tesla AI-Direktors. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in die Verwendung des gesamten VBS-Codes
Einführung in die Verwendung des gesamten VBS-Codes
 Verwendung der C-Sprache printf-Funktion
Verwendung der C-Sprache printf-Funktion
 So richten Sie die automatische Aktualisierung einer Webseite ein
So richten Sie die automatische Aktualisierung einer Webseite ein
 Einführung in die Lightning-Schnittstelle
Einführung in die Lightning-Schnittstelle
 Der Unterschied zwischen geschindelten Scheiben und vertikalen Scheiben
Der Unterschied zwischen geschindelten Scheiben und vertikalen Scheiben
 So erstatten Sie den von Douyin aufgeladenen Doucoin zurück
So erstatten Sie den von Douyin aufgeladenen Doucoin zurück
 Werden Sols-Inschriftenmünzen auf Null zurückkehren?
Werden Sols-Inschriftenmünzen auf Null zurückkehren?
 Warum erfolgt keine Reaktion, wenn Kopfhörer an den Computer angeschlossen sind?
Warum erfolgt keine Reaktion, wenn Kopfhörer an den Computer angeschlossen sind?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



