
 Technologie-Peripheriegeräte
KI
Es dauert nur 3 Sekunden, um Ihre Stimme zu stehlen! Microsoft veröffentlicht Sprachsynthesemodell VALL-E: Netizens riefen aus, dass die Schwelle für „Telefonbetrug' erneut gesenkt wurde
Technologie-Peripheriegeräte
KI
Es dauert nur 3 Sekunden, um Ihre Stimme zu stehlen! Microsoft veröffentlicht Sprachsynthesemodell VALL-E: Netizens riefen aus, dass die Schwelle für „Telefonbetrug' erneut gesenkt wurde
Es dauert nur 3 Sekunden, um Ihre Stimme zu stehlen! Microsoft veröffentlicht Sprachsynthesemodell VALL-E: Netizens riefen aus, dass die Schwelle für „Telefonbetrug' erneut gesenkt wurde

Lassen Sie ChatGPT Ihnen beim Schreiben des Drehbuchs helfen und Stable Diffusion Illustrationen erstellen. Benötigen Sie einen Synchronsprecher, um ein Video zu erstellen? Es kommt!
Kürzlich haben Forscher von Microsoft ein neues Text-to-Speech-Modell (TTS) VALL-E veröffentlicht, das nur drei Sekunden Audiobeispiele bereitstellen muss, um eingegebene menschliche Stimmen zu simulieren, und entsprechende Audiodaten synthetisiert basierend auf dem eingegebenen Text und kann auch den emotionalen Ton des Sprechers aufrechterhalten.

Papierlink: https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Projektlink: https:/ /valle-demo.github.io/
Code-Link: https://github.com/microsoft/unilm
Schauen wir uns zunächst den Effekt an: Angenommen, Sie Habe einen Absatz von 3 Sekunden Aufnahme.
diversity_speaker Audio: 00:0000:03
Geben Sie dann einfach den Text „Weil wir es nicht brauchen“ ein, um die synthetisierte Stimme zu erhalten.
diversity_s1 Audio: 00:0000:01
Selbst durch die Verwendung verschiedener Zufalls-Seeds können Sie auch eine personalisierte Sprachsynthese durchführen.
diversity_s2 Audio: 00:0000:02
VALL-E kann auch den Umgebungsklang des Sprechers beibehalten, beispielsweise die Eingabe dieser Stimme.
env_speaker Audio: 00:0000:03
Dann können Sie gemäß dem Text „Ich denke, es ist, als ob Sie wissen, dass es auch bequemer ist.“ die synthetisierte Sprache ausgeben, während Aufrechterhaltung der Umgebung Stimme.
env_vall_eAudio: 00:0000:02
Und VALL-E kann auch die Emotionen des Sprechers aufrechterhalten, beispielsweise durch die Eingabe einer wütenden Stimme.
anger_pt Audio: 00:0000:03
Basierend auf dem Text „Wir müssen die Anzahl der Plastiktüten reduzieren.“ können Sie auch wütende Emotionen ausdrücken.
anger_ours Audio: 00:0000:02
Viele weitere Beispiele gibt es auf der Projektwebsite.
Insbesondere in Bezug auf die Methode trainierten die Forscher das Sprachmodell VALL-E anhand diskreter Codierungen, die aus handelsüblichen neuronalen Audio-Codec-Modellen extrahiert wurden, und behandelten TTS als bedingte Sprachmodellierungsaufgabe statt kontinuierlich Signalregression.
In der Vortrainingsphase erreichten die von VALL-E empfangenen TTS-Trainingsdaten 60.000 Stunden englische Sprache, was hunderte Male mehr ist als die vom bestehenden System verwendeten Daten.
Darüber hinaus demonstriert VALL-E auch die Fähigkeit des kontextbezogenen Lernens. Es muss lediglich die 3-Sekunden-Registrierungsaufzeichnung des unsichtbaren Sprechers als Tonaufforderung verwendet werden, um hochwertige personalisierte Sprache zu synthetisieren.
