
 Technologie-Peripheriegeräte
KI
Interessanter Vortrag über die Prinzipien und Algorithmen von ChatGPT
Technologie-Peripheriegeräte
KI
Interessanter Vortrag über die Prinzipien und Algorithmen von ChatGPT
Interessanter Vortrag über die Prinzipien und Algorithmen von ChatGPT

Am 1. Dezember letzten Jahres startete OpenAI den Chat-Prototyp für künstliche Intelligenz, ChatGPT, der erneut Aufmerksamkeit erregte und eine große Diskussion in der KI-Community auslöste, ähnlich wie die AIGC, die Künstler arbeitslos machte.
ChatGPT ist ein Sprachmodell, das sich auf die Generierung von Konversationen konzentriert. Es kann basierend auf der Texteingabe des Benutzers entsprechende intelligente Antworten generieren.
Diese Antwort kann aus kurzen Worten oder einem langen Aufsatz bestehen. Unter diesen ist GPT die Abkürzung für Generative Pre-trained Transformer (generatives vortrainiertes Transformationsmodell).
Durch das Lernen aus einer großen Anzahl vorgefertigter Text- und Dialogsammlungen (z. B. Wiki) kann ChatGPT sofort Gespräche wie Menschen führen und verschiedene Fragen fließend beantworten. (Natürlich ist die Antwortgeschwindigkeit immer noch langsamer als die von Menschen) Ob Englisch oder andere Sprachen (wie Chinesisch, Koreanisch usw.), von der Beantwortung historischer Fragen über das Schreiben von Geschichten bis hin zum Schreiben von Geschäften Pläne und Branchenanalysen, kann „fast“ alles. Einige Programmierer haben auf ChatGPT sogar Gespräche über Programmänderungen gepostet.
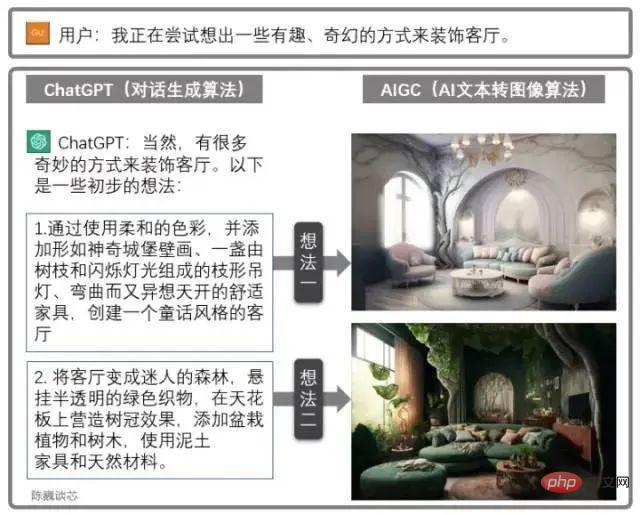
Kombinierte Nutzung von ChatGPT und AIGC
ChatGPT kann auch in Verbindung mit anderen AIGC-Modellen verwendet werden, um weitere coole und praktische Funktionen zu erhalten.
Zum Beispiel wird die Entwurfszeichnung für das Wohnzimmer durch den obigen Dialog erstellt. Dies verbessert die Fähigkeit von KI-Anwendungen, mit Kunden zu kommunizieren, erheblich und ermöglicht es uns, den Beginn einer groß angelegten Implementierung von KI zu erleben.
1. Die Vererbung und Eigenschaften von ChatGPT

▌1.1 OpenAI-Familie
Lassen Sie uns zunächst verstehen, wer OpenAI ist.
OpenAI hat seinen Hauptsitz in San Francisco und wurde 2015 von Teslas Musk, Sam Altman und anderen Investoren mitgegründet. Ziel ist die Entwicklung von KI-Technologie, die der gesamten Menschheit zugute kommt. Musk verließ das Unternehmen 2018 aufgrund von Differenzen in der Entwicklungsrichtung des Unternehmens.
Zuvor war OpenAI für die Einführung der GPT-Reihe von Modellen zur Verarbeitung natürlicher Sprache bekannt. Seit 2018 veröffentlicht OpenAI das generative vortrainierte Sprachmodell GPT (Generative Pre-trained Transformer), mit dem verschiedene Inhalte wie Artikel, Codes, maschinelle Übersetzung und Fragen und Antworten generiert werden können.
Die Anzahl der Parameter jeder Generation von GPT-Modellen ist explodiert, und man kann sagen: „Je größer, desto besser“. GPT-2, das im Februar 2019 veröffentlicht wurde, hatte 1,5 Milliarden Parameter, während GPT-3 im Mai 2020 175 Milliarden Parameter hatte.
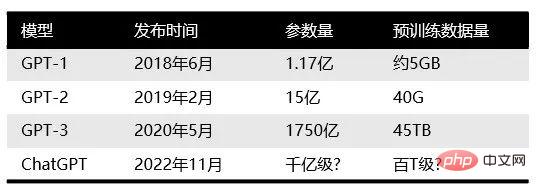
Vergleich der Hauptmodelle der GPT-Familie
▌1.2 Hauptmerkmale von ChatGPT
ChatGPT ist ein Konversations-KI-Modell, das auf der Grundlage der GPT-3.5-Architektur (Generative Pre-trained Transformer 3.5) entwickelt wurde und ein Bruder ist Modell von InstructGPT.
ChatGPT wird wahrscheinlich eine Übung von OpenAI vor dem offiziellen Start von GPT-4 sein oder zum Sammeln großer Mengen an Konversationsdaten verwendet.
