

Heute möchte ich Ihnen einen Artikel zur Vorhersage multivariater Zeitreihen vorstellen, der 2023.1 auf arixv veröffentlicht wurde. Der Ausgangspunkt ist recht interessant: Wie kann die Fairness multivariater Zeitreihen verbessert werden? Bei den in diesem Artikel verwendeten Modellierungsmethoden handelt es sich ausschließlich um herkömmliche Operationen, die bei der Raum-Zeit-Vorhersage, der Domänenanpassung usw. verwendet wurden. Der Punkt der Fairness mehrerer Variablen ist jedoch relativ neu.

Fairnessproblem ist ein Makrokonzept im Bereich des maschinellen Lernens. Ein Verständnis von Fairness beim maschinellen Lernen ist die Konsistenz des Anpassungseffekts eines Modells auf verschiedene Stichproben. Wenn ein Modell bei einigen Stichproben gut und bei anderen Stichproben schlecht abschneidet, ist das Modell weniger fair. Ein häufiges Szenario besteht beispielsweise darin, dass in einem Empfehlungssystem der Vorhersageeffekt des Modells auf Kopfproben besser ist als der auf Schwanzproben, was die Ungerechtigkeit des Vorhersageeffekts des Modells auf verschiedene Proben widerspiegelt.
Zurück zum Problem der multivariaten Zeitreihenvorhersage: Fairness bezieht sich darauf, ob das Modell einen besseren Vorhersageeffekt auf jede Variable hat. Wenn die Vorhersagewirkung des Modells auf verschiedene Variablen sehr unterschiedlich ist, ist dieses multivariate Zeitreihenvorhersagemodell unfair. Im Beispiel in der folgenden Abbildung ist die erste Zeile der Tabelle beispielsweise die Varianz des MAE der Vorhersageeffekte verschiedener Modelle auf jede Variable. Es ist ersichtlich, dass in verschiedenen Modellen ein gewisser Grad an Ungerechtigkeit besteht. Die Sequenz im Bild unten ist ein Beispiel. Einige Sequenzen können besser vorhersagen, während andere schlechter vorhersagen können.
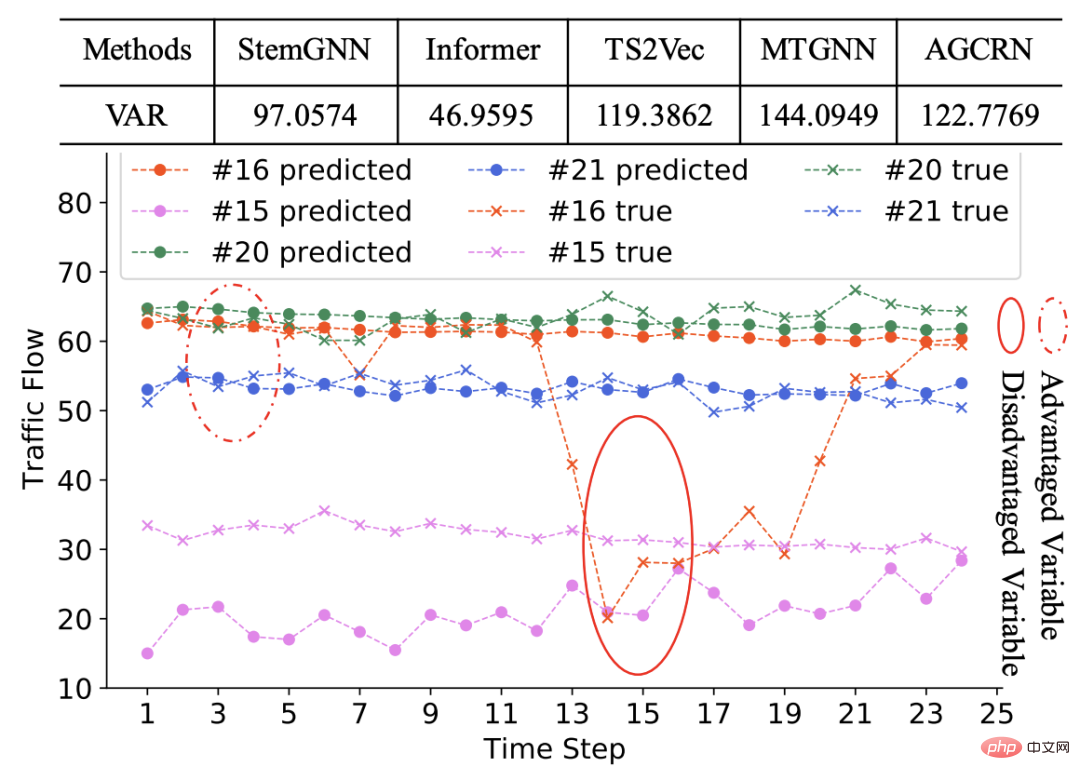
Warum kommt es zu Ungerechtigkeit? Ob in multivariaten Zeitreihen oder anderen Bereichen des maschinellen Lernens: Einer der Hauptgründe für die großen Unterschiede in den Vorhersageeffekten verschiedener Stichproben liegt darin, dass unterschiedliche Stichproben unterschiedliche Eigenschaften aufweisen und das Modell während des Trainingsprozesses möglicherweise von den Eigenschaften bestimmter Stichproben dominiert wird , was dazu führt, dass das Modell bei Stichproben, die das Training dominieren, eine gute Vorhersage macht, bei nicht dominierten Stichproben jedoch eine schlechte Vorhersage.