Experimentelle Ergebnisse zeigen, dass VALL-E in Bezug auf Sprachnatürlichkeit und Sprecherähnlichkeit deutlich besser ist als das hochmoderne Zero-Shot-TTS-System und außerdem die Emotionen und die Stimme des Sprechers bewahren kann Hinweise in der akustischen Syntheseumgebung.
Zero-Shot-Sprachsynthese
Im letzten Jahrzehnt hat die Sprachsynthese durch die Entwicklung neuronaler Netze und End-to-End-Modellierung große Durchbrüche erzielt.
Aber aktuelle kaskadierte Text-to-Speech-Systeme (TTS) verwenden normalerweise eine Pipeline mit einem akustischen Modell und einem Vocoder, der Mel-Spektrogramme als Zwischendarstellungen verwendet.
Während einige Hochleistungs-TTS-Systeme qualitativ hochwertige Sprache von einem oder mehreren Sprechern synthetisieren können, sind dafür immer noch hochwertige, saubere Daten aus dem Aufnahmestudio erforderlich, eine groß angelegte Datenerfassung aus dem Internet ist nicht möglich Die Datenanforderungen werden nicht erfüllt und die Leistung des Modells wird beeinträchtigt.
Aufgrund der relativ geringen Menge an Trainingsdaten weist das aktuelle TTS-System immer noch das Problem einer schlechten Generalisierungsfähigkeit auf.
Unter der Zero-Shot-Aufgabeneinstellung nimmt die Ähnlichkeit und Natürlichkeit der Sprache bei Sprechern, die nicht in den Trainingsdaten enthalten sind, stark ab.
Um das Zero-Shot-TTS-Problem zu lösen, nutzen bestehende Arbeiten normalerweise Methoden wie Lautsprecheranpassung und Lautsprecherkodierung, die zusätzliche Feinabstimmung und komplexe Vorentwurfsfunktionen oder umfangreiche strukturelle Arbeiten erfordern .
Anstatt ein komplexes und spezialisiertes Netzwerk für dieses Problem zu entwerfen, glauben die Forscher angesichts ihres Erfolgs bei der Textsynthese, dass die ultimative Lösung darin bestehen sollte, das Modell mit möglichst vielen unterschiedlichen Daten zu trainieren.
VALL-E-Modell
Im Bereich der Textsynthese werden umfangreiche unbeschriftete Daten aus dem Internet direkt in das Modell eingespeist. Auch die Modellleistung nimmt weiter zu.
Forscher haben diese Idee auf den Bereich der Sprachsynthese übertragen. Das VALL-E-Modell ist das erste TTS-Framework, das auf Sprachmodellen basiert und umfangreiche, vielfältige Sprachdaten mehrerer Sprecher nutzt.
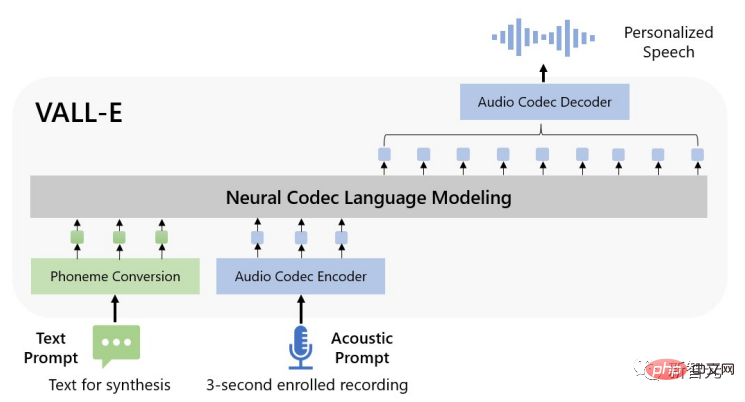
Um personalisierte Sprache zu synthetisieren, generiert das VALL-E-Modell entsprechende akustische Token auf der Grundlage der akustischen Token und Phonemaufforderungen der registrierten 3 Sekunden Die Aufnahme dieser Nachrichten kann die Sprecher- und Inhaltsinformationen einschränken.
