

So fügen Sie Traversal-Elemente zu Java HashSet hinzu

HashSet-Klassendiagramm
HashSet einfache Beschreibung
1.HashSet implementiert Set Schnittstelle HashSet 实现了 Set 接口
2.HashSet 底层实际上是由 HashMap 实现的
public HashSet() {
map = new HashMap<>();
}3.可以存放 null,但是只能有一个 null
4.HashSet 不保证元素是有序的(即不保证存放元素的顺序和取出元素的顺序一致),取决于 hash 后,再确定索引的结果
5.不能有重复的元素
HashSet 底层机制说明
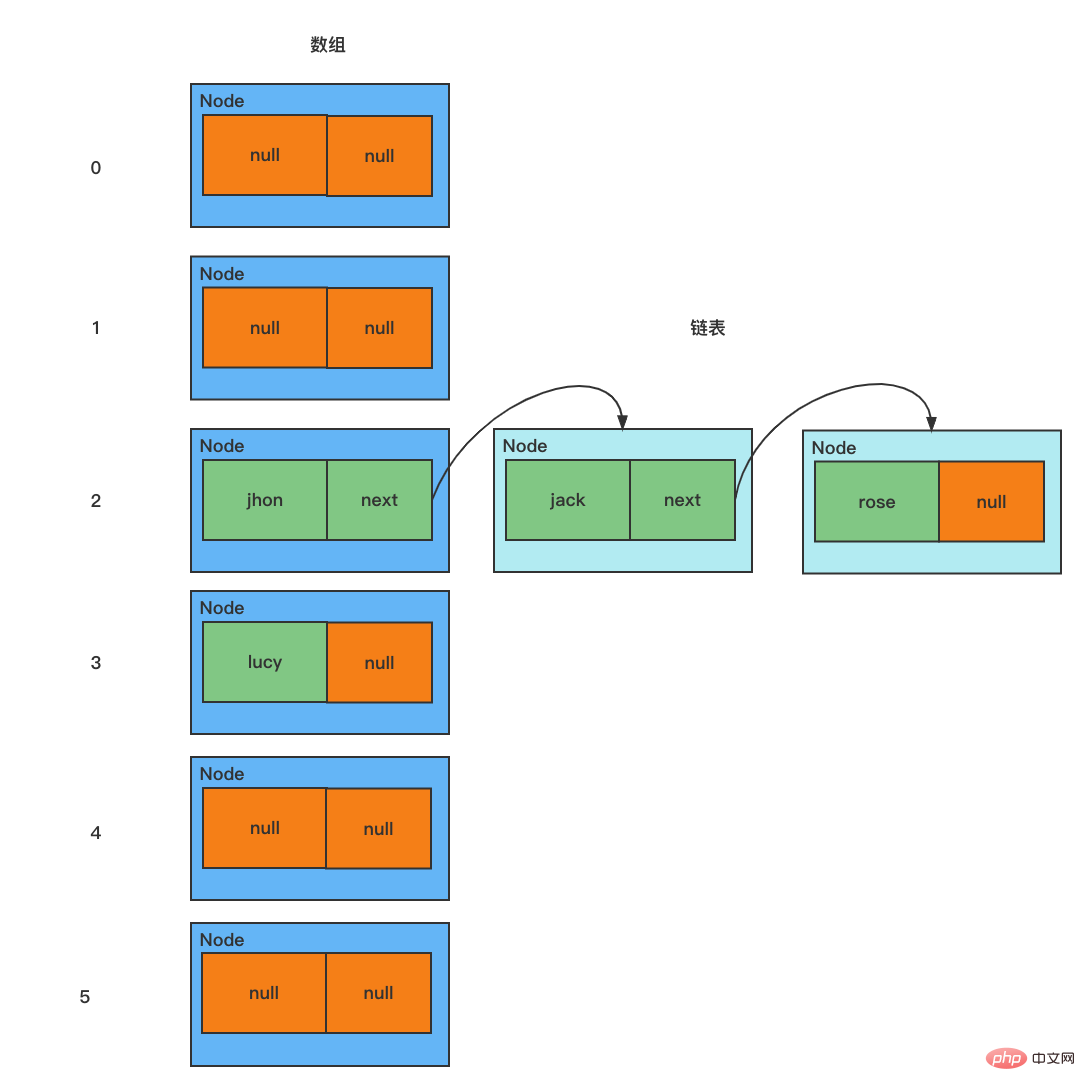
HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树
模拟数组+链表的结构
/**
* 模拟 HashSet 数组+链表的结构
*/
public class HashSetStructureMain {
public static void main(String[] args) {
// 模拟一个 HashSet(HashMap) 的底层结构
// 1. 创建一个数组,数组的类型为 Node[]
// 2. 有些地方直接把 Node[] 数组称为 表
Node[] table = new Node[16];
System.out.println(table);
// 3. 创建节点
Node john = new Node("john", null);
table[2] = jhon; // 把节点 john 放在数组索引为 2 的位置
Node jack = new Node("jack", null);
jhon.next = jack; // 将 jack 挂载到 jhon 的后面
Node rose = new Node("rose", null);
jack.next = rose; // 将 rose 挂载到 jack 的后面
Node lucy = new Node("lucy", null);
table[3] = lucy; // 将 lucy 放在数组索引为 3 的位置
System.out.println(table);
}
}
// 节点类 存储数据,可以指向下一个节点,从而形成链表
class Node{
Object item; // 存放数据
Node next; // 指向下一个节点
public Node(Object item, Node next){
this.item = item;
this.next = next;
}
}HashSet 添加元素底层机制
HashSet 添加元素的底层实现
1.HashSet 底层是 HashMap
2.当添加一个元素时,会先得到 待添加元素的 hash 值,然后将其转换成一个 索引值
3.查询存储数据表(Node 数组) table,看当前 待添加元素 所对应的 索引值 的位置是否已经存放了 其它元素
4.如果当前 索引值 所对应的的位置不存在 其它元素,就将当前 待添加元素 放到这个 索引值 所对应的的位置
5.如果当前 索引值 所对应的位置存在 其它元素,就调用 待添加元素.equals(已存在元素) 比较,结果为 true,则放弃添加;结果为 false,则将 待添加元素 放到 已存在元素 的后面(已存在元素.next = 待添加元素)
HashSet 扩容机制
1.HashSet 的底层是 HashMap,第一次添加元素时,table 数组扩容到 cap = 16,threshold(临界值) = cap * loadFactor(加载因子 0.75) = 12
2.如果 table 数组使用到了临界值 12,就会扩容到 cap * 2 = 32,新的临界值就是 32 * 0.75 = 24,以此类推
3.在 Java8 中,如果一条链表上的元素个数 到达 TREEIFY_THRESHOLD(默认是 8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认是 64),就会进行 树化(红黑树)