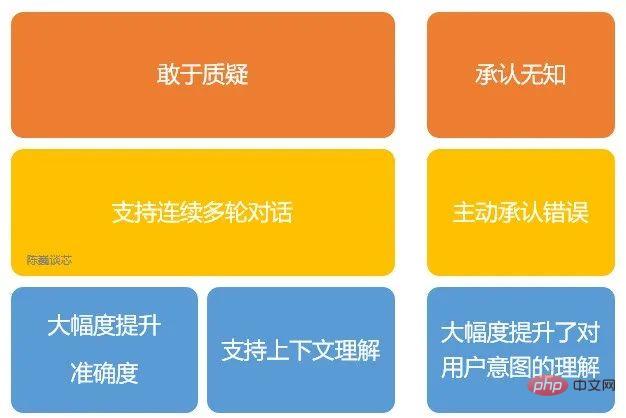
Hauptfunktionen von ChatGPT
OpenAI nutzt die RLHF-Technologie (Reinforcement Learning from Human Feedbac, Human Feedback Reinforcement Learning) zum Trainieren von ChatGPT und fügt mehr manuelle Überwachung zur Feinabstimmung hinzu.
Darüber hinaus weist ChatGPT auch folgende Eigenschaften auf:
1) Es kann proaktiv eigene Fehler eingestehen. Wenn der Benutzer auf seinen Fehler hinweist, hört das Modell zu und verfeinert die Antwort.
2) ChatGPT kann falsche Fragen hinterfragen. Auf die Frage „Was würde passieren, wenn Kolumbus 2015 in die Vereinigten Staaten käme?“ würde der Roboter beispielsweise erklären, dass Kolumbus nicht zu dieser Ära gehört, und die Ausgabe anpassen.
3) ChatGPT kann seine eigene Unwissenheit und sein mangelndes Verständnis für professionelle Technologie eingestehen.
4) Unterstützt mehrere Runden kontinuierlichen Dialogs.
Im Gegensatz zu den verschiedenen intelligenten Lautsprechern und „Verzögerern der künstlichen Intelligenz“, die jeder im Leben verwendet, merkt sich ChatGPT während des Gesprächs die Gesprächsnachrichten früherer Benutzer, dh das Kontextverständnis, um bestimmte hypothetische Fragen zu beantworten.
ChatGPT kann kontinuierliche Konversationen realisieren und so das Benutzererlebnis im Konversationsinteraktionsmodus erheblich verbessern.
Für genaue Übersetzungen (insbesondere Chinesisch und Namenstransliteration) ist ChatGPT noch lange nicht perfekt, ähnelt aber anderen Online-Übersetzungstools in Bezug auf Textflüssigkeit und Identifizierung bestimmter Namen.
Da ChatGPT ein großes Sprachmodell ist und derzeit nicht über Netzwerksuchfunktionen verfügt, kann es nur auf der Grundlage des Datensatzes antworten, über den es im Jahr 2021 verfügt.
Zum Beispiel kennt es die Situation der Fußballweltmeisterschaft 2022 nicht und antwortet nicht, wie das Wetter heute ist, oder hilft Ihnen bei der Suche nach Informationen wie Apples Siri. Wenn ChatGPT selbst online nach Lernmaterialien und Wissen suchen kann, wird es schätzungsweise noch größere Durchbrüche geben.
Auch wenn das erlernte Wissen begrenzt ist, kann ChatGPT dennoch viele seltsame Fragen von Menschen mit offenem Geist beantworten. Um zu verhindern, dass sich ChatGPT schlechte Gewohnheiten aneignet, wird ChatGPT durch Algorithmen geschützt, um schädliche und irreführende Trainingseingaben zu reduzieren.
Anfragen werden über die Moderations-API gefiltert und potenziell rassistische oder sexistische Hinweise werden abgewiesen.
2. Das Prinzip von ChatGPT/GPT
▌2.1 NLP
Zu den bekannten Einschränkungen im NLP/NLU-Bereich gehören wiederholter Text und hochspezialisierte Missverständnisse des Themas und Missverständnis der kontextuellen Phrase.
Für Menschen oder KI braucht es normalerweise jahrelanges Training, um ein normales Gespräch zu führen.
NLP-ähnliche Modelle müssen nicht nur die Bedeutung von Wörtern verstehen, sondern auch verstehen, wie man Sätze bildet und kontextbedeutende Antworten gibt, selbst unter Verwendung geeigneter Umgangssprache und Fachvokabulars.
Anwendungsfelder der NLP-Technologie
Im Wesentlichen GPT-3 oder GPT-3.5, die die Grundlage von ChatGPT bilden, ist ein sehr großes statistisches Sprachmodell oder ein sequentielles Textvorhersagemodell.
▌2.2 GPT vs. BERT
Ähnlich wie das BERT-Modell generiert ChatGPT oder GPT-3.5 automatisch jedes Wort der Antwort basierend auf dem Eingabesatz und der Sprach-/Korpuswahrscheinlichkeit ( Wort).
Aus mathematischer oder maschineller Lernperspektive ist ein Sprachmodell eine Modellierung der Wahrscheinlichkeitskorrelationsverteilung von Wortfolgen, also unter Verwendung gesagter Aussagen (Aussagen können in der Mathematik als Vektoren betrachtet werden). als Eingabebedingungen, um die Wahrscheinlichkeitsverteilung des Auftretens verschiedener Sätze oder sogar Sprachmengen im nächsten Moment vorherzusagen.
ChatGPT wird mithilfe von Reinforcement Learning aus menschlichem Feedback trainiert, einer Methode, die maschinelles Lernen durch menschliches Eingreifen ergänzt, um bessere Ergebnisse zu erzielen.
Während des Trainingsprozesses übernimmt der menschliche Trainer die Rolle des Benutzers und Assistenten der künstlichen Intelligenz und wird durch den proximalen Strategieoptimierungsalgorithmus verfeinert.
Aufgrund der stärkeren Leistung und der umfangreichen Parameter von ChatGPT enthält es mehr Themendaten und kann mehr Nischenthemen verarbeiten.
ChatGPT kann jetzt weitere Aufgaben wie das Beantworten von Fragen, das Schreiben von Artikeln, das Zusammenfassen von Texten, die Sprachübersetzung und das Generieren von Computercode erledigen.