Schließlich wird der generierte akustische Token verwendet, um die endgültige Wellenform mit dem entsprechenden neuronalen Codec zu synthetisieren.
Die diskreten akustischen Token aus dem Audio-Codec-Modell ermöglichen es, TTS als bedingte Codec-Sprachmodellierung zu betrachten, sodass einige fortgeschrittene, auf Hinweisen basierende Techniken großer Modelle (z. B. GPTs) in TTS verwendet werden können. Die Aufgabe ist eröffnet.
Akustische Token können während des Inferenzprozesses auch unterschiedliche Sampling-Strategien verwenden, um unterschiedliche Syntheseergebnisse in TTS zu erzeugen.
Die Forscher trainierten VALL-E mithilfe des LibriLight-Datensatzes, der aus 60.000 Stunden englischer Sprache mit mehr als 7.000 einzelnen Sprechern besteht. Bei den Rohdaten handelt es sich nur um Audiodaten, sodass zur Generierung der Transkripte nur ein Spracherkennungsmodell verwendet wird.
Im Vergleich zu früheren TTS-Trainingsdatensätzen, wie z. B. LibriTTS, enthält der in der Arbeit bereitgestellte neue Datensatz mehr verrauschte Sprache und ungenaue Transkriptionen, bietet jedoch andere Sprecher und Register (Prosodien).
Die Forscher glauben, dass die im Artikel vorgeschlagene Methode robust gegenüber Rauschen ist und Big Data nutzen kann, um eine gute Allgemeingültigkeit zu erreichen.

Es ist erwähnenswert, dass bestehende TTS-Systeme immer Dutzende Stunden einsprachiger Sprecherdaten oder Hunderte Stunden mehrsprachiger Daten verwenden. Das Training erfolgt anhand von Benutzerdaten und ist hunderte Male kleiner als VALL-E.
Kurz gesagt, VALL-E ist eine brandneue Sprachmodellmethode für TTS, die Audiokodierungs- und -dekodierungscodes als Zwischendarstellungen verwendet und eine große Menge verschiedener Daten verwendet, um dem Modell leistungsstarkes kontextbezogenes Lernen zu ermöglichen Fähigkeiten.
Begründung: In-Kontext-Lernen durch Eingabeaufforderung
Kontext-Lernen (In-Kontext-Lernen) ist eine erstaunliche Fähigkeit textbasierter Sprachmodelle, die Beschriftungen für unsichtbare Eingaben ohne vorherzusagen können erfordern zusätzliche Parameteraktualisierungen.
Wenn das Modell bei TTS qualitativ hochwertige Sprache für unsichtbare Sprecher ohne Feinabstimmung synthetisieren kann, wird davon ausgegangen, dass das Modell über kontextbezogene Lernfähigkeiten verfügt.
Bestehende TTS-Systeme sind jedoch nicht sehr in der Lage, im Kontext zu lernen, da sie entweder eine zusätzliche Feinabstimmung erfordern oder unter einer erheblichen Verschlechterung für unsichtbare Sprecher leiden.
Für Sprachmodelle ist eine Eingabeaufforderung erforderlich, um kontextbezogenes Lernen in Zero-Shot-Situationen zu erreichen.