4.判断是否扩容是根据 ++size > threshold,即是否扩容,是根据 HashMap 所存的元素个数(size)是否超过临界值,而不是根据 table.length() 是否超过临界值
HashSet 添加元素源码
/**
* HashSet 源码分析
*/
public class HashSetSourceMain {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set = " + hashSet);
// 源码分析
// 1. 执行 HashSet()
/**
* public HashSet() { // HashSet 底层是 HashMap
* map = new HashMap<>();
* }
*/
// 2. 执行 add()
/**
* public boolean add(E e) { // e == "java"
* // HashSet 的 add() 方法其实是调用 HashMap 的 put()方法
* return map.put(e, PRESENT)==null; // (static) PRESENT = new Object(); 用于占位
* }
*/
// 3. 执行 put()
// hash(key) 得到 key(待存元素) 对应的hash值,并不等于 hashcode()
// 算法是 h = key.hashCode()) ^ (h >>> 16
/**
* public V put(K key, V value) {
* return putVal(hash(key), key, value, false, true);
* }
*/
// 4. 执行 putVal()
// 定义的辅助变量:Node<K,V>[] tab; Node<K,V> p; int n, i;
// table 是 HashMap 的一个属性,初始化为 null;transient Node<K,V>[] table;
// resize() 方法,为 table 数组指定容量
// p = tab[i = (n - 1) & hash] 计算 key的hash值所对应的 table 中的索引位置,将索引位置对应的 Node 赋给 p
/**
* final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
* boolean evict) {
* Node<K,V>[] tab; Node<K,V> p; int n, i; // 辅助变量
* // table 就是 HashMap 的一个属性,类型是 Node[]
* // if 语句表示如果当前 table 是 null,或者 table.length == 0
* // 就是 table 第一次扩容,容量为 16
* if ((tab = table) == null || (n = tab.length) == 0)
* n = (tab = resize()).length;
* // 1. 根据 key,得到 hash 去计算key应该存放到 table 的哪个索引位置
* // 2. 并且把这个位置的索引值赋给 i;索引值对应的元素,赋给 p
* // 3. 判断 p 是否为 null
* // 3.1 如果 p 为 null,表示还没有存放过元素,就创建一个Node(key="java",value=PRESENT),并把这个元素放到 i 的索引位置
* // tab[i] = newNode(hash, key, value, null);
* if ((p = tab[i = (n - 1) & hash]) == null)
* tab[i] = newNode(hash, key, value, null);
* else {
* Node<K,V> e; K k; // 辅助变量
* // 如果当前索引位置对应的链表的第一个元素和待添加的元素的 hash值一样
* // 并且满足下面两个条件之一:
* // 1. 待添加的 key 与 p 所指向的 Node 节点的key 是同一个对象
* // 2. 待添加的 key.equals(p 指向的 Node 节点的 key) == true
* // 就认为当前待添加的元素是重复元素,添加失败
* if (p.hash == hash &&
* ((k = p.key) == key || (key != null && key.equals(k))))