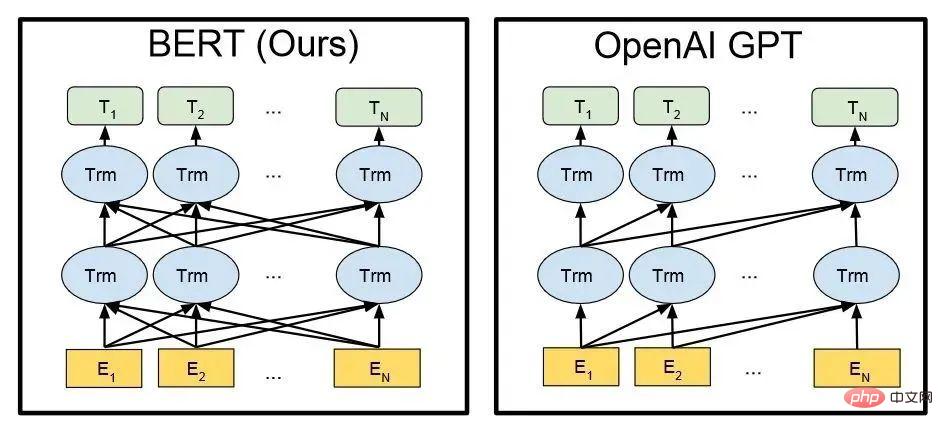
Die technische Architektur von BERT und GPT (En im Bild ist jedes Wort der Eingabe, Tn ist jedes Wort der Ausgabeantwort) #🎜 🎜#
3. Die technische Architektur von ChatGPT ▌3.1 Die Entwicklung der GPT-Familie Wenn wir von ChatGPT sprechen, müssen wir die GPT-Familie erwähnen. ChatGPT hatte zuvor mehrere bekannte Brüder, darunter GPT-1, GPT-2 und GPT-3. Jeder dieser Brüder ist größer als der andere und ChatGPT ähnelt eher GPT-3.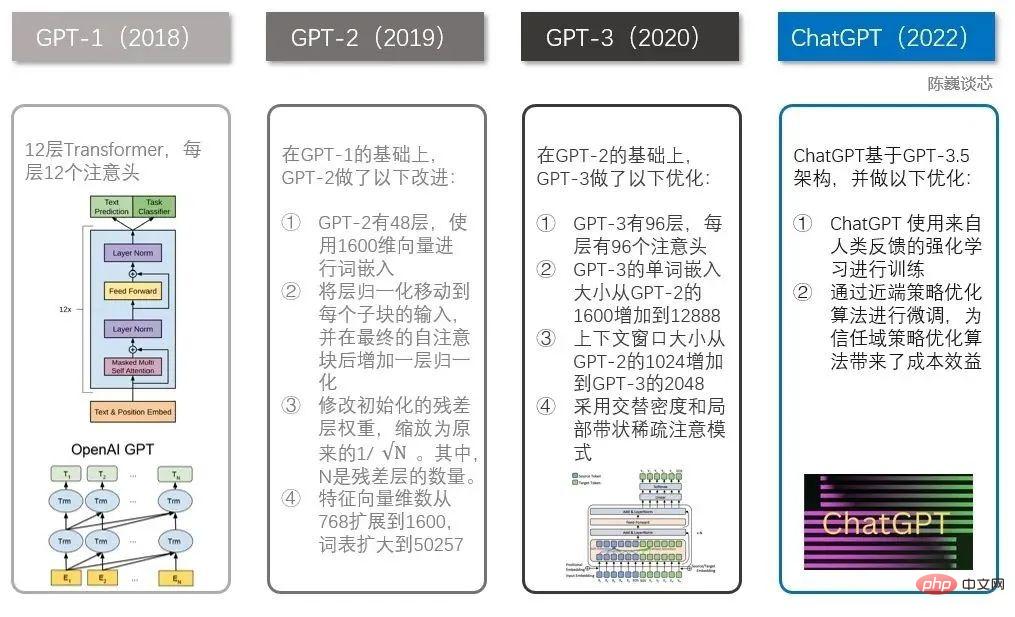
- Authentizität: Handelt es sich um falsche oder irreführende Informationen?
- Unschädlichkeit: Verursacht es körperliche oder geistige Schäden für Menschen oder die Umwelt?
- Nützlichkeit: Löst es die Aufgabe des Benutzers?
▌3.3 TAMER-Framework
Ich muss das TAMER-Framework (Training an Agent Manually via Evaluative Reinforcement) erwähnen.
Dieses Framework führt menschliche Markierungen in den Lernzyklus von Agenten ein und kann Agenten durch Menschen Belohnungsfeedback geben (d. h. Agenten beim Training anleiten), wodurch die Ziele der Trainingsaufgabe schnell erreicht werden.
Der Hauptzweck der Einführung menschlicher Etikettierer besteht darin, das Training zu beschleunigen. Obwohl die Reinforcement-Learning-Technologie in vielen Bereichen hervorragende Leistungen erbringt, weist sie immer noch viele Mängel auf, wie z. B. eine langsame Trainingskonvergenzgeschwindigkeit und hohe Trainingskosten.
Besonders in der realen Welt sind bei vielen Aufgaben hohe Erkundungs- oder Datenerfassungskosten anfallen. Wie die Trainingseffizienz beschleunigt werden kann, ist eines der wichtigen Probleme, die bei den heutigen Aufgaben des verstärkenden Lernens gelöst werden müssen.
TAMER kann das Wissen menschlicher Tagger nutzen, um den Agenten in Form von Belohnungsschreiben-Feedback zu schulen und so seine schnelle Konvergenz zu beschleunigen.
TAMER erfordert vom Tagger keine Fachkenntnisse oder Programmierkenntnisse und die Korpuskosten sind geringer. Mit TAMER+RL (Reinforcement Learning) kann der Prozess des Reinforcement Learning (RL) aus Belohnungen des Markov-Entscheidungsprozesses (MDP) durch Feedback von menschlichen Markern verbessert werden.
