
 Technologie-Peripheriegeräte
KI
Google optimiert das Diffusionsmodell. Samsung-Mobiltelefone nutzen Stable Diffusion und erzeugen Bilder in 12 Sekunden.
Technologie-Peripheriegeräte
KI
Google optimiert das Diffusionsmodell. Samsung-Mobiltelefone nutzen Stable Diffusion und erzeugen Bilder in 12 Sekunden.
Google optimiert das Diffusionsmodell. Samsung-Mobiltelefone nutzen Stable Diffusion und erzeugen Bilder in 12 Sekunden.

Stable Diffusion ist im Bereich der Bildgenerierung ebenso bekannt wie ChatGPT im großen Konversationsmodell. Es ist in der Lage, innerhalb von zehn Sekunden realistische Bilder eines beliebigen Eingabetextes zu erstellen. Da Stable Diffusion über mehr als 1 Milliarde Parameter verfügt und die Rechen- und Speicherressourcen auf dem Gerät begrenzt sind, wird dieses Modell hauptsächlich in der Cloud ausgeführt.
Ohne sorgfältiges Design und Implementierung kann die Ausführung dieser Modelle auf dem Gerät aufgrund des iterativen Rauschunterdrückungsprozesses und des verursachten übermäßigen Speicherverbrauchs zu einer erhöhten Latenz führen.
Wie man Stable Diffusion auf der Geräteseite ausführt, hat das Forschungsinteresse aller geweckt. Zuvor entwickelte ein Forscher eine Anwendung, die Stable auf dem iPhone 14 Pro Diffusion verwendet Die Generierung von Bildern dauert eine Minute und benötigt etwa 2 GB Anwendungsspeicher.
Apple hat auch hier einige Optimierungen vorgenommen. Sie können ein Bild mit einer Auflösung von 512x512 in einer halben Minute auf iPhone, iPad, Mac und anderen Geräten erzeugen. Qualcomm folgt dicht dahinter und führt Stable Diffusion v1.5 auf Android-Telefonen aus und erzeugt Bilder mit einer Auflösung von 512 x 512 in weniger als 15 Sekunden.
Kürzlich haben sie in einem von Google veröffentlichten Artikel „Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations“ erreicht Durch die Ausführung von Stable Diffusion 1.4 auf einem GPU-gesteuerten Gerät wird eine SOTA-Inferenzlatenzleistung erreicht (die Generierung eines 512 × 512-Bildes in 20 Iterationen dauert auf einem Samsung S23 Ultra nur 11,5 Sekunden). Darüber hinaus ist diese Studie nicht spezifisch für ein Gerät, sondern ein allgemeiner Ansatz, der auf die Verbesserung aller potenziellen Diffusionsmodelle anwendbar ist.
Diese Forschung eröffnet viele Möglichkeiten, generative KI lokal auf Ihrem Telefon auszuführen, ohne eine Datenverbindung oder einen Cloud-Server. Stable Diffusion wurde erst letzten Herbst veröffentlicht und kann bereits heute an Geräte angeschlossen und ausgeführt werden, was zeigt, wie schnell sich dieser Bereich entwickelt.

Papieradresse: https://arxiv.org/pdf/2304.11267.pdf#🎜 🎜#
Um diese Generierungsgeschwindigkeit zu erreichen, hat Google einige Optimierungsvorschläge vorgelegt. Schauen wir uns an, wie Google optimiert.
MethodeneinführungDiese Forschung zielt darauf ab, Optimierungsmethoden vorzuschlagen, um die Geschwindigkeit großräumiger Diffusionsmodell-Vincentian-Diagramme zu verbessern, darunter einige Optimierungen werden für die stabile Diffusion vorgeschlagen. Es wird empfohlen, diese Optimierungsvorschläge auch auf andere Diffusionsmodelle im großen Maßstab anzuwenden.
Schauen wir uns zunächst die Hauptkomponenten der stabilen Diffusion an, darunter: Texteinbetter (Texteinbetter), Rauscherzeugung (Rauscherzeugung), Entrauschen neuronaler Netzwerke ( Entrauschen) neuronales Netzwerk) und Bilddecoder, wie in Abbildung 1 unten gezeigt 🎜#Dann schauen wir uns speziell die drei von der Studie vorgeschlagenen Optimierungsmethoden an #
Die Gruppennormalisierungsmethode (GN) funktioniert, indem sie die Kanäle der Feature-Map in kleinere Gruppen aufteilt und jede Gruppe unabhängig normalisiert, wodurch GN weniger und mehr von der Stapelgröße abhängt Geeignet für verschiedene Stapelgrößen und Netzwerkarchitekturen. In dieser Studie wurden die Vorgänge Umformung, Mittelung, Varianz und Normalisierung nicht der Reihe nach durchgeführt, sondern ein einzigartiger A-Kernel in Form eines GPU-Shaders entwickelt, der alle diese Vorgänge in einem einzigen ausführen kann GPU-Befehl ohne die Notwendigkeit von Zwischentensoren. GELU enthält als häufig verwendete Modellaktivierungsfunktion eine große Anzahl numerischer Berechnungen, wie z. B. Multiplikation, Addition und Gaußsche Fehlerfunktionen Berechnungen und die dazugehörigen Teilungs- und Multiplikationsoperationen, sodass sie in einem einzigen AI während des Zeichnungsaufrufs ausgeführt werden könnenDer Text-zu-Bild-Transformator in Stable Diffusion hilft bei der Modellierung bedingter Verteilungen, was für Aufgaben zur Text-zu-Bild-Generierung von entscheidender Bedeutung ist. Selbst-/Kreuzaufmerksamkeitsmechanismen stoßen jedoch aufgrund der Speicherkomplexität und der Zeitkomplexität auf Schwierigkeiten bei der Verarbeitung langer Sequenzen. Auf dieser Grundlage schlägt diese Studie zwei Optimierungsmethoden vor, um den rechnerischen Engpass zu verringern.
Um einerseits zu vermeiden, dass die gesamte Softmax-Berechnung auf einer großen Matrix durchgeführt wird, verwendet diese Forschung einen GPU-Shader, um den Rechenvorgang zu reduzieren, was die Rechenoperationen erheblich reduziert Speicherbedarf von Zwischentensoren und Gesamtverzögerung ist in Abbildung 2 dargestellt.

