
 Technologie-Peripheriegeräte
KI
Eine kurze Analyse der Roadmap der visuellen Wahrnehmungstechnologie für autonomes Fahren
Technologie-Peripheriegeräte
KI
Eine kurze Analyse der Roadmap der visuellen Wahrnehmungstechnologie für autonomes Fahren
Eine kurze Analyse der Roadmap der visuellen Wahrnehmungstechnologie für autonomes Fahren

01 Hintergrund
Autonomes Fahren ist ein schrittweiser Übergang von der Vorhersagephase zur Industrialisierungsphase. Die spezifische Leistung kann in vier Punkte unterteilt werden. Erstens nimmt der Umfang der Datensätze im Zusammenhang mit Big Data rapide zu. Dadurch werden Details von Prototypen, die zuvor an kleinen Datensätzen entwickelt wurden, weitgehend herausgefiltert und nur Arbeiten durchgeführt, die bei großen Datensätzen effektiv sein können -Maßstabsdaten bleiben übrig. Der zweite Grund ist die Verschiebung des Fokus von monokularen zu Multiview-Szenen, was zu einer Erhöhung der Komplexität führt. Hinzu kommt die Tendenz zu anwendungsfreundlichen Designs, etwa der Verlagerung des Ausgaberaums vom Bildraum in den BEV-Raum.
Schließlich sind wir vom reinen Streben nach Genauigkeit zu einer schrittweisen Berücksichtigung der Inferenzgeschwindigkeit übergegangen. Gleichzeitig ist in autonomen Fahrszenarien eine schnelle Reaktion erforderlich, sodass die Leistungsanforderungen die Geschwindigkeit berücksichtigen. Darüber hinaus wird stärker berücksichtigt, wie die Bereitstellung auf Edge-Geräten erfolgt.
Ein weiterer Hintergrund ist, dass sich die visuelle Wahrnehmung in den letzten 10 Jahren durch Deep Learning rasant weiterentwickelt hat. Es gab viel Arbeit und einige recht ausgereifte Paradigmen in Mainstream-Richtungen wie Klassifizierung, Erkennung und Segmentierung . Im Entwicklungsprozess der visuellen Wahrnehmung in autonomen Fahrszenarien wurden Aspekte wie die Zieldefinition der Merkmalskodierung, das Wahrnehmungsparadigma und die Überwachung stark von diesen Hauptrichtungen übernommen. Daher sollten diese Hauptrichtungen untersucht werden, bevor man sich auf die Wahrnehmung des autonomen Fahrens einlässt. Probieren Sie ein bisschen.
Vor diesem Hintergrund sind im vergangenen Jahr zahlreiche 3D-Zielerkennungsarbeiten an großen Datensätzen entstanden, wie in Abbildung 1 dargestellt (die rot markierten sind die ersten Algorithmen).
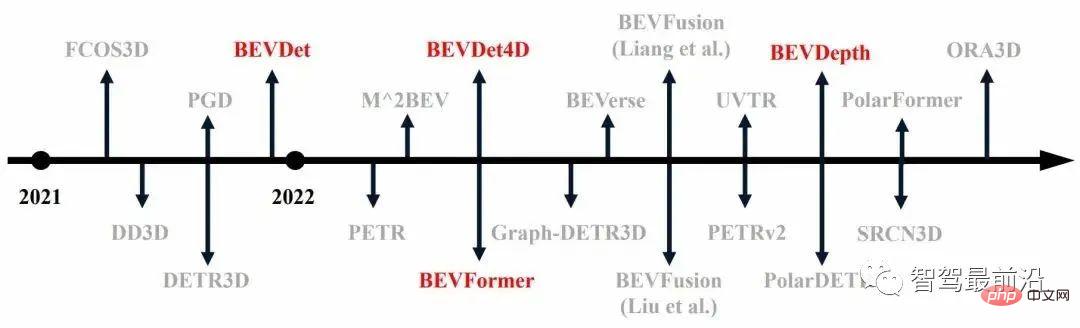
Abbildung 1 Entwicklung der 3D-Zielerkennung im vergangenen Jahr
02 Technische Route
2.1. Heben
Visuelle Wahrnehmung und der Unterschied Der Unterschied zwischen der visuellen Mainstream-Wahrnehmung liegt hauptsächlich im Unterschied im gegebenen Zieldefinitionsraum. Das Ziel der visuellen Mainstream-Wahrnehmung wird im Bildraum definiert, während das Ziel der autonomen Fahrszene im dreidimensionalen Raum definiert wird. Wenn es sich bei den Eingaben ausschließlich um Bilder handelt, ist zum Erhalten der Ergebnisse im dreidimensionalen Raum ein Lift-Prozess erforderlich. Dies ist das Kernproblem der visuellen Wahrnehmung beim autonomen Fahren.