In multivariaten Zeitreihen können verschiedene Variablen sehr unterschiedliche Sequenzmuster aufweisen. Im obigen Beispiel sind beispielsweise die meisten Sequenzen stationär, was den Modelltrainingsprozess dominiert. Eine kleine Anzahl von Sequenzen weist jedoch eine andere Flüchtigkeit auf als andere Sequenzen, was zu einer schlechten Vorhersagewirkung des Modells auf diese Sequenzen führt.
Wie kann die Ungerechtigkeit in multivariaten Zeitreihen gelöst werden? Eine Denkweise besteht darin, dass die oben genannten Probleme gemildert werden können, da die Ungerechtigkeit durch die unterschiedlichen Merkmale verschiedener Sequenzen verursacht wird.
Dieser Artikel basiert auf dieser Idee. Die Gesamtarchitektur besteht darin, die Clustering-Methode zu verwenden, um Sequenzen mit mehreren Variablen zu gruppieren und die gegnerische Lernmethode weiter zu verwenden, um jede Gruppe von der ursprünglichen Darstellung abzutrennen Informationen, öffentliche Informationen erhalten. Durch den oben beschriebenen Prozess werden die öffentlichen Informationen und die sequenzspezifischen Informationen getrennt und die endgültige Vorhersage wird auf der Grundlage dieser beiden Informationsteile getroffen.
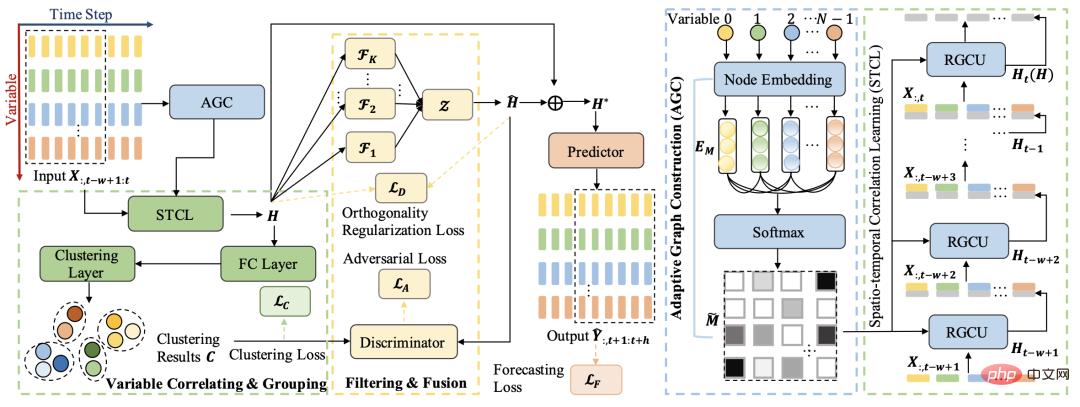
Die Gesamtmodellstruktur umfasst hauptsächlich 4 Module: Lernen mit multivariablen Sequenzbeziehungen, räumlich-zeitliches Beziehungsnetzwerk, Sequenzclustering und Zerlegungslernen.
