
 Technologie-Peripheriegeräte
KI
Das Ideal und die Realität eines geschlossenen Datenkreislaufs für autonomes Fahren
Technologie-Peripheriegeräte
KI
Das Ideal und die Realität eines geschlossenen Datenkreislaufs für autonomes Fahren
Das Ideal und die Realität eines geschlossenen Datenkreislaufs für autonomes Fahren

In den letzten Jahren ist der Daten-Closed-Loop zu einem heißen Thema in der Branche des autonomen Fahrens geworden, und viele Unternehmen des autonomen Fahrens versuchen, ihre eigenen Daten-Closed-Loop-Systeme aufzubauen.
Eigentlich ist der geschlossene Datenkreislauf kein neues Konzept. Im Bereich der traditionellen Softwareentwicklung wird die Datenschließung als wichtige Möglichkeit zur Verbesserung der Benutzererfahrung eingesetzt. Ich glaube, jeder hat diese Erfahrung gemacht. Wenn Sie eine Software verwenden, erscheint ein Popup-Fenster auf dem Bildschirm, in dem Sie gefragt werden: „Erlauben Sie dieser Software, Ihre Daten zu sammeln?“ Wenn Sie den entsprechenden Vorschriften zustimmen, werden die Daten gespeichert Wird verwendet, um das Benutzererlebnis zu verbessern.
Wenn die Client-Software ein Problem erkennt, kann der Hintergrund die entsprechenden Daten erfassen, und dann analysiert das Entwicklungsteam das Problem und repariert und verbessert die Software. Die neue Version der Software wird dann vom Testteam getestet Die neue Version wird in der Cloud abgelegt und vom Benutzer auf dem Terminal aktualisiert. Dies ist ein Daten-Closed-Loop-Prozess.
In autonomen Fahrszenarien werden Problemdaten normalerweise an Testfahrzeugen erfasst, und nur sehr wenige Fahrzeuge können an Serienfahrzeugen erfasst werden. Nach der Erfassung müssen die Daten mit Anmerkungen versehen werden, und dann verwenden Ingenieure die neuen Daten, um das neuronale Netzwerkmodell in der Cloud zu trainieren. Das neu trainierte Modell wird normalerweise über OTA im Fahrzeug bereitgestellt.
Ein vollständiger geschlossener Datenkreislauf umfasst normalerweise Datenerfassung, Datenrückfluss, Datenverarbeitung, Datenanmerkung, Modelltraining sowie Tests und Verifizierung.
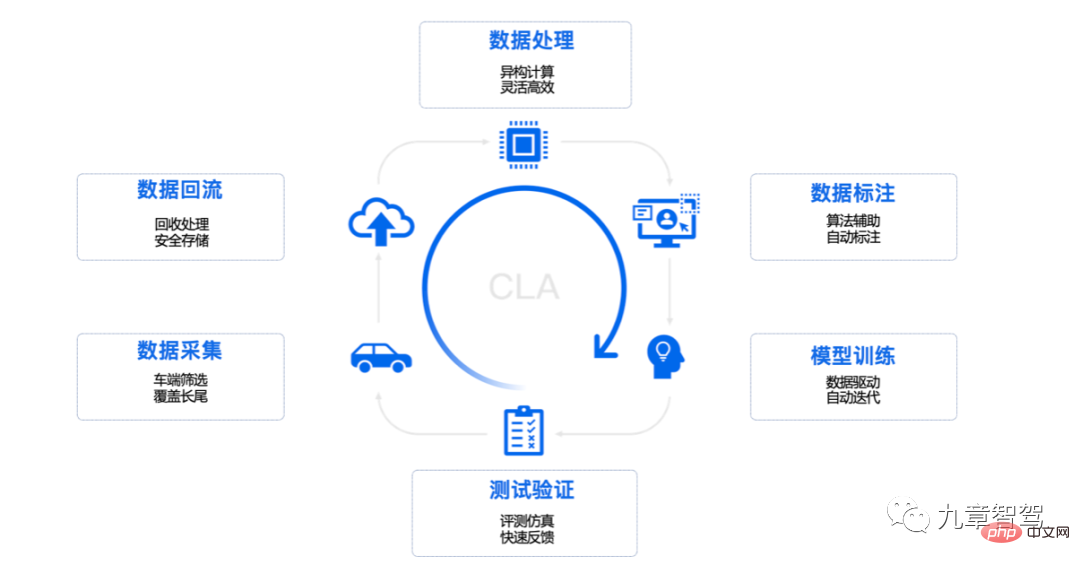
Momenta-Daten-Closed-Loop-Prozessdiagramm
Am Beispiel von Tesla sammelt eine Flotte, die mit autonomer Fahrhardware ausgestattet ist, nach Regeln und Auslösern gefilterte Daten im Schattenmodus und durchläuft die Semantik Die gefilterten Daten werden zurück an die Cloud gesendet. Anschließend verwenden Ingenieure Tools in der Cloud, um die Daten etwas zu verarbeiten, fügen die verarbeiteten Daten dann in den Datencluster ein und verwenden diese effektiven Daten dann zum Trainieren des Modells. Nachdem das Modell trainiert wurde, stellen die Ingenieure das trainierte Modell für eine Reihe von Indikatortests am Fahrzeugterminal bereit. Das verifizierte neue Modell wird zur Verwendung durch den Fahrer am Fahrzeugterminal bereitgestellt.