Die von den Forschern entworfenen Eingabeaufforderungen und Argumente lauten wie folgt:
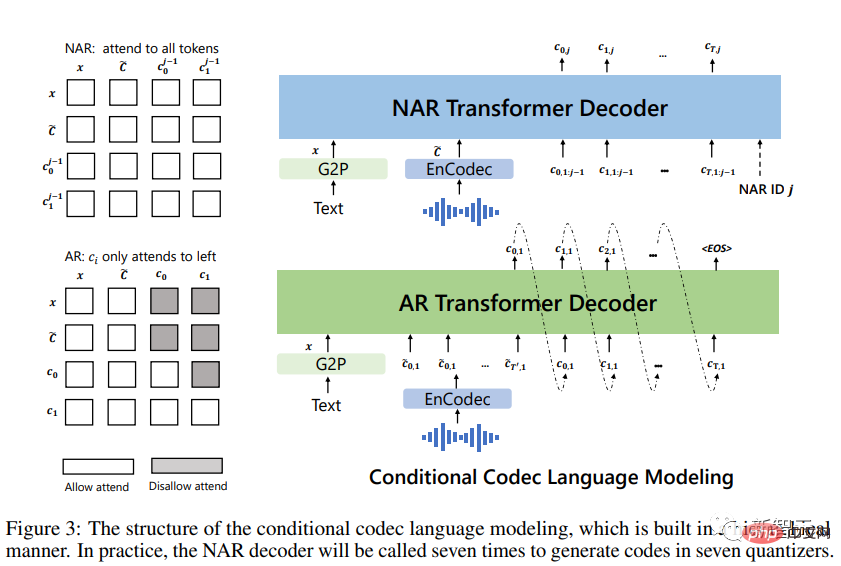
Konvertieren Sie zunächst den Text in eine Phonemsequenz und kodieren Sie die registrierte Aufnahme in eine akustische Matrix, um Phonemhinweise zu bilden und akustische Hinweise, die beide Hinweise in AR- und NAR-Modellen verwendet werden.
Verwenden Sie für AR-Modelle eine auf Hinweisen basierende Sampling-basierte Dekodierung, da die Strahlsuche dazu führen kann, dass LM in eine Endlosschleife eintritt. Darüber hinaus können Sampling-basierte Methoden die Vielfalt der Ausgaben erheblich erhöhen.
Für das NAR-Modell wird die gierige Dekodierung verwendet, um den Token mit der höchsten Wahrscheinlichkeit auszuwählen.
Schließlich wird ein neuronaler Codec verwendet, um Wellenformen zu erzeugen, die auf acht Kodierungssequenzen basieren.
Akustische Hinweise müssen nicht unbedingt eine semantische Beziehung mit der zu synthetisierenden Sprache haben, daher können sie in zwei Situationen unterteilt werden:
VALL-E: Das Hauptziel ist Bieten Sie unsichtbare Sprache. Ein bestimmter Sprecher generiert den angegebenen Inhalt.
Die Eingabe dieses Modells ist ein Textsatz, eine eingeschriebene Rede und die entsprechende Transkription. Fügen Sie die transkribierten Phoneme der registrierten Sprache als Phonemhinweise zur Phonemsequenz des gegebenen Satzes hinzu und verwenden Sie das akustische Token der ersten Ebene der registrierten Sprache als akustisches Präfix. Mit Phonemhinweisen und akustischen Präfixen generiert VALL-E ein akustisches Token für einen bestimmten Text und klont dabei die Stimme des Sprechers.
VALL-E-kontinuierlich: Verwendet das gesamte Transkript und die ersten 3 Sekunden der Äußerung als phonemische bzw. akustische Hinweise und fordert das Modell auf, kontinuierlichen Inhalt zu generieren.
Der Argumentationsprozess ist derselbe wie beim Festlegen von VALL-E, mit der Ausnahme, dass die registrierte Sprache und die generierte Sprache semantisch kontinuierlich sind.
Experimenteller Teil
Die Forscher bewerteten VALL-E anhand der LibriSpeech- und VCTK-Datensätze, wobei nicht alle getesteten Sprecher im Trainingskorpus auftauchten.
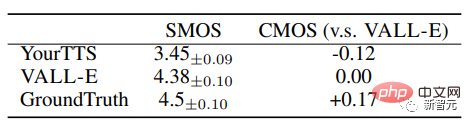
VALL-E übertrifft modernste Zero-Shot-TTS-Systeme deutlich in Bezug auf Sprachnatürlichkeit und Sprecherähnlichkeit, mit einem Comparative Average Option Score (CMOS) von +0,12 und +0,93 bei LibriSpeech-Ähnlichkeit Durchschnittlicher Optionswert (SMOS).
