
 Java
javaLernprogramm
Wie stark verbessert die gleichzeitige Java-Multithread-Programmierung die Effizienz der Datenverarbeitung?
Java
javaLernprogramm
Wie stark verbessert die gleichzeitige Java-Multithread-Programmierung die Effizienz der Datenverarbeitung?
Wie stark verbessert die gleichzeitige Java-Multithread-Programmierung die Effizienz der Datenverarbeitung?

Im Arbeitsszenario sind wir auf eine solche Anforderung gestoßen: verwandte Informationen anderer Modelle basierend auf der IP-Adresse des Hosts zu aktualisieren. Die Anforderungen sind sehr einfach und umfassen nur allgemeine Datenbankverknüpfungsabfragen und Aktualisierungsvorgänge. Bei der Codierungsimplementierung wurde jedoch festgestellt, dass das Durchlaufen von Abfragen und Aktualisierungen viel Zeit in Anspruch nimmt Der Aufruf einer Schnittstelle dauert etwa 30–40 Sekunden.
Um die Ausführungszeit von Schnittstellenmethoden effektiv zu verkürzen, sollten Sie daher die Verwendung gleichzeitiger Multithread-Programmiermethoden in Betracht ziehen, die parallelen Ausführungsfähigkeiten von Mehrkernprozessoren nutzen und Daten asynchron verarbeiten, was die Ausführungszeit erheblich verkürzen kann und die Ausführungseffizienz verbessern.
Hier wird ein wiederverwendbarer Thread-Pool mit einer festen Anzahl von Threads FixedThreadPool verwendet, und das von der CountDownLatch-Parallelitätstoolklasse bereitgestellte Tool zur gleichzeitigen Prozesssteuerung wird in Verbindung verwendet, um sicherzustellen Paralleler Multithread-Programmierprozess Normaler Betrieb in: FixedThreadPool,并使用 CountDownLatch 并发工具类提供的并发流程控制工具作为配合使用,保证多线程并发编程过程中的正常运行:
首先,通过
Runtime.getRuntime().availableProcessors()方法获取运行机器的 CPU 线程数,用于后续设置固定线程池的线程数量。其次,判断任务的特性,如果为计算密集型任务则设置线程数为
CPU 线程数+1,如果为 IO 密集型任务则设置线程数为2 * CPU 线程数,由于在方法中需要与数据库进行频繁的交互,因此属于 IO 密集型任务。之后,对数据进行分组切割,每个线程处理一个分组的数据,分组的组数与线程数保持一致,并且还要创建计数器对象
CountDownLatch,调用构造函数,初始化参数值为线程数个数,保证主线程等待所有子线程运行结束后,再进行后续的操作。然后,调用
executorService.execute()方法,重写run方法编写业务逻辑与数据处理代码,执行完当前线程后记得将计数器减1操作。最后,当所有子线程执行完成后,关闭线程池。
在省略工作场景中的业务逻辑代码后,通用的处理方法示例如下所示:
public ResponseData updateHostDept() {
// ...
List<Map> hostMapList = mongoTemplate.find(query, Map.class, "host");
// split the hostMapList for the following multi-threads task
// return the number of logical CPUs
int processorsNum = Runtime.getRuntime().availableProcessors();
// set the threadNum as 2*(the number of logical CPUs) for handling IO Tasks,
// if Computing Tasks set the threadNum as (the number of logical CPUs) + 1
int threadNum = processorsNum * 2;
// the number of each group data
int eachGroupNum = hostMapList.size() / threadNum;
List<List<Map>> groupList = new ArrayList<>();
for (int i = 0; i < threadNum; i++) {
int start = i * eachGroupNum;
if (i == threadNum - 1) {
int end = mapList.size();
groupList.add(hostMapList.subList(start, end));
} else {
int end = (i+1) * eachGroupNum;
groupList.add(hostMapList.subList(start, end));
}
}
// update data by using multi-threads asynchronously
ExecutorService executorService = Executors.newFixedThreadPool(threadNum/2);
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
for (List<Map> group : groupList) {
executorService.execute(()->{
try {
for (Map map : group) {
// update the data in mongodb
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// let counter minus one
countDownLatch.countDown();
}
});
}
try {
// main thread donnot execute until all child threads finish
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
}
// remember to shutdown the threadPool
executorService.shutdown();
return ResponseData.success();
}那么在使用多线程异步更新的策略后,从当初调用接口所需的大概时间为 30-40 min 下降到了 8-10 min,大大提高了执行效率。
需要注意的是,这里使用的
newFixedThreadPool创建线程池,它有一个缺陷就是,它的阻塞队列默认是一个无界队列,默认值为Integer.MAX_VALUE极有可能会造成 OOM 问题。因此,一般可以使用ThreadPoolExecutor
- First, erhalten durch
Runtime.getRuntime().availableProcessors( )-Methode Die Anzahl der CPU-Threads der laufenden Maschine wird verwendet, um anschließend die Anzahl der Threads im festen Thread-Pool festzulegen.