* e = p;
* // 判断 当前 p 是不是一颗红黑树
* // 如果是一颗红黑树,就调用 putTreeVal,来进行添加
* else if (p instanceof TreeNode)
* e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
* else {
* // 如果 当前索引位置已经形成一个 链表,就使用 for 循环比较
* // 将待添加元素依次和链表上的每个元素进行比较
* // 1. 比较过程中如果出现待添加元素和链表中的元素有相同的,比较结束,出现重复元素,添加失败
* // 2. 如果比较到链表最后一个元素,链表中都没出现与待添加元素相同的,就把当前待添加元素放到该链表最后的位置
* // 注意:在把待添加元素添加到链表后,立即判断 该链表是否已经到达 8 个节点
* // 如果到达,就调用 treeifyBin() 对当前这个链表进行数化(转成红黑树)
* // 注意:在转成红黑树前,还要进行判断
* // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
* // resize();
* // 如果上面条件成立,先对 table 进行扩容
* // 如果上面条件不成立,才转成红黑树
* for (int binCount = 0; ; ++binCount) {
* if ((e = p.next) == null) {
* p.next = newNode(hash, key, value, null);
* if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
* treeifyBin(tab, hash);
* break;
* }
* if (e.hash == hash &&
* ((k = e.key) == key || (key != null && key.equals(k))))
* break;
* p = e;
* }
* }
* // e 不为 null ,说明添加失败
* if (e != null) { // existing mapping for key
* V oldValue = e.value;
* if (!onlyIfAbsent || oldValue == null)
* e.value = value;
* afterNodeAccess(e);
* return oldValue;
* }
* }
* ++modCount;
* // 扩容:说明判断 table 是否扩容不是看 table 的length
* // 而是看 整个 HashMap 的 size(即已存元素个数)
* if (++size > threshold)
* resize();
* afterNodeInsertion(evict);
* return null;
* }
*/
}
}HashSet 遍历元素底层机制
HashSet 遍历元素底层机制
1.HashSet 的底层是 HashMap,HashSet 的迭代器也是借由 HashMap 来实现的
2.HashSet.iterator() 实际上是去调用 HashMap 的 KeySet().iterator()
public Iterator<E> iterator() {
return map.keySet().iterator();
}3.KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}4.KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap 的一个内部类
public final Iterator<K> iterator() { return new KeyIterator(); }5.KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口,即 KeyIterator、HashIterator 才是真正实现 迭代器 的类
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}6.当执行完 Iterator iterator = HashSet.iterator; 之后,此时的 iterator 对象中已经存储了一个元素节点
怎么做到的?