Unter diesem Modell wird die Rückgabe neuer Daten kontinuierlich ausgelöst und bildet so einen Zyklus. An diesem Punkt wird ein vollständiger datengesteuerter iterativer Entwicklungszyklus gebildet.
Derzeit gilt die Verwendung eines Daten-Closed-Loops zur Steuerung der Algorithmusiteration fast als die einzige Möglichkeit, die autonomen Fahrfähigkeiten zu verbessern. Viele OEMs und Tier-1-Unternehmen für autonomes Fahren bauen ihre eigenen Daten-Closed-Loop-Systeme auf und haben sogar eine eigene Position als Daten-Closed-Loop-Architekt.
Was bedeutet Daten-Closed-Loop? Was ist der Hintergrund für die Implementierung eines Daten-Closed-Loops in Massenautos? Was sind die Schwachstellen bei der Implementierung eines Daten-Closed-Loops in Serienfahrzeugen und wie geht man damit um?
Als nächstes werden diese Themen in diesem Artikel einzeln besprochen. 01 Die Bedeutung des Daten-Closed-Loops Gleichzeitig kann es je nach Art der Datenauslösung auch dazu beitragen, andere Aspekte des Systems zu optimieren, z. B. die Erkennung von Radar-/Kamerablockaden, und der Schwellenwert kann basierend auf den zurückgegebenen Daten optimiert werden Das Leistungsniveau und die Datenrückgabe können grundsätzlich alle Leistungen optimieren, z. B. AEB, LKA, ELK, ACC, TJA, NOA usw. MAXIEYE hat AEB, ACC, TJA und andere Systemfunktionen durch Datenrückgabe-OTA kontinuierlich aktualisiert und verfügt über Voreinstellungen -Eingebetteter Schattenmodus neuer Funktionen. „
Heutzutage haben verschiedene Unternehmen ihre eigenen Daten-Closed-Loop-Systeme aufgebaut. Zu den Haupteffekten, die sie erzielen möchten, gehören die Verbesserung der Effizienz der Eckfalldatenerfassung und die Verbesserung der Generalisierung Fähigkeit des Modells und die Steuerung der Iteration des Algorithmus.
1.1 Eckfalldaten sammeln
Solange das Produkt L2 und höher ist, muss es sich weiterentwickeln können. Damit sich das autonome Fahrsystem weiterentwickeln kann, ist es notwendig, kontinuierlich Eckfalldaten zu erhalten. Da immer mehr Eckfälle von „unbekannt“ auf „bekannt“ umgestellt werden, wird es immer schwieriger, neue Eckfälle durch eine begrenzte Anzahl von Testfahrzeugen mit begrenzten Formrouten auszugraben. Durch den Einsatz eines Datenerfassungssystems in Massenfahrzeugen mit breiterer Szenenabdeckung ist es eine Möglichkeit, einen Daten-Backhaul auszulösen, wenn Situationen auftreten, die das aktuelle autonome Fahrsystem nicht gut genug bewältigen kann Holen Sie sich den Eckkoffer. Zum Beispiel kann das AEB-System in einem Serienfahrzeug eingesetzt werden, das mit L2-Fahrassistenz ausgestattet ist, und dann die Daten des Fahrers sammeln, der auf die Bremse tritt. Durchtreten des Gaspedals, Durchtreten des Lenkrads und Durchschlagen des Lenkrads sowie andere Daten, um zu analysieren, warum das AEB-System nicht reagiert, wenn der Fahrer diese Vorgänge ausführt. Entsprechende Verbesserungen sollten vorgenommen werden, um das Problem anzugehen, dass das AEB-System nicht gut genug reagiert, um die Fähigkeiten des AEB-Systems zu verbessern. 1.2 Verbessern Sie die Generalisierungsfähigkeit des Modells Derzeit verlagert sich das hochgradig unterstützte Fahren von Autobahnen in die Städte. Um relativ einfache Szenarien wie Hochgeschwindigkeitsszenarien zu lösen, reicht es grundsätzlich aus, das Modell nur mit den vom Testauto gesammelten Daten zu trainieren, anstatt die Daten des Serienautos zurückgeben zu müssen. Allerdings hat die Komplexität städtischer Szenen erheblich zugenommen erhöht, und es gibt auch viele Unterschiede in den Straßenverhältnissen in verschiedenen Städten. In Guangzhou kann man zum Beispiel überall Dreiräder sehen, die Güter mit hoher Geschwindigkeit über die Straße ziehen, aber in Shanghai sieht man so etwas selten. Daher besteht bei vielen Tier-1- und Autoherstellern für autonomes Fahren eine starke Nachfrage nach Szenenintegration – das heißt, das assistierte Fahrsystem des Fahrzeugs kann verschiedene Straßenbedingungen im Mainstream richtig bewältigen Städte. Da Autohersteller die Fahrreichweite der Benutzer nicht einschränken können, wird die Reichweite der Benutzerbasis erheblich eingeschränkt, wenn die unterstützte Fahrfunktion nur für einen kleinen Bereich bereitgestellt wird. Dies ist offensichtlich nicht das, was Autounternehmen sehen möchten. Um das Ziel der Öffnungsszenarien zu erreichen, muss die Generalisierungsfähigkeit des Modells erheblich verbessert werden. Um die Generalisierungsfähigkeit des Modells erheblich zu verbessern, ist es notwendig, so viele Daten wie möglich zu sammeln, die verschiedenen Szenarien entsprechen. Nur das assistierte Fahren von Pkw, das auf umfangreichen realen menschlichen Fahrdaten basiert, ist in der Lage, Daten in ausreichendem Umfang und in ausreichender Vielfalt zu sammeln. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜#1.3 Drive-Algorithmus-Iteration#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜#Wie erwähnt früher Die Entwicklung von Algorithmen für künstliche Intelligenz auf Basis von Deep Learning hat mehr als zehn Jahre in Anspruch genommen. In dieser Zeit wurde es mit der Weiterentwicklung der Modelle und der Entwicklung der Rechenleistung für das autonome Fahrsystem möglich, große Datenmengen zu verarbeiten. Wenn das autonome Fahrsystem aktualisiert werden muss, müssen außerdem die Wahrnehmungs-, Planungs- und andere Aspekte entsprechend verbessert werden. Die Verwendung von Daten zur kontinuierlichen Weiterentwicklung des Algorithmus ist eine effiziente Möglichkeit, die Wahrnehmungs-, Planungs- und Planungsfähigkeiten zu verbessern andere Aspekte. Urban NOA – das heißt die Punkt-zu-Punkt-Navigationsassistenzfunktion in der Stadt ist der nächste Schwerpunkt vieler OEMs und autonomes Fahren Tier1, um Punkt-zu-Punkt zu erreichen -Punkt-Navigationsassistenz-Fahrfunktionen, semantische Erkennung, Hinderniserkennung und Fahrbereichserkennung des Wahrnehmungssystems müssen alle einen gewissen Grad an Genauigkeit aufweisen. Dieser Standard wurde jedoch noch nicht erreicht. Die aktuelle Netzwerkarchitektur des Mainstream-Wahrnehmungssystems basiert auf dem BEV+Transformer-Modell, das sich zur Optimierung ausschließlich auf Softwareentwickler oder Algorithmusarchitekten verlässt Verbesserung des Modells. Die Architektur von BEV+Transformer kann eine große Datenmenge aufnehmen, was den Modelleffekt voraussichtlich verbessern wird. Auf der Planungsebene kann auch der Datenantrieb eine Rolle spielen. Tesla hatte zuvor die optimale Lösung unter teilweisen Einschränkungen als Anfangswert verwendet, dann einen inkrementellen Ansatz verwendet, um kontinuierlich neue Einschränkungen hinzuzufügen, und dann das Optimierungsproblem nach dem Hinzufügen von Einschränkungen gelöst und schließlich die optimale Lösung für das Planungsproblem erhalten. Die Tesla-Ingenieure haben für diese Methode viele Offline-Vorgenerierungen durchgeführt und parallele Online-Optimierungen durchgeführt, sodass die Berechnungszeit jedes Kandidatenpfads immer noch 1 bis 5 ms beträgt. Laut Angaben von Tesla auf seinem KI-Tag am 30. September 2022 verwenden Tesla-Ingenieure nun eine Reihe datengesteuerter Modelle zur Entscheidungsbaumgenerierung, um dem autonomen Fahrsystem dabei zu helfen, schnell geplante Pfade zu generieren. Dieses datengesteuerte Entscheidungsbaum-Generierungsmodell nutzt die Fahrdaten menschlicher Fahrer in der Tesla-Flotte und den optimalen Weg ohne Zeitbeschränkungen als wahren Wert für das Training. Es kann innerhalb von 100 us einen Kandidaten-Planungsweg generieren, was die Generierungszeit erheblich verkürzt Kandidatenpläne. Aus dem oben Gesagten ist ersichtlich, dass der Aufbau eines guten Daten-Regelkreissystems eine wichtige Möglichkeit ist, die Fähigkeiten des autonomen Fahrsystems zu verbessern. 02 Hintergrund des Daten-Closed-Loops Derzeit sind viele Serienfahrzeuge mit assistiertem Fahren ausgestattet Systeme können Menschen Daten zu Massenfahrzeugen sammeln, und es ist nicht schwer, dass die Testkilometer des autonomen Fahrsystems auf der Straße 100 Millionen Kilometer überschreiten. Darüber hinaus wurde die Rechenleistung des Chips weiter verbessert – beispielsweise verfügt der OrinX-Chip von NVIDIA über eine Rechenleistung von bis zu 254 TOPS, sodass große Modelle zunehmend auf Wahrnehmungssysteme angewendet werden, was es autonomen Fahrsystemen ermöglicht, große Datenmengen zu verarbeiten. Andererseits ist die Cloud-Technologie relativ ausgereift und das autonome Fahren beginnt langsam, in das datengesteuerte Zeitalter einzutreten. Die Erklärung des Unternehmens MAXIEYE lautet: „Um genau zu sein, ist es nicht nur datengesteuert, sondern KI-Algorithmus und datengesteuerter KI-Algorithmus lösen das Problem der Lerneffizienz, und Daten lösen es.