Zweitens bestimmen Sie die Eigenschaften der Aufgabe. Wenn es sich um eine rechenintensive Aufgabe handelt, setzen Sie die Anzahl der Threads auf Anzahl der CPU-Threads + 1</. Wenn es sich um E/A-intensive Aufgaben handelt, legen Sie die Anzahl der Threads auf <code>2 * Anzahl der CPU-Threads fest. Da die Methode eine häufige Interaktion mit der Datenbank erfordert, handelt es sich um eine E/A-intensive Aufgabe.
Danach gruppieren und schneiden Sie die Daten aus. Jeder Thread verarbeitet eine gruppierte Datenmenge. Die Anzahl der gruppierten Gruppen stimmt mit der Anzahl der Threads überein erstellt außerdem< code>CountDownLatch, ruft den Konstruktor auf, initialisiert den Parameterwert auf die Anzahl der Threads und stellt sicher, dass der Hauptthread darauf wartet, dass alle untergeordneten Threads ausgeführt werden, bevor er nachfolgende Vorgänge ausführt.
Dann rufen Sie die Methode executorService.execute() auf und schreiben die Methode run neu, um Geschäftslogik zu schreiben und Denken Sie beim Datenverarbeitungscode daran, den Zähler nach der Ausführung des aktuellen Threads um 1 zu dekrementieren. Schließlich, wenn alle untergeordneten Threads die Ausführung abgeschlossen haben, schließen Sie den Thread-Pool. 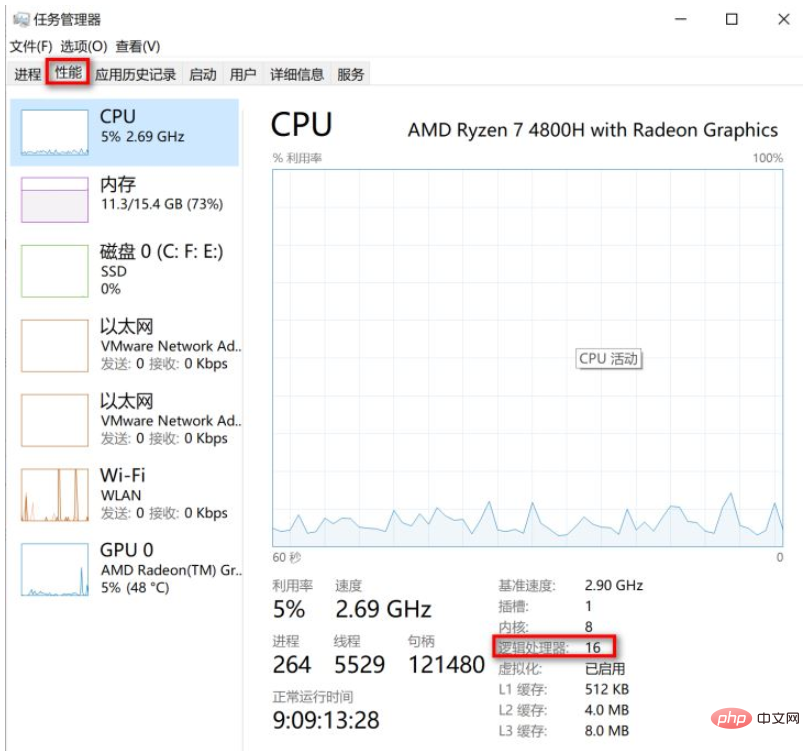
Nachdem der Geschäftslogikcode im Arbeitsszenario weggelassen wurde, lautet das allgemeine Beispiel für die Verarbeitungsmethode wie folgt:
public ResponseData updateHostDept() {
// ...