Einer der Schlüsselpunkte multivariater Zeitreihen besteht darin, die Beziehung zwischen den einzelnen Sequenzen zu lernen. In diesem Artikel wird die räumlich-zeitliche Methode verwendet, um diese Beziehung zu lernen. Da multivariate Zeitreihen nicht mit vielen raumzeitlichen Vorhersageaufgaben vergleichbar sind, kann die Beziehung zwischen verschiedenen Variablen im Voraus definiert werden, sodass hier die automatische Lernmethode der Adjazenzmatrix verwendet wird. Die spezifische Berechnungslogik besteht darin, für jede Variable eine zufällig initialisierte Einbettung zu generieren und dann das innere Produkt der Einbettung und eine gewisse Nachbearbeitung zu verwenden, um die Beziehung zwischen den beiden Variablen als den Elementen an den entsprechenden Positionen der Adjazenzmatrix zu berechnen Die Formel lautet wie folgt:
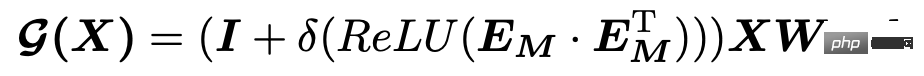
Diese Methode zum automatischen Lernen von Adjazenzmatrizen wird sehr häufig in der räumlich-zeitlichen Vorhersage verwendet, wie in Connecting the Dots: Multivariate Time Series Forecasting with Graph Neural Networks (KDD 2020), REST: Reciprocal Framework for gezeigt Spatiotemporal-Coupled Prediction (WWW 2021) und andere Artikel haben diesen Ansatz übernommen. Ich habe die prinzipielle Implementierung verwandter Modelle im Planet-Artikel KDD2020, klassisches Raum-Zeit-Vorhersagemodell, MTGNN-Codeanalyse, ausführlich vorgestellt. Interessierte Schüler können weiterlesen.
Mit der Adjazenzmatrix verwendet der Artikel ein Diagramm-Zeitreihen-Vorhersagemodell, um die Zeitreihe mit mehreren Variablen räumlich-zeitlich zu kodieren und die Darstellung jeder Variablensequenz zu erhalten. Die spezifische Modellstruktur ist DCRNN sehr ähnlich. Basierend auf GRU wird das GCN-Modul in die Berechnung jeder Einheit eingeführt. Es versteht sich, dass im Berechnungsprozess jeder Einheit der normalen GRU der Vektor des Nachbarknotens eingeführt wird, um einen GCN durchzuführen und eine aktualisierte Darstellung zu erhalten. Informationen zum Implementierungscodeprinzip von DCRNN finden Sie in diesem Artikel zur Quellcodeanalyse des DCRNN-Modells.
Nachdem die Darstellung jeder Variablenzeitreihe erhalten wurde, besteht der nächste Schritt darin, diese Darstellungen zu gruppieren, um die Gruppierung jeder Variablensequenz zu erhalten, und dann die eindeutigen Informationen jeder Variablengruppe zu extrahieren. In diesem Artikel wird die folgende Verlustfunktion eingeführt, um den Clustering-Prozess zu steuern, wobei H die Darstellung jeder Variablensequenz und F die Zugehörigkeit jeder Variablensequenz zu K Kategorien darstellt.
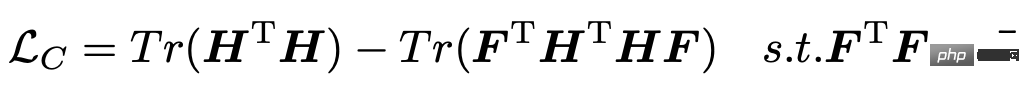
Der Aktualisierungsprozess dieser Verlustfunktion erfordert die Verwendung des EM-Algorithmus, dh das Festlegen der Sequenz zur Darstellung von H, das Optimieren von F und das Festlegen von F und das Optimieren von H. Die in diesem Artikel verwendete Methode besteht darin, SVD zu verwenden, um die Matrix F einmal zu aktualisieren, nachdem mehrere Modellrunden trainiert wurden, um die Darstellung H zu erhalten.
Der Kern des Zerlegungslernmoduls besteht darin, die öffentliche Darstellung und die private Darstellung jeder Kategorievariablen zu unterscheiden. Die öffentliche Darstellung bezieht sich auf die Merkmale, die die Variablensequenz in jedem Cluster gemeinsam hat, und die private Darstellung bezieht sich auf die Merkmale innerhalb jedes Clusters, die für Variablensequenzen einzigartig sind. Um dieses Ziel zu erreichen, übernimmt der Artikel die Ideen des Zerlegungslernens und des kontradiktorischen Lernens, um die Darstellung jedes Clusters von der ursprünglichen Sequenzdarstellung zu trennen. Die Clusterdarstellung stellt die Merkmale jeder Klasse dar, und die gestrippte Darstellung stellt die Gemeinsamkeit aller Sequenzen dar. Durch die Verwendung dieser gemeinsamen Darstellung zur Vorhersage kann eine faire Vorhersage jeder Variablen erreicht werden.