回到第 4 步,
2KeySet().iterator()方法返回一个KeyIteratorHashSetDie unterste Ebene wird tatsächlich durchHashMap#🎜🎜##🎜🎜 # implementiert. 3./** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */Nach dem Login kopierenNach dem Login kopierennullkann gespeichert werden, aber es kann nur einnull#🎜🎜##🎜🎜#4HashSetgarantieren Das Element ist in der Reihenfolge vorhanden (d. h. die Reihenfolge, in der die Elemente gespeichert werden, stimmt nicht garantiert mit der Reihenfolge überein, in der die Elemente herausgenommen werden), hängt vomhashab und bestimmt dann die Reihenfolge Indexergebnis #🎜🎜##🎜🎜#5. Es dürfen keine doppelten Elemente vorhanden sein. #🎜🎜##🎜🎜#HashSet-Beschreibung des zugrunde liegenden Mechanismus#🎜🎜##🎜🎜#HashSetDie unterste Ebene ist < code>HashMap,HashMapDie unterste Ebene ist < strong>Array + verknüpfte Liste + rot-schwarzer Baum#🎜🎜#Simuliert die Struktur von Array + verknüpft list
#🎜🎜# #🎜🎜##🎜🎜#HashSet Der zugrunde liegende Mechanismus zum Hinzufügen von Elementen#🎜🎜#
#🎜🎜##🎜🎜#HashSet Der zugrunde liegende Mechanismus zum Hinzufügen von Elementen#🎜🎜#public final boolean hasNext() { return next != null; }Nach dem Login kopierenNach dem Login kopierenHashSet fügt Elemente hinzu. Die zugrunde liegende Implementierung
#🎜🎜#1.HashSetDer Die unterste Ebene istHashMap#🎜🎜##🎜🎜#2. Beim Hinzufügen eines Elements erhalten Sie zunächst den Wert des hinzuzufügenden Elementshash< /code> wird dann in einen <strong>Indexwert</strong>#🎜🎜##🎜🎜#3 umgewandelt. Fragen Sie die Speicherdatentabelle (Node-Array) <code>tableab und prüfen Sie, ob der Indexwert, der dem aktuell hinzuzufügenden Element entspricht, hat bereits andere Elemente gespeichert >#🎜🎜##🎜🎜#4 strong>Anderes Element an der Position, die dem aktuellen Indexwert entspricht, das aktuelle Element, das hinzugefügt werden soll wird stark> Platzieren Sie es an der Position, die diesem entspricht Indexwert#🎜🎜##🎜🎜#5. Wenn sich an der Position, die dem aktuellen Indexwert entspricht, weitere Elemente befinden, rufen Sie einfach aufElement, das hinzugefügt werden soll.equals (vorhandenes Element)zum Vergleichen. Wenn das Ergebnistrueist, geben Sie das Hinzufügen auf; Platzieren Sie dann Element, das hinzugefügt werden soll nach Vorhandenes Element (Existing element.next = Element, das hinzugefügt werden soll)#🎜🎜#HashSet-Erweiterung Mechanismus
#🎜🎜#1. Die unterste Ebene vonHashSetistHashMapDas Array wird aufcap = 16,threshold(kritischer Wert) = cap * LoadFactor (Ladefaktor 0,75) = 12#🎜🎜##🎜🎜#2 erweitert < Wenn das Code>table-Array den kritischen Wert 12 erreicht, wird es aufcap * 2 = 32erweitert. Der neue kritische Wert ist32 * 0,75 = 24</. code>, also analog #🎜🎜##🎜🎜#3 In Java8, wenn die Anzahl der Elemente in einer verknüpften Liste <code>TREEIFY_THRESHOLDerreicht (der Standardwert ist 8) , undDie Größe der