“ eine Frage der Lerninhalte. Algorithmen und Daten stehen in einer symbiotischen Beziehung In den frühen Stadien der KI war überwachtes Lernen der Mainstream in Wissenschaft und Industrie. Allerdings weist das überwachte Lernen einen schwerwiegenden Fehler auf, der darin besteht, dass es eine große Menge an manuellen Anmerkungen erfordert, was den Fortschritt der KI jedoch stark einschränkt. Es entstehen langsam unbeaufsichtigte und halbüberwachte Lernalgorithmen, die durch Selbstlernen kontinuierlich Daten bereinigen und iterieren können. Daher sind die Voraussetzungen für die Entwicklung autonomer Fahrtechnologien durch datengesteuerte Methoden ausgereift 🎜# # 🎜🎜#03 Schwachstellen und Gegenmaßnahmen für die Implementierung von Daten-Closed-Loops, die Zeit ist grundsätzlich reif für die Implementierung von Daten-Closed-Loops in Massenproduktion Fahrzeuge. Wie erfolgt also die tatsächliche Umsetzung des geschlossenen Datenkreislaufs jedes Unternehmens? Wie beurteilen wir die Wirksamkeit des Datenkreislaufsystems eines Unternehmens? Der Autor hat von der intelligenten Fahrtechnologie MAXIEYE gelernt, dass es für autonomes Fahren Tier1 technisch kein Problem ist, einen geschlossenen Datenkreislauf zu erreichen. Im Wesentlichen ist das, was wir betrachten ist die Stärke des Tier1-Produkts – ob es Automobilhersteller durch einen geschlossenen Datenkreislauf stärken kann. Zweitens hängt die Wirkung des Daten-Closed-Loop auch davon ab, ob die Iteration des Produkts durch den Daten-Closed-Loop gesteuert wird, ob die Software und der Algorithmus auf der Grundlage der zurückgegebenen Daten optimiert und regelmäßig über OTA auf dem Terminal bereitgestellt werden können. Nach den zwischen dem Autor und Brancheninsidern ausgetauschten Informationen handelt es sich bei den aktuellen Datenquellen der meisten Unternehmen um Sammelinstrumente. Aufgrund verschiedener Faktoren wie Benutzerdatenschutz, Infrastruktur und Kosten ist eine groß angelegte Datenerfassung an Massenfahrzeugen für iterative Upgrades autonomer Fahrsysteme noch nicht realisiert worden. Einige Unternehmen haben noch keinen Prozess zur Erfassung von Daten zu Serienfahrzeugen für die Datennutzung im geschlossenen Kreislauf eingerichtet. Einige Unternehmen haben zwar einen Prozess eingerichtet und einige Daten gesammelt, die Daten jedoch noch nicht sinnvoll genutzt. Es wird berichtet, dass einige Unternehmen einige Daten von Massenfahrzeugen sammeln werden, Brancheninsider berichten jedoch, dass die derzeit gesammelten Daten hauptsächlich zur Diagnose des aktuellen autonomen Fahrzeugs verwendet werden Fahrsystemstörungen usw. statt für Iterationen von Deep-Learning-Modellen. Mit anderen Worten, nur wenige Unternehmen haben den Datenkreislauf der Massenproduktion im großen Maßstab wirklich erkannt – das heißt, sie nutzen die im großen Maßstab gesammelten Daten sinnvoll Massenproduktionsfahrzeuge werden verwendet, um die Fähigkeiten autonomer Fahrsysteme zu verbessern. Was sind also die Schwachstellen der Massenproduktion von Daten im geschlossenen Kreislauf? Welche Strategien gibt es, um mit diesen Schmerzpunkten umzugehen? Zu den Problemen, die in der Praxis der Massenproduktion berücksichtigt werden müssen, gehören unter anderem: Wie kann die Einhaltung der Datenerfassung und -nutzung sichergestellt werden, wie können die Probleme gelöst werden? Problem der Datenvalidierung, Daten, wie die Erfassungsfunktion mit dem autonomen Fahrsystem koexistiert, die Schwierigkeit der Datenverarbeitung, die hohe Komplexität datengesteuerter Softwaresysteme und die Schwierigkeit des Modelltrainings usw.
3.1 Compliance-Fragen bei der Datenerhebung und -nutzung #🎜 🎜# Compliance ist in Vermessungs- und Kartierungs-Compliance und Datenschutz-Compliance unterteilt: Vermessungs- und Kartierungs-Compliance umfasst hauptsächlich Compliance bei der Erfassung nationaler geografischer Informationen, und Datenschutz-Compliance umfasst hauptsächlich Compliance bei der Erfassung datenschutzbezogener Benutzerdaten. Im Hinblick auf die Einhaltung der Vermessungs- und Kartierungsvorschriften hat das Land in den letzten Jahren sein Datensicherheitsmanagement verschärft und entsprechende Gesetze und Vorschriften eingeführt, um den Umfang der zurückgegebenen Daten zu begrenzen . Nach den „830 Neuregelungen“ im Jahr 2022 gehören die von Fahrzeugen im Straßenverkehr erfassten Daten zu den Vermessungs- und Kartierungsdaten. Wenn ein Unternehmen Vermessungs- und Kartierungsdaten nutzen möchte, sind eine nachträgliche Datenverschlüsselung und Datenkonformität unerlässlich. Zunächst einmal müssen Unternehmen beim Sammeln von Daten unterwegs über nationale Vermessungs- und Kartierungsqualifikationen verfügen und entsprechende Unterlagen einreichen, andernfalls wird der Erhebungsprozess von der nationalen Sicherheit und anderen Abteilungen blockiert. Derzeit gibt es in China insgesamt etwa 30 Institutionen mit entsprechenden Qualifikationen. Einige Unternehmen verfügen über nationale Qualifikationen für die elektronische Navigation der Klasse A, die ein breites Anwendungsspektrum haben und