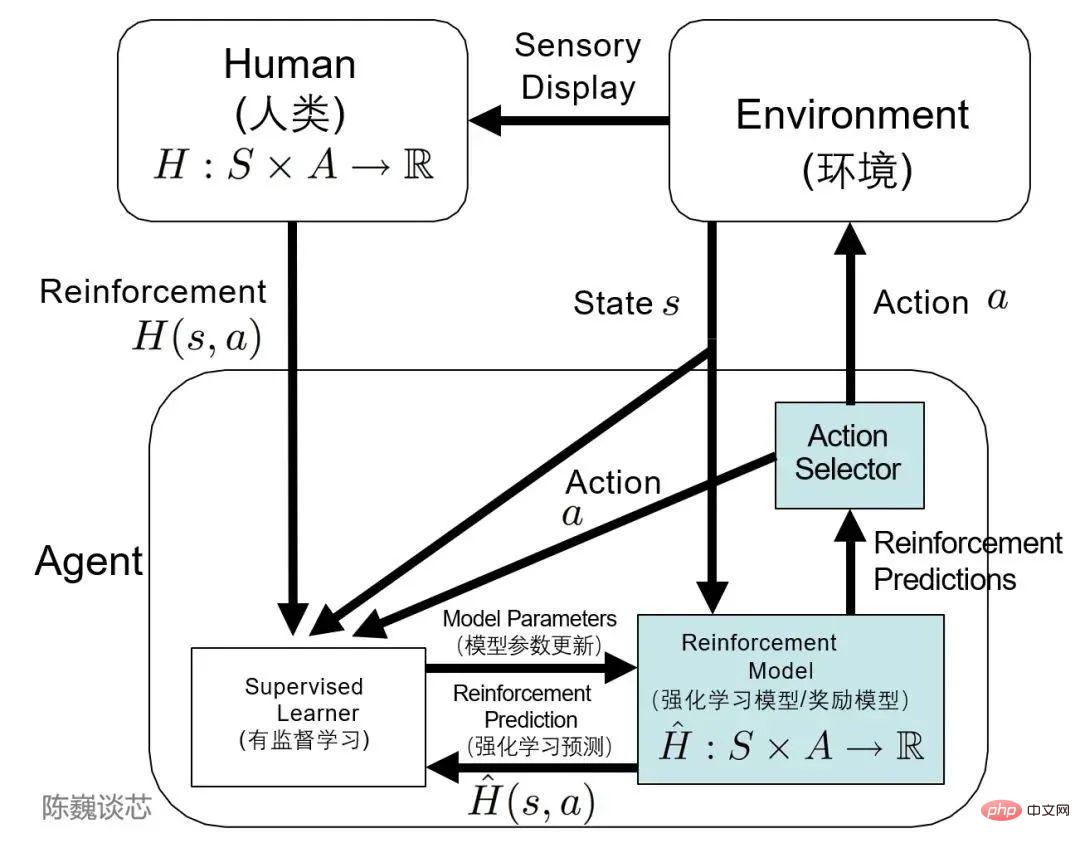
Anwendung der TAMER-Architektur beim verstärkenden Lernen
In Bezug auf die spezifische Implementierung fungieren menschliche Labelersteller als Konversationsnutzer und Assistenten der künstlichen Intelligenz, stellen Gesprächsbeispiele bereit, lassen das Modell einige Antworten generieren, und dann bewerten und bewerten die Labeler die Antwortoptionen, um bessere Ergebnisse in das Modell einzuspeisen.
Agenten lernen aus zwei Feedback-Modi gleichzeitig – menschliche Verstärkung und Markov-Entscheidungsprozess-Belohnung als integriertes System, das das Modell durch Belohnungsstrategien verfeinert und kontinuierlich iteriert.
Auf dieser Basis kann ChatGPT menschliche Sprache oder Anweisungen besser verstehen und vervollständigen als GPT-3, Menschen imitieren und kohärente und logische Textinformationen bereitstellen.
▌3.4 Training von ChatGPT
Der Trainingsprozess von ChatGPT ist in die folgenden drei Phasen unterteilt:
Die erste Phase: Training des überwachten Richtlinienmodells
GPT 3.5 selbst ist schwierig, die unterschiedlichen Absichten zu verstehen, die in verschiedenen Arten von enthalten sind Es ist zudem sehr schwierig zu beurteilen, ob es sich bei den generierten Inhalten um ein qualitativ hochwertiges Ergebnis handelt.
Damit GPT 3.5 zunächst die Absicht hat, Anweisungen zu verstehen, werden zunächst Fragen zufällig aus dem Datensatz ausgewählt und menschliche Annotatoren geben qualitativ hochwertige Antworten. Anschließend werden diese manuell annotierten Daten zur Feinabstimmung verwendet GPT-3.5-Modell (SFT-Modell erhalten, überwachte Feinabstimmung).
Das SFT-Modell ist derzeit beim Befolgen von Anweisungen/Gesprächen bereits besser als GPT-3, entspricht jedoch nicht unbedingt den menschlichen Vorlieben.
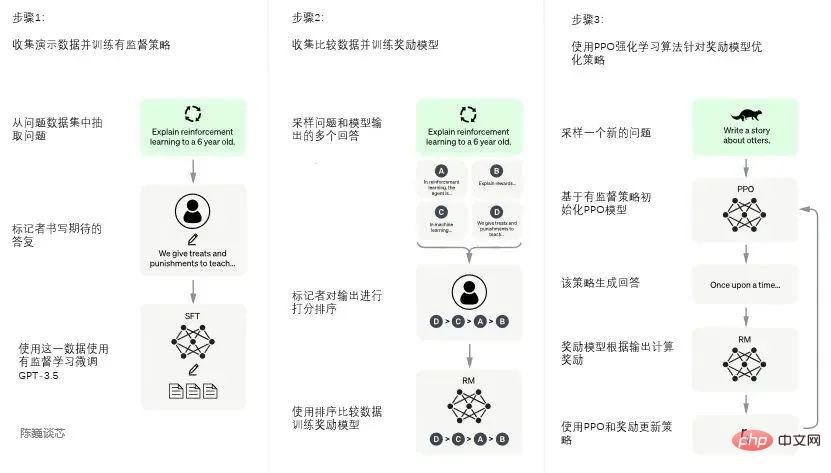
ChatGPT-Modell-Trainingsprozess
Zweite Stufe: Belohnungsmodell trainieren (Belohnungsmodus, RM)
Diese Stufe trainiert hauptsächlich das Belohnungsmodell durch manuelle Annotation von Trainingsdaten (ca. 33.000 Daten).