Tabelle>=MIN_TREEIFY_CAPACITY(Standard ist 64) ist Baum (rot-schwarzer Baum)#🎜🎜# #🎜🎜#4 .Die Entscheidung, ob erweitert werden soll, basiert auf dem Schwellenwert++size >, d. h. ob erweitert werden soll, hängt davon ab, ob die Anzahl der Elemente (size</) code>), der in <code>HashMapgespeichert ist, überschreitet den kritischen Wert und basiert nicht darauf, obtable.length()den kritischen Wert überschreitet#🎜🎜#HashSet fügt Elementquelle hinzu Code
#🎜🎜#HashSet durchläuft den zugrunde liegenden Mechanismus von Elementen#🎜 🎜#/** * HashSet 源码分析 */ public class HashSetSourceMain { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("java"); hashSet.add("php"); hashSet.add("java"); System.out.println("set = " + hashSet); // HashSet 迭代器实现原理 // HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树 // HashSet 本身没有实现迭代器,而是借由 HashMap 来实现的 // 1. hashSet.iterator() 实际上是去调用 HashMap 的 keySet().iterator() /** * public Iteratoriterator() { * return map.keySet().iterator(); * } */ // 2. KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类 /** * public Set keySet() { * Set ks = keySet; * if (ks == null) { * ks = new KeySet(); * keySet = ks; * } * return ks; * } */ // 3. KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap的一个内部类 /** * public final Iterator<K> iterator() { return new KeyIterator(); } */ // 4. KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口 // 即 KeyIterator、HashIterator 才是真正实现 迭代器的类 /** * final class KeyIterator extends HashIterator * implements Iterator { * public final K next() { return nextNode().key; } * } */ // 5. 当执行完 Iterator iterator = hashSet.iterator(); 后 // 此时的 iterator 对象中已经存储了一个元素节点 // 怎么做到的? // 回到第 3 步,KeySet().iterator() 方法返回一个 KeyIterator 对象 // new KeyIterator() 调用 KeyIterator 的无参构造器 // 在这之前,会先调用 KeyIterator 父类 HashIterator 的无参构造器 // 因此分析 HashIterator 的无参构造器就知道发生了什么 /** * Node Nach dem Login kopierenNach dem Login kopierenDer zugrunde liegende Mechanismus von HashSet-Traversalelementen
#🎜🎜#1. Die unterste Ebene vonHashSet< /code> ist <code>HashMap, die Iteration vonHashSet. Das Gerät wird auch vonHashMap#🎜🎜##🎜🎜#2 implementiert >HashSet.iterator() ruft tatsächlichHashMapauf. DasKeySet().iterator()#🎜🎜#rrreee#🎜🎜#3.KeySet ()-Methode gibt einKeySet-Objekt zurück undKeySetist eine interne Klasse vonHashMap#🎜🎜#rrreee#🎜🎜# 4. Die MethodeKeySet().iterator()gibt ein < code>KeyIterator-Objekt zurück.KeyIteratorist eine interne Klasse vonHashMap</code >#🎜🎜#rrreee#🎜🎜#5.<code>KeyIterator-Vererbung Die KlasseHashIterator(interne Klasse vonHashMap) wurde erstellt und die < code>Iterator-Schnittstelle implementiert wurde, nämlichKeyIterator,HashIteratorist die Klasse, die tatsächlich Iterator#🎜🎜#rrreee#🎜 implementiert 🎜#6. Nach der Ausführung vonIterator iterator = HashSet.iterator;wurde zu diesem Zeitpunkt ein Elementknoten imiterator-Objekt #🎜🎜#- #🎜🎜#Wie geht das? #🎜🎜#