Wir können die Methode zur Lösung des Lift-Objektproblems in Eingabe, Zwischenmerkmale und Ausgabe unterteilen. Ein Beispiel für die Eingabeebene ist die Verwendung des Bildes, um über die Tiefeninformationen nachzudenken und sie dann zu verwenden Konvertieren Sie anhand der Tiefeninformationen den RGB-Wert des Bildes in einen dreidimensionalen Raum, um eine farbige Punktwolke zu erhalten, und folgen Sie dann der zugehörigen Arbeit zur Punktwolkenerkennung.
Derzeit sind die vielversprechenderen Transformationen auf Feature-Ebene oder der Lift auf Feature-Ebene, wie z. B. DETR3D, die alle räumliche Änderungen auf Feature-Ebene durchführen. Der Vorteil der Transformation auf Feature-Ebene besteht darin, dass eine wiederholte Extraktion vermieden werden kann Die geringe Menge an Funktionen und Berechnungen auf Bildebene kann auch das Problem der Fusion von Lookaround-Ergebnissen auf Ausgabeebene vermeiden. Natürlich weist die Konvertierung auf Funktionsebene auch einige typische Probleme auf, z. B. werden normalerweise einige seltsame OPs verwendet, was die Bereitstellung unfreundlich macht.
Derzeit basiert der relativ robuste Lift-Prozess auf Feature-Ebene hauptsächlich auf Strategien für Tiefen- und Aufmerksamkeitsmechanismen. Die repräsentativen Strategien sind BEVDet bzw. DETR3D. Die tiefenbasierte Strategie besteht darin, einen Lift-Prozess abzuschließen, indem die Tiefe jedes Bildpunkts berechnet und die Merkmale dann gemäß dem Bildmodell der Kamera in einen dreidimensionalen Raum projiziert werden. Die auf dem Aufmerksamkeitsmechanismus basierende Strategie besteht darin, ein Objekt im dreidimensionalen Raum als Abfrage vorzudefinieren, die dem Mittelpunkt des dreidimensionalen Raums entsprechenden Bildmerkmale als Schlüssel und Wert über interne und externe Parameter zu finden und dann zu berechnen ein dreidimensionales Objekt durch Aufmerksamkeit.
Alle aktuellen Algorithmen sind grundsätzlich stark abhängig von Kameramodellen, egal ob tiefenbasiert oder aufmerksamkeitsbasiert, was zu Kalibrierungsempfindlichkeit und allgemein komplexen Berechnungsprozessen führt. Algorithmen, die auf Kameramodelle verzichten, sind oft nicht robust genug, sodass dieser Aspekt noch nicht vollständig ausgereift ist.