List<Map> hostMapList = mongoTemplate.find(query, Map.class, "host");
// split the hostMapList for the following multi-threads task
// return the number of logical CPUs
int processorsNum = Runtime.getRuntime().availableProcessors();
// set the threadNum as 2*(the number of logical CPUs) for handling IO Tasks,
// if Computing Tasks set the threadNum as (the number of logical CPUs) + 1
int threadNum = processorsNum * 2;
// the number of each group data
int eachGroupNum = hostMapList.size() / threadNum;
List<List<Map>> groupList = new ArrayList<>();
for (int i = 0; i < threadNum; i++) {
int start = i * eachGroupNum;
if (i == threadNum - 1) {
int end = mapList.size();
groupList.add(hostMapList.subList(start, end));
} else {
int end = (i+1) * eachGroupNum;
groupList.add(hostMapList.subList(start, end));
}
}
// update data by using multi-threads asynchronously
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 8, 30L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100));
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
for (List<Map> group : groupList) {
executor.execute(()->{
try {
for (Map map : group) {
// update the data in mongodb
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// let counter minus one
countDownLatch.countDown();
}
});
}
try {
// main thread donnot execute until all child threads finish
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
}
// remember to shutdown the threadPool
executor.shutdown();
return ResponseData.success();
}30-40 Minuten auf 8-10 Minuten, was die Ausführungseffizienz erheblich verbesserte. 🎜🎜Es ist zu beachten, dass der hier zum Erstellen eines Thread-Pools verwendetenewFixedThreadPoolden Fehler aufweist, dass seine Blockierungswarteschlange standardmäßig eine unbegrenzte Warteschlange ist und der StandardwertInteger ist. MAX_VALUEEs ist sehr wahrscheinlich, dass es zu OOM-Problemen kommt. Daher können Sie im AllgemeinenThreadPoolExecutorverwenden, um einen Thread-Pool zu erstellen, und Sie können die Anzahl der Threads in der Warteschlange angeben, um OOM-Probleme zu vermeiden. 🎜🎜rrreee🎜Im obigen Code beträgt die Anzahl der Kernthreads 5 bzw. 8. Sie sind nicht auf sehr große Werte eingestellt, da bei hohen Werten häufig der Kontext zwischen Threads gewechselt wird erhöht auch den Zeitverbrauch, kann jedoch die Vorteile von Multithreading nicht maximieren. Die Auswahl geeigneter Parameter muss anhand der Parameter der Maschine und der Art der Aufgabe festgelegt werden. 🎜🎜Wenn Sie schließlich die Anzahl der CPU-Threads der Maschine durch nicht codierende Methoden ermitteln möchten, ist dies auch sehr einfach. Im Windows-System können Sie die Anzahl der CPU-Threads über den Task-Manager anzeigen und „Leistung“ auswählen ", wie in der Abbildung unten gezeigt Anzeige: 🎜🎜🎜🎜🎜Wie Sie auf dem Bild oben sehen können, sind die Kerne in meiner Maschine acht CPUs, aber durch Hyper-Threading-Technologie kann ein physischer CPU-Kern in zwei logische simuliert werden CPU-Threads, daher unterstützt mein Computer 8 Core 16-Threads. 🎜
Das obige ist der detaillierte Inhalt vonWie stark verbessert die gleichzeitige Java-Multithread-Programmierung die Effizienz der Datenverarbeitung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Leitfaden zur Quadratwurzel in Java. Hier diskutieren wir anhand eines Beispiels und seiner Code-Implementierung, wie Quadratwurzel in Java funktioniert.
 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