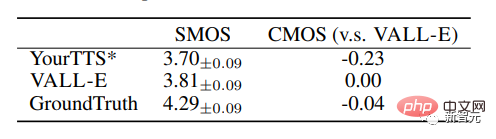
VALL-E übertraf auch das Basissystem mit Leistungsverbesserungen von +0,11 SMOS und +0,23 CMOS bei VCTK und erreichte sogar den Ground Truth-Wert von +0,04 CMOS , was darauf hinweist, dass bei VCTK synthetisierte Sprache von unsichtbaren Sprechern genauso natürlich ist wie menschliche Aufnahmen.
Darüber hinaus zeigt die qualitative Analyse, dass VALL-E in der Lage ist, verschiedene Ausgaben mit zwei identischen Texten und Zielsprechern zu synthetisieren, was der Erstellung von Sprach-Dummy-Daten zugute kommen kann für Identifikationsaufgaben.
Im Experiment konnte auch festgestellt werden, dass VALL-E die Klangumgebung (z. B. Nachhall) und die durch den Klang hervorgerufenen Emotionen (z. B. Wut usw.) aufrechterhalten kann.
Sicherheitsrisiken
Der Missbrauch leistungsstarker Technologie kann der Gesellschaft schaden. Beispielsweise wurde die Schwelle für Telefonbetrug erneut gesenkt!
Aufgrund des Potenzials von VALL-E für Unfug und Täuschung hat Microsoft den Code oder die Schnittstellen von VALL-E nicht zum Testen geöffnet.
Einige Internetnutzer teilten mit: Wenn Sie den Systemadministrator anrufen, zeichnen Sie ein paar Worte auf, die er „Hallo“ sagt, und synthetisieren Sie dann die Stimme basierend auf diesen Worten „Hallo, ich bin der Systemadministrator.“ Mein Sound ist eine eindeutige Kennung und kann sicher überprüft werden. „Ich dachte immer, das sei unmöglich. Mit so wenigen Daten könnte man diese Aufgabe nicht bewältigen.“ Nun scheint es, dass ich mich möglicherweise geirrt habe ...
In der abschließenden Ethikerklärung des Projekts erklärten die Forscher: „Die Experimente in diesem Artikel wurden durchgeführt, als der Modellbenutzer der Zielsprecher war und vom Sprecher genehmigt wurde.“ Wenn das Modell jedoch auf unsichtbare Sprecher verallgemeinert wird, sollten die relevanten Teile von einem Sprachbearbeitungsmodell begleitet werden, einschließlich eines Protokolls, um sicherzustellen, dass der Sprecher der Durchführung der Änderung zustimmt, und einem System zur Erkennung der bearbeiteten Rede In dem Papier heißt es außerdem, dass VALL-E, da es Sprache synthetisieren kann, die die Identität des Sprechers beibehält, potenzielle Risiken eines Missbrauchs des Modells mit sich bringen kann, wie z. B. die Täuschung der Spracherkennung oder die Nachahmung eines bestimmten Sprechers.
Um dieses Risiko zu verringern, kann ein Erkennungsmodell erstellt werden, um zu unterscheiden, ob ein Audioclip von VALL-E synthetisiert wurde. Während wir diese Modelle weiterentwickeln, werden wir auch die KI-Prinzipien von Microsoft in die Praxis umsetzen. 