2.2 Zeitlich
Zeitliche Informationen können die Wirkung der Zielerkennung effektiv verbessern. Für autonome Fahrszenarien hat das Timing eine tiefere Bedeutung, da die Geschwindigkeit des Ziels eines der Hauptwahrnehmungsziele im aktuellen Szenario ist. Der Schwerpunkt der Geschwindigkeit liegt auf der Änderung. Da einzelne Frame-Daten nicht über ausreichende Änderungsinformationen verfügen, ist eine Modellierung erforderlich, um Änderungsinformationen in der Zeitdimension bereitzustellen. Die bestehende Methode zur Modellierung von Punktwolken-Zeitreihen besteht darin, die Punktwolken mehrerer Frames als Eingabe zu mischen, sodass eine relativ dichte Punktwolke erhalten werden kann, wodurch die Erkennung genauer wird. Darüber hinaus enthalten Multi-Frame-Punktwolken kontinuierliche Informationen. Später, während des Netzwerktrainingsprozesses, wird BP verwendet, um zu lernen, wie diese kontinuierlichen Informationen extrahiert werden, um Aufgaben wie Geschwindigkeitsschätzungen zu lösen, die kontinuierliche Informationen erfordern.
Die Timing-Modellierungsmethode der visuellen Wahrnehmung stammt hauptsächlich von BEVDet4D und BEVFormer. BEVDet4D stellt kontinuierliche Informationen für nachfolgende Netzwerke bereit, indem es einfach ein Feature aus zwei Frames zusammenführt. Der andere Weg basiert auf Aufmerksamkeit, indem er sowohl Einzelzeitrahmen- als auch Gegenuhrzeigersinnsmerkmale als Abfrageobjekt bereitstellt und diese beiden Merkmale dann gleichzeitig durch Aufmerksamkeit abfragt, um Zeitinformationen zu extrahieren.
2,3 Tiefe
Visuelle Wahrnehmung beim autonomen Fahren im Vergleich zu Radar One Einer der größten Nachteile der Wahrnehmung ist die Genauigkeit der Tiefenschätzung. Der Artikel „Probabilistische und geometrische Tiefe: Objekte in der Perspektive erkennen“ untersucht den Einfluss verschiedener Faktoren auf die Leistungsbewertung durch Ersetzen der GT-Methode. Die wichtigste Schlussfolgerung aus der Analyse ist, dass eine genaue Tiefenschätzung erhebliche Leistungsverbesserungen bringen kann.
Aber die Tiefenschätzung ist ein großer Engpass in der aktuellen visuellen Wahrnehmung. Derzeit gibt es zwei Möglichkeiten, sie zu verbessern. Eine besteht darin, geometrische Einschränkungen zur Vorhersage von PGD zu verwenden. Die Tiefenkarte wurde verfeinert. Die andere besteht darin, Lidar als Überwachung zu verwenden, um eine robustere Tiefenschätzung zu erhalten.
Die derzeit überlegene Lösung im Prozess, BEVDepth, verwendet die von Lidar während des Trainingsprozesses bereitgestellten Tiefeninformationen, um die Tiefenschätzung während des Änderungsprozesses zu überwachen Wahrnehmungsaufgaben werden gleichzeitig ausgeführt.
2.4 Muti-Modalität/Multi-Task
Multi- Tasking Es besteht die Hoffnung, dass eine Vielzahl von Wahrnehmungsaufgaben in einem einheitlichen Rahmen erledigt werden können und durch diese Berechnung der Zweck der Ressourceneinsparung oder der Beschleunigung des rechnerischen Denkens erreicht werden kann. Die aktuellen Methoden erreichen jedoch grundsätzlich Multitasking, indem sie die Funktionen einfach auf verschiedenen Ebenen verarbeiten, nachdem sie eine einheitliche Funktion erhalten haben. Es besteht ein häufiges Problem der Leistungsverschlechterung nach dem Zusammenführen von Aufgaben. Multimodalität ist auch nahezu universell, wenn es darum geht, eine Form zu finden, die im gesamten Urteil direkt verschmolzen werden kann, und dann eine einfache Verschmelzung zu erreichen.
03 BEVDet. Serie
#🎜 🎜 #3.1 BEVDet
BEVDet-Netzwerk ist in Abbildung 2 dargestellt. Der Merkmalsextraktionsprozess besteht hauptsächlich darin, ein Merkmal des extrahierten Bildraums zu konvertieren In ein BEV-Raummerkmal umwandeln und dieses Merkmal dann weiter kodieren, um ein Merkmal zu erhalten, das für die Vorhersage verwendet werden kann, und schließlich die dichte Vorhersage verwenden, um das Ziel vorherzusagen.
