
 Technologie-Peripheriegeräte
KI
Sanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus
Technologie-Peripheriegeräte
KI
Sanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus
Sanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus

Wir wissen, dass punktebasierte Modelle und entrauschende Diffusions-Wahrscheinlichkeitsmodelle (DDPM) zwei leistungsstarke Arten generativer Modelle sind, die Stichproben durch Umkehrung des Diffusionsprozesses generieren. Diese beiden Arten von Modellen wurden in der Arbeit „Score-based generative modeling through stochastic Differential Equations“ von Yang Song und anderen Forschern in einem einzigen Rahmenwerk zusammengefasst und sind weithin als Diffusionsmodelle bekannt.
Gegenwärtig hat das Diffusionsmodell große Erfolge in einer Reihe von Anwendungen erzielt, darunter Bild-, Audio- und Videoerzeugung und die Lösung inverser Probleme. In der Arbeit „Elucidating the design space of diffusionbased generative models“ analysierten Forscher wie Tero Karras den Designraum des Diffusionsmodells und identifizierten drei Phasen, nämlich i) Auswahl der Planung des Rauschpegels, ii) Auswahl der Netzwerkparameter. isierung (jede Parametrisierung erzeugt eine andere Verlustfunktion), iii) Entwurf des Abtastalgorithmus.
In einem kürzlich von Google Research und UT-Austin gemeinsam durchgeführten arXiv-Artikel „Soft Diffusion: Score Matching for General Corruptions“ glauben mehrere Forscher, dass das Diffusionsmodell noch einen wichtigen Schritt hat: Korruption. Im Allgemeinen handelt es sich bei Korruption um einen Prozess, bei dem Rauschen unterschiedlicher Amplitude hinzugefügt wird, und bei DDMP ist auch eine Neuskalierung erforderlich. Obwohl Versuche unternommen wurden, unterschiedliche Distributionen für die Verbreitung zu nutzen, fehlt noch immer ein allgemeiner Rahmen. Daher schlugen die Forscher einen Entwurfsrahmen für ein Diffusionsmodell für einen allgemeineren Schadensprozess vor.
Konkret schlugen sie ein neues Trainingsziel namens Soft Score Matching und eine neuartige Stichprobenmethode Momentum Sampler vor. Theoretische Ergebnisse zeigen, dass Soft Score MatchIng für Schadensprozesse, die Regelmäßigkeitsbedingungen erfüllen, in der Lage ist, deren Scores (d. h. Wahrscheinlichkeitsgradienten) zu lernen, die durch Diffusion jedes Bild in jedes Bild mit einer Wahrscheinlichkeit ungleich Null umwandeln müssen.
Im experimentellen Teil trainierten die Forscher das Modell auf CelebA und CIFAR-10. Das auf CelebA trainierte Modell erreichte den SOTA-FID-Score des linearen Diffusionsmodells – 1,85. Gleichzeitig ist das von den Forschern trainierte Modell deutlich schneller als das Modell, das mit der ursprünglichen Gaußschen Entrauschungsdiffusion trainiert wurde.

Papieradresse: https://arxiv.org/pdf/2209.05442.pdf
Übersicht über die Methode
Im Allgemeinen werden Diffusionsmodelle durch Umkehrung des Schadensprozesses mit allmählich zunehmendem Schaden erzeugt Rauschbild. Die Forscher zeigen, wie man lernen kann, die Diffusion durch lineare deterministische Degradation und stochastisches additives Rauschen umzukehren.

Konkret demonstrierten die Forscher ein Framework zum Training eines Diffusionsmodells mithilfe eines allgemeineren Schadensmodells, das aus drei Teilen besteht, nämlich dem neuen Trainingsziel Soft Score Matching, der neuartigen Stichprobenmethode Momentum Sampler und der Planung des Schadensmechanismus.
Schauen wir uns zunächst das Trainingsziel Soft Score Matching an. Der Name ist von Soft Filtering inspiriert, einem Begriff aus der Fotografie, der sich auf einen Filter bezieht, der feine Details entfernt. Es lernt den Anteil eines herkömmlichen linearen Schadensprozesses auf nachweisbare Weise, integriert außerdem einen Filterprozess in das Netzwerk und trainiert das Modell, um Bilder nach dem Schaden vorherzusagen, die mit Diffusionsbeobachtungen übereinstimmen.
Solange die Diffusion jedem sauberen, beschädigten Bildpaar eine Wahrscheinlichkeit ungleich Null zuweist, kann dieses Trainingsziel beweisen, dass die Punktzahl gelernt ist. Darüber hinaus ist diese Bedingung immer dann erfüllt, wenn im Schaden zusätzliches Rauschen vorhanden ist.
Konkret untersuchten die Forscher den Schadensprozess in den folgenden Formen.