Wählen Sie zufällig Fragen aus dem Datensatz aus und verwenden Sie das in der ersten Stufe generierte Modell, um für jede Frage mehrere unterschiedliche Antworten zu generieren. Menschliche Annotatoren berücksichtigen diese Ergebnisse und geben eine Rangfolge vor. Dieser Prozess ähnelt einem Coaching oder Mentoring.
Als nächstes verwenden Sie diese Ranking-Ergebnisdaten, um das Belohnungsmodell zu trainieren. Mehrere Sortierergebnisse werden paarweise kombiniert, um mehrere Trainingsdatenpaare zu bilden.
Das RM-Modell akzeptiert eine Eingabe und vergibt eine Punktzahl, um die Qualität der Antwort zu bewerten. Auf diese Weise werden für ein Paar Trainingsdaten die Parameter so angepasst, dass qualitativ hochwertige Antworten höher bewertet werden als Antworten geringer Qualität.
Die dritte Stufe: Verwenden Sie PPO-Verstärkungslernen (Proximal Policy Optimization, proximale Richtlinienoptimierung), um die Strategie zu optimieren.
Die Kernidee von PPO besteht darin, den On-Policy-Trainingsprozess in Policy Gradient in Off-Policy-Training umzuwandeln, das heißt, Online-Lernen in Offline-Lernen umzuwandeln. Dieser Transformationsprozess wird als Importance Sampling bezeichnet.
Diese Stufe verwendet das in der zweiten Stufe trainierte Belohnungsmodell und stützt sich auf Belohnungswerte, um die Parameter des vorab trainierten Modells zu aktualisieren. Wählen Sie nach dem Zufallsprinzip Fragen aus dem Datensatz aus, verwenden Sie das PPO-Modell, um Antworten zu generieren, und verwenden Sie das in der vorherigen Phase trainierte RM-Modell, um Qualitätsbewertungen zu erhalten.
Übertragen Sie die Belohnungswerte nacheinander, erzeugen Sie so einen Richtliniengradienten und aktualisieren Sie die PPO-Modellparameter durch verstärkendes Lernen.
Wenn wir die zweite und dritte Stufe weiterhin wiederholen, wird durch Iteration ein ChatGPT-Modell mit höherer Qualität trainiert.
4. Einschränkungen von ChatGPT
Solange der Benutzer eine Frage eingibt, kann ChatGPT diese nicht mehr mit Schlüsselwörtern an Google oder Baidu weiterleiten und wir können sofort die gewünschte Antwort erhalten?
Obwohl ChatGPT hervorragende kontextbezogene Dialogfähigkeiten und sogar Programmierfähigkeiten bewiesen hat und die Transformation des öffentlichen Eindrucks von Mensch-Maschine-Dialogrobotern (ChatBot) von „künstlich zurückgeblieben“ zu „interessant“ abgeschlossen hat, müssen wir auch sehen, dass die ChatGPT-Technologie immer noch vorhanden ist weist einige Einschränkungen auf. Die Einschränkungen werden immer noch verbessert.
1) ChatGPT mangelt es an „menschlichem gesunden Menschenverstand“ und Erweiterungsmöglichkeiten in Bereichen, in denen es nicht mit einer großen Menge an Korpus trainiert wurde, und es kann sogar ernsthaften „Unsinn“ sprechen. ChatGPT kann in vielen Bereichen „Antworten erstellen“, aber wenn Benutzer nach richtigen Antworten suchen, kann ChatGPT auch irreführende Antworten geben. Lassen Sie ChatGPT beispielsweise eine Bewerbungsfrage für die Grundschule erstellen. Obwohl es eine lange Reihe von Berechnungsprozessen schreiben kann, ist die endgültige Antwort falsch.
Sollten wir dann den Ergebnissen von ChatGPT glauben oder nicht?
2) ChatGPT kann mit komplexen, langwierigen oder besonders professionellen Sprachstrukturen nicht umgehen. Bei Fragen aus sehr speziellen Bereichen wie Finanzen, Naturwissenschaften oder Medizin kann ChatGPT möglicherweise keine passenden Antworten generieren, wenn nicht genügend Korpus-„Feeding“ vorhanden ist.
3) ChatGPT benötigt eine sehr große Menge an Rechenleistung (Chips), um seine Schulung und Bereitstellung zu unterstützen. Unabhängig davon, dass zum Trainieren des Modells eine große Menge an Korpusdaten erforderlich ist, erfordert die Anwendung von ChatGPT derzeit noch die Unterstützung von Servern mit großer Rechenleistung, und die Kosten dieser Server liegen außerhalb der Reichweite normaler Benutzer Ein Modell mit Milliarden von Parametern erfordert eine enorme Menge an Rechenressourcen zum Ausführen und Trainieren. Wenn jedoch Hunderte Millionen Benutzeranfragen von echten Suchmaschinen eingehen und die derzeit beliebte kostenlose Strategie übernommen wird, wird es für jedes Unternehmen schwierig sein, diese Kosten zu tragen. Daher muss die breite Öffentlichkeit immer noch auf leichtere Modelle oder kostengünstigere Computerplattformen warten.
4) ChatGPT war noch nicht in der Lage, neues Wissen online zu integrieren, und es ist unrealistisch, das GPT-Modell erneut zu trainieren, wenn neues Wissen auftaucht. Unabhängig davon, ob es sich um Schulungszeit oder Schulungskosten handelt, ist es für normale Trainer schwierig, dies zu akzeptieren . Wenn wir ein Online-Schulungsmodell für neues Wissen übernehmen, scheint dies machbar und die Korpuskosten sind relativ niedrig, aber es kann leicht zu dem Problem führen, dass das ursprüngliche Wissen aufgrund der Einführung neuer Daten katastrophal vergessen wird.