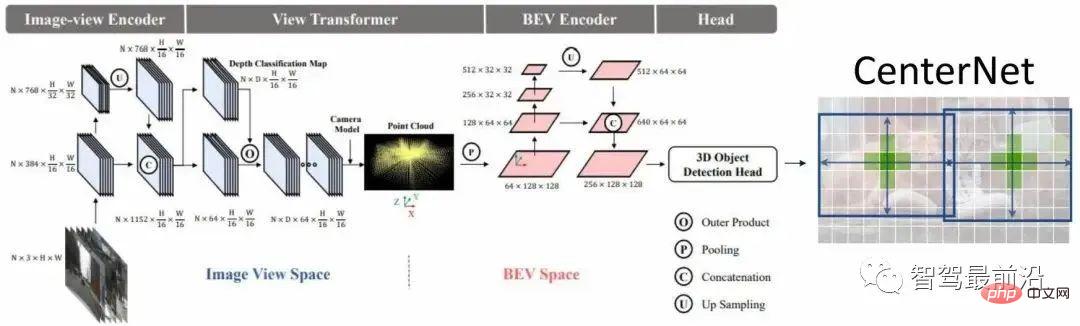
Abbildung 2 BEVDet-Netzwerkstruktur # 🎜🎜#
Der Prozess des Perspektivenänderungsmoduls ist in zwei Schritte unterteilt. Zuerst wird angenommen, dass die Größe des zu transformierenden Features VxCxHxW ist, und dann wird eine Tiefe vorhergesagt Eine Klassifizierungsmethode im Bildraum erhält eine D-dimensionale Tiefenverteilung. Anschließend können Sie diese beiden Merkmale verwenden, um unterschiedliche Tiefenmerkmale zu rendern, um ein visuelles Merkmal zu erhalten, und es dann mithilfe des Kameramodells in eine 3 projizieren -dimensionalen Raum und Voxel den dreidimensionalen Raum und führen Sie dann den Splat-Prozess durch, um die BEV-Merkmale zu erhalten.Ein sehr wichtiges Merkmal des Perspektivwechselmoduls ist, dass es eine gegenseitige Isolationsrolle bei der Datenverlangsamung spielt. Insbesondere kann durch die internen Parameter der Kamera ein Punkt im Kamerakoordinatensystem erhalten werden, indem er in einen dreidimensionalen Raum projiziert wird, wenn die Datenerweiterung auf einen Punkt im Bildraum angewendet wird, um die Koordinaten beizubehalten Der Punkt im Kamerakoordinatensystem ist invariant. Sie müssen eine umgekehrte Transformation durchführen, dh eine Koordinate im Kamerakoordinatensystem bleibt vor und nach der Erweiterung unverändert, was einen gegenseitigen Isolationseffekt hat. Der Nachteil der gegenseitigen Isolation besteht darin, dass die Erweiterung des Bildraums das Lernen des BEV-Raums nicht reguliert. Der Vorteil kann die Robustheit des BEV-Raumlernens verbessern #🎜🎜 # Aus Experimenten können wir mehrere wichtige Schlussfolgerungen ziehen. Erstens ist es nach der Verwendung des BEV-Raumencoders wahrscheinlicher, dass der Algorithmus in eine Überanpassung gerät. Eine weitere Schlussfolgerung ist, dass die Erweiterung des BEV-Speicherplatzes einen größeren Einfluss auf die Leistung haben wird als die Erweiterung des Bildspeicherplatzes. Es besteht auch eine Korrelation zwischen der Zielgröße des BEV-Raums und der Kategoriehöhe. Gleichzeitig ist die Überlappungslänge zwischen den Zielen sehr gering Es wird beobachtet, dass die nicht-maximale Unterdrückungsmethode nicht optimal ist. Der Kern der simultanen Beschleunigungsstrategie besteht darin, mithilfe paralleler Rechenmethoden unabhängige Threads verschiedenen kleinen Rechenaufgaben zuzuweisen, um den Zweck der parallelen Rechenbeschleunigung zu erreichen. Der Vorteil besteht darin, dass kein zusätzlicher Grafikspeicheraufwand entsteht. Die Netzwerkstruktur von BEVDet4D ist in der Abbildung dargestellt. 3 . Der Schwerpunkt dieses Netzwerks liegt auf der Anwendung der Features des Reverse-Time-Frames auf den aktuellen Frame. Wir wählen das Eingabe-Feature als beibehaltenes Objekt, wählen dieses Bild-Feature jedoch nicht, da die Zielvariablen im BEV-Raum definiert sind , und die Bildeigenschaften sind nicht für die direkte Timing-Modellierung geeignet. Gleichzeitig werden die Features hinter dem BEV-Encoder nicht als kontinuierliche Fusionsfeatures ausgewählt, da wir im BEV-Encoder ein kontinuierliches Feature extrahieren müssen.