Andererseits verwendet diese Studie FlashAttention [7] Dieses IO Durch den Wahrnehmungspräzisions-Aufmerksamkeitsalgorithmus ist die Anzahl der Zugriffe auf den Speicher mit hoher Bandbreite (HBM) geringer als beim Standard-Aufmerksamkeitsmechanismus, wodurch die Gesamteffizienz verbessert wird.
Winograd-Faltung
Winograd-Faltung führt die Faltungsoperation Konvertieren aus zu einer Reihe von Matrixmultiplikationen. Diese Methode kann viele Multiplikationsoperationen reduzieren und die Berechnungseffizienz verbessern. Dies erhöht jedoch auch den Speicherverbrauch und die numerischen Fehler, insbesondere bei der Verwendung größerer Kacheln.
Das Rückgrat von Stable Diffusion basiert stark auf 3×3-Faltungsschichten, insbesondere im Bilddecoder, wo sie 90 % ausmachen. Diese Studie bietet eine eingehende Analyse dieses Phänomens, um die potenziellen Vorteile der Verwendung von Winograd mit unterschiedlichen Kachelgrößen auf 3 × 3-Kernelfaltungen zu untersuchen. Untersuchungen haben ergeben, dass eine Kachelgröße von 4 × 4 optimal ist, da sie das beste Gleichgewicht zwischen Recheneffizienz und Speichernutzung bietet. Die Studie wurde auf verschiedenen Geräten verglichen: Samsung S23 Ultra (Adreno 740) und iPhone 14 Pro Max (A16). Die Ergebnisse des Benchmark-Tests sind in der folgenden Tabelle 1 aufgeführt: Mit jeder aktivierten Optimierung wird die Latenz schrittweise reduziert (was so verstanden werden kann, dass die Zeit zum Generieren des Bildes verkürzt wird). Konkret im Vergleich zum Ausgangswert: 52,2 % Latenzreduzierung beim Samsung S23 Ultra; 32,9 % Latenzreduzierung beim iPhone 14 Pro Max. Darüber hinaus bewertet die Studie auch die End-to-End-Latenz des Samsung S23 Ultra, indem innerhalb von 20 Entrauschungs-Iterationsschritten ein 512 × 512 Pixel großes Bild generiert wird, wodurch SOTA-Ergebnisse in weniger als 12 Sekunden erzielt werden.
Was bedeutet das für die Zukunft, wenn kleine Geräte ihre eigenen generativen KI-Modelle ausführen können? Wir können mit einer Welle rechnen. 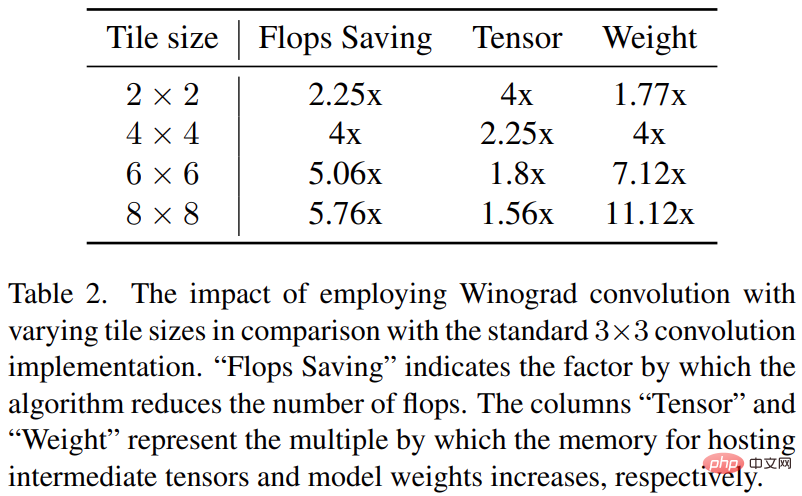
Das obige ist der detaillierte Inhalt vonGoogle optimiert das Diffusionsmodell. Samsung-Mobiltelefone nutzen Stable Diffusion und erzeugen Bilder in 12 Sekunden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