in vielen Städten des Landes erworben werden können Qualifikationen, die ein breites Anwendungsspektrum haben. Sie werden kleiner sein und können nur in bestimmten Städten erworben werden. Da es schwierig ist, Vermessungs- und Kartierungsqualifikationen zu erlangen, ist ein langfristiger Geschäftsaufbau erforderlich. Um die Vermessungs- und Kartierungsqualifikationen aufrechtzuerhalten, müssen Unternehmen über entsprechende Vermessungs- und Kartierungsqualifikationen verfügen Dienstleistungen. Daher vertrauen OEMs und autonomes Fahren Tier 1 im Allgemeinen qualifizierten Lieferanten oder Einheiten an. Beispielsweise unterstützen einige Cloud-Anbieter ihre Kunden jetzt bei der Entwicklung eines Compliance-Plans rund um die Erfassung, Verarbeitung und Nutzung von Daten. Nachdem die Daten erfasst wurden, müssen sie auf der Fahrzeugseite noch desensibilisiert und verschlüsselt werden. Nachdem sie in die Cloud hochgeladen wurden (im Allgemeinen handelt es sich um private Daten). Cloud) müssen einige Compliance-Arbeiten durchgeführt werden. Dieser Teil wird von qualifizierten Lieferanten oder Einheiten übernommen, die bei der Vermessung und Kartierung der Compliance helfen. Einige sehr sensible Daten müssen vom Bildhändler erfasst werden, die Daten müssen desensibilisiert und auf dem vom Bildhändler überwachten Server gespeichert werden. Darüber hinaus dürfen Vermessungs- und Kartierungsdaten nicht weitergegeben werden, insbesondere dürfen die Daten nicht ins Ausland verschoben werden. Nicht-chinesische Staatsangehörige können weder Vermessungs- und Kartierungsdaten erhalten noch operieren innerhalb des Unternehmens. Vermessungs- und Kartierungsdaten. Im Allgemeinen werden OEMs und autonomes Fahren Tier1 ihre eigenen Rechenzentren einrichten. Aus Sicherheitsgründen sind diese Rechenzentren relativ geschlossen. Wenn OEMs und Tier 1 für autonomes Fahren die in diesen Rechenzentren gespeicherten Daten nutzen müssen, um auf der Grundlage von Compliance-Anforderungen Schulungen, Simulationen usw. durchzuführen, müssen entsprechende Modelle zur Verwendung im Rechenzentrum bereitgestellt werden. Einige Branchenexperten sagten: „Der Compliance-Prozess für Vermessung und Kartierung ist zu kompliziert, und alle hoffen, ihre Abhängigkeit von Hochpräzision zu verringern.“ Dies ist einer der Gründe, warum die Lösung „starke Wahrnehmung und leichte Karte“ derzeit in der Branche beliebt ist, aber tatsächlich ist die leichte Karte nicht unbedingt „besser“, da die Wirkung von Kartendaten vorhanden ist Auf jeden Fall ist es besser, als es nicht zu haben. Es muss nicht unbedingt die beste sein, aber jeder hofft, es einfacher zu machen. Ähnlich wie bei der Nutzung von WeChat verlangen Unternehmen von den Nutzern, dass sie zu Beginn eine Autorisierungsvereinbarung unterzeichnen und die Nutzer darüber informieren, welche Daten erfasst und welches Nutzungsverhalten aufgezeichnet werden. Derzeit hat das Land im Hinblick auf die Einhaltung des Datenschutzes noch keinen besonders konkreten Plan herausgegeben, der festlegt, welche Daten gesammelt werden können und welche nicht, sondern nur einen relativ weit gefasste Klausel, die festlegt, dass Datensammler „die Privatsphäre der Benutzer nicht preisgeben dürfen“. Im tatsächlichen Betrieb müssen Daten im Zusammenhang mit Benutzerinformationen desensibilisiert werden, beispielsweise muss das Nummernschild ausgeblendet werden usw. 3.2 Datenbestätigungsproblem Können wir das in der Wie wäre es mit der Erfassung von Daten aus Kameras, Lasern oder Millimeterwellen, die die Branche des autonomen Fahrens benötigt? Moshi Intelligent Product Manager Su Linfei stellte vor: „Gemäß den einschlägigen Bestimmungen des chinesischen „Gesetzes zum Schutz personenbezogener Daten“ unterliegt die nicht gesetzlich zulässige Datenerfassung dem Datenschutz In Deutschland hat das ehemalige Bundesamt für Informationssicherheit festgelegt, dass das Aufzeichnen der Gesichter und Fahrzeuge anderer Fahrer ohne Zustimmung der anderen Partei einen Verstoß gegen das Datenschutzgesetz darstellt Wenn der Autobesitzer die Informationen anderer Personen aufzeichnet, kann dies jedoch illegal sein. Da die Branche des autonomen Fahrens im Zusammenhang mit Fahrzeugen mit neuer Energie noch sehr neu ist, fehlen jedoch noch die gesetzlichen Bestimmungen „# 🎜🎜# Können die von Autobesitzern, die ihre eigenen Fahrzeuge nutzen, gesammelten Daten zur Nutzung durch andere Einheiten autorisiert werden?