Abbildung 3 BEVDet4D-Netzwerkstruktur # 🎜🎜# Wie gestaltet man Zielvariablen, die zur Netzwerkstruktur passen? Zuvor müssen wir zunächst einige Schlüsselmerkmale des Netzwerks verstehen. Das erste ist das Empfangsfeld des Features. Da das Netzwerk durch BP lernt, wird das Empfangsfeld des Features durch den Ausgaberaum bestimmt. Da die vom Perspektivenwechselmodul ausgegebenen Features relativ spärlich sind, wird nach dem Perspektivenwechsel ein zusätzlicher BEV-Encoder angeschlossen, um vorläufige BEV-Features zu extrahieren und dann einen auszuführen zeitliche Abfolge der Modellierung. Während der Timing-Fusion verbinden wir einfach die Merkmale des Gegenuhrzeigersinns mit der aktuellen Nadel, um die Fusion dieses Timings abzuschließen. Tatsächlich überlassen wir hier die Aufgabe, die Timing-Features zu extrahieren Es.
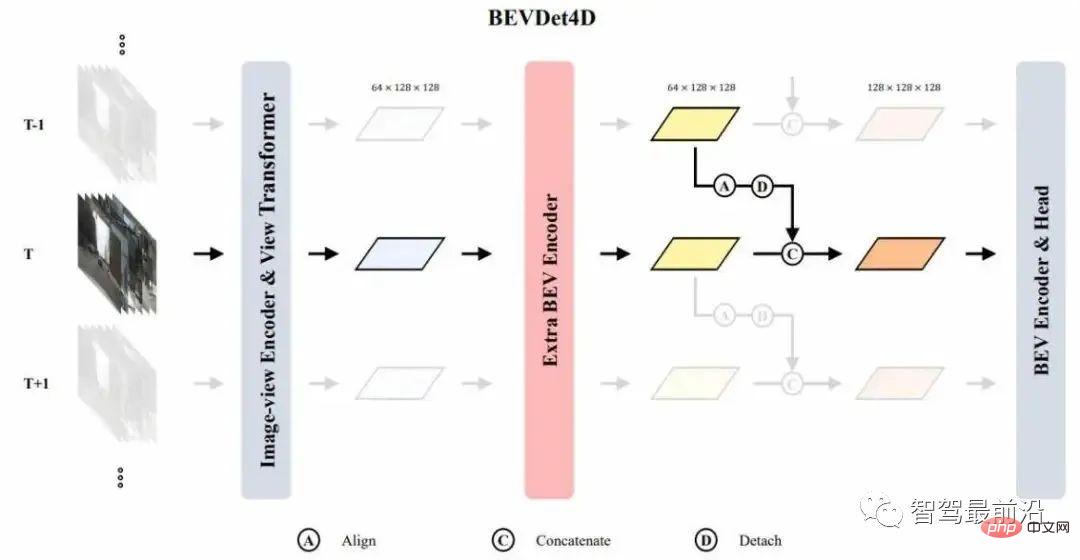
Wenn die beiden Features direkt miteinander verbunden sind, ist die Position des statischen Ziels in den beiden Feature-Maps unterschiedlich und die Position des dynamischen Ziels in der Der Versatz zwischen zwei Feature-Maps ist gleich dem selbst gemessenen Versatz plus dem Versatz des dynamischen Ziels im Weltkoordinatensystem. Gemäß dem Prinzip der Musterkonsistenz sollte es sich bei der Festlegung des Lernziels des Netzwerks um die Änderung der Position des Ziels in diesen handeln, da der Versatz des Ziels in den gespleißten Merkmalen mit dem eigenen Fahrzeug zusammenhängt zwei Feature-Maps.