- #🎜🎜#Gehen Sie zurück zu Schritt 4, die Methode
KeySet().iterator()gibt einKeyIterator-Objekt#🎜 zurück 🎜 # new KeyIterator()调用KeyIterator的无参构造器在这之前,会先调用其父类
HashIterator的无参构造器因此,分析
HashIterator的无参构造器就知道发生了什么
/** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */Nach dem Login kopierenNach dem Login kopierennext、current、index都是HashIterator的属性Node<K,V>[] t = table;先把Node数组talbe赋给tcurrent = next = null;current、next都置为nullindex = 0;index置为0do {} while (index < t.length && (next = t[index++]) == null);这个do-while会在table中遍历Node结点一旦
(next = t[index++]) == null不成立 时,就说明找到了一个table中的Node结点将这个节点赋给
next,并退出当前do-while循环此时
Iterator iterator = HashSet.iterator;就执行完了当前
iterator的运行类型其实是HashIterator,而HashIterator的next中存储着从table中遍历出来的一个Node结点
7.执行
iterator.hasNext此时的
next存储着一个Node,所以并不为null,返回truepublic final boolean hasNext() { return next != null; }Nach dem Login kopierenNach dem Login kopieren8.执行
iterator.next()I.
Node<K,V> e = next;把当前存储着Node结点的next赋值给了eII.
(next = (current = e).next) == null判断当前结点的下一个结点是否为null(a). 如果当前结点的下一个结点为
null,就执行do {} while (index < t.length && (next = t[index++]) == null);,在table数组中遍历,寻找table数组中的下一个Node并赋值给next(b). 如果当前结点的下一个结点不为
null,就将当前结点的下一个结点赋值给next,并且此刻不会去table数组中遍历下一个Node结点
III.将找到的结点
e返回IV.之后每次执行
iterator.next()都像 (a)、(b) 那样去判断遍历,直到遍历完成HashSet 遍历元素源码
/** * HashSet 源码分析 */ public class HashSetSourceMain { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("java"); hashSet.add("php"); hashSet.add("java"); System.out.println("set = " + hashSet); // HashSet 迭代器实现原理 // HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树 // HashSet 本身没有实现迭代器,而是借由 HashMap 来实现的 // 1. hashSet.iterator() 实际上是去调用 HashMap 的 keySet().iterator() /** * public Iteratoriterator() { * return map.keySet().iterator(); * } */ // 2. KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类 /** * public Set keySet() { * Set ks = keySet; * if (ks == null) { * ks = new KeySet(); * keySet = ks; * } * return ks; * } */ // 3. KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap的一个内部类 /** * public final Iterator<K> iterator() { return new KeyIterator(); } */ // 4. KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口 // 即 KeyIterator、HashIterator 才是真正实现 迭代器的类 /** * final class KeyIterator extends HashIterator * implements Iterator { * public final K next() { return nextNode().key; } * } */ // 5. 当执行完 Iterator iterator = hashSet.iterator(); 后 // 此时的 iterator 对象中已经存储了一个元素节点 // 怎么做到的? // 回到第 3 步,KeySet().iterator() 方法返回一个 KeyIterator 对象 // new KeyIterator() 调用 KeyIterator 的无参构造器 // 在这之前,会先调用 KeyIterator 父类 HashIterator 的无参构造器 // 因此分析 HashIterator 的无参构造器就知道发生了什么 /** * Node Nach dem Login kopierenNach dem Login kopierenDas obige ist der detaillierte Inhalt vonSo fügen Sie Traversal-Elemente zu Java HashSet hinzu. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