“ Aktuell gibt es keine relevanten gesetzlichen Regelungen und Einschränkungen. In anderen Branchen wie Mobiltelefonen und Internet ist dies jedoch weitgehend zulässig. Wer kann die vom Autobesitzer hochgeladenen Daten erhalten? Aus Sicht der Arbeitsteilung in der Automobilindustrie gibt es zwei Arten von Unternehmen, die unbemannte Flotten betreiben, wie beispielsweise Baidu 2 Typen sind OEMs. Da Ersteres jedoch relativ klein ist, konzentrieren wir uns auf Letzteres. Da der OEM dem Benutzer am nächsten ist, ist es am einfachsten, die vom Benutzer hochgeladenen Daten zu erhalten. Weltweit ist Tesla in dieser Hinsicht der beste OEM. Derzeit öffnen OEMs selten Daten für die Außenwelt. Nachdem autonomes Fahren Tier 1 OEMs bei der Implementierung OEM-kundenspezifischer Funktionen unterstützt, ist es schwierig, Benutzer-Feedback-Daten bei der Verwendung dieser Funktionen zu sammeln, es sei denn Tier1 verfügt über viele eigene Testfahrzeuge. Dann wird es für das autonome Fahren der Stufe 1 schwierig sein, eine anschließende Optimierung relevanter Funktionen auf der Grundlage von Benutzer-Feedback-Daten durchzuführen, und es wird schwierig sein, einen geschlossenen Datenkreislauf zu erreichen. Moshi Intelligent Product Manager Su Linfei sagte dem Autor: „Nachdem wir ein Projekt für den OEM abgeschlossen hatten, wäre es schwierig, wenn der OEM die Datenschnittstelle nicht öffnen würde.“ Nachdem wir Benutzer-Feedbackdaten erhalten hatten, haben wir die Produktleistung für dieses Modell weiter iteriert. Am Ende wurden die meisten Anbieter von autonomen Fahrsystemen zu Unternehmen mit Projektbetrieb und wurden nach und nach eliminiert, da die Produktleistung zurückblieb 🎜# Wenn OEMs die Daten nicht für Lieferanten offenlegen, sollten sie den Wert der Daten selbst erkunden. Anfangs kannte niemand den konkreten Wert dieser Daten. Erst durch deren Nutzung konnte der Wert langsam entdeckt werden. Der OEM kann die Daten zunächst an Lieferanten weitergeben und eine Kopie für sich behalten. Der Lieferant kann sie dann an den OEM zurückgeben, nachdem er den Wert der Daten erkannt hat. Jetzt werden einige OEMs von Lieferanten verlangen, dass sie ihnen weiterhin bei der Software-Iteration nach dem Sop helfen, und Lieferanten können dies auch als Gelegenheit nutzen, um Daten zu erhalten, also Erstens, OEMs und Lieferanten können eine Win-Win-Situation erreichen. Aus Sicht des OEM weist diese Methode natürlich noch einige Mängel auf, da es für Lieferanten schwierig ist, zu garantieren, dass der Effekt nach Iterationen besser wird. Für OEMs ist es auch schwierig, die Auswirkungen von Iterationen zu überprüfen. Daher verlangen OEMs häufig von Lieferanten, dass sie Schnittstellen für Daten zu Zwischenergebnissen (z. B. Ergebnisse der Erkennung von Wahrnehmungszielen) öffnen, damit OEMs die Iterationen von Lieferanten anhand statistischer Indikatoren für Zwischenergebnisse überprüfen können . Wirkung. Derzeit ist es vor allem erforderlich, dass beide Parteien eine Mentalität des gegenseitigen Vertrauens und der aufrichtigen Zusammenarbeit haben. Der OEM sollte dem Lieferanten das Recht zur Datennutzung eröffnen Der Lieferant kann die Software regelmäßig aktualisieren und entsprechende Auswirkungen erkennen, sodass die Zusammenarbeit fortgesetzt werden kann. Es ist nur so, dass dieses Modell noch keine breite Akzeptanz gefunden hat, weil nicht jeder offensichtliche Auswirkungen gesehen hat. 3.3 Die Datenerfassung belegt Systemressourcen In Massenproduktion Das Sammeln von Daten über das Fahrzeug beansprucht einige Systemressourcen, wie z. B. Rechen- und Speicherkapazität. Theoretisch kann davon ausgegangen werden, dass die Rechenressourcen, die Netzwerkbandbreite usw. nicht begrenzt sind. Wie kann jedoch sichergestellt werden, dass die gesammelten Daten den normalen Betrieb des autonomen Fahrsystems in der Massenproduktion nicht beeinträchtigen? Fahrzeuge, zum Beispiel, wie man die Verzögerung des autonomen Fahrsystems nicht beeinträchtigt, ist ein Problem, das gelöst werden muss. Natürlich laden einige Unternehmen Daten hoch, wenn das autonome Fahrsystem nicht läuft, sodass kein Problem mit der Ressourcenbelegung besteht. Einige Leute in der Branche glauben jedoch, dass das Hochladen von Daten nur dann, wenn das autonome Fahrsystem nicht läuft, die Menge der gesammelten Daten begrenzen wird. In dieser Phase ist es immer noch notwendig, so viele Daten wie möglich zu sammeln. Beim Entwurf müssen dann die Auswirkungen der Datenerfassung auf den Betrieb des autonomen Fahrsystems berücksichtigt werden. 