Nach der folgenden Formel können wir ein Lernziel ableiten, das nicht mit der selbst getesteten Bewegung zusammenhängt, sondern nur vom Ziel im Weltkoordinatensystem abhängt Ein Sport bezogen.
Der Unterschied zwischen den Lernzielen, die wir oben abgeleitet haben, und den Lernzielen aktueller Mainstream-Methoden besteht darin, dass die Zeitkomponente entfernt wird und die Geschwindigkeit gleich der Verschiebung/Zeit ist. Diese beiden Funktionen liefern jedoch keinen Zeitbezug Hinweise, also wenn Sie dies lernen Das Geschwindigkeitsziel erfordert, dass das Netzwerk die Zeitkomponente genau schätzt, was die Lernschwierigkeit erhöht. In der Praxis können wir die Zeit zwischen zwei Frames während des Trainingsprozesses als konstanten Wert festlegen. Ein Netzwerk mit konstanten Zeitintervallen kann durch Lernen von BP erlernt werden.
Bei der Erweiterung des Zeitbereichs verwenden wir während des Trainingsprozesses zufällig unterschiedliche Zeitintervalle. In unterschiedlichen Zeitintervallen ist der Zielversatz in den beiden Bildern unterschiedlich, und auch der Zielversatz des Lernens ist unterschiedlich , um den Lupineneffekt des Modells bei verschiedenen Offsets zu erzielen. Gleichzeitig weist das Modell eine gewisse Empfindlichkeit gegenüber dem Versatz des Ziels auf. Das heißt, wenn das Intervall zu klein ist, ist die Änderung zwischen zwei Bildern schwer zu erkennen, wenn es zu klein ist. Daher kann die Wahl eines geeigneten Zeitintervalls während des Tests die Generalisierungsleistung des Modells effektiv verbessern.
3.3 BEVDepth
Dieser Artikel verwendet Radar, um eine robuste Tiefenschätzung zu erhalten, wie in Abbildung 4 dargestellt. Es verwendet Punktwolken zur Überwachung der Tiefenverteilung im Änderungsmodul. Diese Überwachung ist im Vergleich zur vom Ziel bereitgestellten Tiefenüberwachung dicht, aber sie erreicht auch nicht jedes Pixel. Es können jedoch mehr Stichproben bereitgestellt werden, um die Generalisierungsleistung dieser Tiefenschätzung zu verbessern.