Dabei entdeckten die Forscher, dass Rauschen sowohl empirisch (also für bessere Ergebnisse) als auch theoretisch (also für das Lernen von Brüchen) wichtig ist. Dies ist auch ein wesentlicher Unterschied zu Cold Diffusion, einer parallelen Arbeit, die deterministische Korruption umkehrt.
Die zweite ist die Sampling-Methode Momentum Sampling. Die Forscher zeigten, dass die Wahl des Probenehmers einen erheblichen Einfluss auf die Qualität der erzeugten Proben hat. Sie schlugen den Momentum Sampler vor, um einen universellen linearen Schadensprozess umzukehren. Der Sampler nutzt konvexe Schadenskombinationen mit unterschiedlichen Diffusionsniveaus und ist von Impulsmethoden in der Optimierung inspiriert.
Diese Stichprobenmethode ist von der kontinuierlichen Formulierung des Diffusionsmodells inspiriert, das in der oben genannten Arbeit von Yang Song et al. vorgeschlagen wurde. Der Algorithmus für Momentum Sampler ist unten dargestellt.

Die folgende Abbildung zeigt visuell den Einfluss verschiedener Probenahmemethoden auf die Qualität der generierten Proben. Das mit Naive Sampler aufgenommene Bild auf der linken Seite scheint sich zu wiederholen und es mangelt an Details, während der Momentum Sampler auf der rechten Seite die Sampling-Qualität und den FID-Score deutlich verbessert.

Zum Schluss noch die Terminplanung. Selbst wenn die Art der Verschlechterung vordefiniert ist (z. B. Unschärfe), ist die Entscheidung, wie viel Schaden bei jedem Diffusionsschritt verursacht werden soll, nicht trivial. Die Forscher schlagen ein prinzipielles Werkzeug zur Steuerung der Gestaltung von Schadensprozessen vor. Um den Zeitplan zu ermitteln, minimieren sie den Wasserstein-Abstand zwischen Verteilungen entlang des Pfads. Intuitiv wünschen sich Forscher einen reibungslosen Übergang von einer vollständig beschädigten Verteilung zu einer sauberen Verteilung.
Experimentelle Ergebnisse
Die Forscher bewerteten die vorgeschlagene Methode anhand von CelebA-64 und CIFAR-10, die beide Standardbasislinien für die Bilderzeugung sind. Der Hauptzweck des Experiments besteht darin, die Rolle der Schadensart zu verstehen.
Die Forscher versuchten zunächst, Unschärfe und Rauschen mit niedriger Amplitude zur Schädigung zu nutzen. Die Ergebnisse zeigen, dass ihr vorgeschlagenes Modell SOTA-Ergebnisse auf CelebA erreicht, d. h. einen FID-Score von 1,85, und damit alle anderen Methoden übertrifft, die nur Rauschen hinzufügen und das Bild möglicherweise neu skalieren. Darüber hinaus beträgt der auf CIFAR-10 erzielte FID-Score 4,64, was konkurrenzfähig ist, obwohl er SOTA nicht erreicht.

Darüber hinaus schnitt die Methode des Forschers bei den CIFAR-10- und CelebA-Datensätzen auch bei einer anderen Metrik, der Stichprobenzeit, besser ab. Ein weiterer zusätzlicher Vorteil sind erhebliche Rechenvorteile. Das Entschärfen (fast kein Rauschen) scheint eine effizientere Manipulation im Vergleich zu Methoden zur Rauschunterdrückung bei der Bilderzeugung zu sein.
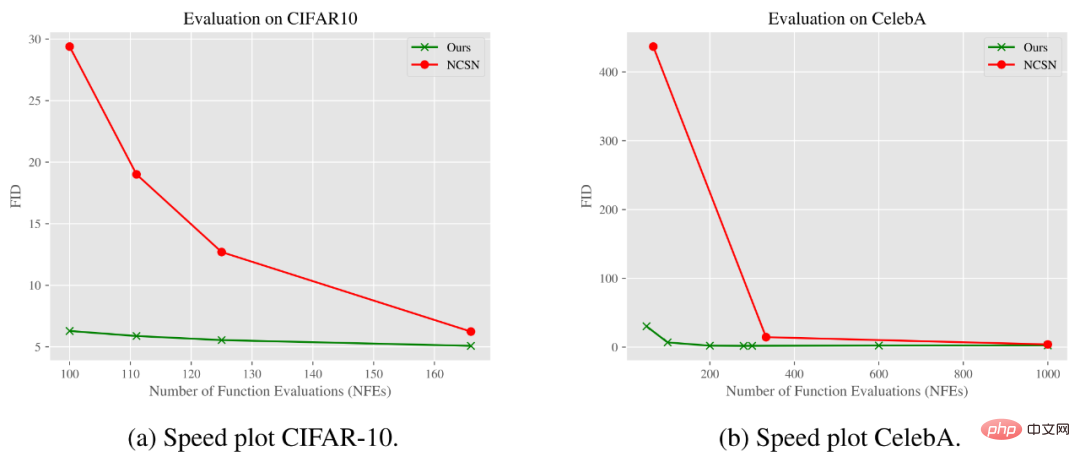
Das Diagramm unten zeigt, wie sich der FID-Score mit der Anzahl der Funktionsbewertungen (NFE) ändert. Wie aus den Ergebnissen hervorgeht, kann unser Modell mit deutlich weniger Schritten für die CIFAR-10- und CelebA-Datensätze die gleiche oder eine bessere Qualität als das Standard-Gaußsche Rauschunterdrückungs-Diffusionsmodell erreichen.
Das obige ist der detaillierte Inhalt vonSanfte Diffusion: Das neue Framework von Google plant, lernt und probiert einen universellen Diffusionsprozess korrekt aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