Der Artikel verwendet die Idee des kontradiktorischen Lernens, um den L2-Abstand zwischen der öffentlichen Darstellung und der privaten Darstellung (dh der durch Clustering erhaltenen Darstellung jedes Clusters) direkt als Verlustumkehroptimierung zu berechnen Die Kluft zwischen der öffentlichen Teilvertretung und der privaten Teilvertretung ist möglichst groß. Darüber hinaus wird eine orthogonale Einschränkung hinzugefügt, um das innere Produkt der öffentlichen Darstellung und der privaten Darstellung nahe bei 0 zu halten.
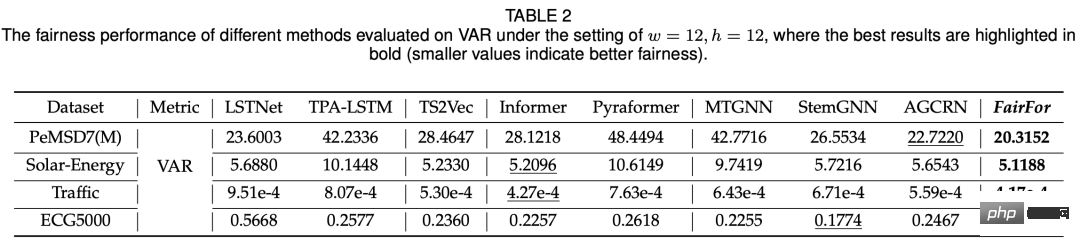
Die Experimente in diesem Artikel werden hauptsächlich unter zwei Aspekten verglichen: Fairness und Vorhersageeffekt. Die verglichenen Modelle umfassen grundlegende Zeitreihenvorhersagemodelle (LSTNet, Informer), Diagrammzeitreihenvorhersagemodelle usw. Im Hinblick auf die Fairness wird die Varianz der Vorhersageergebnisse verschiedener Variablen verwendet. Durch den Vergleich wird die Fairness dieser Methode im Vergleich zu anderen Modellen erheblich verbessert (wie in der folgenden Tabelle dargestellt).
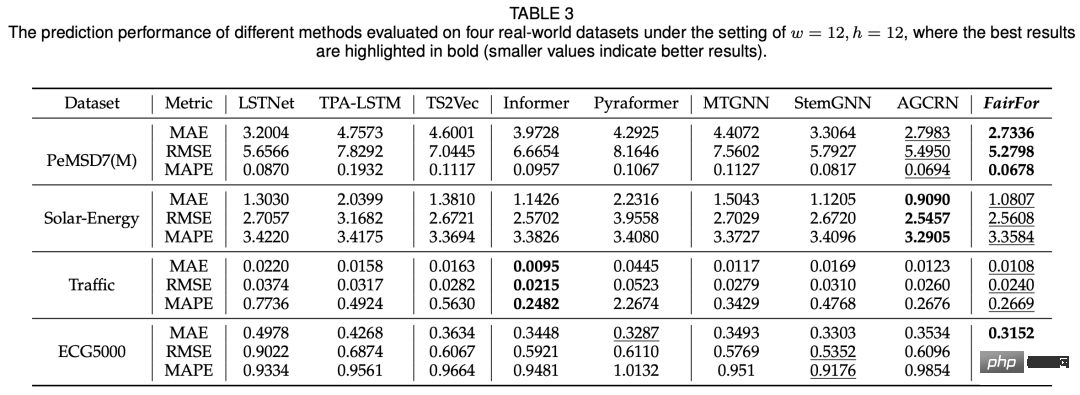
In Bezug auf den Vorhersageeffekt kann das in diesem Artikel vorgeschlagene Modell grundsätzlich gleichwertige Ergebnisse wie SOTA erzielen:
Das obige ist der detaillierte Inhalt vonZur Frage der Fairness in multivariaten Zeitreihen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie das HTMLlabel-Label
So verwenden Sie das HTMLlabel-Label
 Die Rolle des Routers
Die Rolle des Routers
 So installieren Sie Pycharm
So installieren Sie Pycharm
 Der Unterschied zwischen Concat und Push in JS
Der Unterschied zwischen Concat und Push in JS
 Verwendung von Versprechen
Verwendung von Versprechen
 Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
 So entschlüsseln Sie die Bitlocker-Verschlüsselung
So entschlüsseln Sie die Bitlocker-Verschlüsselung
 Welche Plattform ist Kuai Tuan Tuan?
Welche Plattform ist Kuai Tuan Tuan?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