5) ChatGPT ist immer noch ein Black-Box-Modell. Derzeit kann die interne Algorithmuslogik von ChatGPT nicht zerlegt werden, daher gibt es keine Garantie dafür, dass ChatGPT keine Anweisungen generiert, die Benutzer angreifen oder sogar schädigen.
Natürlich werden die Mängel nicht verschwiegen. Einige Ingenieure haben ChatGPT in einem Gespräch gebeten, Verilog-Code (Chip-Design-Code) zu schreiben. Es ist ersichtlich, dass das Niveau von ChatGPT das Niveau einiger Verilog-Anfänger übertroffen hat. 5. Zukünftige Verbesserungsrichtungen von ChatGPT .
Die Mitglieder des Gründungsteams von Anthropic sind größtenteils frühe und wichtige Mitarbeiter von OpenAI und haben an OpenAIs GPT-3, multimodalen Neuronen, Lernen zur Verstärkung menschlicher Präferenzen usw. teilgenommen. 
CAI-Modelltrainingsprozess
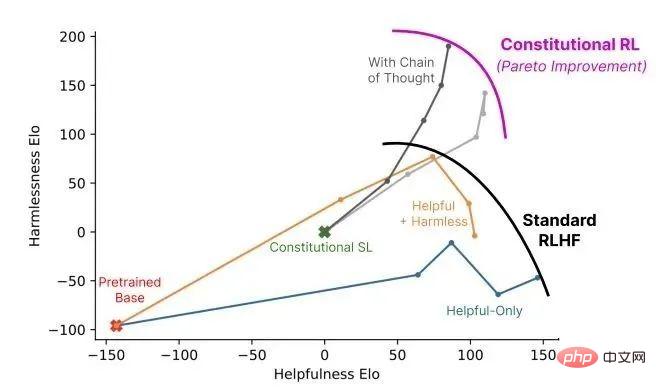
Sowohl Claude als auch ChatGPT verlassen sich auf Reinforcement Learning (RL), um Präferenzmodelle zu trainieren. CAI (Constitutional AI) basiert ebenfalls auf RLHF. Der Unterschied besteht darin, dass der Ranking-Prozess von CAI Modelle (und nicht Menschen) verwendet, um ein erstes Ranking-Ergebnis für alle generierten Ausgabeergebnisse bereitzustellen.
CAI nutzt das Feedback künstlicher Intelligenz, um menschliche Präferenzen für harmlose Ausdrücke zu ersetzen, d. h. RLAIF bewertet Antwortinhalte auf der Grundlage einer Reihe verfassungsrechtlicher Grundsätze.
▌5.2 Machen Sie die Mängel in Mathematik wett
ChatGPT verfügt über starke Konversationsfähigkeiten, aber es ist leicht, in Gesprächen über mathematische Berechnungen ernsthaften Unsinn zu reden.
Der Informatiker Stephen Wolfram hat eine Lösung für dieses Problem vorgeschlagen. Stephen Wolfram hat die Wolfram-Sprach- und Computer-Wissenssuchmaschine Wolfram|Alpha erstellt, deren Backend durch Mathematica implementiert wird.
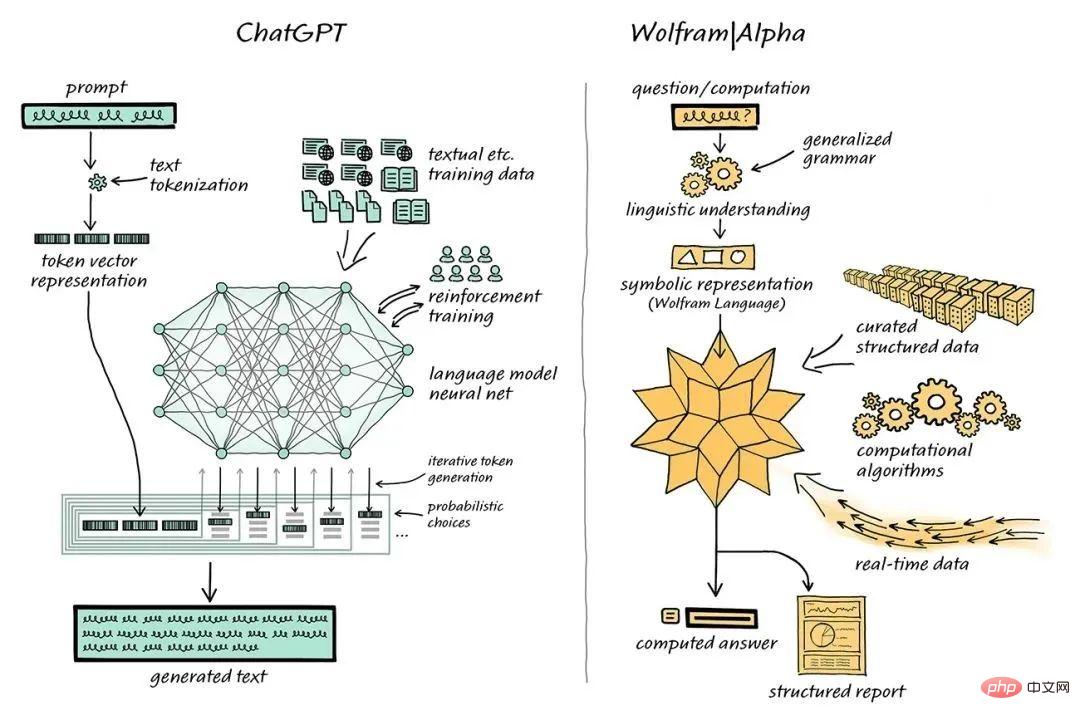
ChatGPT wird mit Wolfram|Alpha kombiniert, um Kämmprobleme zu lösen
In diesem kombinierten System kann ChatGPT mit Wolfram|Alpha „sprechen“, genau wie Menschen, die Wolfram|Alpha verwenden, und Wolfram|Alpha verwendet seine Symbolübersetzung The Fähigkeit, von ChatGPT erhaltene natürliche Sprachausdrücke in die entsprechende symbolische Computersprache zu „übersetzen“.