3.4 Datenannotation und anschließende Verarbeitung sind schwierig Laut Es wird geschätzt, dass nach der Rückübertragung der Daten vom Serienfahrzeug die täglich vom Fahrrad zurückgesendete Datenmenge etwa 100 Megabyte beträgt. Im Forschungs- und Entwicklungsstadium kann die Gesamtzahl der Fahrzeuge nur einige Dutzend oder einige Hundert betragen. Aber in der Massenproduktionsphase kann die Zahl der Fahrzeuge Zehntausende, Hunderttausende oder sogar mehr erreichen. In der Massenproduktionsphase ist die Datenmenge, die die gesamte Flotte täglich generiert, enorm. Die stark zunehmende Datenmenge hat sowohl den Speicherplatz als auch die Datenverarbeitungsgeschwindigkeit vor Herausforderungen gestellt. Nach der Massenproduktion muss die Latenz der Datenverarbeitung auf dem gleichen Niveau wie in der Forschungs- und Entwicklungsphase gehalten werden. Wenn die zugrunde liegende Infrastruktur jedoch nicht mithalten kann, kommt es mit zunehmender Datenmenge zu entsprechend längeren Verzögerungen bei der Datenverarbeitung, was den Fortschritt des Forschungs- und Entwicklungsprozesses erheblich verlangsamt. Für die Systemiteration ist diese Effizienzminderung nicht akzeptabel. Ein Branchenexperte sagte dem Autor: „Derzeit haben wir kein Unternehmen gesehen, das in der Lage ist, die großen Datenmengen zu verarbeiten, die von Massenfahrzeugen zurückgegeben werden. Nicht einmal ein Unternehmen, das innovativere Arbeit leistet.“ die Daten-Closed-Loop-Ebene Neue Automobilhersteller, selbst wenn jedes Serienauto nur 5 Minuten Daten pro Tag zurücksendet, werden sie Schwierigkeiten haben, mit einer solchen Datenmenge umzugehen, weil aktuelle Speichergeräte, Dateilesesysteme, Computertools usw. können die riesige Datenmenge noch nicht bewältigen.“ Das Engineering-Team muss ein vollständiges Datenzugriffs-SDK entwickeln. Da die Dateigrößen von visuellen Daten und Radardaten sehr groß sind, müssen die Datenzugriffs-, Abfrage-, Sprung- und Dekodierungsprozesse effizient genug sein, da sonst der Forschungs- und Entwicklungsfortschritt stark verlangsamt wird. Nachdem die fahrzeugseitigen Daten zurück in die Cloud übertragen wurden, muss das Ingenieurteam eine große Datenmenge zeitnah kennzeichnen. Die Branche verwendet derzeit vorab trainierte Modelle für Hilfsannotationen. Bei großen Datenmengen erfordert die Annotation jedoch immer noch viel Arbeit. Beim Etikettieren von Daten müssen Sie auch die Konsistenz der Etikettierungsergebnisse sicherstellen. Derzeit hat die Branche noch keine vollautomatische Datenannotation implementiert und erfordert immer noch manuelle Arbeit, um einen Teil der Arbeitslast zu erledigen. Im manuellen Betrieb ist es ebenfalls eine große Herausforderung, die Konsistenz der Etikettierungsergebnisse bei großen Datenmengen sicherzustellen. Darüber hinaus sind die Daten rund um das autonome Fahren nicht nur umfangreich, sondern auch unterschiedlicher Art, was die Datenverarbeitung ebenfalls erschwert. Datentypen werden nach Quelle unterteilt, einschließlich Fahrzeugdaten, Standortdaten, Umgebungserfassungsdaten, Anwendungsdaten, personenbezogenen Daten usw., und nach Format unterteilt, einschließlich strukturierter Daten und unstrukturierter Daten, und Datendiensttypen umfassen Dateien, Objekte, usw. Die Vereinheitlichung von Standards und die Koordinierung verschiedener Arten von Speicher- und Zugriffsschnittstellen sind ebenfalls ein großes Problem. 3.5 Datengesteuerte Softwaresysteme sind hochkomplex Das traditionelle V-förmige Entwicklungsmodell lässt sich nur schwer auf geschlossene Datenkreisläufe anwenden. Darüber hinaus gibt es derzeit in der Branche keine einheitliche Softwareentwicklungsplattform und Middleware für autonomes Fahren auf hohem Niveau. Ein technischer Experte aus der Abteilung für autonomes Fahren eines Unternehmens sagte dem Autor: „Das auf Daten und Deep-Learning-Modellen basierende Iterationssystem für autonome Fahrfunktionen kann als Software 2.0 bezeichnet werden. In diesem Modell ist das gesamte System, einschließlich der Teambildung.“ „ In der Software-1.0-Ära ist es einfach zu bewerten, welchen Code jeder einreicht und welche Auswirkungen er erwartet. Im Software-2.0-Zeitalter ist es jedoch schwieriger geworden, die Auswirkung des Beitrags jedes Einzelnen auf die Gesamtwirkung zu messen, und es ist auch schwierig, sie im Voraus vorherzusagen, da das, was alle miteinander kommunizieren, kein klar sichtbarer Code mehr ist. sondern Daten und datenbasierte Kommunikation. Wenn die Datenmenge sehr gering ist, beispielsweise als wir am AI-Vision-Algorithmus für mobile Internetanwendungen arbeiteten, verwalteten die beteiligten visuellen Modellingenieure aufgrund der geringen Datenmenge grundsätzlich ihre eigenen Ordner in Windows oder Ubuntu, und die Teammitglieder verwenden direkt verschiedene umbenannte Ordner, um