https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Das obige ist der detaillierte Inhalt vonEs dauert nur 3 Sekunden, um Ihre Stimme zu stehlen! Microsoft veröffentlicht Sprachsynthesemodell VALL-E: Netizens riefen aus, dass die Schwelle für „Telefonbetrug' erneut gesenkt wurde. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Einstiegsadresse für die internationale Bing-Version von Microsoft (Einstieg in die Bing-Suchmaschine)
Mar 14, 2024 pm 01:37 PM
Einstiegsadresse für die internationale Bing-Version von Microsoft (Einstieg in die Bing-Suchmaschine)
Mar 14, 2024 pm 01:37 PM
Bing ist eine von Microsoft eingeführte Online-Suchmaschine. Die Suchfunktion ist sehr leistungsfähig und verfügt über zwei Eingänge: die inländische Version und die internationale Version. Wo sind die Eingänge zu diesen beiden Versionen? Wie greife ich auf die internationale Version zu? Werfen wir einen Blick auf die Details unten. Zugang zur Website der chinesischen Version von Bing: https://cn.bing.com/ Zugang zur Website der internationalen Version von Bing: https://global.bing.com/ Wie greife ich auf die internationale Version von Bing zu? 1. Geben Sie zunächst die URL ein, um Bing zu öffnen: https://www.bing.com/ 2. Sie sehen, dass es Optionen für nationale und internationale Versionen gibt. Wir müssen nur die internationale Version auswählen und die Schlüsselwörter eingeben.
 Warum kann ich den Ton auf WeChat Voice nicht hören? Was soll ich tun, wenn ich bei WeChat Voice keinen Ton höre?
Mar 13, 2024 pm 02:31 PM
Warum kann ich den Ton auf WeChat Voice nicht hören? Was soll ich tun, wenn ich bei WeChat Voice keinen Ton höre?
Mar 13, 2024 pm 02:31 PM
Warum kann ich den Ton auf WeChat Voice nicht hören? WeChat ist ein unverzichtbares Kommunikationstool in unserem täglichen Leben. Viele Benutzer haben während der Verwendung Probleme gehabt, den Ton in der WeChat-Sprache nicht zu hören. Was also tun? Auf dieser Website erhalten Benutzer eine detaillierte Einführung, was zu tun ist, wenn sie den Ton in der WeChat-Sprache nicht hören können. Was soll ich tun, wenn ich den Ton in der WeChat-Sprache nicht höre? 1. Der vom Mobiltelefonsystem eingestellte Ton ist relativ leise oder stumm. In diesem Fall können Sie die Lautstärke erhöhen oder den Stummmodus ausschalten 2. Es ist auch möglich, dass die WeChat-Lautsprecherfunktion nicht aktiviert ist. Öffnen Sie „Einstellungen“ und wählen Sie die Option „Chat“. 3. Nachdem Sie auf die Option „Chat“ geklickt haben
 Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Laut Nachrichten vom 3. Juni sendet Microsoft aktiv Vollbildbenachrichtigungen an alle Windows 10-Benutzer, um sie zu einem Upgrade auf das Betriebssystem Windows 11 zu ermutigen. Dabei handelt es sich um Geräte, deren Hardwarekonfigurationen das neue System nicht unterstützen. Seit 2015 hat Windows 10 fast 70 % des Marktanteils eingenommen und seine Dominanz als Windows-Betriebssystem fest etabliert. Der Marktanteil liegt jedoch weit über dem Marktanteil von 82 %, und der Marktanteil übersteigt den von Windows 11, das 2021 erscheinen wird, bei weitem. Obwohl Windows 11 seit fast drei Jahren auf dem Markt ist, ist die Marktdurchdringung immer noch langsam. Microsoft hat angekündigt, den technischen Support für Windows 10 nach dem 14. Oktober 2025 einzustellen, um sich stärker darauf zu konzentrieren
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
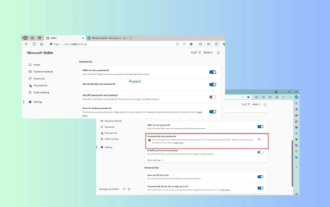 Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Neuigkeiten vom 18. April: Kürzlich berichteten einige Benutzer des Microsoft Edge-Browsers, die den Canary-Kanal nutzten, dass sie nach dem Upgrade auf die neueste Version festgestellt hätten, dass die Option zum automatischen Speichern von Passwörtern deaktiviert sei. Nach einer Untersuchung stellte sich heraus, dass es sich hierbei um eine geringfügige Anpassung nach dem Browser-Upgrade und nicht um eine Aufhebung der Funktionalität handelte. Vor der Verwendung des Edge-Browsers für den Zugriff auf eine Website berichteten Benutzer, dass der Browser ein Fenster öffnete, in dem sie gefragt wurden, ob sie das Anmeldekennwort für die Website speichern wollten. Nachdem Sie sich zum Speichern entschieden haben, gibt Edge bei der nächsten Anmeldung automatisch die gespeicherte Kontonummer und das gespeicherte Passwort ein, was den Benutzern großen Komfort bietet. Aber das neueste Update ähnelt einer Optimierung, bei der die Standardeinstellungen geändert werden. Benutzer müssen das Speichern des Passworts auswählen und dann in den Einstellungen das automatische Ausfüllen des gespeicherten Kontos und Passworts manuell aktivieren.
 Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Laut Nachrichten dieser Website vom 27. April hat Microsoft Anfang dieses Monats das Vorschauversionsupdate für Windows 11 Build 26100 auf den Canary- und Dev-Kanälen veröffentlicht, das voraussichtlich eine mögliche RTM-Version des Windows 1124H2-Updates werden wird. Die wichtigsten Änderungen in der neuen Version sind der Datei-Explorer, die Integration von Copilot, die Bearbeitung von PNG-Dateimetadaten, die Erstellung von TAR- und 7z-komprimierten Dateien usw. @PhantomOfEarth hat herausgefunden, dass Microsoft einige Funktionen der 24H2-Version (Germanium) auf die 23H2/22H2-Version (Nickel) übertragen hat, beispielsweise die Erstellung von TAR- und 7z-komprimierten Dateien. Wie im Diagramm gezeigt, unterstützt Windows 11 die native Erstellung von TAR
 Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Einer Nachricht vom 21. März zufolge hat Microsoft kürzlich seinen Microsoft Edge-Browser aktualisiert und eine praktische „Bild vergrößern“-Funktion hinzugefügt. Wenn Benutzer den Edge-Browser verwenden, können Benutzer diese neue Funktion jetzt ganz einfach im Popup-Menü finden, indem sie einfach mit der rechten Maustaste auf das Bild klicken. Noch praktischer ist, dass Benutzer auch mit der Maus über das Bild fahren und dann die Strg-Taste doppelklicken können, um schnell die Funktion zum Vergrößern des Bildes aufzurufen. Nach Angaben des Herausgebers wurde der neueste veröffentlichte Microsoft Edge-Browser im kanarischen Kanal auf neue Funktionen getestet. Die stabile Version des Browsers hat außerdem offiziell die praktische Funktion „Bild vergrößern“ eingeführt, die Benutzern ein komfortableres Durchsuchen von Bildern ermöglicht. Darauf haben auch ausländische Wissenschafts- und Technologiemedien geachtet
 Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
In der zweiten Hälfte des Jahres 2024 veröffentlichte der offizielle Microsoft-Sicherheitsblog eine Nachricht als Reaktion auf den Aufruf der Sicherheits-Community. Das Unternehmen plant, das in der zweiten Jahreshälfte 2024 veröffentlichte NTLAN Manager (NTLM)-Authentifizierungsprotokoll in Windows 11 zu eliminieren, um die Sicherheit zu verbessern. Nach bisherigen Erläuterungen hat Microsoft bereits zuvor ähnliche Schritte unternommen. Am 12. Oktober letzten Jahres schlug Microsoft in einer offiziellen Pressemitteilung einen Übergangsplan vor, der darauf abzielt, NTLM-Authentifizierungsmethoden auslaufen zu lassen und mehr Unternehmen und Benutzer dazu zu bewegen, auf Kerberos umzusteigen. Um Unternehmen zu helfen, die möglicherweise Probleme mit fest verdrahteten Anwendungen und Diensten haben, nachdem sie die NTLM-Authentifizierung deaktiviert haben, stellt Microsoft IAKerb und zur Verfügung