In der Vergangenheit gab es in der akademischen Gemeinschaft Meinungsverschiedenheiten über die von ChatGPT verwendeten „statistischen Methoden“ und die „symbolischen Methoden“ von Wolfram|Alpha.
Aber jetzt hat die Komplementarität von ChatGPT und Wolfram|Alpha dem NLP-Bereich die Möglichkeit gegeben, ihn auf die nächste Ebene zu heben.
ChatGPT muss solchen Code nicht generieren, es muss lediglich eine reguläre natürliche Sprache generieren und diese dann mit Wolfram|Alpha in die präzise Wolfram Language übersetzen, und dann führt die zugrunde liegende Mathematica Berechnungen durch.
▌5.3 Miniaturisierung von ChatGPT
Obwohl ChatGPT leistungsstark ist, schrecken seine Modellgröße und Nutzungskosten auch viele Menschen ab.
Es gibt drei Arten der Modellkomprimierung, die die Modellgröße und -kosten reduzieren können.
Die erste Methode ist die Quantisierung, die die Genauigkeit der numerischen Darstellung eines einzelnen Gewichts verringert. Beispielsweise hat ein Downgrade von Tansformer von FP32 auf INT8 kaum Auswirkungen auf die Genauigkeit.
Die zweite Methode der Modellkomprimierung ist das Pruning, bei dem Netzwerkelemente, einschließlich Kanäle, von einzelnen Gewichten (unstrukturiertes Pruning) zu Komponenten mit höherer Granularität wie Gewichtsmatrizen entfernt werden. Dieser Ansatz ist bei Vision- und kleineren Sprachmodellen effektiv.
Die dritte Modellkomprimierungsmethode ist die Sparsifizierung. Beispielsweise kann SparseGPT (arxiv.org/pdf/2301.0077), vorgeschlagen vom Österreichischen Institut für Wissenschaft und Technologie (ISTA), das GPT-Serienmodell in einem einzigen Schritt ohne Umschulung auf 50 % Sparsity beschneiden. Beim Modell GPT-175B kann diese Bereinigung mit nur einer einzigen GPU in wenigen Stunden erreicht werden.
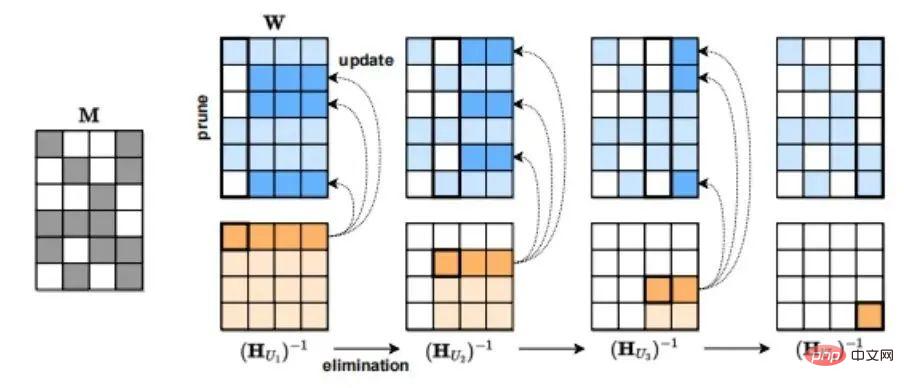
SparseGPT-Komprimierungsprozess
6. Die industrielle Zukunft und Investitionsmöglichkeiten von ChatGPT
▌6.1 AIGC
Wenn es um ChaGPT geht, müssen wir AIGC erwähnen.
AIGC nutzt Technologie der künstlichen Intelligenz, um Inhalte zu generieren. Im Vergleich zu UGC (benutzergenerierter Inhalt) und PGC (professionell produzierter Inhalt) in den vorherigen Web1.0- und Web2.0-Ära stellt AIGC, das auf künstlicher Intelligenz konzipierte Inhalte darstellt, eine neue Runde von Änderungen der Inhaltsproduktionsmethode dar, und AIGC Der Inhalt befindet sich in Web3. Auch in der 0-Ära wird es ein exponentielles Wachstum geben.
Das Aufkommen des ChatGPT-Modells ist für die Anwendung von AIGC im Text-/Sprachmodus von großer Bedeutung und wird erhebliche Auswirkungen auf die vor- und nachgelagerte KI-Branche haben.
▌6.2 Nutzenszenarien
Aus der Perspektive nachgelagerter Nutzenanwendungen, einschließlich, aber nicht beschränkt auf codefreie Programmierung, Romangenerierung, Konversationssuchmaschinen, Sprachbegleiter, Spracharbeitsassistenten, konversationsorientierte virtuelle Menschen, Kundenservice mit künstlicher Intelligenz, maschinelle Übersetzung, Chip-Design usw.
Aus der Perspektive der gestiegenen Nachfrage aus dem Upstream, einschließlich Computerchips, Datenannotation, Verarbeitung natürlicher Sprache (NLP) usw. 🔜 mehr Felder, wodurch mehr und bessere Gespräche und Inhalte für Menschen generiert werden.