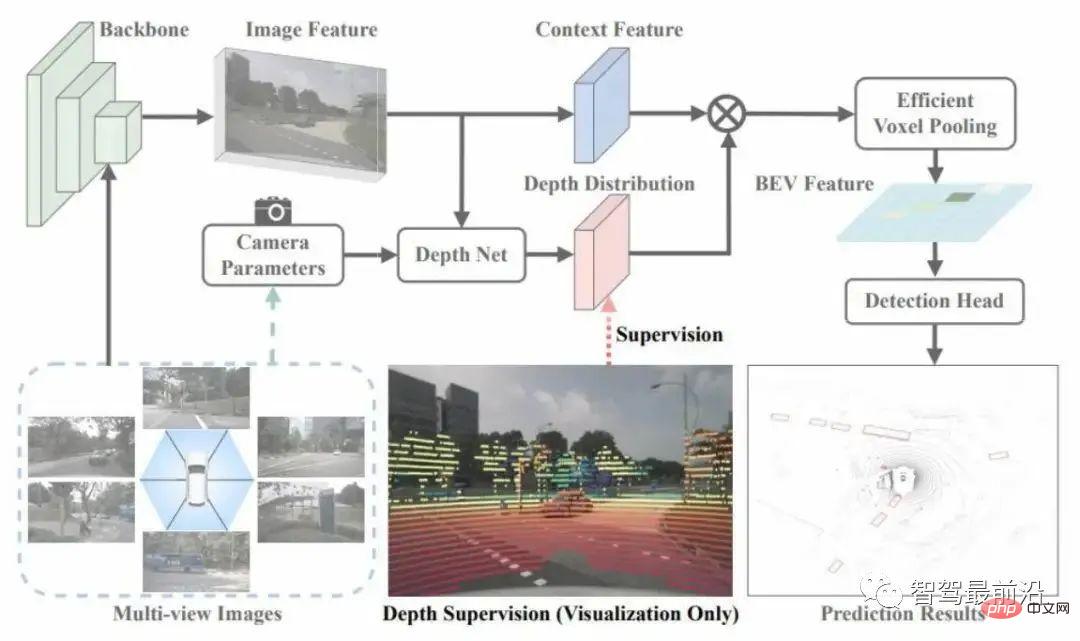
Abbildung 4 BEVTiefennetzwerkstruktur
Ein weiterer Aspekt dieser Arbeit besteht darin, die Merkmale und die Tiefe zur Schätzung in zwei Zweige zu unterteilen und dem Tiefenschätzungszweig zusätzliche Residuen hinzuzufügen Netzwerk zur Verbesserung des Empfangsfelds des Tiefenschätzungszweigs. Forscher gehen davon aus, dass die Genauigkeit der internen und externen Parameter der Kamera zu einer Fehlausrichtung von Kontext und Tiefe führt. Wenn das Tiefenschätzungsnetzwerk nicht leistungsfähig genug ist, kommt es zu einem gewissen Genauigkeitsverlust.
Schließlich werden die internen Parameter dieser Kamera als Zweigeingabe zur Tiefenschätzung verwendet, wobei eine NSE-ähnliche Methode verwendet wird, um den Kanal der Eingabefunktion auf Kanalebene anzupassen, wodurch die Reaktion des Netzwerks auf verschiedene Kameras effektiv verbessert werden kann interne Parameter der Robustheit.
04 Einschränkungen und damit verbundene Diskussionen
Zuallererst dient die visuelle Wahrnehmung des autonomen Fahrens letztendlich der Umsetzung, und während der Umsetzung wird es Datenprobleme und Modellprobleme geben. Das Datenproblem beinhaltet ein Diversitätsproblem und Datenannotationen, da manuelle Annotationen sehr teuer sind. Daher werden wir sehen, ob in Zukunft automatisierte Annotationen erreicht werden können.
Die Beschriftung dynamischer Ziele ist derzeit beispiellos. Bei statischen Zielen kann eine teilweise oder halbautomatische Beschriftung durch 3D-Rekonstruktion erfolgen. Was die Modelle betrifft, ist das aktuelle Modelldesign nicht robust gegenüber der Kalibrierung oder reagiert empfindlich auf die Kalibrierung. Daher ist es auch eine Frage, darüber nachzudenken, wie das Modell robust gegenüber der Kalibrierung oder unabhängig von der Kalibrierung gemacht werden kann.
Das andere ist das Problem der Netzwerkstrukturbeschleunigung. Kann ein allgemeines OP verwendet werden, um Perspektivenänderungen zu erreichen?
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der Roadmap der visuellen Wahrnehmungstechnologie für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