untereinander hin und her zu übertragen, was für den Datenaustausch oder die Zusammenarbeit sehr ineffizient ist. Aber wenn es um autonome Fahraufgaben geht, stehen wir vor Hunderttausenden Bildern, und Hunderte von Menschen entwickeln gemeinsam ein System. Jede Änderung umfasst Hunderte oder sogar Tausende von Modulen. Die Bewertung der Codequalität jedes Moduls und die Überprüfung, ob Konflikte zwischen Modulen vorliegen, sind relativ komplexe Aufgaben. Bisher denke ich, dass dieses System immer noch schlecht ist und der technische Teil nicht ausgereift genug ist. In der Phase der Software 2.0 müssen noch folgende Probleme angegangen werden: Wie lässt sich die Auswirkung neuer Daten auf bestimmte Szenarien und die Gesamtsituation messen und wie kann vermieden werden, dass Neuschulungsmodelle auf der Grundlage neuer Daten bei einigen scheitern? Bei bestimmten Aufgaben wird der Effekt besser, aber insgesamt nimmt der Effekt ab. Um diese Probleme zu lösen, müssen wir Unit-Tests durchführen, um zu prüfen, ob das Hinzufügen einiger Daten den segmentierten Szenarien, die wir lösen möchten, und der Gesamtsituation hilft. Wenn beispielsweise für eine bestimmte Aufgabe der ursprüngliche Datensatz 20 Millionen Bilder umfasst und dann 500 neue Bilder hinzugefügt werden, verbessert sich die Fähigkeit, diese bestimmte Aufgabe zu lösen, aber manchmal bedeutet dies auch dass sich die Punktzahl des Modells bei der Bearbeitung globaler Aufgaben verringert. Darüber hinaus müssen wir bei visuellen Aufgaben nicht nur die Auswirkungen neuer Daten auf das Modell anhand von Indikatoren beurteilen, sondern auch tatsächlich sehen, was die konkreten Auswirkungen sind , damit wir wissen können, ob die Optimierung den Erwartungen entspricht. Allein die Betrachtung der Indikatoren kann dazu führen, dass sich die Indikatoren zwar verbessert haben, die tatsächlichen Ergebnisse jedoch immer noch nicht den Erwartungen entsprechen. Wir benötigen außerdem eine Reihe von Infrastrukturen, um sicherzustellen, dass jedes Update global optimal ist. Diese Infrastruktur umfasst Datenmanagement, Trainingsauswertung usw. Tesla ist in dieser Hinsicht führend in der Branche. Seine gesamte datengesteuerte Verbindung ist von Anfang an darauf ausgelegt, die Branche anzuführen, und von 2019 bis 2022 werden keine großen Änderungen erforderlich sein, um seine Produkte zu unterstützen. 3.6 Die Schwierigkeit des Modelltrainings wird erhöht löst das Problem der Datenerfassung. Nachdem Probleme wie Speicherung und Annotation gelöst sind, stellen das anschließende Modelltraining und die Funktionsiteration immer noch Herausforderungen dar. Die große Datenmenge, die vom Trainings-Massenproduktionsfahrzeug zurückgegeben wird, erfordert ein effizientes Dateiübertragungssystem, um sicherzustellen, dass sie während des Trainings nicht durch E/A „hängen bleibt“. Gleichzeitig muss ausreichend Rechenleistung vorhanden sein. Die Möglichkeit, die Rechenleistung zu verbessern, besteht normalerweise darin, einen parallelen Cluster mit mehreren Karten aufzubauen. Dann ist es auch ein Problem, wie man während des Trainings eine effiziente Kommunikation zwischen den Karten aufrechterhält, um Verzögerungen bei der Datenübertragung zu reduzieren und die Rechenleistung jeder Karte vollständig und effektiv zu nutzen muss berücksichtigt werden. Um den Bedarf an Rechenleistung im Modelltraining zu bewältigen, haben einige OEMs eigens eigene intelligente Rechenzentren gebaut. Allerdings sind die Kosten für den Aufbau eines intelligenten Rechenzentrums sehr hoch und für kleine und mittlere Unternehmen nahezu unmöglich. Obwohl es immer noch viele Schmerzpunkte gibt, können wir dennoch damit rechnen, dass die aktuellen Probleme im Laufe der Zeit nach und nach gelöst werden. Bis dahin kann der Daten-Closed-Loop tatsächlich in Massenfahrzeugen implementiert werden, und die nach der Implementierung in Massenfahrzeugen gesammelten Daten werden das Daten-Closed-Loop-System rückkoppeln und das autonome Fahrsystem auf ein höheres Niveau bringen.
Derzeit kann autonomes Fahren Tier 1 je nach Grad der Daten-Closed-Loop-Fähigkeit in drei Kategorien unterteilt werden: Die erste ist die erreichte Daten-Closed-Loop Die zweite besteht darin, einen geschlossenen Kreislauf durch Sammelfahrzeuge zu erreichen, und der dritte besteht darin, noch nicht in der Lage zu sein, einen geschlossenen Datenkreislauf zu erreichen. Der erste Typ ist derzeit noch in der Minderheit.
Das obige ist der detaillierte Inhalt vonDas Ideal und die Realität eines geschlossenen Datenkreislaufs für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