Abschließend fragte der Autor nach dem Status der integrierten Speicher- und Computertechnologie im Bereich ChatGPT (der Autor konzentriert sich derzeit auf die Förderung der Implementierung integrierter Speicher- und Computerchips und sagte mutig voraus, dass integrierter Speicher und Die Computertechnologie wird den Status von ChatGPT-Chips dominieren. (Hat mein Herz gewonnen)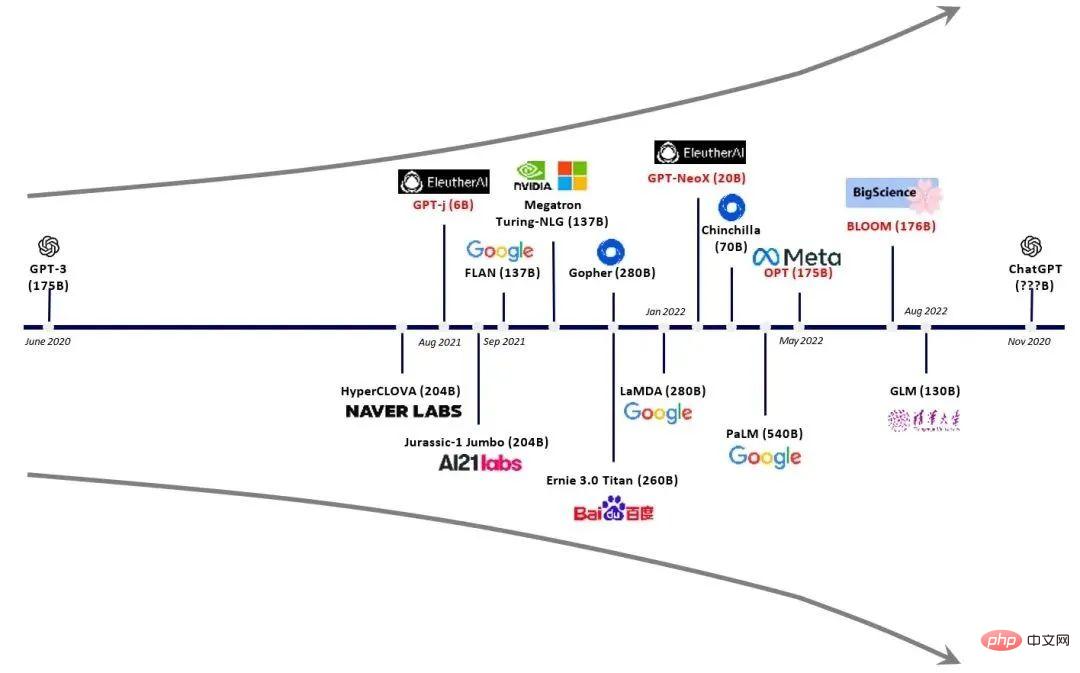
- ChatGPT: Optimierung von Sprachmodellen für den Dialog. ChatGPT: Optimierung von Sprachmodellen für den Dialog Sprachmodelle zum Befolgen von Anweisungen mit menschlichem Feedback /~ai-lab/p
- TAMER框架论文:Interaktive Gestaltung von Agenten durch menschliche Verstärkung cs.utexas.edu/~bradknox
- PPO算法:Proximale Richtlinienoptimierungsalgorithmen Proximale Richtlinienoptimierungsalgorithmen
Das obige ist der detaillierte Inhalt vonInteressanter Vortrag über die Prinzipien und Algorithmen von ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Analyse der Funktion und des Prinzips von Nohup
Mar 25, 2024 pm 03:24 PM
Analyse der Funktion und des Prinzips von Nohup
Mar 25, 2024 pm 03:24 PM
Analyse der Rolle und des Prinzips von nohup In Unix und Unix-ähnlichen Betriebssystemen ist nohup ein häufig verwendeter Befehl, mit dem Befehle im Hintergrund ausgeführt werden können. Selbst wenn der Benutzer die aktuelle Sitzung verlässt oder das Terminalfenster schließt, kann der Befehl ausgeführt werden werden weiterhin ausgeführt. In diesem Artikel werden wir die Funktion und das Prinzip des Nohup-Befehls im Detail analysieren. 1. Die Rolle von Nohup: Befehle im Hintergrund ausführen: Mit dem Befehl Nohup können wir Befehle mit langer Laufzeit weiterhin im Hintergrund ausführen lassen, ohne dass dies dadurch beeinträchtigt wird, dass der Benutzer die Terminalsitzung verlässt. Dies muss ausgeführt werden
 Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Die unterste Ebene der C++-Sortierfunktion verwendet die Zusammenführungssortierung, ihre Komplexität beträgt O(nlogn) und bietet verschiedene Auswahlmöglichkeiten für Sortieralgorithmen, einschließlich schneller Sortierung, Heap-Sortierung und stabiler Sortierung.
 Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Die Konvergenz von künstlicher Intelligenz (KI) und Strafverfolgung eröffnet neue Möglichkeiten zur Kriminalprävention und -aufdeckung. Die Vorhersagefähigkeiten künstlicher Intelligenz werden häufig in Systemen wie CrimeGPT (Crime Prediction Technology) genutzt, um kriminelle Aktivitäten vorherzusagen. Dieser Artikel untersucht das Potenzial künstlicher Intelligenz bei der Kriminalitätsvorhersage, ihre aktuellen Anwendungen, die Herausforderungen, denen sie gegenübersteht, und die möglichen ethischen Auswirkungen der Technologie. Künstliche Intelligenz und Kriminalitätsvorhersage: Die Grundlagen CrimeGPT verwendet Algorithmen des maschinellen Lernens, um große Datensätze zu analysieren und Muster zu identifizieren, die vorhersagen können, wo und wann Straftaten wahrscheinlich passieren. Zu diesen Datensätzen gehören historische Kriminalstatistiken, demografische Informationen, Wirtschaftsindikatoren, Wettermuster und mehr. Durch die Identifizierung von Trends, die menschliche Analysten möglicherweise übersehen, kann künstliche Intelligenz Strafverfolgungsbehörden stärken
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 SearchGPT: Open AI tritt mit seiner eigenen KI-Suchmaschine gegen Google an
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI tritt mit seiner eigenen KI-Suchmaschine gegen Google an
Jul 30, 2024 am 09:58 AM
Open AI macht endlich seinen Vorstoß in die Suche. Das Unternehmen aus San Francisco hat kürzlich ein neues KI-Tool mit Suchfunktionen angekündigt. The Information berichtete erstmals im Februar dieses Jahres über das neue Tool, das treffend SearchGPT heißt und über ein c
